JAVA提高十三:Hashtable&Properties深入分析
最近因为一些琐碎的事情,导致一直没时间写博客,正好今天需求开发完的早,所以趁早写下本文,本文主要学习的是Hashtable的分析,因为上面一篇文章研究的是HashMap,而Hashtable和HashMap之间存在相似处,是面试中经常会问到的一个问题,因此进行下分析;而之所以加上Properties,是因为Hashtable 在实际生活中我们用的并不多,但是它的子类Properties 使用的频率相对还是不低的,因此也一起介绍下。好了,言归正传,接下来开始分析。
一、Hashtable 的定义
我们翻看下源码中对Hashtable的定义如下:
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
从中可以看出HashTable继承Dictionary类,实现Map接口。其中Dictionary类是任何可将键映射到相应值的类(如 Hashtable)的抽象父类。每个键和每个值都是一个对象。在任何一个 Dictionary 对象中,每个键至多与一个值相关联。Map是"key-value键值对"接口。
HashTable采用"拉链法"实现哈希表,它定义了几个重要的参数:table、count、threshold、loadFactor、modCount。table:为一个Entry[]数组类型,Entry代表了“拉链”的节点,每一个Entry代表了一个键值对,哈希表的"key-value键值对"都是存储在Entry数组中的。
count:HashTable的大小,注意这个大小并不是HashTable的容器大小,而是他所包含Entry键值对的数量。
threshold:Hashtable的阈值,用于判断是否需要调整Hashtable的容量。threshold的值="容量*加载因子"。
loadFactor:加载因子。 modCount:用来实现“fail-fast”机制的(也就是快速失败)。所谓快速失败就是在并发集合中,其进行迭代操作时,若有其他线程对其进行结构性的修改,这时迭代器会立马感知到,并且立即抛出ConcurrentModificationException异常,而不是等到迭代完成之后才告诉你。
Hashtable 和Map 之间关系图:

Hashtable继承于Dictionary类,实现了Map接口。Map是"key-value键值对"接口,Dictionary是声明了操作"键值对"函数接口的抽象类。
二、构造方法
// 默认构造函数。
public Hashtable() // 指定“容量大小”的构造函数
public Hashtable(int initialCapacity) // 指定“容量大小”和“加载因子”的构造函数
public Hashtable(int initialCapacity, float loadFactor) // 包含“子Map”的构造函数
public Hashtable(Map<? extends K, ? extends V> t)
上述构造方法中,最核心的其实就是第三个,因为无论是无参构造还是初始化容量构造最后都是调用的第三个,因此有必要看下第三个方法的源码:
public Hashtable(int initialCapacity, float loadFactor)
{
//验证初始容量
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
//验证加载因子
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor); if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
//初始化table,获得大小为initialCapacity的table数组
table = new Entry[initialCapacity];
////计算阀值
threshold = (int)(initialCapacity * loadFactor);
}
Hashtable 方法:
synchronized void clear()
synchronized Object clone()
boolean contains(Object value)
synchronized boolean containsKey(Object key)
synchronized boolean containsValue(Object value)
synchronized Enumeration<V> elements()
synchronized Set<Entry<K, V>> entrySet()
synchronized boolean equals(Object object)
synchronized V get(Object key)
synchronized int hashCode()
synchronized boolean isEmpty()
synchronized Set<K> keySet()
synchronized Enumeration<K> keys()
synchronized V put(K key, V value)
synchronized void putAll(Map<? extends K, ? extends V> map)
synchronized V remove(Object key)
synchronized int size()
synchronized String toString()
synchronized Collection<V> values()
