Java爬虫框架WebMagic——入门(爬取列表类网站文章)
初学爬虫,WebMagic作为一个Java开发的爬虫框架很容易上手,下面就通过一个简单的小例子来看一下。
WebMagic框架简介
WebMagic框架包含四个组件,PageProcessor、Scheduler、Downloader和Pipeline。
这四大组件对应爬虫生命周期中的处理、管理、下载和持久化等功能。
这四个组件都是Spider中的属性,爬虫框架通过Spider启动和管理。
WebMagic总体架构图如下:
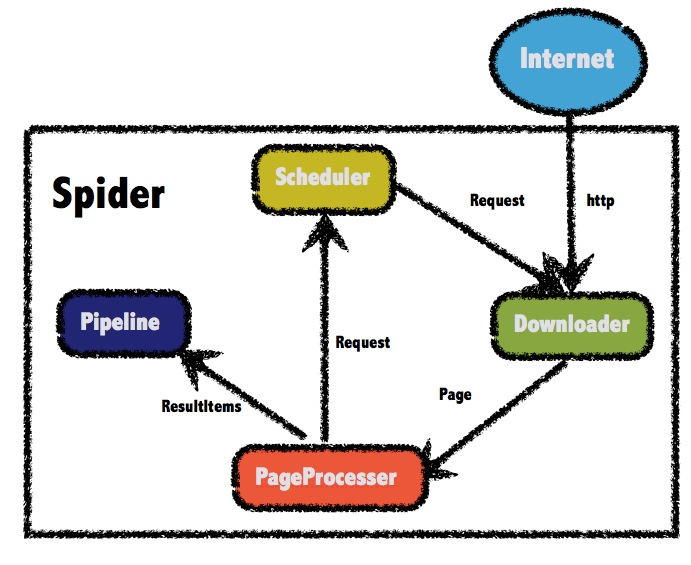
四大组件
PageProcessor 负责解析页面,抽取有用信息,以及发现新的链接。需要自己定义。
Scheduler 负责管理待抓取的URL,以及一些去重的工作。一般无需自己定制Scheduler。
Pipeline 负责抽取结果的处理,包括计算、持久化到文件、数据库等。
Downloader 负责从互联网上下载页面,以便后续处理。一般无需自己实现。
用于数据流转的对象
Request 是对URL地址的一层封装,一个Request对应一个URL地址。
Page 代表了从Downloader下载到的一个页面——可能是HTML,也可能是JSON或者其他文本格式的内容。
ResultItems 相当于一个Map,它保存PageProcessor处理的结果,供Pipeline使用。
环境配置
使用Maven来添加依赖的jar包。
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
或者直接摸我下载。
添加完jar包就完成了所有准备工作,是不是很简单。
下面来测试一下。
package edu.heu.spider; import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.processor.PageProcessor; /**
* @ClassName: MyCnblogsSpider
* @author LJH
* @date 2017年11月26日 下午4:41:40
*/
public class MyCnblogsSpider implements PageProcessor { private Site site = Site.me().setRetryTimes(3).setSleepTime(100); public Site getSite() {
return site;
} public void process(Page page) {
if (!page.getUrl().regex("http://www.cnblogs.com/[a-z 0-9 -]+/p/[0-9]{7}.html").match()) {
page.addTargetRequests(
page.getHtml().xpath("//*[@id=\"mainContent\"]/div/div/div[@class=\"postTitle\"]/a/@href").all());
} else {
