JAVA提高四:反射基本应用
在前面一节《http://www.cnblogs.com/pony1223/p/7659210.html》,我们学习了JAVA的反射的相关知识,那么本节我们对前面所学习的知识做一个应用相关的学习。
一、利用反射创建集合ArrayList 并添加元素
我们前面学习了那么反射相关的知识,那么我们究竟如何用呢?其实本身反射多于框架的设计,如果不做框架或者底层开发是不会去涉及太多反射的知识,那么假如我们有一个需求为:动态通过配置去创建Collection的集合,该如何去做呢?
首先我们回顾下集合类相关的知识点:
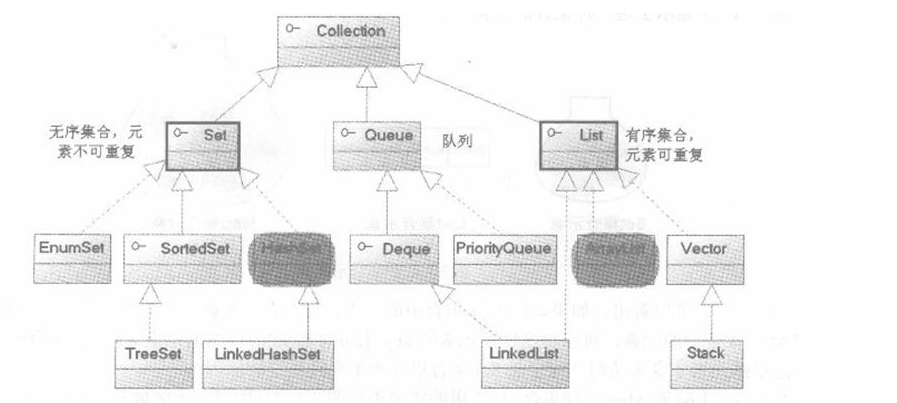
粗线圈出的Set和List接口是Collection接口派生出的两个子接口,它们分别代表了无序集合和有序集合,阴影部分HashSet和ArrayList是两个主要的实现类,经常使用到的就是这两个。
基本知识:
Collection是一个接口,是高度抽象出来的集合,它包含了集合的基本操作和属性。
Collection包含了List和Set两大主要分支。
(01) List是一个有序的队列,每一个元素都有它的索引。第一个元素的索引值是0。
List的实现类有LinkedList, ArrayList, Vector, Stack。
********************************************************************************************************************
LinkedList 是一个继承于AbstractSequentialList的双向链表。它也可以被当作堆栈、队列或双端队列进行操作。
LinkedList 实现 List 接口,能对它进行队列操作。
LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。
LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。
LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输。
LinkedList 是非同步的。
********************************************************************************************************************
ArrayList 是一个数组队列,相当于动态数组。与Java中的数组相比,它的容量能动态增长。它继承于AbstractList,实现了List, RandomAccess, Cloneable, java.io.Serializable这些接口。
ArrayList 继承了AbstractList,实现了List。它是一个数组队列,提供了相关的添加、删除、修改、遍历等功能。
ArrayList 实现了RandmoAccess接口,即提供了随机访问功能。RandmoAccess是java中用来被List实现,为List提供快速访问功能的。在ArrayList中,我们即可以通过元素的序号快速获取元素对象;这就是快速随机访问。稍后,我们会比较List的“快速随机访问”和“通过Iterator迭代器访问”的效率。
ArrayList 实现了Cloneable接口,即覆盖了函数clone(),能被克隆。
ArrayList 实现java.io.Serializable接口,这意味着ArrayList支持序列化,能通过序列化去传输。
********************************************************************************************************************
Vector 是矢量队列,它是JDK1.0版本添加的类。继承于AbstractList,实现了List, RandomAccess, Cloneable这些接口。
Vector 继承了AbstractList,实现了List;所以,它是一个队列,支持相关的添加、删除、修改、遍历等功能。
Vector 实现了RandmoAccess接口,即提供了随机访问功能。RandmoAccess是java中用来被List实现,为List提供快速访问功能的。在Vector中,我们即可以通过元素的序号快速获取元素对象;这就是快速随机访问。
Vector 实现了Cloneable接口,即实现clone()函数。它能被克隆。
********************************************************************************************************************
Stack是栈。它的特性是:先进后出(FILO, First In Last Out)。
java工具包中的Stack是继承于Vector(矢量队列)的,由于Vector是通过数组实现的,这就意味着,Stack也是通过数组实现的,而非链表。当然,我们也可以将LinkedList当作栈来使用!
