flume1.8 基础架构介绍(一)
1. 系统要求
1. Java运行环境 —— Java 1.8及以上
2. 内存 —— 足够的内存供配置的sources,channels 或者sinks使用
3. 硬盘空间 —— 足够的硬盘空间供配置的channels或者sinks使用
4. 文件权限 —— agent使用的文件夹读写权限
2. 架构及数据流模型
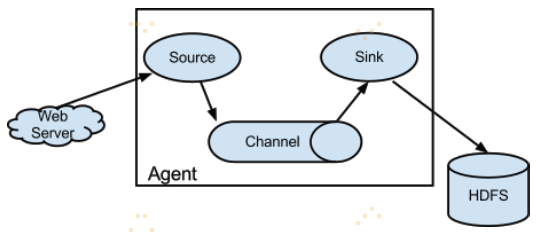
模型介绍详情参考:http://www.cnblogs.com/swordfall/p/8093464.html
3. 创建
3.1 创建一个Agent
Flume agent配置存储在一个本地的配置文件。这个text文件遵循Java配置文件格式。配置一个或多个agents可以在同一配置文件中。配置文件包含一个agent里的每一个source,sink和channel,以及它们怎样连接在一起,形成数据流。在流中每个组件(source,sink或者channel)有名字,类型和一系列配置。如,Avro source有hostname和port。内存channel可以有最大队列值(如capacity),HDFS sink有文件系统URI路径。
3.1.1 启动一个agent
agent需要使用flume-ng shell脚本启动运行,该脚本位于Flume文件夹的bin目录下。你需要在命令中指定agent名,config目录和config文件:

3.1.2 一个简单示例
下述是单节点Flume部署配置文件。该配置文件让用户生成Events并随后在控制台记录出来。
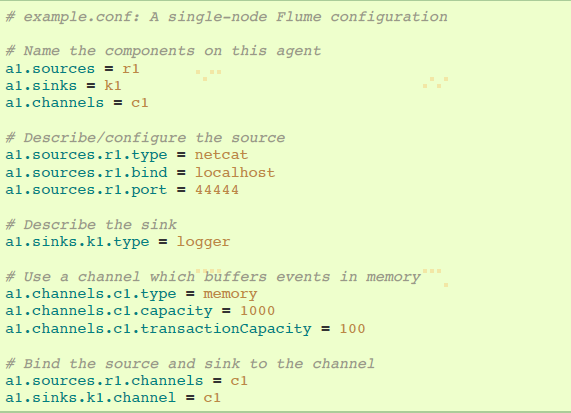
这个配置定义了一个简单agent,叫a1。a1 有一个source监听数据端口44444,一个channel在内存中缓存event数据,还有一个sink在控制台记录event日志。配置文件命名变量组件,然后描述组件的类型和配置属性。一个配置好的文件可能定义了几个不同的agent;当一个Flume进程运行时需要说明启动哪个agent。查看如下命令:

注意:一个完整部署应该包含多一个option:--conf=<conf-dir>。<conf-dir>目录包含flume-env.sh shell脚本和log4j配置文件。在这个例子中,我们通过Java选择强制Flume在控制台打印日志,没有通过传统的环境脚本。
通过一个独立终端,我们可以telnet port 44444 并给Flume发送一个event:

Flume原来的终端在log消息中打印event:

3.1.3 在配置文件中使用环境变量

这要实现需要设置 propertiesImplementation = org.apache.flume.node.EnvVarResolverProperties
Flume启动命令例如:
$ NC_PORT=44444 bin/flume-ng agent –conf conf –conf-file example.conf –name a1 -Dflume.root.logger=INFO,console -DpropertiesImplementation=org.apache.flume.node.EnvVarResolverProperties
注意环境变量也可以在conf/flume-env.sh文件中配置
3.1.4 记录原始数据
在许多生产环境不期望记录摄取通道上的原始数据流,因为这也许导致Flume日志文件泄漏敏感数据或者安全相关的配置,如密钥。默认的,Flume不会记录这类信息。另一方面,如果数据通道被打断,Flume会尝试提供调试问题的线索。
调试event管道上的问题的方法是去设置一个额外Memory Channel连接Logger Sink,这会在Flume logs上输出所有event 数据。在一些情况下,然而,这方法是不够的。
为了能记录event-和配置相关的数据,一些Java系统属性必须设置在log4j配置上。
启用配置相关的日志记录,设置Java系统属性 -Dorg.apache.flume.log.printconfig=true。这可以在命令行设置或者在flume-env.sh文件Java_OPTS变量设置。
启用数据日志记录,在上面描述的同样方法中设置-Dorg.apache.flume.log.rawdata=true。对于大多数组件,为了使event特定的日志出现在Flume日志中,log4j日志级别设置为DEBUG或者TRACE。下面例子,当设置Log4j 日志级别为DEBUG时,控制台能同时打印出配置日志和原始数据日志:
bin/flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger=DEBUG,console -Dorg.apache.flume.log.printconfig=true -Dorg.apache.flume.log.rawdata=true