page.putField(page.getHtml().xpath("//*[@id=\"cb_post_title_url\"]/text()").toString(),
page.getHtml().xpath("//*[@id=\"cb_post_title_url\"]/@href").toString());
}
}
public static void main(String[] args) {
Spider.create(new MyCnblogsSpider()).addUrl("http://www.cnblogs.com/justcooooode/")
.addPipeline(new ConsolePipeline()).run();
}
}
输出结果:
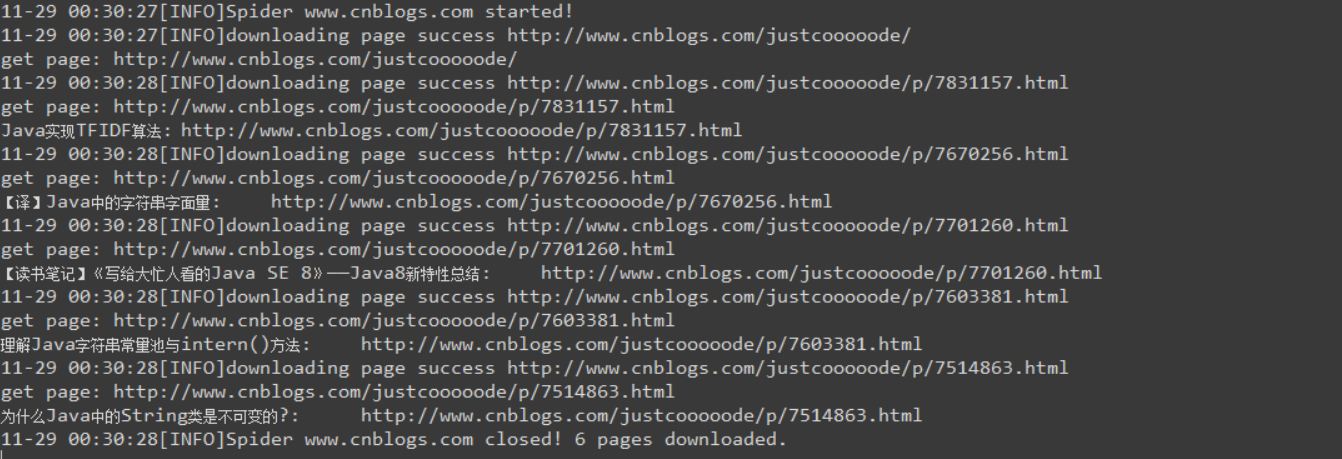
如果你和我一样之前没有用过log4j,可能会出现下面的警告:

这是因为少了配置文件,在resource目录下新建log4j.properties文件,将下面配置信息粘贴进去即可。
目录可以定义成你自己的文件夹。
# 全局日志级别设定 ,file
log4j.rootLogger=INFO, stdout, file # 自定义包路径LOG级别
log4j.logger.org.quartz=WARN, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{MM-dd HH:mm:ss}[%p]%m%n # Output to the File
log4j.appender.file=org.apache.log4j.FileAppender
log4j.appender.file.File=D:\\MyEclipse2017Workspaces\\webmagic\\webmagic.log
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%n%-d{MM-dd HH:mm:ss}-%C.%M()%n[%p]%m%n
现在试一下,没有警告了吧
Java爬虫框架WebMagic——入门(爬取列表类网站文章)的更多相关文章
- Java爬虫框架WebMagic入门——爬取列表类网站文章
初学爬虫,WebMagic作为一个Java开发的爬虫框架很容易上手,下面就通过一个简单的小例子来看一下. WebMagic框架简介 WebMagic框架包含四个组件,PageProcessor.Sch ...
- 爬虫框架Scrapy入门——爬取acg12某页面
1.安装1.1自行安装python3环境1.2ide使用pycharm1.3安装scrapy框架2.入门案例2.1新建项目工程2.2配置settings文件2.3新建爬虫app新建app将start_ ...
- JAVA 爬虫框架webmagic 初步使用Demo
一想到做爬虫大家第一个想到的语言一定是python,毕竟python比方便,而且最近也非常的火爆,但是python有一个全局锁的概念新能有瓶颈,所以用java还是比较牛逼的, webmagic 官网 ...
