mahout-distribution-0.9.tar.gz的安装的与配置、启动与运行自带的mahout算法
不多说,直接上干货!
首先,别在windows下搭建什么,安装什么Cygwin啊!直接在linux,对于企业里推荐用CentOS6.5,在学校里用Ubuntu。
Mahout安装所需软件清单:
软件 版本 说明
操作系统 CentOS6.5 64位
JDK jdk1.7.0_79
Hadoop 2.6.0
Mahout mahout-distribution-0.8
为什么采用这个版本,而不是0.9及其以后的版本,是因为差别有点大,比如fpg关联规则算法。以及网上参考资料少
说在前面的话,
关于Mahout的安装配置,这里介绍两种方式:其一,下载源码(直接下载源码或者通过svn下载源码都可以),然后使用Maven进行编译;其二,下载完整包进行解压缩。这里我使用的是完整包进行解压缩安装。
一、 mahout-distribution-0.8.tar.gz的下载
http://archive.apache.org/dist/mahout/0.8/
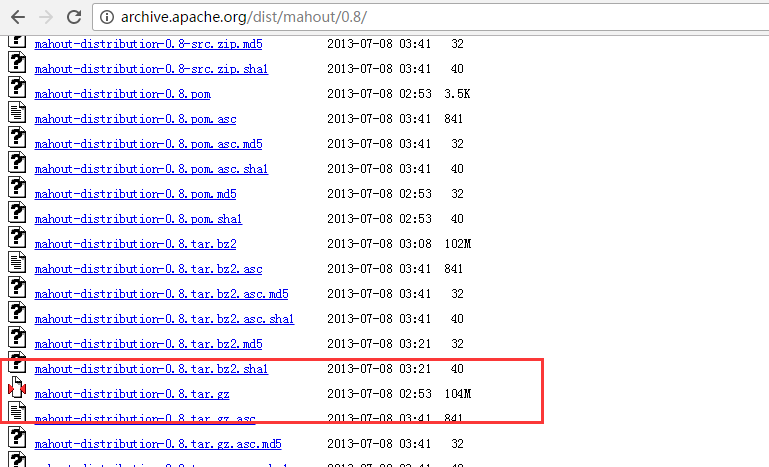
我这里,以稳定版本mahout-0.9为例
当然,这里也可以使用wget命令在线下载,很简单,不多说。
二、 mahout-distribution-0.8.tar.gz的安装
1、先新建好目录
我一般喜欢在/usr/loca/下新建
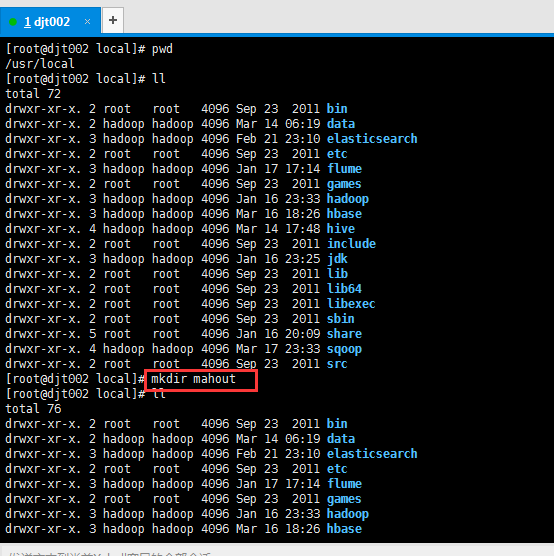

[root@djt002 local]# pwd
/usr/local
[root@djt002 local]# ll
total
drwxr-xr-x. root root Sep bin
drwxr-xr-x. hadoop hadoop Mar : data
drwxr-xr-x. hadoop hadoop Feb : elasticsearch
drwxr-xr-x. root root Sep etc
drwxr-xr-x. hadoop hadoop Jan : flume
drwxr-xr-x. root root Sep games
drwxr-xr-x. hadoop hadoop Jan : hadoop
drwxr-xr-x. hadoop hadoop Mar : hbase
drwxr-xr-x. hadoop hadoop Mar : hive
drwxr-xr-x. root root Sep include
drwxr-xr-x. hadoop hadoop Jan : jdk
drwxr-xr-x. root root Sep lib
drwxr-xr-x. root root Sep lib64
drwxr-xr-x. root root Sep libexec
drwxr-xr-x. root root Sep sbin
drwxr-xr-x. root root Jan : share
drwxr-xr-x. hadoop hadoop Mar : sqoop
drwxr-xr-x. root root Sep src
[root@djt002 local]# mkdir mahout
[root@djt002 local]# ll
total
drwxr-xr-x. root root Sep bin
drwxr-xr-x. hadoop hadoop Mar : data
drwxr-xr-x. hadoop hadoop Feb : elasticsearch
drwxr-xr-x. root root Sep etc
drwxr-xr-x. hadoop hadoop Jan : flume
drwxr-xr-x. root root Sep games
drwxr-xr-x. hadoop hadoop Jan : hadoop
drwxr-xr-x. hadoop hadoop Mar : hbase
drwxr-xr-x. hadoop hadoop Mar : hive
drwxr-xr-x. root root Sep include
drwxr-xr-x. hadoop hadoop Jan : jdk
drwxr-xr-x. root root Sep lib
drwxr-xr-x. root root Sep lib64
drwxr-xr-x. root root Sep libexec
drwxr-xr-x root root Apr : mahout
drwxr-xr-x. root root Sep sbin
drwxr-xr-x. root root Jan : share
drwxr-xr-x. hadoop hadoop Mar : sqoop
drwxr-xr-x. root root Sep src