********************************************************************************************************************
区别:
Vector和ArrayList不同,Vector中的操作是线程安全的。
ArrayList与Vector的区别在于:
1在扩展上,arraylist变成(150%+1),Vector变成(200%)。
2Arraylist不是线程安全的,而Vector是线程安全的;
ArrayList 和Vector是采用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,都允许直接序号索引元素,但是插入数据要设计到数组元素移动等内存操作,所以索引数据快插入数据慢,Vector由于使用了synchronized方法(线程安全)所以性能上比ArrayList要差,LinkedList使用双向链表实现存储,按序号索引数据需要进行向前或向后遍历,但是插入数据时只需要记录本项的前后项即可,所以插入数度较快!
(02) Set是一个无序不允许有重复元素的集合。
Set的实现类有HastSet和TreeSet。HashSet依赖于HashMap,它实际上是通过HashMap实现的;TreeSet依赖于TreeMap,它实际上是通过TreeMap实现的。
(03)List 和 Set 的区别是什么?
List
有序的、可重复的、按索引位置排序 (这点类似于数组)
实现类
ArrayList 数组实现
1.代表长度可变的数组
2.允许对元素进行快速的随机访问(根据索引进行访问)
3.向ArrayList中插入和删除元素的速度较慢,需要移动大量的元素
LinkedList 双向链表实现
1.插入和删除元素的速度较快(不需要移动元素)
2.随机访问的速度相对较慢,随机访问的含义是根据索引定位特定位置的元素
3.提供addFirst(0 addLast() getFirst() getLast() removeFirst()和removeLast()方法,使LinkedList可以作为堆栈,队列和双向队列使用
Set
无序的、不可重复的、
实现类
HashSet 哈希算法实现、底层是HashMap实现,用到了key的部分。
1. 按照哈希算法存取集合中的对象,具有很好的存取和查找性能
2. 当向集合中加入一个对象时,Hashset会调用对象的hashCode()方法获得哈希码,然后根据哈希码进一步计算对象在集合中的存放位置
3. 在java.lang.Object中定义了hashCode()和equals()方法,在最原始的Object中定义的equals()方法是按照内存地址比较对象是否相等,因此对于Object而言,如果equals方法的结果为true,则说明两个引用实际上引用相同的对象,这两个引用的哈希码必然也相同
为保证HashSet能够正常工作,要求两个对象用equals()方法比较的结果为true时,他们的哈希码也相同
如果用户定义的类覆盖了Object的equals方法而没有覆盖hashCode方法,会导致当equals方法结果为true时,对象的哈希码并不相同,这样会使hashSet无法正常工作,用户本意是作为同一个对象引用处理,但是由于没有覆盖hashCode()方法,导致哈希码不同,hashSet将作为不同对象处理。
SortedSet
排序的set
实现类
TreeSet,在HashSet的基础上维护了一个双向链表,
1.排序的依据对象实现实现了Comparable接口,或者是构造时传入Comparator比较器。像Integer,Double和String他们自己都实现了Compareble接口
再回顾了Collection 的集合知识后,我们知道平时我们创建Collection 集合都通过子类如:ArrayList HashSet 直接通过NEW来创建的.那么现在我们不采用new的方式,因为客户即可能使用ArrayList 也可能是用的HashSet 的,应该是客户端来决定,因此我们采用反射的方式来进行,代码如下:
package study.javaenhance; import java.io.InputStream;
import java.util.Collection;
import java.util.Properties; import study.javaenhance.util.ReflectPoint; public class ReflectTest2
{
public static void main(String[] args) throws Exception
{
//首先,为了方便客户端自己定义采用ArrayList,还是HashSet 为此我们定义一个配置文件为config.properties
//1.加载读取config.properties
InputStream inputstream = ReflectTest2.class.getResourceAsStream("config.properties");
//2.properties 存放读取的值
Properties properties = new Properties();
properties.load(inputstream);
inputstream.close();
//3.从Properties中获取值 反射进行,加载类
Class clazz = Class.forName(properties.getProperty("className"));
//4.解析类
Collection collections = (Collection) clazz.newInstance(); ReflectPoint pt1 = new ReflectPoint(3,3);
ReflectPoint pt2 = new ReflectPoint(5,5);
ReflectPoint pt3 = new ReflectPoint(3,3); collections.add(pt1);
collections.add(pt2);
collections.add(pt3);
collections.add(pt1); System.out.println(collections.size()); } }
config.properties 配置的值为:className=java.util.ArrayList
最后输出的结果为4;
如果我们将配置修改为:
config.properties 配置的值为:className=java.util.HashSet
这个时候的结果将取决于ReflectPoint 这个类即添加的这个类是否实现了equals 和 hashcode 方法,如果没有实现,那么按照默认Object中的equals方法来比较结果为false即不是同一个元素,那么pt1 和 pt3 不相等,因此在hashset 不算重复的元素,因此这个时候结果为3,但是如果实现了equals方法和hashcode 方法,那么这个时候,如果实现比较的方法如下:
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + x;
result = prime * result + y;
return result;
} @Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
final ReflectPoint other = (ReflectPoint) obj;
if (x != other.x)
return false;
if (y != other.y)
return false;
return true;
}
那么这个时候输出的结果为2,可以看见差异性还是有的,那么arrayList hashset 区别是什么?
