Python爬虫知识点二
一。request库
import json
import requests from io import BytesIO
#显示各种函数相当于api
# print(dir(requests)) url = 'http://www.baidu.com'
r = requests.get(url)
print(r.text)
print(r.status_code)
print(r.encoding)
结果:

# 传递参数:不如http://aaa.com?pageId=1&type=content
params = {'k1':'v1', 'k2':'v2'}
r = requests.get('http://httpbin.org/get', params)
print(r.url)
结果:

# 二进制数据
# r = requests.get('http://i-2.shouji56.com/2015/2/11/23dab5c5-336d-4686-9713-ec44d21958e3.jpg')
# image = Image.open(BytesIO(r.content))
# image.save('meinv.jpg')
# json处理
r = requests.get('https://github.com/timeline.json')
print(type(r.json))
print(r.text)
结果:

# 原始数据处理
# 流式数据写入
r = requests.get('http://i-2.shouji56.com/2015/2/11/23dab5c5-336d-4686-9713-ec44d21958e3.jpg', stream = True)
with open('meinv2.jpg', 'wb+') as f:
for chunk in r.iter_content(1024):
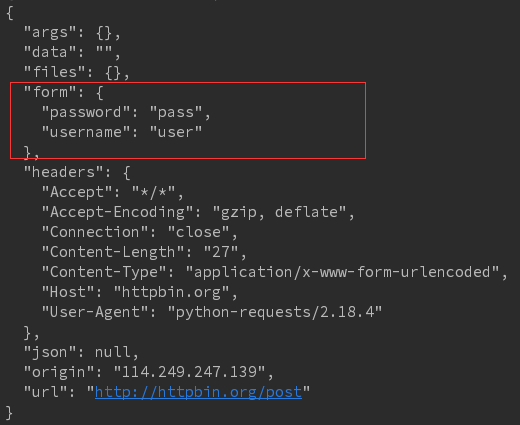
f.write(chunk) # 提交表单 form = {'username':'user', 'password':'pass'}
r = requests.post('http://httpbin.org/post', data = form)
print(r.text)
结果:参数以表单形式提交,所以参数放在form参数中
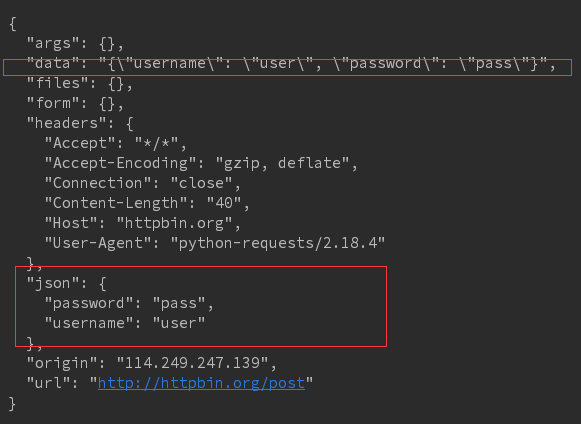
r = requests.post('http://httpbin.org/post', data = json.dumps(form))
print(r.text)
结果:参数不是以form表单提交的,所以放在json字段中
# cookie url = 'http://www.baidu.com'
r = requests.get(url)
cookies = r.cookies
#cookie实际上是一个字典
for k, v in cookies.get_dict().items():
print(k, v)
结果:cookie实际上是一个键值对

cookies = {'c1':'v1', 'c2': 'v2'}
r = requests.get('http://httpbin.org/cookies', cookies = cookies)
print(r.text)
结果:

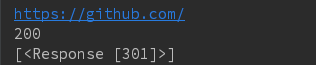
# 重定向和重定向历史
r = requests.head('http://github.com', allow_redirects = True)
print(r.url)
print(r.status_code)
print(r.history)
结果:通过301定向
# # 代理
#
# proxies = {'http': ',,,', 'https': '...'}
# r = requests.get('...', proxies = proxies)
二。BeautifulSoup库
html:举例如下
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
解析代码如下:
from bs4 import BeautifulSoup
soup = BeautifulSoup(open('test.html'))
#使html文本更加结构化
# print(soup.prettify())
# Tag
print(type(soup.title))
结果:bs4的一个类

print(soup.title.name)
print(soup.title)
结果如下:

# String print(type(soup.title.string))
print(soup.title.string)
结果如下:只显示标签里面内容

# Comment print(type(soup.a.string))
print(soup.a.string)
结果:显示注释中的内容,所以有时需要判断获取到的内容是不是注释

#
# '''
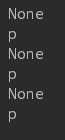
for item in soup.body.contents:
print(item.name) 结果:body下面有三个item
# CSS查询
print(soup.select('.sister'))
结果:样式选择器返回带有某个样式的所有内容 结果为一个list

print(soup.select('#link1'))
结果:ID选择器,选择ID等于link1的内容

print(soup.select('head > title'))
结果:

a_s = soup.select('a')
for a in a_s:
print(a)
结果:标签选择器,选择所有a标签的

持续更新中。。。。,欢迎大家关注我的公众号LHWorld.

