【转载】Linux下的IO监控与分析
近期要在公司内部做个Linux IO方面的培训, 整理下手头的资料给大家分享下
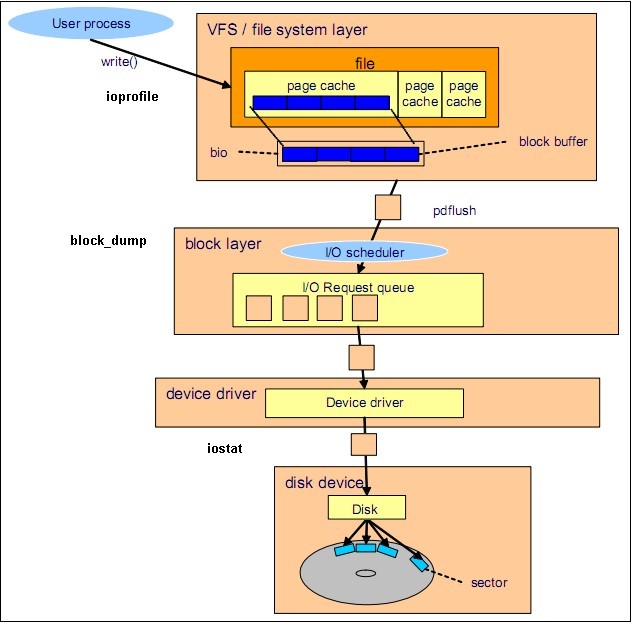
各种IO监视工具在Linux IO 体系结构中的位置
源自 Linux Performance and Tuning Guidelines.pdf
1 系统级IO监控
iostat
iostat -xdm 1 # 个人习惯

%util 代表磁盘繁忙程度。100% 表示磁盘繁忙, 0%表示磁盘空闲。但是注意,磁盘繁忙不代表磁盘(带宽)利用率高
argrq-sz 提交给驱动层的IO请求大小,一般不小于4K,不大于max(readahead_kb, max_sectors_kb)
可用于判断当前的IO模式,一般情况下,尤其是磁盘繁忙时, 越大代表顺序,越小代表随机
svctm 一次IO请求的服务时间,对于单块盘,完全随机读时,基本在7ms左右,既寻道+旋转延迟时间
注: 各统计量之间关系
=======================================
%util = ( r/s + w/s) * svctm / 1000 # 队列长度 = 到达率 * 平均服务时间
avgrq-sz = ( rMB/s + wMB/s) * 2048 / (r/s + w/s) # 2048 为 1M / 512
=======================================
总结:
iostat 统计的是通用块层经过合并(rrqm/s, wrqm/s)后,直接向设备提交的IO数据,可以反映系统整体的IO状况,但是有以下2个缺点:
1 距离业务层比较遥远,跟代码中的write,read不对应(由于系统预读 + pagecache + IO调度算法等因素, 也很难对应)
2 是系统级,没办法精确到进程,比如只能告诉你现在磁盘很忙,但是没办法告诉你是谁在忙,在忙什么?
2 进程级IO监控
iotop 和 pidstat (仅rhel6u系列)
iotop 顾名思义, io版的top
pidstat 顾名思义, 统计进程(pid)的stat,进程的stat自然包括进程的IO状况
这两个命令,都可以按进程统计IO状况,因此可以回答你以下二个问题
- 当前系统哪些进程在占用IO,百分比是多少?
- 占用IO的进程是在读?还是在写?读写量是多少?
pidstat 参数很多,仅给出几个个人习惯
pidstat -d 1 #只显示IO

pidstat -u -r -d -t 1 # -d IO 信息,
# -r 缺页及内存信息
# -u CPU使用率
# -t 以线程为统计单位
# 1 1秒统计一次
iotop, 很简单,直接敲命令