ArrayList是一组有序的集合,当对象被添加到ArrayList时,对象会先找到第一个空缺的地方,记住,放进去的是对象的引用,不是对象本身,接下来,第二个对象依次在第二个位置增加,如果发现有相同的对象,也是按照顺序放进去,也就是说,在这个有序集合里,每有一个对象就会放入一个引用,可能出现多个引用指向同一个对象的情况,但没有关系.
HashSet,当放入对象时,首先查看里面是否有这样一个对象,如果有,则不放,如果没有才会放入,如果真的很想放进去这个对象,除非将已经存在的对象删除。所以,使用ArrayList的返回的size是4,而使用HashSet的时候返回size的值是3,也就是说,使用Hashset的时候,最后一个pt1没有放进去因为已经存在。
那下面还有一个问题,pt1和pt3是否相同的,因为具有相同的属性。默认的两个独立的对象,如果我们想让他们相同,必须自己去写equals方法,所以我们覆盖equals方法和hashCode方法.此时返回的长度为2,因为此时pt1和pt3是相同的点,没有被添加到HashSet当中.
HashSet内部添加元素的时候,因为要对于重复的元素不能添加进来,通常的做法的是:
如果想查找一个集合中是否含有某个对象,大概的程序代码怎么写呢?你通常是逐一的取出每个元素与要查找的对象进行比较,当发现某个元素与要查找的对象进行equals方法比较的结果相等时,则停止继续查找并返回肯定的信息,否则,返回否定的信息,如果一个集合中有个很多个元素,比如说有一万个元素进行比较,也效率是非常差劲的。有人发明了一种哈希算法来提高效率,这种方式将集合分为若干个存储区域,每个对象可以计算出一个哈希码,可以将哈希码分组,每个组分别对应某个存储区域,根据一个对象的哈希码就可以确定该对象应该存储在某个区域。
HashSet的做法是哈希算法:
HashSet就是采用哈希算法存储对象的集合,他内部采用对某个数组n进行取余的方法对哈希码进行分组和划分对象的存储区域,Object类中定义了一个HashCode方法返回每个java对象的哈希码,当从HashSet集合中查找到某个对象时。Java系统首先调用对象的hashCode方法获得该对象的哈希码,然后根据哈希码找到对应的存储区域,最后取出该存储区域的每个元素与该对象进行equals方法的比较,这样不用遍历集合中的所有元素就可以得到结论,可见,HashSet集合具有很好的对象检索性能,但是。HashSet集合存储对象的效率相对要低些,因为向HashSet集合中添加对象的时候,首先要计算出来对象的哈希码和根据这个哈希码来确定对象在集合中的存放位置。
为了保证一个类的实例对象可能在HashSet正常存储,要求这个类的两个实例对象用equals方法比较的结果相等时,他们的哈希码也必须相等。
如果一个类的hashcode方法没有遵循上述要求,那么当这个类的两个实例对象用equals方法比较的结果相等时,他们本来应该无法被同时的存储进Set集合中,但是他们因为hash值得不同结果存储进了HashSet集合中,由于他们的hashCode方法的返回值不同,第二个对象首先按照哈希码计算可能会被放进与第一个对象不同的区域中,这样,他就不可能与第一个对象进行equals比较了,也就可能被存储进hashSet集合中了,Object类中的hashCode方法不能满足对象被存入到HashSet中的要求,因为它的返回值是通过对象的内存地址推算出来的,同一个对象在程序运行期间的任何时候返回的哈希码都是始终不变的,所以只要是两个不同的实例对象,即使他们的queals方法比较结果相等,他们默认的hashCode方法的返回值是不同的。只要将例子中使用的ArrayList集合改为使用HashSet集合就可以看到这种错误的效果了。【不要覆写equals 和 hashcode 的时候的效果就是hashset中存放了3个元素,或者覆写了equals而不覆写hashcode的时候效果也是一样的,明明是equals相等的两个元素却方进去了】 因此特别注意:覆写的时候hashcode 和 equals 两个方法要同时覆写.