[root@djt002 local]# chown -R hadoop:hadoop mahout
[root@djt002 local]# ll
total
drwxr-xr-x. root root Sep bin
drwxr-xr-x. hadoop hadoop Mar : data
drwxr-xr-x. hadoop hadoop Feb : elasticsearch
drwxr-xr-x. root root Sep etc
drwxr-xr-x. hadoop hadoop Jan : flume
drwxr-xr-x. root root Sep games
drwxr-xr-x. hadoop hadoop Jan : hadoop
drwxr-xr-x. hadoop hadoop Mar : hbase
drwxr-xr-x. hadoop hadoop Mar : hive
drwxr-xr-x. root root Sep include
drwxr-xr-x. hadoop hadoop Jan : jdk
drwxr-xr-x. root root Sep lib
drwxr-xr-x. root root Sep lib64
drwxr-xr-x. root root Sep libexec
drwxr-xr-x hadoop hadoop Apr : mahout
drwxr-xr-x. root root Sep sbin
drwxr-xr-x. root root Jan : share
drwxr-xr-x. hadoop hadoop Mar : sqoop
drwxr-xr-x. root root Sep src
[root@djt002 local]#
2、上传mahout压缩包

[root@djt002 local]# su hadoop
[hadoop@djt002 local]$ cd mahout/
[hadoop@djt002 mahout]$ pwd
/usr/local/mahout
[hadoop@djt002 mahout]$ ll
total
[hadoop@djt002 mahout]$ rz [hadoop@djt002 mahout]$ ll
total
-rw-r--r-- hadoop hadoop Apr : mahout-distribution-0.8.tar.gz
[hadoop@djt002 mahout]$
3、解压
[hadoop@djt002 mahout]$ pwd
/usr/local/mahout
[hadoop@djt002 mahout]$ ll
total
-rw-r--r-- hadoop hadoop Apr : mahout-distribution-0.8.tar.gz
[hadoop@djt002 mahout]$ tar -zxvf mahout-distribution-0.9.tar.gz
4、删除压缩包和赋予用户组
[hadoop@djt002 mahout]$ pwd
/usr/local/mahout
[hadoop@djt002 mahout]$ ll
total
drwxrwxr-x hadoop hadoop Apr : mahout-distribution-0.8
-rw-r--r-- hadoop hadoop Apr : mahout-distribution-0.8.tar.gz
[hadoop@djt002 mahout]$ rm mahout-distribution-0.9.tar.gz
[hadoop@djt002 mahout]$ ll
total
drwxrwxr-x hadoop hadoop Apr : mahout-distribution-0.8
[hadoop@djt002 mahout]$
5、mahout的配置
[root@djt002 mahout-distribution-0.8]# pwd
/usr/local/mahout/mahout-distribution-0.8
[root@djt002 mahout-distribution-0.8]# vim /etc/profile

#mahout
export MAHOUT_HOME=/usr/local/mahout/mahout-distribution-0.8
export MAHOUT_HOME_CONF_DIR=/usr/local/mahout/mahout-distribution-0.8/conf
export PATH=$PATH:$MAHOUT_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib:$MAHOUT_HOME/lib:$JRE_HOME/lib:$CLASSPATH