3.1.5 基于Zookeeper的配置
Flume通过Zookeeper支持Agent配置。这是实验性功能。配置文件需要上传到Zookeeper,有可配置的前缀。配置文件保存在Zookeeper Node data节点上。
一旦配置文件上传,启动带有下述选项的agent:
$ bin/flume-ng agent –conf conf -z zkhost:2181,zkhost1:2181 -p /flume –name a1 -Dflume.root.logger=INFO,console
| Argument Name | Default | Description |
|---|---|---|
| z | – | Zookeeper connection string. Comma separated list of hostname:port |
| p | /flume | Base Path in Zookeeper to store Agent configurations |
3.2 提取数据
3.2.1 RPC方式
Flume distribution包含的Avro客户端可以通过使用avro RPC机制发送文件到Flume Avro source.

上面命令将会在41414端口发送/usr/log.10文件内容发送到Flume source.
3.2.2 Network streams
FLume支持下面机制去从log流类型读取数据, 如: 1. Avro 2. Thrift 3. Syslog 4. Netcat
3.2.3 设置多个agent流

为了使数据流通多个agents或者hops, 前一个agent的sink和当前hop的source需要是avro类型, 同时sink指向source的hostname(或者IP地址)和port.
3.2.4 合并
大量的日志生成客户端发送数据到几个消费者agents, 这些agents连接着存储系统.例如, 几百个web servers收集的日志发送到多个agents, 最后agents写进HDFS集群.

通过配置多个带有avro sink的一级agents, 然后全部指向单独agent的avro source(或者使用thrift sources/sinks/clients), 这在Flume上是可以实现的.二级agent的source合并接收的events进一个单独channel, 这个channel里面的events会被一个sink消费后进入到最终目的地.
3.2.5 多路复用流程
Flume支持复用event流向一个或多个目的地。通过定义可复制或者选择性地将event路由到一个或多个channels的流复用器实现。
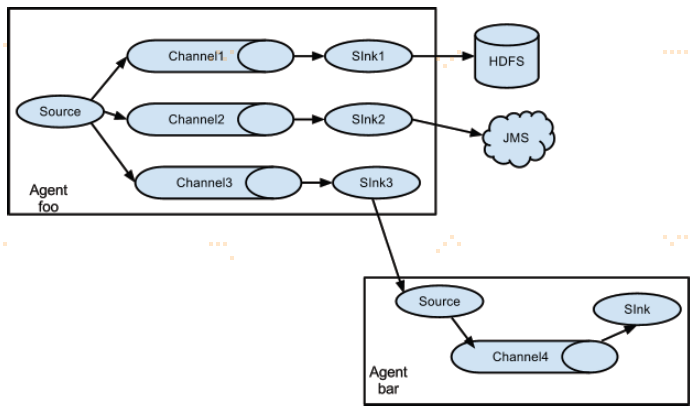
上述例子展示了一个agent "foo"的source把流量分散到三个不同的channels。这分散可以被复制或复用。在复制流量的情况下,每个event都被发送到三个channels。对于复用情况,当一个event的属性匹配到预配置的值时,该event被传递到可用channels的子集。例如,如果一个event属性“txnType” 被设置为“customer”,然后它应该去channel1和channel3,如果它是“vendor”,然后它应该去channel2,否则channel3。这个映射可以设置在agent的配置文件中。
4. 配置
4.1 定义flow
在一个简单agent中定义流程,你需要通过一个channel连接sources和sinks。你需要为给出的agent列出sources,sinks和channels,然后j将source和sink指向channel。一个source实例可以指定多个channels,但是一个sink实例只能指定一个channel。格式为下述:

举例,一个名叫agent_foo的agent从外部avro client读取数据,然后通过一个memory channel发送数据到HDFS。配置文件类似如下:
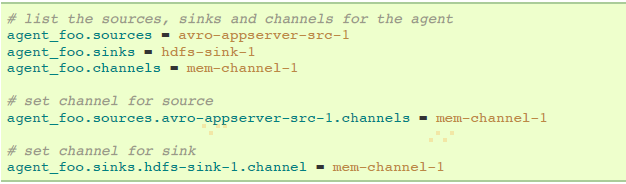
这个将会使events通过memory channel mem-channel-1从avro-AppSrv-source流向hdfs-sink-1。
4.2 配置单个组件
定义流程之后,你需要设置每个source、sink和channel的配置。在相同的阶级式名称空间中,你可以为每个组件特定的属性设置组件类型和其他值。