非常重要的注意点:
(1)通常来说,一个类的两个实例对象用equals方法比较的结果相等的时候,他们的哈希码也必须相等,但反之则不成立,即equals方法比较结果不相等的对象可以有相同的哈希码,或者说哈希码相同的两个对象的equals方法比较的结果可以不等,例如,字符串BB和Aa的equals方法比较的结果肯定不相等,但是他们的hashCode方法返回值相等。
(2)当一个对象被存储到HashSet集合中以后,就不能修改这个对象中的某些参与计算哈希码的字段了,否则,对象修改以后的哈希码与最初存储金集合的哈希码就不同了,在这种情况下,即使在contains方法使用该对象的当前引用作为的参数去HashSet集合中检索对象,也将返回找不到对象的结果,这也会导致无法从Hash集合中单独的删除当前的对象,从而造成内存泄漏。
关于第二点我们看一个例子如下:
//首先,为了方便客户端自己定义采用ArrayList,还是HashSet 为此我们定义一个配置文件为config.properties
//1.加载读取config.properties
InputStream inputstream = ReflectTest2.class.getResourceAsStream("config.properties");
//2.properties 存放读取的值
Properties properties = new Properties();
properties.load(inputstream);
inputstream.close();
//3.从Properties中获取值 反射进行,加载类
Class clazz = Class.forName(properties.getProperty("className"));
//4.解析类
Collection collections = (Collection) clazz.newInstance(); ReflectPoint pt1 = new ReflectPoint(3,3);
ReflectPoint pt2 = new ReflectPoint(5,5);
ReflectPoint pt3 = new ReflectPoint(3,3); //ReflectPoint类重写了hashCode方法---算法依据x,y。
collections.add(pt1); //放入
collections.add(pt2);//放入
collections.add(pt3);//hashCode比较后,和pt1在同一区域;比较equals发现相同,舍弃pt3这个引用
collections.add(pt1);//hashCode比较后,和pt1在同一区域;比较equals发现相同,舍弃
System.out.println("初始大小, size= "+collections.size());//2 最终放入collections 了2个元素
collections.remove(pt1);
System.out.println("删除一个元素后大小, size= "+collections.size());//删除了pt1 大小为1
上面是我们期望的结果,但是如果我们不遵循第二条,即在删除前加上下面这一个语句:
pt1.y=4;//修改参与进行hashCode运算的 y值,则pt3此时的hashCode和上面放入collections时的hashCode是不相等的。
//这将导致Java系统无法在collections中检索到。
那么将会出现在删除后的大小结果还是2而不是1;
//首先,为了方便客户端自己定义采用ArrayList,还是HashSet 为此我们定义一个配置文件为config.properties
//1.加载读取config.properties
InputStream inputstream = ReflectTest2.class.getResourceAsStream("config.properties");
//2.properties 存放读取的值
Properties properties = new Properties();
properties.load(inputstream);
inputstream.close();
//3.从Properties中获取值 反射进行,加载类
Class clazz = Class.forName(properties.getProperty("className"));
//4.解析类
Collection collections = (Collection) clazz.newInstance(); ReflectPoint pt1 = new ReflectPoint(3,3);
ReflectPoint pt2 = new ReflectPoint(5,5);
ReflectPoint pt3 = new ReflectPoint(3,3); //ReflectPoint类重写了hashCode方法---算法依据x,y。
collections.add(pt1); //放入
collections.add(pt2);//放入
collections.add(pt3);//hashCode比较后,和pt1在同一区域;比较equals发现相同,舍弃pt3这个引用
collections.add(pt1);//hashCode比较后,和pt1在同一区域;比较equals发现相同,舍弃
