深入理解计算机系统_3e 第五章家庭作业 CS:APP3e chapter 5 homework
**5.13**
A.
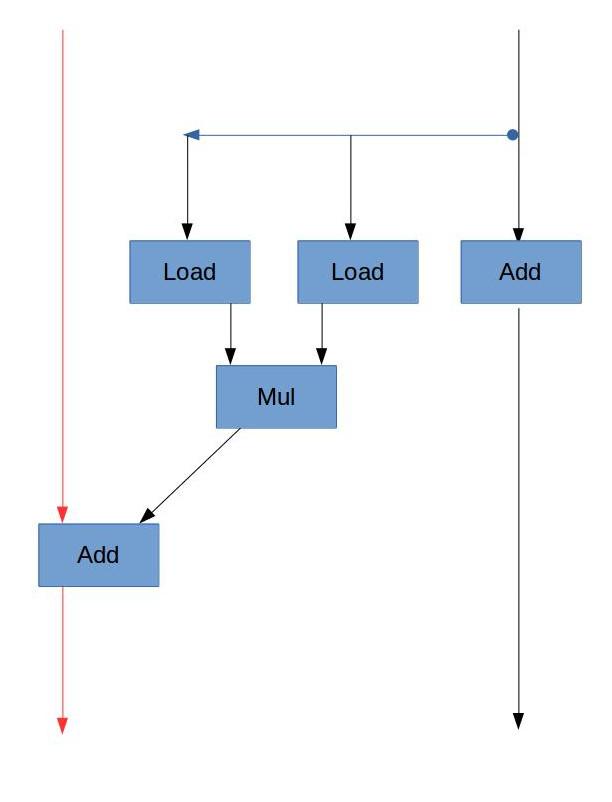
B. 由浮点数加法的延迟,CPE的下界应该是3。
C. 由整数加法的延迟,CPE的下界应该是1.
D. 由A中的数据流图,虽然浮点数乘法需要5个周期,但是它没有“数据依赖”,也就是说,每次循环时的乘法不需要依赖上一次乘法的结果,可以各自独立进行。但是加法是依赖于上一次的结果的(sum = sum + 乘法结果),所以该循环的“关键路径”是加法这条链。而浮点数加法的延迟为3个周期,所以CPE为3.00。
5.14
A. 由5.13中分析的,关键路径是一个加法,而整数加法的延迟为1个周期,所以CPE的下界为1。
更新:题意弄错,不是只分析6*1整数运算,跳跳熊12138指出,已更正。
下面是跳跳熊12138给的答案:
本题的代码有n(数据规模)次加运算和乘运算。cpe最低的情况是加的功能功能单元和乘的功能单元全都处于满流水的状态,此时加和乘都达到吞吐量下界。对于整数运算,加法的吞吐量下界为0.5,乘法的吞吐量下界为1.0,所以cpe=max{0.5,1.0};对于浮点数运算,加法的吞吐量下界是1.0,乘法的吞吐量下界是0.5,所以cpe=max{1.0,0.5}=1.0。综上,cpe的下界是1.0。
B. “6 * 1 loop unrolling”只减少了循环的次数(所以整数的CPE下降了,书上把这个称为“overhead”),并没有减少内存读写的次数和流水线的发生,所以浮点数运算还是不能突破“关键路径”的CPE下界。
5.15
/* 6 * 6 loop unrolling */
/*省略*/
data_t sum1 = (data_t) 0;
data_t sum2 = (data_t) 0;
data_t sum3 = (data_t) 0;
data_t sum4 = (data_t) 0;
data_t sum5 = (data_t) 0;
for(i = 0; i < length; i += 6)
{
sum1 = sum1 + udata[i] * vdata[i]; /* 相互独立,可以流水线 */
sum2 = sum2 + udata[i+1] * vdata[i+1];
sum3 = sum3 + udata[i+2] * vdata[i+2];
sum4 = sum4 + udata[i+3] * vdata[i+3];
sum5 = sum5 + udata[i+4] * vdata[i+4];
sum6 = sum6 + udata[i+5] * vdata[i+5];
}
for(; i < length; ++i)
{
sum1 = sum1 + udata[i] * vdata[i];
}
*dest = sum1 + sum2 + sum3 + sum4 + sum5 + sum6;
虽然此时可以流水线,但是浮点数加法的单元的Issue time为1个周期,而Capacity也为1,所以最多每个时钟周期完成I/C = 1个加法操作,即此时CPE的下界为1。
5.16
/* 6 * 1a loop unrolling */
/*省略*/
data_t sum1 = (data_t) 0;
data_t sum2 = (data_t) 0;
data_t sum3 = (data_t) 0;
data_t sum4 = (data_t) 0;
data_t sum5 = (data_t) 0;
for(i = 0; i < length; i += 6)
{
sum = sum + (udata[i] * vdata[i] + udata[i+1] * vdata[i+1] + udata[i+2] * vdata[i+2] + udata[i+3] * vdata[i+3] + udata[i+4] * vdata[i+4] + udata[i+5] * vdata[i+5]);
}
for(; i < length; ++i)
{
sum = sum + udata[i] * vdata[i];
}
*dest = sum;
5.17
#include <limits.h>
#define K sizeof(unsigned long)
void *word_memset(void *s, int c, size_t n)
{
if (n < K)
{
size_t cnt = 0;
unsigned char *schar = s;
while (cnt < n)
{
*schar++ = (unsigned char)c;
cnt++;
}
}
else
{
unsigned long word = 0;
for (int i = 0; i < K; ++i)
{
word <<= K*CHAR_BIT;
word += (unsigned char)c;
}
size_t cnt = 0;
unsigned long *slong = s;
while (cnt < n)
{
*slong++ = word;
cnt += K;
}
