TensorBoard的使用(结合线性模型)
TensorBoard是TensorFlow 的可视化工具。主要为了更方便用户理解 TensorFlow 程序、调试与优化,用户可以用 TensorBoard 来展现 TensorFlow 图像,绘制图像生成的定量指标图以及附加数据。
TensorBoard 通过读取 TensorFlow 的事件文件来运行。TensorFlow 的事件文件包括了在 TensorFlow 运行中涉及到的主要数据,在运行计算图后,tensorflow会在当前文件夹下,生成一个log文件夹,所有的事件文件都会放在文件夹中,每次运行文件都会生成一个日志文件。tensorboard是通过运行这些日志文件把计算图过程可视化。
下面我们来看个简单例子:
import tensorflow as tf
with tf.Graph().as_default():
x=tf.placeholder(tf.float32,name='x')
y_true=tf.placeholder(tf.float32,name='y_true')
writer=tf.summary.FileWriter(logdir='logs',graph=tf.get_default_graph())
writer.close()
运行上面代码会在当前目录下生成一个logs的文件夹,然后我们可以通过tensorboard运行这个日志文件来展示计算图。
tensorboard --logdir=C:\Users\Administrator\PycharmProjects\untitled2\logs
其中tensorboard --logdir运行事件文件的命令行,C:\Users\Administrator\PycharmProjects\untitled2\logs为日志文件的路径
需要注意的是运行tensorboard命令时,需要先进入到tesorboard的安装文件夹下,或者已经在系统中设定好了环境变量
运行后会生成一段类似这样的代码TensorBoard 0.4.0rc3 at http://20170318-133753:6006 (Press CTRL+C to quit)
把其中http://20170318-133753:6006的地址复制到浏览器打开,就能进入tensorboard界面。
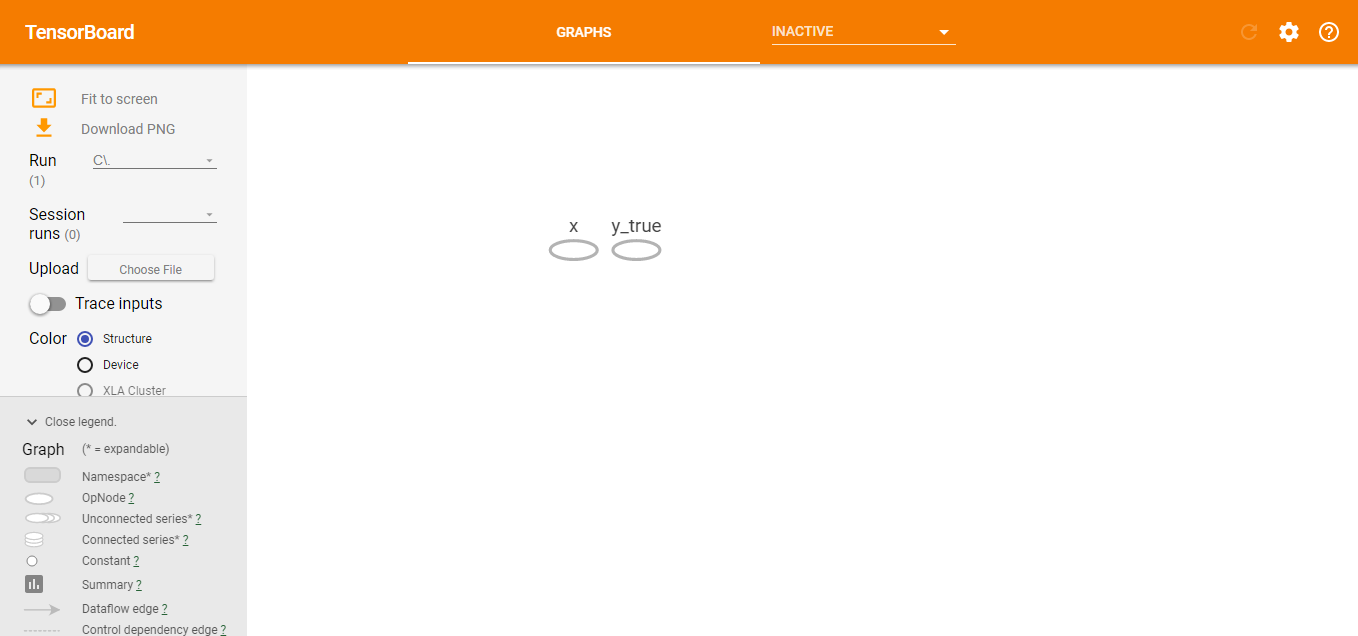
下面是简单线性模型代码和计算图
import tensorflow as tf
with tf.Graph().as_default():
#name_scope作用是给节点添加名称,以便生成简洁的tensorboard
with tf.name_scope('input'):
#添加占位符
x=tf.placeholder(tf.float32,name='x')
y_true=tf.placeholder(tf.float32,name='y_true')
with tf.name_scope('inference'):
#添加变量
w=tf.Variable(tf.zeros([1]),name='weight')
b = tf.Variable(tf.zeros([1]),name='bias')
#添加模型函数
y_pre=tf.add(tf.multiply(x,w),b)
#添加损失函数
loss_function=tf.reduce_mean(tf.pow(y_true-y_pre,2))/2
#梯度计算(learning_rate 是学习步长)
optimizer=tf.train.GradientDescentOptimizer(learning_rate=0.01)
#添加训练节点
trian=optimizer.minimize(loss_function)
#添加评估节点
envalue=tf.reduce_mean(tf.pow(y_true-y_pre,2))/2
#初始化变量和节点
init=tf.global_variables_initializer()
writer=tf.summary.FileWriter(logdir='logs',graph=tf.get_default_graph())
writer.close()
呈现的结果如下:

TensorBoard的使用(结合线性模型)的更多相关文章
- [TF] Architecture - Computational Graphs
阅读笔记: 仅希望对底层有一定必要的感性认识,包括一些基本核心概念. Here只关注Graph相关,因为对编程有益. TF – Kernels模块部分参见:https://mp.weixin.qq.c ...