System.out.println("初始大小, size= "+collections.size());//2 最终放入collections 了2个元素
pt1.y = 4;
collections.remove(pt1);
System.out.println("删除一个元素后大小, size= "+collections.size());//删除了pt1 大小却还是2
上面的代码,将会发生内存泄漏,因为认为删除掉了其实没有删除掉。
原则上:只有类的实例对象要给采用哈希算法进行存储和检索时,这个类才需要按照要求覆盖hashCode方法。即使程序可能暂时不会用到当前类的hashCode方法,但是为它提供一个hashCode方法也不会有什么不好,没准以后什么时候又用到这个方法了,所以通常要求hashCode方法和equals方法一并被同时覆盖。
如果还是无法理解 hashcode 和 equals 可以看一下这篇文章:一次性搞清楚equals和hashCode,
二、用类加载器的方式管理资源和配置文件
前面一小节,讲到用反射实现创建ArrayList的时候有一个配置文件叫config.properties,那么它是怎么配加载的呢?这一节我们来学习一下:
//1.加载读取config.properties
/**
* 1.采用的是Class 中的getResourceAsStream方法去加载配置文件,此时默认配置文件的路就是和类名的class在同一级目录
*/
//InputStream inputstream = ReflectTest2.class.getResourceAsStream("config.properties");
/**
* 2.使用类加载器加载配置文件.类加载器默认都是从classPath的根目录去读取文件,而config.properties不在根目录下
* 我们之需要加载classpath的路径就可以了,注意不要在前面加上"/",本身类加载器默认就是从根目录下加载
*/
//InputStream inputstream = ReflectTest2.class.getClassLoader().getResourceAsStream("study/javaenhance/config.properties");
/**
* 3.使用Class 提供的加载配置文件的方法因为其默认是从当前class文件的路径查找的是一个相对路径,也可以从指定其从绝对路径查找
* 这个时候需要在前面加上/
*/
InputStream inputstream = ReflectTest2.class.getResourceAsStream("/study/javaenhance/config.properties");
上面三种方式都是可以的,加载资源文件和加载类一样,都是采用的类加载器进行的加载.上面说的对classpath 进行加载时指的你自己配置的classpath路径,可以查看项目目录下面的.classpath文件中看到,如下:

三、内省以及内省操作JAVABean
上面我们讲解了反射的基本应用,下面我们在来看一个JDK的反射应用,内省操作。
1.什么内省?
内省(Introspector)是Java 语言对JavaBean类属性、事件的一种缺省处理方法。例如类 A 中有属性 name, 那我们可以通过 getName,setName 来得到其值或者设置新的值。通过 getName/setName 来访问 name 属性,这就是默认的规则.
Java 中提供了一套 API 用来访问某个属性的 getter/setter 方法,通过这些 API 可以使你不需要了解这个规则(但你最好还是要搞清楚),这些 API 存放于包 java.beans 中。
2).直接通过属性的描述器java.beans.PropertyDescriptor类,来访问属性的getter/setter 方法;
package study.javaenhance; import java.beans.PropertyDescriptor;
import java.lang.reflect.Method; import study.javaenhance.util.ReflectPoint; public class IntroSpectorTest
{
public static void main(String[] args) throws Exception
{ ReflectPoint pt1 = new ReflectPoint(3,5); System.out.println(pt1.getX());
/**
* 那么上面的getX 就可以得到返回的值,那么其底层是怎么实现的呢?同样setX 为什么可以实现呢?
* 这就是JDK 底层的内省操作,用于可以访问到javaBean对象的get 和 set 方法.
* 思考:如果我们要访问getX 方法,不采用JDK API 底层内省帮我们实现的getX方法,我们该怎么做,那么我们肯定会用到反射
* 反射的应用之一:JDK 的内省操作
* 要通过反射获取到getX方法,那么需要经过"x"-->"X"-->"getX"-->MethodGetX 这样一个流程,那么这个流程比较麻烦
* 于是可以利用内省中的PropertyDescriptor 类帮我们实现.