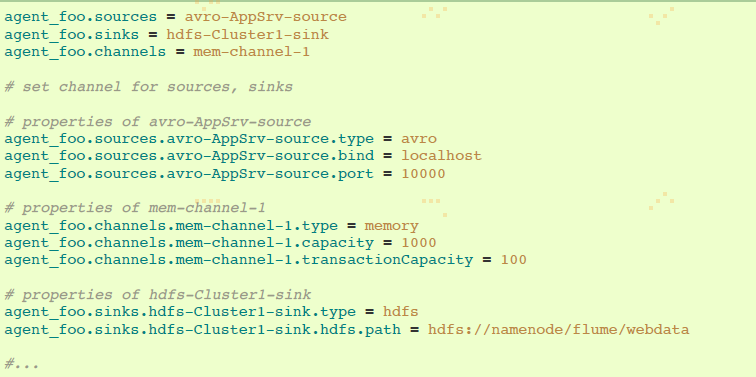
Flume的每个组件都需要设置类型“type”,为了指明组件需要成为哪种对象类型。每个source、sink和channel类型各自有一系列功能属性。当需要时,它们需要被设置出来。上一个例子,我们有通过memory channel mem-channel-1从avro-AppSrv-Source到hdfs-Cluster1-sink的流程。下面例子展示那些组件的配置:
4.3 在一个agent中添加多个流程
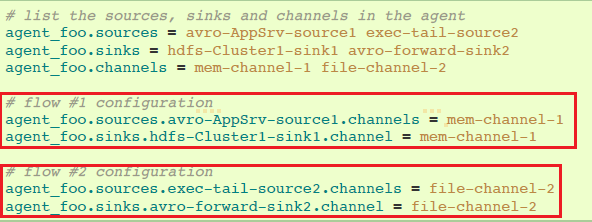
一个简单Flume agent可以包含多个独立的流程。你可以在配置中列出多个sources、sinks和channels。这些组件可以链接形成多个流程:

你可以将sources和sinks链接到它们相应的channels,建立两个不同的流程。例如,如果你需要在一个agent建立两个流程,一个从外部avro client到外部HDFS,另一个从tail输出到avro sink,配置如下:
4.4 配置一个多agent流程
为了建立一个多层流程,你需要第一层的avro/thrift sink 指向下一层的avro/thrift source。这将会导致第一个Flume agent的events转发给下一个Flume agent。例如,你正在用avro client定期发送文件(一个文件即为event)到本地的Flume agent,然后这个本地agent会把文件转发给另一个有存储功能的agent。
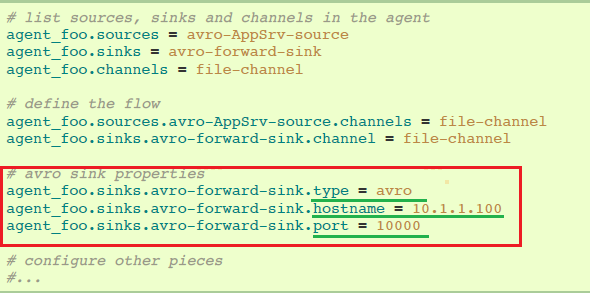
Weblog agent配置:
HDFS agent配置:
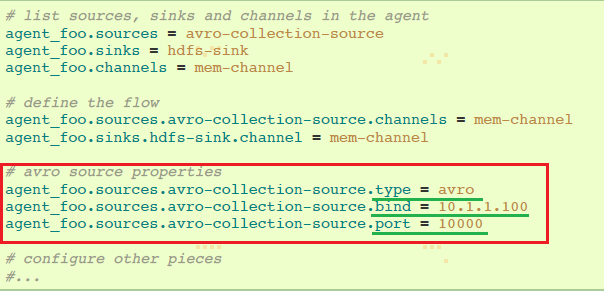
这里,我们将weblog agent的avro-forward-sink链接到hdfs agent的avro-collection-source。这导致来自外部appserver source的events最终存储在HDFS中。
4.5 分散流程
如上节讨论的那样,Flume支持从一个source到多个channels的分散流程。分散有两种模式,复制(replicating)和复用(multiplexing)。在复制流程中,event将会被发送到全部配置的channels。在复用情况下,event只会被发送到符合要求的channels。在分散流程中,需要指定source的channels列表和分散规则。添加一个channel "selector",可以是replicating或者multiplexing,然后指定选择规则,如果你没有指定一个selector,默认replicating:
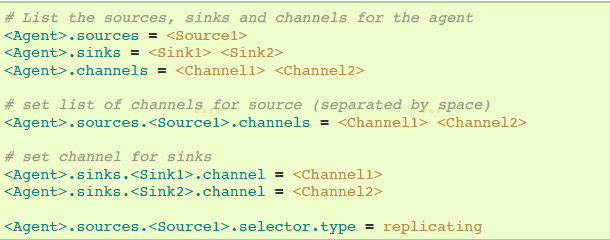
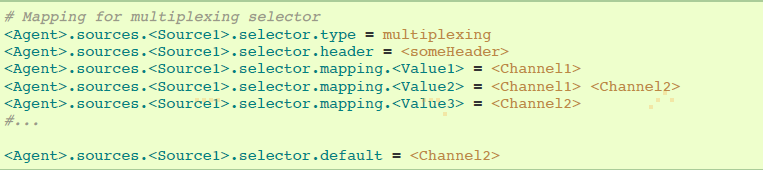
复用选择有一系列属性去分流流程。这要求在channel设置指定event属性的mapping。selector在event的header检查每个配置的属性。如果匹配到指定的值,该event会被发送到映射该值的channels。如果没有匹配到,event将会发送到配置好默认的channels。
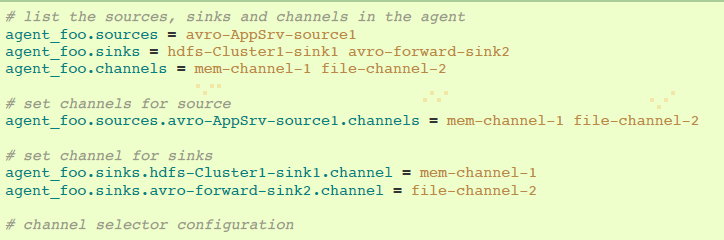
下面的例子展示,一个简单流程多路复用到两条路径。名叫agent_foo的agent有一个简单avro source和两个链接到两个sinks的channels:

selector检查叫“State”的header。如果值为“CA”,然后它所属的event将会被发送到mem-channel-1,如果值为“AZ”则发送到file-channel-2,或者值为“NY”则两个channels都发送。如果“State“ header没有设置或者匹配不到三个值中的一个,则event被发送到默认的mem-channel-1。
selector也支持可选的channel。为header指定可选的channels,配置属性‘optional’可以像下面那样使用:
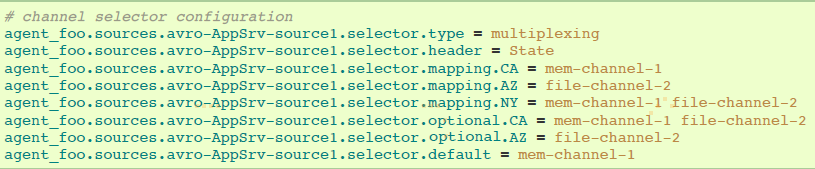
selector第一次将会尝试向要求的channels发送events,如果这些channels消费events失败,则提交事务失败,事务将会再次向这些channels提交。一旦要求的channels消费完这些events,selector将会向可选的channels发送events。如果这些可选channels消费失败,将会被忽略,不会再次提交事务。
注意:如果header没有要求的channels,events将会写进默认channels,也会试图写进可选的channels。如果没有要求channels指定,指定可选的channels将会同样造成event被写进默认channels。如果没有默认的和要求的channels,selector将会把events试图写进可选channels。在这种情况下,失败将会被忽略。
参考资料:
https://flume.apache.org/FlumeUserGuide.html
flume1.8 基础架构介绍(一)的更多相关文章
- ORM,Entity Framework介绍以及其所包含的基础架构介绍
一:entity framework 6.0 ORM (实体关系模型) O: Domain Object 领域模型 R: Relational Database 关系型数据库 M: Mapping 映 ...
- 基础架构之spring cloud基础架构
这篇文章是给公司设计的微服务基础架构,包括架构设计.部署流程.部署架构.开发Tip等等.这里分享出来,如果对看官们有点用,我就非常的高兴了. 首页 2. 架构设计 3. 部署流程 4. 部署架构 5. ...
- LYNC2013介绍和基础架构准备角色
LYNC2013部署系列PART1:LYNC2013介绍和基础架构准备 前言:LYNC 2013发布已经很久了,本人一直在进行相关的学习和测试,在有限的资源条件下,把能够模拟出来的角色进行了安装部署, ...
- 深入浅出node.js游戏服务器开发1——基础架构与框架介绍
2013年04月19日 14:09:37 MJiao 阅读数:4614 深入浅出node.js游戏服务器开发1——基础架构与框架介绍 游戏服务器概述 没开发过游戏的人会觉得游戏服务器是很神秘的 ...
- 【HBase】HBase基本介绍和基础架构
目录 基本介绍 概述 特点 HBase和Hadoop的关系 RDBMS与HBase的对比 特征 基础架构 基本介绍 概述 HBase是bigtable的开源java版本,是建立在HDFS之上,提供高可 ...
- 1.Ceph 基础篇 - 存储基础及架构介绍
文章转载自:https://mp.weixin.qq.com/s?__biz=MzI1MDgwNzQ1MQ==&mid=2247485232&idx=1&sn=ff0e93b9 ...
- [Search Engine] 搜索引擎分类和基础架构概述
大家一定不会多搜索引擎感到陌生,搜索引擎是互联网发展的最直接的产物,它可以帮助我们从海量的互联网资料中找到我们查询的内容,也是我们日常学习.工作和娱乐不可或缺的查询工具.之前本人也是经常使用Googl ...
- 面向服务体系架构(SOA)和数据仓库(DW)的思考基于 IBM 产品体系搭建基于 SOA 和 DW 的企业基础架构平台
面向服务体系架构(SOA)和数据仓库(DW)的思考 基于 IBM 产品体系搭建基于 SOA 和 DW 的企业基础架构平台 当前业界对面向服务体系架构(SOA)和数据仓库(Data Warehouse, ...
- 用c#开发微信 (11) 微统计 - 阅读分享统计系统 1 基础架构搭建
微信平台自带的统计功能太简单,有时我们需要统计有哪些微信个人用户阅读.分享了微信公众号的手机网页,以及微信个人用户访问手机网页的来源:朋友圈分享访问.好友分享消息访问等.本系统实现了手机网页阅读.分享 ...
随机推荐
- 深度优先搜索(DFS)——部分和问题
对于深度优先搜索,这里有篇写的不错的博客:DFS算法介绍 .总得来说是从某个状态开始,不断的转移状态知道无法转移,然后回到前一步的状态.如此不断的重复一直到找到最终的解.根据这个特点,常常会用到递归. ...
- xml文件生成方式一(字符串拼接,将多实体类对象写入xml文件)
1.xml文件生成,拼接字符串使用StringBuffer或StringBuilder 2.拼接好后写入文件即可,将多个实体类写入xml文件 3.这种方式比较简单,但是操作也比较麻烦 4.下面是我的代 ...
- Hibernate问题浅析
1.什么是SessionFactory?什么是Session?httpsession和hibernate的session的有什么区别? SessionFactory接口负责初始化Hiber ...
- C#扩展(2):Random的扩展
在.net中关于Random一共也只有这几个方法 // // 摘要: // 表示伪随机数生成器,一种能够产生满足某些随机性统计要求的数字序列的设备. [ComVisible(true)] public ...
- js功能代码大全
1.日期格式化 //化为2017-08-14 function formatDate (date) { var y = date.getFullYear(); var m = date.getMont ...
- c语言中的转义序列
c中的输出函数printf()可以带以下的转义序列,不同的转义序列会得到不同的结果. 1.\a:警报 2.\b:退格(光标回退一格)3.\f:换页4.\n:换行(光标去到下一行的起始处)5.\r:回车 ...
- python内置函数与匿名函数
内置函数 Built-in Functions abs() dict() help() min() setattr() all() dir() hex() next() slice() any() d ...
- ADO.NET访问数据库
1:ADO.NET数据库的方法和技术 2:ADO.NET的主要组成: 1>DataSet(数据集)-----独立于数据间的数据访问 2>.NETFramework(数据提供程序)----- ...
- Fiddler中使用AutoResponder创建规则替换线上文件
Fiddler 的AutoResponder tab允许你从本地返回文件,而不用将http request 发送到服务器上. 1.AutoResponder规则实例 (1) 打开博客园首页,把博客园的 ...
- jQuery 入门
不能正常引用jQuery-2.2.4.min.js所以代码没生效 jQuery 是一个 JavaScript 函数库.jQuery 库包含以下特性: HTML 元素选取 HTML 元素操作 CSS 操 ...