用于NLP的CNN架构搬运:from keras0.x to keras2.x
本文亮点:
将用于自然语言处理的CNN架构,从keras0.3.3搬运到了keras2.x,强行练习了Sequential+Model的混合使用,具体来说,是Model里嵌套了Sequential。
本文背景:
暑假在做一个推荐系统的小项目,老师让我们搜集推荐系统领域Top5的算法和模型,要求结合深度学习。
我和小伙伴选择了其中的两篇文献深入研究,我负责跑通文献Convolutional Matrix Factorization for Document Context-Aware Recommendation里的模型,这是Recsys16下载量Top2的文章,仅次于youtube那篇。论文链接:http://dm.postech.ac.kr/~cartopy/ConvMF/ ,文章最下有数据集和源代码。
源代码的配置环境比较旧,基于python2.7和keras0.3.3,高级的地方是使用了GPU加速训练。其中用到的处理item document的CNN架构完全用keras0.3.3写的(这里的CNN用于NLP,与用于图像识别的CNN架构上有一定区别),其余的.py文件都是用py2写的
一、codes搬运:从python2到python3
现在py3用的比较多,也是趋势,所以我首先确定把py2的代码改写成py3能用的
python2和python3在code时有一定区别,在改写成py3时,有些简单的根据报错信息,百度google下很容易debug出来,比如:
print的内容在py3里要加括号
xrange-->range
zip()[]-->list(zip())[]
以上这些涉及到的代码就相当多了
真正麻烦耗时的是,二进制文件的读取,涉及编码类型。文献用的movielens数据集不是csv文件,下载下来查看了下有的编码是"utf-8",有的是"ANSI"。
我在下面这些地方研究了很久,简要记录下:
cpickle-->pikle,pickle.load,pickle.dump,"rb","wb","r"...
codecs.open(,"utf-8-sig")
二、CNN架构搬运:从keras0.3.3到keras2.x
两个版本的区别:keras0.3.3和keras2.x相差太多(keras0.x和keras1.x就相差很多了),主要是后者移除了Graph,新增了函数式模型--Model。
两个模型的区别:简单来说,Sequential是单输入单输出,Model(Graph)是多输入多输出。Graph图模型,建模时依然是向其中add_input, add_node, add_output,而2.x版的Model是一种函数式模型,建模时先定义Input,传递给Layer1,做了一次矩阵计算,再将当前层的输出,传递给Layer2,又做了一次矩阵计算···将最后的输出定义为整个模型的输出,最开始的输入定义为整个模型的输入,相当于给一个输入,得到一个输出,中间经过的黑箱就是我们的模型,这种行为就是函数,所以叫函数式模型。在2.x里,更强调Sequential是Model的特殊情况(这是文档里的原话,那不就意味着,必要时,Sequential也能当函数式模型用)。
改写难度:就该文献而言,改写难度在于源代码混合使用了Sequential+Graph,具体来说,是Graph里嵌套了Sequential。从0.x到2.x可以简单认为Graph对应着Model,这意味我可能要同时使用Sequential+Model,这是思路1。此时最希望的就是有现成的例子可以参考啊,而博客、文档中能找到的例子都是单独使用Sequential和Graph(Model)的,难道改写时,需要换成全用Sequential或全用Model,这里分别产生了思路2和思路3。
我很快决定采用思路1的主要原因有两点:
1)直觉:源代码混合使用了Sequential+Graph,从0.x到2.x可以简单认为Graph对应着Model,这暗示Sequential+Model可行(debug到实在不行我再全部改用Sequential);
2)就像前面文档里提到的,“在2.x里,更强调Sequential是Model的特殊情况”,那不就意味着,必要时,Sequential也能当函数式模型用(在写这篇博客时,我发现这里和思路3本质相同);
其实对于keras小白来说,快速选择思路1,主要还是靠直觉,后面也是理解了CNN架构、源代码逻辑,仔细查看两个版本的文档时,越来越确认思路1可行。所以,这也是下面要介绍的。
改写的正确姿势:看懂CNN的架构(原理图、流程图)-->看懂keras0.3.3写的架构-->对应着改写到keras2.x
1、CNN的架构
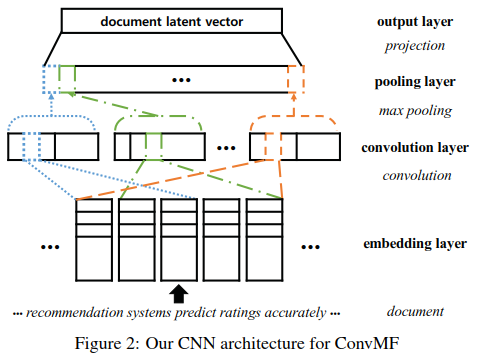
输入层:
输入对象为文档,可看成长度为l的词序列,每篇文档长度不等,统一设置max_len = 300(后面在keras序列数据预处理时用pad_sequence填充)
keras0.x:add_input
model = Graph()
'''Input'''
model.add_input(name='input', input_shape=(max_len,), dtype=int)
keras2.x:Input
'''Input'''
doc_input = Input(shape=(max_len,), dtype='int32', name='doc_input')
print("Builded input...")