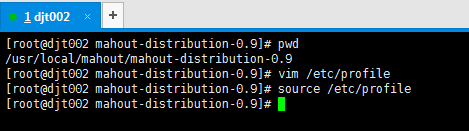
[root@djt002 mahout-distribution-0.9]# source /etc/profile
认识下mahout的目录结构
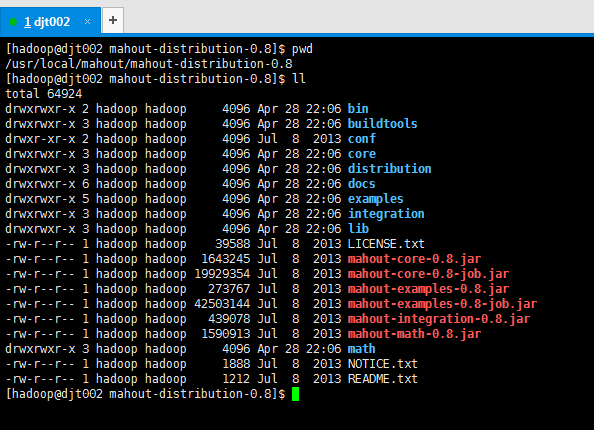
[hadoop@djt002 mahout-distribution-0.8]$ pwd
/usr/local/mahout/mahout-distribution-0.8
[hadoop@djt002 mahout-distribution-0.8]$ ll
total
drwxrwxr-x hadoop hadoop Apr : bin
drwxrwxr-x hadoop hadoop Apr : buildtools
drwxr-xr-x hadoop hadoop Jul conf
drwxrwxr-x hadoop hadoop Apr : core
drwxrwxr-x hadoop hadoop Apr : distribution
drwxrwxr-x hadoop hadoop Apr : docs
drwxrwxr-x hadoop hadoop Apr : examples
drwxrwxr-x hadoop hadoop Apr : integration
drwxrwxr-x hadoop hadoop Apr : lib
-rw-r--r-- hadoop hadoop Jul LICENSE.txt
-rw-r--r-- hadoop hadoop Jul mahout-core-0.8.jar
-rw-r--r-- hadoop hadoop Jul mahout-core-0.8-job.jar
-rw-r--r-- hadoop hadoop Jul mahout-examples-0.8.jar
-rw-r--r-- hadoop hadoop Jul mahout-examples-0.8-job.jar
-rw-r--r-- hadoop hadoop Jul mahout-integration-0.8.jar
-rw-r--r-- hadoop hadoop Jul mahout-math-0.8.jar
drwxrwxr-x hadoop hadoop Apr : math
-rw-r--r-- hadoop hadoop Jul NOTICE.txt
-rw-r--r-- hadoop hadoop Jul README.txt
[hadoop@djt002 mahout-distribution-0.8]$
三、验证mahout是否安装成功
[hadoop@djt002 mahout-distribution-0.8]$ bin/mahout --help
Running on hadoop, using /usr/local/hadoop/hadoop-2.6./bin/hadoop and HADOOP_CONF_DIR=
MAHOUT-JOB: /usr/local/mahout/mahout-distribution-0.9/mahout-examples-0.9-job.jar
Unknown program '--help' chosen.
Valid program names are:
arff.vector: : Generate Vectors from an ARFF file or directory
baumwelch: : Baum-Welch algorithm for unsupervised HMM training
canopy: : Canopy clustering
cat: : Print a file or resource as the logistic regression models would see it
cleansvd: : Cleanup and verification of SVD output
clusterdump: : Dump cluster output to text
clusterpp: : Groups Clustering Output In Clusters
cmdump: : Dump confusion matrix in HTML or text formats
concatmatrices: : Concatenates matrices of same cardinality into a single matrix
cvb: : LDA via Collapsed Variation Bayes (0th deriv. approx)
cvb0_local: : LDA via Collapsed Variation Bayes, in memory locally.