- 机器学习笔记4-Tensorflow线性模型示例及TensorBoard的使用
前言 在上一篇中,我简单介绍了一下Tensorflow以及在本机及阿里云的PAI平台上跑通第一个示例的步骤.在本篇中我将稍微讲解一下几个基本概念以及Tensorflow的基础语法. 本文代码都是基于A ...
- tensorboard入门
Tensorboard tensorboard用以图形化展示我们的代码结构和图形化训练误差等,辅助优化程序 tensorboard实际上是tensorflow机器学习框架下的一个工具,需要先安装ten ...
- 广义线性模型(Generalized Linear Models)
前面的文章已经介绍了一个回归和一个分类的例子.在逻辑回归模型中我们假设: 在分类问题中我们假设: 他们都是广义线性模型中的一个例子,在理解广义线性模型之前需要先理解指数分布族. 指数分布族(The E ...
- SPSS数据分析—广义线性模型
我们前面介绍的一般线性模型.Logistic回归模型.对数线性模型.Poisson回归模型等,实际上均属于广义线性模型的范畴,广义 线性模型包含的范围非常广泛,原因在于其对于因变量.因变量的概率分布等 ...
- SPSS数据分析—对数线性模型
我们之前讲Logistic回归模型的时候说过,分类数据在使用卡方检验的时候,当分类过多或者每个类别的水平数过多时,单元格会划分的非常细,有可能会导致大量单元格频数很小甚至为0,并且卡方检验虽然可以分析 ...
- Tensorflow学习笔记3:TensorBoard可视化学习
TensorBoard简介 Tensorflow发布包中提供了TensorBoard,用于展示Tensorflow任务在计算过程中的Graph.定量指标图以及附加数据.大致的效果如下所示, Tenso ...
- Stanford大学机器学习公开课(四):牛顿法、指数分布族、广义线性模型
(一)牛顿法解最大似然估计 牛顿方法(Newton's Method)与梯度下降(Gradient Descent)方法的功能一样,都是对解空间进行搜索的方法.其基本思想如下: 对于一个函数f(x), ...
- SPSS数据分析—混合线性模型
之前介绍过的基于线性模型的方差分析,虽然扩展了方差分析的领域,但是并没有突破方差分析三个原有的假设条件,即正态性.方差齐性和独立性,这其中独立性要求较严格,我们知道方差分析的基本思想其实就是细分,将所 ...
随机推荐
- 》》初识移动端--rem
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <meta na ...
- Golang学习--TOML配置处理
上一篇文章中我们学会了使用包管理工具,这样我们就可以很方便的使用包管理工具来管理我们依赖的包. 配置工具的选择 但我们又遇到了一个问题,一个项目通常是有很多配置的,比如PHP的php.ini文件.Ng ...
- nyoj 123 士兵杀敌(四)【树状数组】+【插线问点】
树状数组有两种情况:插点问线和插线问点.这道题是插线问点. 由于树状数组最简单的作用是计算1~x的和,所以给出(a, b. c).表示(a,b)区间添加c, 那我们仅仅须要在a点原来的基础上添加c,然 ...
- jquery查找元素
一:查找元素 * 所有元素 element 该名称的所有元素(p,input) #id 拥有指定id属性的元素 .class 拥有所有指定class属性的元素 selector1,selector2 ...
- Android查缺补漏--Activity生命周期和启动模式
一.生命周期 onCreate():启动Activity时,首次创建Activity时回调. onRestart():再次启动Activity时回调. onStart():首次启动Activity时在 ...
- 从0开始做垂直O2O个性化推荐-以58到家美甲为例
从0开始做垂直O2O个性化推荐 上次以58转转为例,介绍了如何从0开始如何做互联网推荐产品(回复"推荐"阅读),58转转的宝贝为闲置物品,品类多种多样,要做统一的宝贝画像比较难,而 ...
- Java加密与解密笔记(二) 对称加密
前面的仅仅是做了编码或者摘要,下面看看真正的加密技术. DES public class DESUtil { static final String ALGORITHM = "DES&quo ...
- Tomcat配置(二):tomcat配置文件server.xml详解和部署简介
*/ .hljs { display: block; overflow-x: auto; padding: 0.5em; color: #333; background: #f8f8f8; } .hl ...
- 个推demo
官网文档更详细,这里是只做个测试 http://docs.getui.com/server/java/start/ 全部推送(针对app应用) public static final String a ...
- iOS10 相册权限
当我升级到Xcode8后,启动我的相机项目,直接crash,输出的日志如下: '2016-07-08 16:41:11.268943 project-name[362:56625] [MC] Syst ...