嵌入层:
将one-hot编码的词向量(每个词向量维度=词典单词总数,这里vocab_size = 8000)嵌入成p维,这里emb_dim = 200,此时词序列的shape为p*l
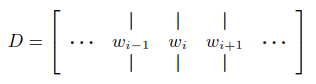

Reshape层:
进入Conv2D之前,reshape成channels last的形式
卷积层:3种不同window size的filter,每种filter提取出的特征图深度均为100,nb_filters=100,
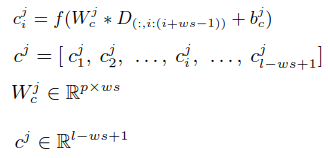
池化层:3种不同window size的filter

\(W_c^j\)提取\(c_i^j\)(第\(i\)个单词的\(j\)号上下文特征),每篇文档词序列长度为\(l\),共有\(l-ws+1\)个单词会被提取上下文特征,每个单词由\(n_c\)种不同的共享权重\(W_c^1,...,W_c^j,...,W_c^{n_c}\)提取\(n_c\)种特征,所以一篇文档,经卷积层提取出的上下文特征的shape是\(n_c*(l-ws+1)\),\(n_c\)相当于用于图像识别的CNN中特征图深度这一概念,这里特征图深度\(n_c=nbfilters=100\)
\]
\]
\]
\]
\]
\]
这里文档长度\(l\)和卷积核\(ws\)不同,提取出的特征矩阵shape不同,但只要经过maxpooling层,每个\(c^j\)取最大,最终得到\(n_c=100\)维的特征向量
\]
flatten层:
全连接层(200)&projection层(50):
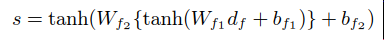
2、源代码逻辑
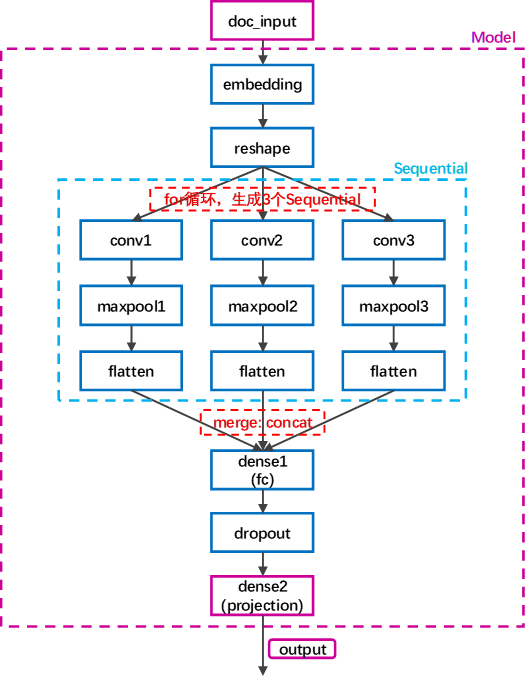
这里的CNN架构本质上是单输入单输出,输入是每一个item的document,输出是文档隐向量。中间用了3个不同window size的filter对reshape的输出做卷积&池化,flatten之后(斜体部分用循环生成了3个Sequential,注意这里不是共享层,共享层要求结构相同,这里3个不同的filter做卷积&池化,layer的结构明显不同),有3个outputs(都是100维的向量),再作为inputs输入到后面的layers(依次:全连接层200维,projection层50维)时,实际将3个inputs拼接起来了。
我一开始没注意到这里的拼接,文献和源代码也没有明显指出3个inputs的拼接,只是如果不拼接,每个input单独输入后面的共享层,从100维到200维再到50维,很奇怪!!一般都是高维的特征进入全连接层进行特征压缩,应该降维才对,这里居然升维,而如果3个100维的inputs拼接起来变成300维,再降到200维,最后降到50维,这样才合理,这是我的推断。后来我在keras0.3.3写的源代码找到了一个拼接的证据,这步里用到了add_node:
model.add_node(Dense(vanila_dimension, activation='tanh'), name='fully_connect', inputs=['unit_' + str(i) for i in filter_lengths])
这里的3个inputs实际是concat了在一起,变成3*100维,下面经过fc变成200维,再经过pj变成50维
keras0.3.3文档中关于add_node,默认merge_mode=‘cancat’
文档是这样定义的:https://keras.io/layers/containers/
add_node(layer, name, input=None, inputs=[], merge_mode='concat', concat_axis=-1, dot_axes=-1, create_output=False)
解释:Add a node in the graph. It can be connected to multiple inputs, which will first be merged into one tensor according to the mode specified.