block_dump, iodump
iotop 和 pidstat 用着很爽,但两者都依赖于/proc/pid/io文件导出的统计信息, 这个对于老一些的内核是没有的,比如rhel5u2
因此只好用以上2个穷人版命令来替代:
echo 1 > /proc/sys/vm/block_dump # 开启block_dump,此时会把io信息输入到dmesg中
# 源码: submit_bio@ll_rw_blk.c:3213
watch -n 1 "dmesg -c | grep -oP \"\w+\(\d+\): (WRITE|READ)\" | sort | uniq -c"
# 不停的dmesg -c
echo 0 > /proc/sys/vm/block_dump # 不用时关闭
也可以使用现成的脚本 iodump, 具体参见 http://code.google.com/p/maatkit/source/browse/trunk/util/iodump?r=5389
iotop.stp
systemtap脚本,一看就知道是iotop命令的穷人复制版,需要安装Systemtap, 默认每隔5秒输出一次信息
stap iotop.stp # examples/io/iotop.stp
总结
进程级IO监控 ,
- 可以回答系统级IO监控不能回答的2个问题
- 距离业务层相对较近(例如,可以统计进程的读写量)
但是也没有办法跟业务层的read,write联系在一起,同时颗粒度较粗,没有办法告诉你,当前进程读写了哪些文件? 耗时? 大小 ?
3 业务级IO监控
ioprofile
ioprofile 命令本质上是 lsof + strace, 具体下载可见 http://code.google.com/p/maatkit/
ioprofile 可以回答你以下三个问题:
1 当前进程某时间内,在业务层面读写了哪些文件(read, write)?
2 读写次数是多少?(read, write的调用次数)
3 读写数据量多少?(read, write的byte数)
假设某个行为会触发程序一次IO动作,例如: "一个页面点击,导致后台读取A,B,C文件"
============================================
./io_event # 假设模拟一次IO行为,读取A文件一次, B文件500次, C文件500次
ioprofile -p `pidof io_event` -c count # 读写次数

ioprofile -p `pidof io_event` -c times # 读写耗时

ioprofile -p `pidof io_event` -c sizes # 读写大小

注: ioprofile 仅支持多线程程序,对单线程程序不支持. 对于单线程程序的IO业务级分析,strace足以。
总结:
ioprofile本质上是strace,因此可以看到read,write的调用轨迹,可以做业务层的io分析(mmap方式无能为力)
4 文件级IO监控
文件级IO监控可以配合/补充"业务级和进程级"IO分析
文件级IO分析,主要针对单个文件, 回答当前哪些进程正在对某个文件进行读写操作.
1 lsof 或者 ls /proc/pid/fd
2 inodewatch.stp
lsof 告诉你 当前文件由哪些进程打开
lsof ../io # io目录 当前由 bash 和 lsof 两个进程打开

lsof 命令 只能回答静态的信息, 并且"打开" 并不一定"读取", 对于 cat ,echo这样的命令, 打开和读取都是瞬间的,lsof很难捕捉
可以用 inodewatch.stp 来弥补
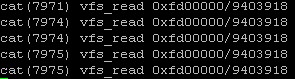
stap inodewatch.stp major minor inode # 主设备号, 辅设备号, 文件inode节点号
stap inodewatch.stp 0xfd 0x00 523170 # 主设备号, 辅设备号, inode号,可以通过 stat 命令获得
5 IO模拟器
iotest.py # 见附录
开发人员可以 利用 ioprofile (或者 strace) 做详细分析系统的IO路径,然后在程序层面做相应的优化。
但是一般情况下调整程序,代价比较大,尤其是当不确定修改方案到底能不能有效时,最好有某种模拟途径以快速验证。
以为我们的业务为例,发现某次查询时,系统的IO访问模式如下:
访问了A文件一次
访问了B文件500次, 每次16字节, 平均间隔 502K
访问了C文件500次, 每次200字节, 平均间隔 4M
这里 B,C文件是交错访问的, 既
1 先访问B,读16字节,
2 再访问C,读200字节,
3 回到B,跳502K后再读16字节,
4 回到C,跳4M后,再读200字节
5 重复500次
strace 文件如下:

一个简单朴素的想法, 将B,C交错读,改成先批量读B , 再批量读C,因此调整strace 文件如下:
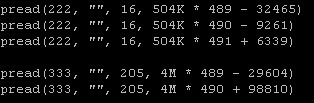
将调整后的strace文件, 作为输入交给 iotest.py, iotest.py 按照 strace 文件中的访问模式, 模拟相应的IO
iotest.py -s io.strace -f fmap
fmap 为映射文件,将strace中的222,333等fd,映射到实际的文件中
===========================
111 = /opt/work/io/A.data
222 = /opt/work/io/B.data
333 = /opt/work/io/C.data
===========================
6 磁盘碎片整理
一句话: 只要磁盘容量不常年保持80%以上,基本上不用担心碎片问题。
如果实在担心,可以用 defrag 脚本
7 其他IO相关命令
blockdev 系列
=======================================
blockdev --getbsz /dev/sdc1 # 查看sdc1盘的块大小
block blockdev --getra /dev/sdc1 # 查看sdc1盘的预读(readahead_kb)大小
blockdev --setra 256 /dev/sdc1 # 设置sdc1盘的预读(readahead_kb)大小,低版的内核通过/sys设置,有时会失败,不如blockdev靠谱
=======================================
附录 iotest.py