三、主要方法分析
HashTable的API对外提供了许多方法,这些方法能够很好帮助我们操作HashTable【如上所示】,但是这里主要介绍的是两个最根本的方法:put、get。
首先我们先看put方法:将指定 key 映射到此哈希表中的指定 value。注意这里键key和值value都不可为空。
public synchronized V put(K key, V value) {
// 确保value不为null
if (value == null) {
throw new NullPointerException();
}
/*
* 确保key在table[]是不重复的
* 处理过程:
* 1、计算key的hash值,确认在table[]中的索引位置
* 2、迭代index索引位置,如果该位置处的链表中存在一个一样的key,则替换其value,返回旧值
*/
Entry tab[] = table;
int hash = hash(key); //计算key的hash值
int index = (hash & 0x7FFFFFFF) % tab.length; ////迭代,寻找该key,替换
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
modCount++;
if (count >= threshold) { //如果容器中的元素数量已经达到阀值,则进行扩容操作
rehash();
tab = table;
hash = hash(key);
index = (hash & 0x7FFFFFFF) % tab.length;
}
// 在索引位置处插入一个新的节点
Entry<K,V> e = tab[index];
tab[index] = new Entry<>(hash, key, value, e);
//容器中元素+1
count++;
return null;
}
put方法的整个处理流程是:计算key的hash值,根据hash值获得key在table数组中的索引位置,然后迭代该key处的Entry链表,若该链表中存在一个这个的key对象,那么就直接替换其value值即可,否则在将改key-value节点插入该index索引位置处。如下:假设我们现在Hashtable的容量为5,已经存在了(5,5),(13,13),(16,16),(17,17),(21,21)这 5 个键值对,目前他们在Hashtable中的位置如下:

现在,我们插入一个新的键值对,put(16,22),假设key=16的索引为1.但现在索引1的位置有两个Entry了,所以程序会对链表进行迭代。迭代的过程中,发现其中有一个Entry的key和我们要插入的键值对的key相同,所以现在会做的工作就是将newValue=22替换oldValue=16,然后返回oldValue=16.

然后我们现在再插入一个,put(33,33),key=33的索引为3,并且在链表中也不存在key=33的Entry,所以将该节点插入链表的第一个位置。

在HashTabled的put方法中有两个地方需要注意:
1、HashTable的扩容操作,在put方法中,如果需要向table[]中添加Entry元素,会首先进行容量校验,如果容量已经达到了阀值,HashTable就会进行扩容处理rehash(),如下:
protected void rehash() {
int oldCapacity = table.length;
//元素
Entry<K,V>[] oldMap = table;
//新容量=旧容量 * 2 + 1
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
return;
newCapacity = MAX_ARRAY_SIZE;
}
//新建一个size = newCapacity 的HashTable
Entry<K,V>[] newMap = new Entry[];
modCount++;
//重新计算阀值
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
//重新计算hashSeed
boolean rehash = initHashSeedAsNeeded(newCapacity);
table = newMap;
//将原来的元素拷贝到新的HashTable中
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
if (rehash) {
e.hash = hash(e.key);
}
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = newMap[index];
newMap[index] = e;
}
}
}
在这个rehash()方法中我们可以看到容量扩大两倍+1,同时需要将原来HashTable中的元素一一复制到新的HashTable中,这个过程是比较消耗时间的,同时还需要重新计算hashSeed的,毕竟容量已经变了。这里对阀值啰嗦一下:比如初始值11、加载因子默认0.75,那么这个时候阀值threshold=8,当容器中的元素达到8时,HashTable进行一次扩容操作,容量 = 8 * 2 + 1 =17,而阀值threshold=17*0.75 = 13,当容器元素再一次达到阀值时,HashTable还会进行扩容操作,一次类推。
2、在计算索引位置index时,HashTable进行了一个与运算过程(hash & 0x7FFFFFFF),为什么需要做一步操作,这么做有什么好处?