Python爬虫知识点二的更多相关文章
- Python爬虫利器二之Beautiful Soup的用法
上一节我们介绍了正则表达式,它的内容其实还是蛮多的,如果一个正则匹配稍有差池,那可能程序就处在永久的循环之中,而且有的小伙伴们也对写正则表达式的写法用得不熟练,没关系,我们还有一个更强大的工具,叫Be ...
- python爬虫知识点详解
python爬虫知识点总结(一)库的安装 python爬虫知识点总结(二)爬虫的基本原理 python爬虫知识点总结(三)urllib库详解 python爬虫知识点总结(四)Requests库的基本使 ...
- 2.Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- 转 Python爬虫入门二之爬虫基础了解
静觅 » Python爬虫入门二之爬虫基础了解 2.浏览网页的过程 在用户浏览网页的过程中,我们可能会看到许多好看的图片,比如 http://image.baidu.com/ ,我们会看到几张的图片以 ...
- Python 爬虫入门(二)——爬取妹子图
Python 爬虫入门 听说你写代码没动力?本文就给你动力,爬取妹子图.如果这也没动力那就没救了. GitHub 地址: https://github.com/injetlee/Python/blob ...
- python 爬虫(二)
python 爬虫 Advanced HTML Parsing 1. 通过属性查找标签:基本上在每一个网站上都有stylesheets,针对于不同的标签会有不同的css类于之向对应在我们看到的标签可能 ...
随机推荐
- 《RabbitMQ Tutorial》译文 第 4 章 路由
原文来自 RabbitMQ 英文官网的教程(4.Routing),其示例代码采用了 .NET C# 语言. In the previous tutorial we built a simple log ...
- 使用背景图修改radio、checkbox样式
如果觉得设置样式太麻烦,或者页面上选中的样式太复杂,也可以用背景图去修改样式<div class=""> <label><input type=&qu ...
- sqlserver2005公布与订阅配置步骤
1,新建公布 前提条件:第一要调通网络,在sqlserver configuration manager 中选择mssqlserver的协议把named pipes改为启用.第二要建立一个目录D:\b ...
- UVA - 11082 Matrix Decompressing(最大流+行列模型)
题目大意:给出一个R行C列的矩阵,如今给出他的前1-R行和 && 前1-C列和,问这个矩阵原来是如何的,要求每一个元素大小在1-20之间 解题思路:将每一行连接到超级源点,容量为该行的 ...
- 前端优化之动画为什么要尽量用css3代替js
导致JavaScript效率低的两大原因:操作DOM和使用页面动画.通常我们会通过频繁的操作 DOM的CSS来实现视觉上的动画效果,导致js效率低的两个因素都包括在内了在频繁的操作DOM和CSS时,浏 ...
- 学习customEvent
title: 认真学习customEvent tags: DOM date: 2017-7-22 23:20:57 --- 最近要实现一个模拟的select元素组件,所以好好看了这个自定义事件api, ...
- time模块整理
time模块中包含的方法 time() -- 返回当前系统的时间戳clock() -- 在UNIX系统上,它返回的是"进程时间",它是用秒表示的浮点数(时间戳). 而在WINDOW ...
- 字符设备 Vs. 块设备 Character Device Vs. Block Device
字符设备是指驱动发送/接受单个字符(例如字节)的设备. 块设备是指驱动发送/接受整块数据(例如512个字节为一个块)的设备. 常见的字符设备:串口,并口,声卡. 常见的块设备:硬盘(最小读取单位为扇区 ...
- 设备指纹识别之User Agent 解析
设备指纹识别之User Agent 解析User Agent 解析 zoerywzhou@163.com http://www.cnblogs.com/swje/ 作者:Zhouwan 2017-4- ...
- bootstrap表格固定表头,表格内容滚动条滚动显示
直接贴代码--- <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> < ...