unsigned char *schar = slong;
while (cnt < n)
{
*schar++ = (unsigned char)c;
cnt++;
}
}
return s;
}
5.18
答案不唯一,我这里是利用10 × 10的loop unrolling改“direct evaluation”的版本。
原函数的瓶颈在于xpwr = xpwr * x这一句,乘法数据依赖,由书上给出的K >= L*C (第540面),其中L是latency,C是capacity,由于浮点数乘法分别对应5和2,所以这里的K选择为10。
另外,K大的时候很可能会碰到寄存器不够的情况,不得不使用栈来保存局部变量(运行的时候会加载到高速缓存),会有一些性能上的牺牲。
double faster_poly(double a[], double x, long degree)
{
long i;
double result1 = a[0];
double result2 = 0;
double result3 = 0;
double result4 = 0;
double result5 = 0;
double result6 = 0;
double result7 = 0;
double result8 = 0;
double result9 = 0;
double result10 = 0;
double xpwr1 = x;
double xpwr2 = xpwr1 * x;
double xpwr3 = xpwr2 * x;
double xpwr4 = xpwr3 * x;
double xpwr5 = xpwr4 * x;
double xpwr6 = xpwr5 * x;
double xpwr7 = xpwr6 * x;
double xpwr8 = xpwr7 * x;
double xpwr9 = xpwr8 * x;
double xpwr10 = xpwr9 * x;
double x10 = xpwr10;
for (i = 1; (i+9) <= degree; i += 10)
{
result1 += a[i] * xpwr1;
result2 += a[i+1] * xpwr2;
result3 += a[i+2] * xpwr3;
result4 += a[i+3] * xpwr4;
result5 += a[i+4] * xpwr5;
result6 += a[i+5] * xpwr6;
result7 += a[i+6] * xpwr7;
result8 += a[i+7] * xpwr8;
result9 += a[i+8] * xpwr9;
result10 += a[i+9] * xpwr10;
xpwr1 *= x10;
xpwr2 *= x10;
xpwr3 *= x10;
xpwr4 *= x10;
xpwr5 *= x10;
xpwr6 *= x10;
xpwr7 *= x10;
xpwr8 *= x10;
xpwr9 *= x10;
xpwr10 *= x10;
}
for (; i <= degree; ++i)
{
result1 += a[i] * xpwr1;
xpwr1 *= x;
}
result1 += result2;
result1 += result3;
result1 += result4;
result1 += result5;
result1 += result6;
result1 += result7;
result1 += result8;
result1 += result9;
result1 += result10;
return result1;
}
5.19
瓶颈在于val=val+a[i] (书上还加了last_val ,一个意思)这一句,加法数据依赖,由书上给出的K >= L*C (第540面),其中L是latency,C是capacity,由于浮点数加法分别对应3和1,所以这里选择3*1a。
void faster_psum1a(float a[], float p[], long n)
{
long i;
float val = 0;
for (i = 0; (i+2) < n; i += 3)
{
float tmp1 = a[i];
float tmp2 = tmp1 + a[i+1];
float tmp3 = tmp2 + a[i+2];
p[i] = var + tmp1;
p[i+1] = var + tmp2;
p[i+2] = var = var + tmp3;
}
for (; i < n; ++i)
{
var += a[i];
p[i] = var;
}
}
深入理解计算机系统_3e 第五章家庭作业 CS:APP3e chapter 5 homework的更多相关文章
- 深入理解计算机系统_3e 第六章家庭作业 CS:APP3e chapter 6 homework
6.22 假设磁道沿半径均匀分布,即总磁道数和(1-x)r成正比,设磁道数为(1-x)rk: 由题单个磁道的位数和周长成正比,即和半径xr成正比,设单个磁道的位数为xrz: 其中r.k.z均为常数. ...