这是因为在计算hash值得时候可能是负数因此采用了和0X7FFFFFFF相与的操作保证为正数,这个涉及到计算机的二进制数存放正数负数是如何存放的一个逻辑基础知识,正数很容易,负数的存放是采用负数的绝对值取反得到反码然后+1 得到补码然后进行的存放,因此和0X7FFFFFFF相与可保证只改变符号位而不改变其它位。
相关基础知识可以参考:
负数的二进制表示方法:http://www.360doc.com/content/12/0801/17/6828497_227700914.shtml
Java 8 种数据类型:http://blog.csdn.net/never_cxb/article/details/47204485
Java位运算符及二进制常识:http://blog.csdn.net/coffeelifelau/article/details/52433653
get方法
相比较于 put 方法,get 方法则简单很多。其过程就是首先通过 hash()方法求得 key 的哈希值,然后根据 hash 值得到 index 索引(上述两步所用的算法与 put 方法都相同)。然后迭代链表,返回匹配的 key 的对应的 value;找不到则返回 null。
public synchronized V get(Object key) {
Entry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
return null;
}
Hashtable 遍历方式
//1、使用keys()
Enumeration<String> en1 = table.keys();
while(en1.hasMoreElements()) {
en1.nextElement();
} //2、使用elements()
Enumeration<String> en2 = table.elements();
while(en2.hasMoreElements()) {
en2.nextElement();
} //3、使用keySet()
Iterator<String> it1 = table.keySet().iterator();
while(it1.hasNext()) {
it1.next();
} //4、使用entrySet()
Iterator<Entry<String, String>> it2 = table.entrySet().iterator();
while(it2.hasNext()) {
it2.next();
}
四、HashTable与HashMap的区别
HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。
1.HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
2.HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
3.另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
4.由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
HashMap不能保证随着时间的推移Map中的元素次序是不变的。
我们能否让HashMap同步?
HashMap可以通过下面的语句进行同步:Map m = Collections.synchronizeMap(hashMap);
结论:
Hashtable和HashMap有几个主要的不同:线程安全以及速度。仅在你需要完全的线程安全的时候使用Hashtable,而如果你使用Java 5或以上的话,请使用ConcurrentHashMap。
五、Properties分析
java.util
类 Properties
java.lang.Object
java.util.Dictionary<K,V>
java.util.Hashtable<Object,Object>
java.util.Properties
可以看到它是Hashtable的一个子类,是一个使用比父类使用更多的类,Properties类表示了一个持久的属性集,它是在一个文件中存储键值对儿的,其中键值对儿以等号分隔。Properties可保存在流中或从流中加载。属性列表中的每个键及其所对应的值都是字符串。Properties类是线程安全的:多个线程可以共享单个Properties对象而无需进行外部同步。一组属性示例:
foo=bar
fu=baz
一个属性列表可包含另一个属性列表作为它的“默认值”;如果未能在原有的属性列表中搜索到属性键,则搜索第二个属性列表。
如果在“不安全”的 Properties 对象(即包含非 String 的键或值)上调用 store 或 save 方法,则该调用将失败。类似地,如果在“不安全”的 Properties 对象(即包含非 String 的键)上调用 propertyNames 或 list 方法,则该调用将失败。
除了输入/输出流使用 ISO 8859-1 字符编码外,load(InputStream) / store(OutputStream, String)方法与 load(Reader)/store(Writer, String)对的工作方式完全相同。
loadFromXML(InputStream)和 storeToXML(OutputStream, String, String)方法按简单的 XML 格式加载和存储属性。默认使用 UTF-8 字符编码,但如果需要,可以指定某种特定的编码。XML 属性文档具有以下 DOCTYPE 声明:
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
一下列出了Properties的方法摘要,有关每个方法的详细使用情况,请参看API:
http://www.apihome.cn/api/java/Properties.html

示例练习一:如何装载属性文件并列出它当前的一组键和值。
思路:传递属性文件的输入流InputStream给load()方法,会将改属性文件中的每个键值对儿添加到Properties实例中;然后条用list()列出所有属性或者使用getProperty()获取单独的属性。(注意 list() 方法的输出中键-值对的顺序与它们在输入文件中的顺序不一样。 Properties 类在一个散列表(hashtable,事实上是一个 Hashtable 子类)中储存一组键-值对,所以不能保证顺序。 )
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.util.Properties; public class PropertiesTest { public static void main(String[] args) {
Properties properties = new Properties();
try {
properties.load(new FileInputStream("test.properties"));//加载属性文件
properties.list(System.out);//将属性文件中的键值对儿打印到控制台
properties.getProperty("foo");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
} }
示例练习二:如何装载XML版本的属性文件并列出它当前的一组键和值。(只有装载方法有差异,其余完全相同load(),loadFromXML())
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.util.Properties; public class PropertiesTest { public static void main(String[] args) {
Properties properties = new Properties();
try {
properties.loadFromXML(new FileInputStream("test.xml"));//加载属性文件
properties.list(System.out);//将属性文件中的键值对儿打印到控制台
properties.getProperty("foo");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
} }
示例练习三:如何将文件保存到属性文件中?