*/
//get实现
//1.通过要获取的set get方法的属性 和 Class 来得到PropertyDescriptor
PropertyDescriptor propertyDescriptor = new PropertyDescriptor("x",ReflectPoint.class);
//2.通过PropertyDescriptor 中的方法来获取set 和 get 方法
Method methodGetX = propertyDescriptor.getReadMethod();
//3.invoke 调用,因为get方法没有参数所以传入空
Object object = methodGetX.invoke(pt1, null);
//可以看到我们没有直接用对象的get方法也获取到了其值,其实这就是JDK底部内省的默认实现方法内省操作
System.out.println(object); //set的实现
PropertyDescriptor propertyDescriptor2 = new PropertyDescriptor("x",ReflectPoint.class);
Method methodSetX = propertyDescriptor.getWriteMethod();
methodSetX.invoke(pt1,7);
System.out.println(pt1.getX()); } }
3).通过类 Introspector 来获取某个对象的 BeanInfo 信息,然后通过 BeanInfo 来获取属性的描述器( PropertyDescriptor ),通过这个属性描述器就可以获取某个属性对应的 getter/setter 方法,然后我们就可以通过反射机制来调用这些方法。
package study.javaenhance; import java.beans.BeanInfo;
import java.beans.IntrospectionException;
import java.beans.Introspector;
import java.beans.PropertyDescriptor;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method; import study.javaenhance.util.ReflectPoint; public class IntroSpectorTest
{
public static void main(String[] args) throws Exception
{ ReflectPoint pt1 = new ReflectPoint(3,5); //System.out.println(pt1.getX());
/**
* 那么上面的getX 就可以得到返回的值,那么其底层是怎么实现的呢?同样setX 为什么可以实现呢?
* 这就是JDK 底层的内省操作,用于可以访问到javaBean对象的get 和 set 方法.
* 思考:如果我们要访问getX 方法,不采用JDK API 底层内省帮我们实现的getX方法,我们该怎么做,那么我们肯定会用到反射
* 反射的应用之一:JDK 的内省操作
* 要通过反射获取到getX方法,那么需要经过"x"-->"X"-->"getX"-->MethodGetX 这样一个流程,那么这个流程比较麻烦
* 于是可以利用内省中的PropertyDescriptor 类帮我们实现.
*/
//get实现
String propertyName = "x";
Object retValue = getProperty(pt1, propertyName);
System.out.println(retValue);
//set的实现
Object value = 7;
setProperty(pt1, propertyName, value);
System.out.println(pt1.getX()); } private static void setProperty(Object pt1, String propertyName,
Object value) throws IntrospectionException,
IllegalAccessException, InvocationTargetException
{ /*PropertyDescriptor propertyDescriptor2 = new PropertyDescriptor(propertyName,pt1.getClass());*/
BeanInfo beanInfo = Introspector.getBeanInfo(pt1.getClass());
PropertyDescriptor[] pd = beanInfo.getPropertyDescriptors();
for (PropertyDescriptor propertyDescriptor : pd)
{
if(propertyDescriptor.getName().equals(propertyName))
{
Method methodSetX = propertyDescriptor.getWriteMethod();
methodSetX.invoke(pt1,value);
break;
}
}
} private static Object getProperty(Object pt1,
String propertyName) throws IntrospectionException,
IllegalAccessException, InvocationTargetException
{
BeanInfo beanInfo = Introspector.getBeanInfo(pt1.getClass());
PropertyDescriptor[] pd = beanInfo.getPropertyDescriptors();
Object retVal = null;
for (PropertyDescriptor propertyDescriptor : pd)
{
if(propertyDescriptor.getName().equals(propertyName))
{
Method methodGetX = propertyDescriptor.getReadMethod();
retVal = methodGetX.invoke(pt1);
break;
}
}
return retVal;
/*//1.通过要获取的set get方法的属性 和 Class 来得到PropertyDescriptor
PropertyDescriptor propertyDescriptor = new PropertyDescriptor(propertyName,pt1.getClass());
//2.通过PropertyDescriptor 中的方法来获取set 和 get 方法
Method methodGetX = propertyDescriptor.getReadMethod();
//3.invoke 调用,因为get方法没有参数所以传入空
return methodGetX.invoke(pt1, null);