另外,我也找到Graph对于多输入做merge的例子:https://github.com/cartopy/keras-0.3.3/blob/master/docs/templates/models.md
思考卷积&池化,选择3种window size的filters意义何在:不同ws的filter对每个单词提取的上下文范围不同,对应了不同的空间尺度空间,最后再组合起来。有点类似图像处理里,将二维图像分解到不同空间尺度上。这里将每个单词的上下文特征分解到3个尺度上,最后再拼接回来。当然也可以分解到更多空间尺度上。
========================================================================================================
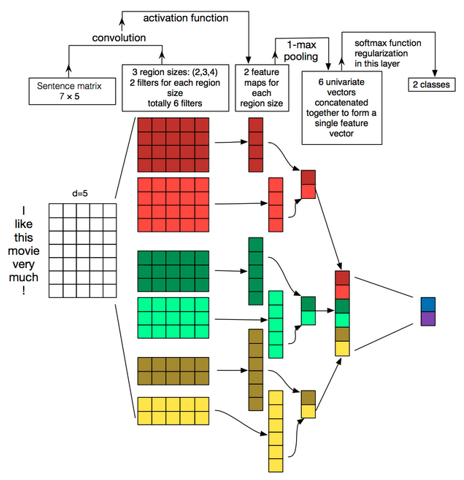
分割线内容写于这篇blog初步发表的一天后:选择3个不同window size的filter处理嵌入后的文本:卷积&池化(&flatten)之后再拼接,这是用CNN做NLP的基本操作,改写codes的时候,我只学过CNN做图像识别,后来学了点CNN做文本分类,恍然大悟,原来就是需要拼接的
========================================================================================================
3、两个版本的代码对比如下:
首先是keras0.3.3:
# coding: utf-8
'''
Created on Dec 8, 2015
@author: donghyun
'''
import numpy as np
np.random.seed(1337)
from keras.callbacks import EarlyStopping
from keras.layers.containers import Sequential
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.layers.core import Reshape, Flatten, Dropout, Dense
from keras.layers.embeddings import Embedding
from keras.models import Graph
from keras.preprocessing import sequence
output_dimesion = 50
vocab_size = 8000
dropout_rate = 0.2
emb_dim = 200
max_len = 300
nb_filters = 100
init_W = None
max_features = vocab_size
vanila_dimension = 200
projection_dimension = output_dimesion
filter_lengths = [3, 4, 5]
model = Graph()
print("Building Embedding Layer...")
'''Embedding Layer'''
model.add_input(name='input', input_shape=(max_len,), dtype=int)
if init_W is None:
model.add_node(Embedding(max_features, emb_dim, input_length=max_len), name='sentence_embeddings', input='input')
else:
self.model.add_node(Embedding(max_features, emb_dim, input_length=max_len, weights=[init_W / 20]), name='sentence_embeddings', input='input')
print("Building Convolution Layer & Max Pooling Layer...")
'''Convolution Layer & Max Pooling Layer'''
for i in filter_lengths:
model_internal = Sequential()
model_internal.add(Reshape(dims=(1, self.max_len, emb_dim), input_shape=(self.max_len, emb_dim)))
model_internal.add(Convolution2D(nb_filters, i, emb_dim, activation="relu"))
model_internal.add(MaxPooling2D(pool_size=(self.max_len - i + 1, 1)))
model_internal.add(Flatten())
model.add_node(model_internal, name='unit_' + str(i), input='sentence_embeddings')
# 以上for循环体内的代码要缩进
print("Building Fully Connect Layer & Dropout Layer...")