#! /usr/bin/env python
# -*- coding: gbk -*-
import os
import re
import timeit
from ctypes import CDLL, create_string_buffer, c_ulong, c_longlong
from optparse import OptionParser usage = '''%prog -s strace.log -f fileno.map ''' _glibc = None
_glibc_pread = None
_c_char_buf = None _open_file = [] def getlines(filename):
_lines = []
with open(filename,'r') as _f:
for line in _f:
if line.strip() != "":
_lines.append(line.strip())
return _lines def parsecmdline():
parser = OptionParser(usage)
parser.add_option("-s", "--strace", dest="strace_filename",
help="strace file", metavar="FILE") parser.add_option("-f", "--fileno", dest="fileno_filename",
help="fileno file", metavar="FILE") (options, args) = parser.parse_args()
if options.strace_filename is None: parser.error("strace is not specified.")
if not os.path.exists(options.strace_filename): parser.error("strace file does not exist.") if options.fileno_filename is None: parser.error("fileno is not specified.")
if not os.path.exists(options.strace_filename): parser.error("fileno file does not exist.") return options.strace_filename, options.fileno_filename # [type, ...]
# [pread, fno, count, offset]
# pread(15, "", 4348, 140156928)
def parse_strace(filename):
lines = getlines(filename) action = []
_regex_str = r'(pread|pread64)[^\d]*(\d+),\s*[^,]*,\s*([\dkKmM*+\-. ]*),\s*([\dkKmM*+\-. ]*)'
for i in lines:
_match = re.match(_regex_str, i)
if _match is None: continue # 跳过无效行
_type, _fn, _count, _off = _match.group(1), _match.group(2), _match.group(3), _match.group(4)
_off = _off.replace('k', " * 1024 ").replace('K', " * 1024 ").replace('m', " * 1048576 ").replace('M', " * 1048576 ")
_count = _count.replace('k', " * 1024 ").replace('K', " * 1024 ").replace('m', " * 1048576 ").replace('M', " * 1048576 ")
#print _off
action.append([_type, _fn, str(int(eval(_count))), str(int(eval(_off))) ]) return action def parse_fileno(filename):
lines = getlines(filename)
fmap = {}
for i in lines:
if i.strip().startswith("#"): continue # 注释行
_split = [j.strip() for j in i.split("=")]
if len(_split) != 2: continue # 无效行
fno, fname = _split[0], _split[1]
fmap[fno] = fname
return fmap def simulate_before(strace, fmap):
global _open_file, _c_char_buf
rfmap = {}
for i in fmap.values():
_f = open(i, "r+b")
#print "open {0}:{1}".format(_f.fileno(), i)
_open_file.append(_f)
rfmap[i] = str(_f.fileno()) # 反向映射 to_read = 4 * 1024 # 默认4K buf
for i in strace:
i[1] = rfmap[fmap[i[1]]] # fid -> fname -> fid 映射转换
to_read = max(to_read, int(i[2]))
#print "read buffer len: %d Byte" % to_read
_c_char_buf = create_string_buffer(to_read) def simulate_after():
global _open_file
for _f in _open_file:
_f.close() def simulate(actions): #timeit.time.sleep(10) # 休息2秒钟, 以便IO间隔 start = timeit.time.time() for act in actions:
__simulate__(act) finish = timeit.time.time() return finish - start def __simulate__(act):
global _glibc, _glibc_pread, _c_char_buf if "pread" in act[0]:
_fno = int(act[1])
_buf = _c_char_buf
_count = c_ulong(int(act[2]))