import java.util.*;
import java.io.*; public class StoreXML {
public static void main(String args[]) throws Exception {
Properties prop = new Properties();
prop.setProperty("one-two", "buckle my shoe");
prop.setProperty("three-four", "shut the door");
prop.setProperty("five-six", "pick up sticks");
prop.setProperty("seven-eight", "lay them straight");
prop.setProperty("nine-ten", "a big, fat hen");
prop.storeToXML(new FileOutputStream("test.xml"), "saveXML");//将键值对儿保存到XML文件中
prop.store(new FileOutputStream("test.properties"), "saveProperties");//将键值对儿保存到普通的属性文件中
fos.close();
}
}
将键值对儿保存到XML文件中的输出结果如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>Rhyme</comment>
<entry key="seven-eight">lay them straight</entry>
<entry key="five-six">pick up sticks</entry>
<entry key="nine-ten">a big, fat hen</entry>
<entry key="three-four">shut the door</entry>
<entry key="one-two">buckle my shoe</entry>
</properties>
将键值对儿保存到普通的属性文件中输出结果如下:
one-two=buckle my shoe
three-four=shut the door
five-six=pick up sticks
seven-eight=lay them straight
nine-ten=a big, fat hen
注意:从一个XML文件中装载一组属性,其DTD文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<!-- DTD for properties -->
<!ELEMENT properties ( comment?, entry* ) >
<!ATTLIST properties version CDATA #FIXED "1.0">
<!ELEMENT comment (#PCDATA) >
<!ELEMENT entry (#PCDATA) >
<!ATTLIST entry key CDATA #REQUIRED>
在外围 <properties> 标签中包装的是一个 <comment> 标签,后面是任意数量的 <entry>标签。对每一个 <entry> 标签,有一个键属性,输入的内容就是它的值。
注意点:路径问题,如下:
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.Properties; /**
* 使用Properties读取配置文件
* 资源配置文件:
* 使用相对与绝对路径读取
* load(InputStream inStream)
load(Reader reader)
loadFromXML(InputStream in)
* @author Administrator
*
*/
public class Demo03 { /**
* @param args
* @throws IOException
* @throws FileNotFoundException
*/
public static void main(String[] args) throws FileNotFoundException, IOException {
Properties pro=new Properties();
//读取 绝对路径
//pro.load(new FileReader("e:/others/db.properties"));
//读取 相对路径
pro.load(new FileReader("src/com/bjsxt/others/pro/db.properties"));
System.out.println(pro.getProperty("user", "bjsxt"));
} }
import java.io.IOException;
import java.util.Properties; /**
* 使用类相对路径读取配置文件
* bin
* @author Administrator
*
*/
public class Demo04 { /**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
Properties pro =new Properties();
//类相对路径的 / bin
//pro.load(Demo04.class.getResourceAsStream("/com/bjsxt/others/pro/db.properties"));
//"" bin
pro.load(Thread.currentThread().getContextClassLoader().getResourceAsStream("com/bjsxt/others/pro/db.properties"));
System.out.println(pro.getProperty("user", "bjsxt"));
} }
关于类路径需要注意一下;举个例子:
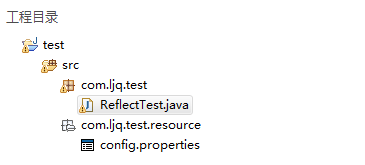
import java.io.FileInputStream;
import java.io.InputStream;
import java.util.Collection;
import java.util.Properties; /**
* 使用配置文件读取调用者的类
*
* @author jiqinlin
*
*/
public class ReflectTest {
public static void main(String[] args) throws Exception{
//使用绝对路径,否则无法读取config.properties