- 深入理解计算机系统_3e 第七章家庭作业 CS:APP3e chapter 7 homework
7.6 +-----------------------------------------------------------------------+ |Symbol entry? Symbol ...
- 深入理解计算机系统_3e 第三章家庭作业 CS:APP3e chapter 3 homework
3.58 long decode2(long x, long y, long z) { int result = x * (y - z); if((y - z) & 1) result = ~ ...
- 深入理解计算机系统_3e 第十一章家庭作业 CS:APP3e chapter 11 homework
注:tiny.c csapp.c csapp.h等示例代码均可在Code Examples获取 11.6 A. 书上写的示例代码已经完成了大部分工作:doit函数中的printf("%s&q ...
- 深入理解计算机系统_3e 第九章家庭作业 CS:APP3e chapter 9 homework
9.11 A. 00001001 111100 B. +----------------------------+ | Parameter Value | +--------------------- ...
- 深入理解计算机系统_3e 第二章家庭作业 CS:APP3e chapter 2 homework
初始完成日期:2017.9.26 许可:除2.55对应代码外(如需使用请联系 randy.bryant@cs.cmu.edu),任何人可以自由的使用,修改,分发本文档的代码. 本机环境: (有一些需要 ...
- 深入理解计算机系统_3e 第四章家庭作业(部分) CS:APP3e chapter 4 homework
4.52以后的题目中的代码大多是书上的,如需使用请联系 randy.bryant@cs.cmu.edu 更新:关于编译Y86-64中遇到的问题,可以参考一下CS:APP3e 深入理解计算机系统_3e ...
- 深入理解计算机系统_3e 第八章家庭作业 CS:APP3e chapter 8 homework
8.9 关于并行的定义我之前写过一篇文章,参考: 并发与并行的区别 The differences between Concurrency and Parallel +---------------- ...
- 深入理解计算机系统_3e 第十章家庭作业 CS:APP3e chapter 10 homework
10.6 1.若成功打开"foo.txt": -->1.1若成功打开"baz.txt": 输出"4\n" -->1.2若未能成功 ...
随机推荐
- Java并发之线程管理(线程基础知识)
因为书中涵盖的知识点比较全,所以就以书中的目录来学习和记录.当然,学习书中知识的时候自己的思考和实践是最重要的.说到线程,脑子里大概知道是个什么东西,但很多东西都还是懵懵懂懂,这是最可怕的.所以想着细 ...
- 利用bootstrap写的一点本地(localStorage)储存
摘要: H5本地存储 在以前,我们想要存储一些数据,并且只是在前端使用,服务端并不会使用,我们只能存在cookie里,但是cookie会跟随请求头在客户端和服务端之间来回传递,而且cookie还有一些 ...
- Python 动态导入模块
动态导入模块 目录结构: zhangsandeMacBook-Air:1110 zhangsan$ tree . . ├── lib │ └── aa.py ├── test1.py lib目录下 ...
- [最短路]P1119 灾后重建
题目背景 B地区在地震过后,所有村庄都造成了一定的损毁,而这场地震却没对公路造成什么影响.但是在村庄重建好之前,所有与未重建完成的村庄的公路均无法通车.换句话说,只有连接着两个重建完成的村庄的公路才能 ...
- excel vlookup
今天在百度知道的时候,看到旁边有人问excel中条件查找vlookup的问题,有几位高手都知道使用vlookup作答,可惜都是没有经过测试,直接复制别人的答案,让所有的读者都无法实施,一头雾水.今天我 ...
- C语言之随机数
#include<stdio.h>#include<stdlib.h>#include<time.h>int main(){ srand(time(0)); int ...
- java的基本知识导航
java基本知识 备注:本次主要是思维导图,就是简单的说一下,只会扩展导图中的java关键字,其他以后再写 1.思维导图 2.java关键字 关键字 描述 abstract 抽象方法,抽象类的修饰符 ...
- 自己动手编写IOC框架(二)
万事开头难,上篇已经起了一个头,之后的事情相对就简单了.上次定义了框架所需的dtd也就是规定了xml中该怎么写,有哪些元素.并且我们也让dtd和xml绑定在了一起,使dtd对xml的格式进行校验,并且 ...
- 域名和ip不能访问的原因
centos的话可能默认可能会有firewalld,可以执行 systemctl stop firewalld systemctl disable firewalld 禁用后在看看,前提都是域名得备案 ...
- 数据库索引------Hash索引的使用限制
1.hash索引必须进行二次查找. 2.hash索引无法进行排序. 3.hash索引不支持部分索引查找也不支持范围查找. 4.hash索引中hash码的计算可能存在hash冲突.