'''Fully Connect Layer'''
model.add_node(Dense(vanila_dimension, activation='tanh'), name='fully_connect', inputs=['unit_' + str(i) for i in filter_lengths])
# 这里的3个inputs实际是concat了在一起,变成3*100维,下面经过fc变成200维,再经过pj变成50维
# keras0.3.3文档中关于add_node,默认merge_mode=‘cancat’,https://keras.io/layers/containers/
'''Dropout Layer'''
model.add_node(Dropout(dropout_rate), name='dropout', input='fully_connect')
print("Building Projection Layer & Output Layer...")
'''Projection Layer & Output Layer'''
model.add_node(Dense(projection_dimension, activation='tanh'), name='projection', input='dropout')
# Output Layer
model.add_output(name='output', input='projection')
model.compile('rmsprop', {'output': 'mse'})
keras2.x:
import numpy as np
np.random.seed(1337)
from keras.callbacks import EarlyStopping
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.layers.core import Reshape, Flatten, Dropout
from keras.layers import Input, Embedding, Dense
from keras.models import Model, Sequential
from keras.preprocessing import sequence
output_dimesion = 50
vocab_size = 8000
dropout_rate = 0.2
emb_dim = 200
max_len = 300
nb_filters = 100
init_W = None
max_features = vocab_size
vanila_dimension = 200
projection_dimension = output_dimesion
filter_lengths = [3, 4, 5]
'''Input'''
doc_input = Input(shape=(max_len,), dtype='int32', name='doc_input')
print("Builded input...")
'''Embedding Layer'''
if init_W is None:
sentence_embeddings = Embedding(output_dim=emb_dim, input_dim=max_features, input_length=max_len, name='sentence_embeddings')(doc_input)
else:
sentence_embeddings = Embedding(output_dim=emb_dim, input_dim=max_features, input_length=max_len, weights=[init_W / 20], name='sentence_embeddings')(doc_input)
print("Builded Embedding Layer...")
'''Reshape Layer'''
reshape = Reshape(target_shape=(max_len, emb_dim, 1), name='reshape')(sentence_embeddings) # chanels last
print("Builded Reshape Layer...")
flatten_ = []
for i in filter_lengths:
model_internal = Sequential()
model_internal.add(Conv2D(nb_filters, (i, emb_dim), activation="relu", name='conv2d_' + str(i), input_shape=(self.max_len, emb_dim, 1)))
# chanels last,默认了strides=(1,1), padding='valid'
model_internal.add(MaxPooling2D(pool_size=(self.max_len - i + 1, 1), name='maxpool2d_' + str(i)))
model_internal.add(Flatten())
flatten = model_internal(reshape)
flatten_.append(flatten)
# 以上for循环体内的代码要缩进
'''Fully Connect Layer & Dropout Layer'''
fully_connect = Dense(vanila_dimension, activation='tanh', name='fully_connect')(concatenate(flatten_, axis=-1))
dropout = Dropout(dropout_rate, name='dropout')(fully_connect)
print("Builded Fully Connect Layer & Dropout Layer...")
'''Projection Layer & Output Layer'''
pj = Dense(projection_dimension, activation='tanh', name='output') # output layer
projection = pj(dropout)
print("Builded Projection Layer & Output Layer...")
# Compile Model: set inputs & outputs ...
model = Model(inputs=doc_input, outputs=projection)
model.compile(optimizer='rmsprop', loss='mse')
参考资料:
1、keras0.3.3文档关于model的部分:https://github.com/cartopy/keras-0.3.3/blob/master/docs/templates/models.md
(keras0.3.3的文档很难找,一开始找到的总是2.x的文档,后来baidu+google+bing找到了github上的这篇,目前还不会用github,据说很好找东西,用git??,值得研究)
介绍了keras0.x中用的两种模型,
2、keras2.x文档很好找,重点关注Models和各种Layers
用于NLP的CNN架构搬运:from keras0.x to keras2.x的更多相关文章
- 【深度学习篇】--神经网络中的池化层和CNN架构模型
一.前述 本文讲述池化层和经典神经网络中的架构模型. 二.池化Pooling 1.目标 降采样subsample,shrink(浓缩),减少计算负荷,减少内存使用,参数数量减少(也可防止过拟合)减少输 ...
- JWPL工具处理维基百科wikipedia数据用于NLP
JWPL处理维基百科数据用于NLP 处理zhwiki JWPL是一个Wikipedia处理工具,主要功能是将Wikipedia dump的文件经过处理.优化导入mysql数据库,用于NLP过程.以下以 ...