_off = c_longlong(int(act[3])) _glibc_pread(_fno, _buf, _count, _off) #print _glibc.time(None)
else:
pass
pass def loadlibc():
global _glibc, _glibc_pread
_glibc = CDLL("libc.so.6")
_glibc_pread = _glibc.pread64 if __name__ == "__main__": _strace, _fileno = parsecmdline() # 解析命令行参数 loadlibc() # 加载动态库 _action = parse_strace(_strace) # 解析 action 文件 _fmap = parse_fileno(_fileno) # 解析 文件名映射 文件 simulate_before(_action, _fmap) # 预处理
#print "total io operate: %d" % (len(_action)) #for act in _action: print " ".join(act)
print "%f" % simulate(_action)
【转载】Linux下的IO监控与分析的更多相关文章
- Linux下的IO监控与分析
Linux下的IO监控与分析 近期要在公司内部做个Linux IO方面的培训, 整理下手头的资料给大家分享下 各种IO监视工具在Linux IO 体系结构中的位置 源自 Linux Performan ...
- Linux下的IO监控与分析(转)
各种IO监视工具在Linux IO 体系结构中的位置 源自 Linux Performance and Tuning Guidelines.pdf 1 系统级IO监控 iostat iostat -x ...
- Centos下的IO监控与分析
近期要在公司内部做个Linux IO方面的培训, 整理下手头的资料给大家分享下 各种IO监视工具在Linux IO 体系结构中的位置 源自 Linux Performance and Tuni ...
- Linux下使用NMON监控、分析系统性能 -转载
原帖地址:http://blog.itpub.net/23135684/viewspace-626439/ 谢谢原帖大人 一.下载nmon. 根据CPU的类型选择下载相应的版本:http://nmon ...
- Linux下使用NMON监控、分析系统性能
一.下载nmon. 根据CPU的类型选择下载相应的版本:http://nmon.sourceforge.net/pmwiki.php?n=Site.Downloadwget http://source ...
- [转载] Linux下多路复用IO接口 epoll select poll 的区别
原地址:http://bbs.linuxpk.com/thread-43628-1-1.html 废话不多说,一下是本人学习nginx 的时候总结的一些资料,比较乱,但看完后细细揣摩一下应该就弄明白区 ...
- [转载] Linux五种IO模型
转载:http://blog.csdn.net/jay900323/article/details/18141217 Linux五种IO模型性能分析 目录(?)[-] 概念理解 Lin ...
- Linux进程实时IO监控iotop命令详解
介绍 Linux下的IO统计工具如iostat, nmon等大多数是只能统计到per设备的读写情况, 如果你想知道每个进程是如何使用IO的就比较麻烦. iotop 是一个用来监视磁盘 I/O 使用状况 ...
- Windows五种IO模型性能分析和Linux五种IO模型性能分析
Windows五种IO模型性能分析和Linux五种IO模型性能分析 http://blog.csdn.net/jay900323/article/details/18141217 http://blo ...
随机推荐
- weka 通过普通文本转化成arff文件
这个问题来源于我要用weka这个数据挖掘工具,测试时发现我们新建txt文件,输入内容,然后直接改后缀. 这样生成的arff文件不能打开. 究其原因是编码的问题,正确处理方法如下: 新建文本,然后用no ...
- 后台程序处理 (一)python asyncio 协程使用
由于脚本需要在完成事件处理后N秒检查事件处理结果,当执行失败时再执行另一个事件处理. 想要最小化完成这个功能.同时在第一时间就将执行完毕的结果反馈给接口. 因此想到使用协程. 使用之前先翻阅了一下现有 ...
- VUE-CLI Vue安装及开发,npm run build无法查看项目的问题
Vue-cli 本地安装vue项目 需要安装node.js,用node命令行npm的方式安装Vue 步骤: 1.进入项目地址安装 npm install vue-cli -g 2.初始化一下 ESli ...
- 【python】字典dict
- jemeter工作台设置
工作台的设置 1.创建一个线程组 创建一个http代理服务器:工作台-->添加-->非测试元件-->http代理服务器 设置参照下图,要录制的时候点击启动 2.设置IE浏览器 IE- ...
- iOS 类似朋友圈的图片浏览器SDPhotoBrowser
SDPhotoBrowser.Demo 1.在文件SDBrowserImageView.m中有用SDWebImage到网络加载图片 需要的注释去掉即可 #import "ViewContro ...
- mouseout、mouseover和mouseleave、mouseenter区别
今天在使用鼠标事件时,用错了mouseout,于是做个测试总结. 结论: mouseenter:当鼠标移入某元素时触发. mouseleave:当鼠标移出某元素时触发. mouseover:当鼠标移入 ...
- 平方根的C语言实现(三) ——最终程序实现
版权申明:本文为博主窗户(Colin Cai)原创,欢迎转帖.如要转贴,必须注明原文网址 http://www.cnblogs.com/Colin-Cai/p/7223254.html 作者:窗户 Q ...
- bzoj 4012: [HNOI2015]开店
Description 风见幽香有一个好朋友叫八云紫,她们经常一起看星星看月亮从诗词歌赋谈到 人生哲学.最近她们灵机一动,打算在幻想乡开一家小店来做生意赚点钱.这样的 想法当然非常好啦,但是她们也发现 ...
- HBase0.98使用ReplicationAdmin管理集群同步
公司datalink平台负责从各种数据源读取数据并同步到其他的同步或者异构数据源,最近增加的HBase的reader利用到了Hbase的Replication特性. 正常情况下,我们配置HBase的R ...