//可以看到我们没有直接用对象的get方法也获取到了其值,其实这就是JDK底部内省的默认实现方法内省操作
*/
} }
注意点:
1.我们又通常把javabean的实例对象称之为值对象 (Value Object),因为这些bean中通常只有一些信息字段和存储方法,没有功能性方法。一个JavaBean类可以不当JavaBean用,而当成普通类 用。JavaBean实际就是一种规范,当一个类满足这个规范,这个类就能被其它特定的类调用。一个类被当作javaBean使用时,JavaBean的 属性是根据方法名推断出来的,它根本看不到java类内部的成员变量(javabean的成员变量通常都是私有private的)。
2.除了反射用到的类需要引入外,内省需要引入的类如下所示,它们都属于java.beans包中的类,自己写程序的时候也不能忘了引入相应的包或者类
import java.beans.BeanInfo;
import java.beans.IntrospectionException;
import java.beans.Introspector;
import java.beans.PropertyDescriptor;
四、BeanUtils工具包操作JavaBean
下面讲解一些开源的工具类Beanutils,需要额外下载的,commons-beanutils.jar,要使用它还必须导入commons-logging.jar包,不然会出异常;
案例一:
public static void main(String[] args) throws Exception {
Point point = new Point(2, 5);
String proName = "x";
BeanUtils.setProperty(point, proName, "8");
System.out.println(point.getX());// 8
System.out.println(BeanUtils.getProperty(point, proName));// 8
System.out.println(BeanUtils.getProperty(point, proName).getClass().getName());// java.lang.String
BeanUtils.setProperty(point, proName, 8);
System.out.println(BeanUtils.getProperty(point, proName).getClass().getName());// java.lang.String
}
//我们看到虽然属性x的类型是Integer,但是我们设置的时候无论是Integer还是String,BeanUtils的内部都是当成String来处理的。
案例二:BeanUtils支持javabean属性的级联操作
public static void main(String[] args) throws Exception {
Point point = new Point(2, 5);//在point中加一个属性 private Date birth = new Date();并产生setter/getter方法
String proName = "birth";
Date date= new Date();
date.setTime(10000);
BeanUtils.setProperty(point, proName, date);
System.out.println(BeanUtils.getProperty(point, proName));
BeanUtils.setProperty(point, "birth.time", 10000);
System.out.println(BeanUtils.getProperty(point, "birth.time"));//10000
}
//之所以可以 BeanUtils.setProperty(point, "birth.time", 10000);这样写,那是因为Date类中有getTime()和setTime()方法,即Date类中相当于有time这个属性。
案例三:BeanUtils和PropertyUtils对比
public static void main(String[] args) throws Exception {
Point point = new Point(2, 5);
String proName = "x";
BeanUtils.setProperty(point, proName, "8");
System.out.println(BeanUtils.getProperty(point, proName));//8
System.out.println(BeanUtils.getProperty(point, proName).getClass().getName());//java.lang.String
// PropertyUtils.setProperty(point, proName, "8");//exception:argument type mismatch
PropertyUtils.setProperty(point, proName, 8);
System.out.println(PropertyUtils.getProperty(point, proName));//8
System.out.println(PropertyUtils.getProperty(point, proName).getClass().getName());//java.lang.Integer
}
//BeanUtils它以字符串的形式对javabean进行转换,而PropertyUtils是以原本的类型对javabean进行操作。如果类型不对,就会有argument type mismatch异常。
理解了相应的原理,那些现成的工具用起来就会更舒服,如Beanutils与 PropertyUtils工具。这两个工具设置属性的时候一个主要区别是PropertyUtils.getPropety方法获得的属性值的类型为该 属性本来的类型,而BeanUtils.getProperty则是将该属性的值转换成字符串后才返回。
参考资料:
张孝祥Java基础增强
JAVA提高四:反射基本应用的更多相关文章
- Java提高合集(转载)
转载自:http://www.cnblogs.com/pony1223/p/7643842.html Java提高十五:容器元素比较Comparable&Comparator深入分析 JAVA ...
- java提高篇(十四)-----关键字final
在程序设计中,我们有时可能希望某些数据是不能够改变的,这个时候final就有用武之地了.final是java的关键字,它所表示的是"这部分是无法修改的".不想被改变的原因有两个:效 ...
- 【java提高】---java反射机制
java反射机制 一.概述 1.什么是反射机制 反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法:对于任意一个对象,都能够调用它的任意一个方法和属性:这种动态获取的信息以及动态 ...