//InputStream inStream=new FileInputStream("F:\\android\\test\\src\\com\\ljq\\test\\resource\\config.properties"); //ReflectTest.class.getClassLoader().getResourceAsStream(String path): 默认则是从ClassPath根下获取,path不能以’/'开头,最终是由ClassLoader获取资源。
//InputStream inStream = ReflectTest.class.getClassLoader().getResourceAsStream("com/ljq/test/resource/config.properties"); // ReflectTest.class.getResourceAsStream(String path): path不以’/'开头时默认是从此类所在的包下取资源,以’/'开头则是从ClassPath根下获取。
//其只是通过path构造一个绝对路径,最终还是由ClassLoader获取资源。
//InputStream inStream = ReflectTest.class.getResourceAsStream("/com/ljq/test/resource/config.properties"); //config.properties配置文件所在目录是ReflectTest类所在子目录,才可以;否则报空指针异常
InputStream inStream = ReflectTest.class.getResourceAsStream("resource/config.properties"); Properties props=new Properties();
props.load(inStream);
inStream.close(); String className=props.getProperty("className");
Collection collection=(Collection)Class.forName(className).newInstance();
collection.add("123");
System.out.println("size="+collection.size()); //size=1
}
}
config.properties配置文件
className=java.util.HashSet
getResourceAsStream用法大致有以下几种:
第一:要加载的文件和.class文件在同一目录下,例如:com.ljq.test目录下有类ReflectTest.class,同时有资源文件config.properties 那么,应该有如下代码:
ReflectTest.class.getResourceAsStream("config.properties"); 第二:在ReflectTest.class目录的子目录下,例如:com.ljq.test下有类ReflectTest.class,同时在com.ljq.test.resource目录下有资源文件config.properties 那么,应该有如下代码:
ReflectTest.class.getResourceAsStream("resource/config.properties"); 第三:不在ReflectTest.class目录下,也不在子目录下,例如:com.ljq.test下有类ReflectTest.class ,同时在com.ljq.resource目录下有资源文件config.properties 那么,应该有如下代码:
ReflectTest.class.getResourceAsStream("/com/ljq/resource/config.properties"); 总结一下,可能只是两种写法 第一:前面有 “/” ,“/”代表了工程的根目录,例如工程名叫做test,“/”代表了test
ReflectTest.class.getResourceAsStream("/com/ljq/resource/config.properties"); 第二:前面没有 “/” ,代表当前类的目录
ReflectTest.class.getResourceAsStream("config.properties");
ReflectTest.class.getResourceAsStream("resource/config.properties"); 最后,总结
getResourceAsStream读取的文件路径只局限在工程的源文件夹中,包括在工程src根目录下,以及类包里面任何位置,但是如果配置文件路径是在除了源文件夹之外的其他文件夹中时,该方法是用不了的。
Properties获取数据乱码解决
1.原因
Properties调用load(InputStream)时,读取文件时使用的默认编码为ISO-8859-1;当我们将中文放入到properties文件中,通过getProperty(key)获取值时,取到得数据是ISO-8859-1格式的,但是ISO-8859-1是不能识别中文的。
2.解决方法
通过getProperty()获取的数据data既然是ISO-8859-1编码的,就通过data.getByte(“iso-8859-1”)获取获取,使用new String(data.getByte(“iso-8859-1”),”UTF-8”)进行转换。当然properties文件的编码类型需要和new String(Byte[],charset)中的第二个参数的编码类型相同。
参考资料:
http://wiki.jikexueyuan.com/project/java-collection
http://blog.csdn.net/chenssy/article/details/22896871
http://www.cnblogs.com/linjiqin
JAVA提高十三:Hashtable&Properties深入分析的更多相关文章
- java提高篇---HashTable
在java中与有两个类都提供了一个多种用途的hashTable机制,他们都可以将可以key和value结合起来构成键值对通过put(key,value)方法保存起来,然后通过get(key)方法获取相 ...
- JAVA提高十:ArrayList 深入分析
前面一章节,我们介绍了集合的类图,那么本节将学习Collection 接口中最常用的子类ArrayList类,本章分为下面几部分讲解(说明本章采用的JDK1.6源码进行分析,因为个人认为虽然JDK1. ...
- JAVA提高十一:LinkedList深入分析
上一节,我们学习了ArrayList 类,本节我们来学习一下LinkedList,LinkedList相对ArrayList而言其使用频率并不是很高,因为其访问元素的性能相对于ArrayList而言比 ...