- pyspider爬虫框架webui简介-爬取阿里招聘信息
命令行输入pyspider开启pyspider 浏览器打开http://localhost:5000/ group表示组名,几个项目可以同一个组名,方便管理,当组名修改为delete时,项目会在一天后 ...
- java爬虫系列第二讲-爬取最新动作电影《海王》迅雷下载地址
1. 目标 使用webmagic爬取动作电影列表信息 爬取电影<海王>详细信息[电影名称.电影迅雷下载地址列表] 2. 爬取最新动作片列表 获取电影列表页面数据来源地址 访问http:// ...
- java爬虫框架webmagic学习(一)
1. 爬虫的分类:分布式和单机 分布式主要就是apache的nutch框架,java实现,依赖hadoop运行,学习难度高,一般只用来做搜索引擎开发. java单机的框架有:webmagic和webc ...
- python爬虫scrapy框架——爬取伯乐在线网站文章
一.前言 1. scrapy依赖包: 二.创建工程 1. 创建scrapy工程: scrapy staratproject ArticleSpider 2. 开始(创建)新的爬虫: cd Artic ...
- Java爬虫——B站弹幕爬取
如何通过B站视频AV号找到弹幕对应的xml文件号 首先爬取视频网页,将对应视频网页源码获得 就可以找到该视频的av号aid=8678034 还有弹幕序号,cid=14295428 弹幕存放位置为 h ...
- 爬虫框架之Scrapy——爬取某招聘信息网站
案例1:爬取内容存储为一个文件 1.建立项目 C:\pythonStudy\ScrapyProject>scrapy startproject tenCent New Scrapy projec ...
随机推荐
- Bootstrap 禁用滚动条
Bootstrap中禁用滚动条的方法 逻辑: 当点击弹窗按钮后,js会为body元素添加一个modal-open的类,该类主要内容如下 .modal-open .modal { overflow-x: ...
- Linux入门(16)——Ubuntu16.04下配置sublime text 3使用markdown
sublime text 3安装两个插件: MarkDown Editing OmniMarkupPreviewer 有的人使用 MarkDown Editing markdownpreviewer ...
- 在 JPA、Hibernate 和 Spring 中配置 Ehcache 缓存
jpa, hibernate 和 spring 时配置 ehcache 二级缓存的步骤. 缓存配置 首先在 persistence.xml 配置文件中添加下面内容: <property name ...
- 【转】IO流程
原文地址:http://blog.chinaunix.net/uid-26922071-id-3954900.html IO之流程与buffer概览 为了说明这个流程,还是用图来描述一下比较直观. ...
- 关于python如果没有numpy模块如何处理
1.在python中,你在python的shell输入>>>import numpy 但是编译器告诉你没有numpy库,这时候你就要导入python库,那么如何导入呢 2.收下访问h ...
- SVN.服务器迁移方法
SVN项目, 源服务器 : 10.10.13.48 目标服务器: 10.10.13.129 要把SVN项目从.48上迁移到.129上. 做法: 准备: 版本库:vos 源服务器 : 10.10.1 ...
- js实现强大功能
作者:知乎用户链接:https://www.zhihu.com/question/48187821/answer/110002647来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请 ...
- linux下使用crontab实现定时PHP计划任务失败的原因分析
这篇文章主要介绍了linux下使用crontab实现定时PHP计划任务失败的原因分析,需要的朋友可以参考下 很多人在linux下使用crontab实现PHP执行定时任务却未能成功,不能生成缓存.本 ...
- C++中引用的底层实现
为了研究一下C++中引用的底层实现,写了一个小代码验证其中的基本原理. 引用是一个变量的别名,到底会不会为引用申请内存空间?如果申请空间,空间存放的是什么,下面的代码就主要解决这个疑问. 代码如下,详 ...
- zabbix 2.2.20 安装详解(Centos6.9)
环境说明 [root@centos ~]# cat /etc/redhat-release CentOS release 6.9 (Final) [root@centos ~]# uname -a L ...