- java提高篇(二四)-----HashSet
在前篇博文中(java提高篇(二三)-----HashMap)详细讲解了HashMap的实现过程,对于HashSet而言,它是基于HashMap来实现的,底层采用HashMap来保存元素. ...
- java提高篇(四)-----理解java的三大特性之多态
面向对象编程有三大特性:封装.继承.多态. 封装隐藏了类的内部实现机制,可以在不影响使用的情况下改变类的内部结构,同时也保护了数据.对外界而已它的内部细节是隐藏的,暴露给外界的只是它的访问方法. 继承 ...
- 从零开始学java (四)反射
反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法:对于任意一个对象,都能够调用它的任意一个方法和属性:这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制. ...
- Java提高篇(二六)-----hashCode
在前面三篇博文中LZ讲解了(HashMap.HashSet.HashTable),在其中LZ不断地讲解他们的put和get方法,在这两个方法中计算key的hashCode应该是最重要也是最 ...
- 【java提高】(16)---java注解(Annotation)
java提高(16)---java注解 注解含义注解是JDK1.5之后才有的新特性,它相当于一种标记,在程序中加入注解就等于为程序打上某种标记,之后又通过类的反射机制来解析注解. 一.JDK自带注解 ...
- Java的四种内部类
Java的四种内部类包括如下: 成员内部类 静态内部类 局部内部类 匿名内部类 成员内部类: 定义在另一个类(外部类)的内部,而且与成员方法和属性平级叫成员内部类,......相当于外部类的非静态方法 ...
随机推荐
- Markdown(editormd)语法解析成html
我们在一些网站中可以见到一款网页编辑器--markdown: 这是一款功能强大的富文本编辑器,之前自己在网页上使用的时候遇到了一点点的问题,现在跟大家分享下 在我们写了文章之后是需要将内容保存到数据库 ...
- 一些LVS实验配置、工具和方案
最近做了一些LVS配置和方案的验证实验,将过程中用到的一些配置.工具和具体的解决方案记录一下.使用DR模式.验证一种不中断业务的RealServer升级或者重启方案. 网络规划: 节点 IP地址 ce ...
- 团队作业8----第二次项目冲刺(Beta阶段) 第三天
BETA阶段冲刺第三天 1.小会议ing 2.每个人的工作 (1) 昨天已完成的工作 注册账号时时添加了账号相同不能添加的功能,以防两个账号一样的情况: 老师账号注册时添加一个密令: (2) 今天计划 ...
- 团队作业八-Beta版本冲刺计划及安排
Beta版本冲刺计划及安排 目录: 1.介绍小组新加入的成员,他担任的角色 2.下一阶段需要改进完善的功能 3.下一阶段新增(或修改)的功能 4.需要改进的团队分工 5.需要改进的工具流程 6.冲刺的 ...
- 201521123007《Java程序设计》第4周学习总结
1. 本周学习总结 1.1 尝试使用思维导图总结有关继承的知识点. 1.2 使用常规方法总结其他上课内容. 1.1有关继承的知识点: 1.2有关多态 多态性:相同的形态,不同的行为.体现在相同的方法名 ...
- 201521123113 《Java程序设计》第2周学习总结
1.本周学习总结 学习了各种java数据类型以及各种运算符的使用 string类之所以好用是因为这是人可以看得懂的类型,操作简便 Scanner扫描器与标准输出输入用法上的不同,Scanner较标准输 ...
- 201521123092,《java程序设计》第1周学习总结
1.本周学习总结 这一周是我学习java的第一周,刚接触一门全新的编程语言,觉得还是有点困难的,很多基础性的java知识需要一点点学习,我会请教同学以及查询网上的学习资料,认真学好这一门学科. 本周学 ...
- Java课设-购物车系统
1.团队课程设计博客链接 /[博客链接]http://www.cnblogs.com/yayaya/p/7062197.html 2.个人负责模板或任务说明 1.建立Action类 2.购物车的属性 ...
- 201521123119《Java程序设计》第9周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结异常相关内容. 2. 书面作业 本次PTA作业题集异常 Q1.常用异常 题目5-1 Q1.1 截图你的提交结果(出现学号) Q1.2 ...
- 201521123089 《Java程序设计》第9周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结异常相关内容. 2. 书面作业 本次PTA作业题集异常 常用异常 题目5-11.1 截图你的提交结果(出现学号) 1.2 自己以前编 ...