- Java提高十七:TreeSet 深入分析
前一篇我们分析了TreeMap,接下来我们分析TreeSet,比较有意思的地方是,似乎有Map和Set的地方,Set几乎都成了Map的一个马甲.此话怎讲呢?在前面一篇讨论HashMap和HashSet ...
- Java提高合集(转载)
转载自:http://www.cnblogs.com/pony1223/p/7643842.html Java提高十五:容器元素比较Comparable&Comparator深入分析 JAVA ...
- JAVA提高十九:WeakHashMap&EnumMap&LinkedHashMap&LinkedHashSet深入分析
因为最近工作太忙了,连续的晚上支撑和上班,因此没有精力来写下这篇博客,今天上午正好有一点空,因此来复习一下不太常用的集合体系大家族中的几个类:WeakHashMap&EnumMap&L ...
- Java提高(二)---- HashTable
阅读博客 java提高篇(二五)—–HashTable 这篇博客由chenssy 发表与2014年4月,基于源码是jdk1.7 ========================== 本文针对jdk1. ...
- Java提高篇(二六)-----hashCode
在前面三篇博文中LZ讲解了(HashMap.HashSet.HashTable),在其中LZ不断地讲解他们的put和get方法,在这两个方法中计算key的hashCode应该是最重要也是最 ...
- Java提高篇(三三)-----Map总结
在前面LZ详细介绍了HashMap.HashTable.TreeMap的实现方法,从数据结构.实现原理.源码分析三个方面进行阐述,对这个三个类应该有了比较清晰的了解,下面LZ就Map做一个简单的总结. ...
随机推荐
- 让asp.net网站支持多语言,使用资源文件
<%@ Page Language="C#" AutoEventWireup="true" CodeFile="test.aspx.cs&quo ...
- rewrap-ajax.js插件
很久没有动手写技术的文章,这个过程中间一直在写日记,生活点滴的记录替代了技术文章的编写,可以看出以往的内心是激情或烈火,现在是... 最近写了一个JS插件,用圈内的话说叫造了个轮子,造的好与不好都不是 ...
- Python学习笔记(四)
Python学习笔记(四) 作业讲解 编码和解码 1. 作业讲解 重复代码瘦身 # 定义地图 nav = {'省略'} # 现在所处的层 current_layer = nav # 记录你去过的地方 ...
- 【ASP.NET MVC 学习笔记】- 17 Model验证
本文参考:http://www.cnblogs.com/willick/p/3434483.html 1.Model验证用于在实际项目中对用户提交的表单的信息进行验证,MVC对其提供了很好的支持. 2 ...
- iOS 通讯录空格
iOS 通讯录联系人出现 ASCII 码值为 160 的空格 NOTE: 这里的"空格"是指 在通讯录中取出的联系人中带有特殊空格 带有特殊空格的字符串 " ...
- LeetCode 106. Construct Binary Tree from Inorder and Postorder Traversal (用中序和后序树遍历来建立二叉树)
Given inorder and postorder traversal of a tree, construct the binary tree. Note:You may assume that ...
- Android开发中的OpenCV霍夫直线检测(Imgproc.HoughLines()&Imgproc.HoughLinesP())
本文为作者原创,转载请注明出处(http://www.cnblogs.com/mar-q/)by 负赑屃 //2017-04-21更新: 很多网友希望能得到源码,由于在公司做的,所以不太方便传出来 ...
- 关于在Python下安装布隆过滤器(bloomfilter)的方法
由于在爬虫代码中需要实现信息的去重功能,所以需借助bloomfilter,在看完各种博客后发现没有安装,这就尴尬了,不会连门都找不到吧.那就安装呗,各种错误,查看官方文档:http://axiak.g ...
- 【前端GUI】——网站设计的重要知识点总结&思维导图(一)
前言:网页美术设计具有四大特点,分别为交互性.整合性.多维性以及动态性.完整的网页设计既需要试听元素,也需要版式设计,以求有效的传达信息.在设计的时候,设计者要学会利用框架,也要学会打破框架. 一.优 ...
- HDU X mod f(x)(题解注释)
X mod f(x) Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total ...