- CNN结构:用于检测的CNN结构进化-分离式方法
前言: 原文链接:基于CNN的目标检测发展过程 文章有大量修改,如有不适,请移步原文. 参考文章:图像的全局特征--用于目标检测 目标的检测和定位中一个很困难的问题是,如何从数以万计的候选 ...
- 深度学习与CV教程(10) | 轻量化CNN架构 (SqueezeNet,ShuffleNet,MobileNet等)
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/37 本文地址:http://www.showmeai.tech/article-det ...
- CNN结构:用于检测的CNN结构进化-结合式方法
原文链接:何恺明团队提出 Focal Loss,目标检测精度高达39.1AP,打破现有记录 呀 加入Facebook的何凯明继续优化检测CNN网络,arXiv 上发现了何恺明所在 FAIR 团 ...
- NLP用CNN分类Mnist,提取出来的特征训练SVM及Keras的使用(demo)
用CNN分类Mnist http://www.bubuko.com/infodetail-777299.html /DeepLearning Tutorials/keras_usage 提取出来的特征 ...
- 第九节课-CNN架构
2017-08-21 这次的课程比较偏向实际的运用,介绍了当前几种比较主流的CNN网络: 主要是AlexNet,GoogleNet, VGG, ResNet 需要把课后习题做了才能更好的理解.
- CNN结构:用于检测的CNN结构进化-一站式方法
有兴趣查看原文:YOLO详解 人眼能够快速的检测和识别视野内的物体,基于Maar的视觉理论,视觉先识别出局部显著性的区块比如边缘和角点,然后综合这些信息完成整体描述,人眼逆向工程最相像的是DPM模型. ...
- 转载 - CNN感受野(receptive-fields)RF
本文翻译自A guide to receptive field arithmetic for Convolutional Neural Networks(可能需要FQ才能访问),方便自己学习和参考.若 ...
随机推荐
- 行内元素和块级元素的具体区别是什么?行内元素的padding和margin可设置吗?
块级元素(block)特性: 总是独占一行,表现为另起一行开始,而且其后的元素也必须另起一行显示; 宽度(width).高度(height).内边距(padding)和外边距(margin)都可控制; ...
- spring注解一次 清除多个缓存
@Caching(evict = { @CacheEvict(value="cacheName",key="#info.id+'_baojia'",before ...
- 如何设计相对安全的cookie自动登录系统
很多网站登录的时候,都会有一个"记住我"功能,用户可以在限定时间段内免登录, 比如豆瓣.人人.新浪微博等都有这种设计.这种技术其实就是基于 cookie的自动登录, 用户登录的时候 ...
- mysql 左连接 右连接 内链接
一般所说的左连接,右连接是指左外连接,右外连接.做个简单的测试你看吧.先说左外连接和右外连接:[TEST1@orcl#16-12月-11] SQL>select * from t1;ID NAM ...
- 耍一把codegen,这样算懂编译么?
最近使用protobuf搭了些服务器,对protobuf的机制略感兴趣,所以研究了下. 大致分析没有什么复杂的 1 对定义的结构体生成消息封包协议 2 对定义的rpc函数生成接口定义 3 用户按pro ...
- Charles抓包工具安装与配置
在实际开发中,我们需要时常抓取线上的请求及数据,甚至是请求的html文档,js,css等静态文件来进行调试.在这里,我使用charles来进行以上操作.但是呢,charles需要进行一系列配置才能达到 ...
- ASP.NET Core Web 资源打包与压缩
本文将介绍使用的打包和压缩的优点,以及如何在ASP.NET Core应用程序中使用这些功能. 概述 在ASP.Net中可以使用打包与压缩这两种技术来提高Web应用程序页面加载的性能.通过减少从服务器请 ...
- Linux 安装依赖库
###安装依赖库###yum -y install rsync net-snmp syslog net-snmp-devel wget patch screen gcc gcc-c++ autocon ...
- BufferedWriterTest
public class BufferedWriterTest { public static void main(String[] args) { try { //创建一个FileWriter 对象 ...
- python编程快速上手之第4章实践项目参考答案
#!/usr/bin/env python3.5 # coding:utf-8 # 假定有一个列表,编写函数以一个列表值作为参数,返回一个字条串 # 该字符串包含所有表项,之间以逗号和空格分隔,并在最 ...