evaluateFactorization: : compute RMSE and MAE of a rating matrix factorization against probes
fkmeans: : Fuzzy K-means clustering
hmmpredict: : Generate random sequence of observations by given HMM
itemsimilarity: : Compute the item-item-similarities for item-based collaborative filtering
kmeans: : K-means clustering
lucene.vector: : Generate Vectors from a Lucene index
lucene2seq: : Generate Text SequenceFiles from a Lucene index
matrixdump: : Dump matrix in CSV format
matrixmult: : Take the product of two matrices
parallelALS: : ALS-WR factorization of a rating matrix
qualcluster: : Runs clustering experiments and summarizes results in a CSV
recommendfactorized: : Compute recommendations using the factorization of a rating matrix
recommenditembased: : Compute recommendations using item-based collaborative filtering
regexconverter: : Convert text files on a per line basis based on regular expressions
resplit: : Splits a set of SequenceFiles into a number of equal splits
rowid: : Map SequenceFile<Text,VectorWritable> to {SequenceFile<IntWritable,VectorWritable>, SequenceFile<IntWritable,Text>}
rowsimilarity: : Compute the pairwise similarities of the rows of a matrix
runAdaptiveLogistic: : Score new production data using a probably trained and validated AdaptivelogisticRegression model
runlogistic: : Run a logistic regression model against CSV data
seq2encoded: : Encoded Sparse Vector generation from Text sequence files
seq2sparse: : Sparse Vector generation from Text sequence files
seqdirectory: : Generate sequence files (of Text) from a directory
seqdumper: : Generic Sequence File dumper
seqmailarchives: : Creates SequenceFile from a directory containing gzipped mail archives
seqwiki: : Wikipedia xml dump to sequence file
spectralkmeans: : Spectral k-means clustering
split: : Split Input data into test and train sets
splitDataset: : split a rating dataset into training and probe parts
ssvd: : Stochastic SVD
streamingkmeans: : Streaming k-means clustering
svd: : Lanczos Singular Value Decomposition
testnb: : Test the Vector-based Bayes classifier
trainAdaptiveLogistic: : Train an AdaptivelogisticRegression model
trainlogistic: : Train a logistic regression using stochastic gradient descent
trainnb: : Train the Vector-based Bayes classifier
transpose: : Take the transpose of a matrix
validateAdaptiveLogistic: : Validate an AdaptivelogisticRegression model against hold-out data set
vecdist: : Compute the distances between a set of Vectors (or Cluster or Canopy, they must fit in memory) and a list of Vectors
vectordump: : Dump vectors from a sequence file to text
viterbi: : Viterbi decoding of hidden states from given output states sequence
[hadoop@djt002 mahout-distribution-0.9]$
出现上述的界面,说明mahout安装成功,因为,自动列出mahout已经实现的所有命令。
运行mahout自带的示例(确保hadoop集群已开启)
mahout中的算法大致可以分为三大类:
聚类,协同过滤和分类
其中
常用聚类算法有:canopy聚类,k均值算法(kmeans),模糊k均值,层次聚类,LDA聚类等
常用分类算法有:贝叶斯,逻辑回归,支持向量机,感知器,神经网络等
因为,我的版本是mahout-0.8,所以mahout-examples-0.8-job.jar。
以下是运行mahout自带的keans算法
$HADOOP_HOME/bin/hadoop jar /usr/local/mahout/mahout-distribution-0.8/mahout-examples-0.8-job.jar org.apache.mahout.clustering.syntheticcontrol.kmeans.Job 或者 以下是运行mahout自带的cnopy算法
$HADOOP_HOME/bin/hadoop jar /usr/local/mahout/mahout-distribution-0.8/mahout-examples-0.8-job.jar org.apache.mahout.clustering.syntheticcontrol.canopy.Job

[hadoop@djt002 mahout-distribution-0.9]$ $HADOOP_HOME/bin/hadoop jar /usr/local/mahout/mahout-distribution-0.9/mahout-examples-0.9-job.jar org.apache.mahout.clustering.syntheticcontrol.canopy.Job
// :: INFO canopy.Job: Running with default arguments
// :: INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:
// :: WARN mapreduce.JobSubmitter: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
// :: INFO mapreduce.JobSubmitter: Cleaning up the staging area /tmp/hadoop-yarn/staging/hadoop/.staging/job_1493332712225_0001
Exception in thread "main" org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist: hdfs://djt002:9000/user/hadoop/testdata
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.getSplits(FileInputFormat.java:)
at org.apache.hadoop.mapreduce.JobSubmitter.writeNewSplits(JobSubmitter.java:)
at org.apache.hadoop.mapreduce.JobSubmitter.writeSplits(JobSubmitter.java:)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:)
at org.apache.hadoop.mapreduce.Job$.run(Job.java:)
at org.apache.hadoop.mapreduce.Job$.run(Job.java:)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:)
at org.apache.mahout.clustering.conversion.InputDriver.runJob(InputDriver.java:)
at org.apache.mahout.clustering.syntheticcontrol.canopy.Job.run(Job.java:)
at org.apache.mahout.clustering.syntheticcontrol.canopy.Job.main(Job.java:)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.hadoop.util.RunJar.run(RunJar.java:)
at org.apache.hadoop.util.RunJar.main(RunJar.java:)
[hadoop@djt002 mahout-distribution-0.9]$
准备测试数据
练习数据下载地址:
http://download.csdn.net/detail/qq1010885678/8582941
上面的练习数据是用来检测kmeans聚类算法的数据。
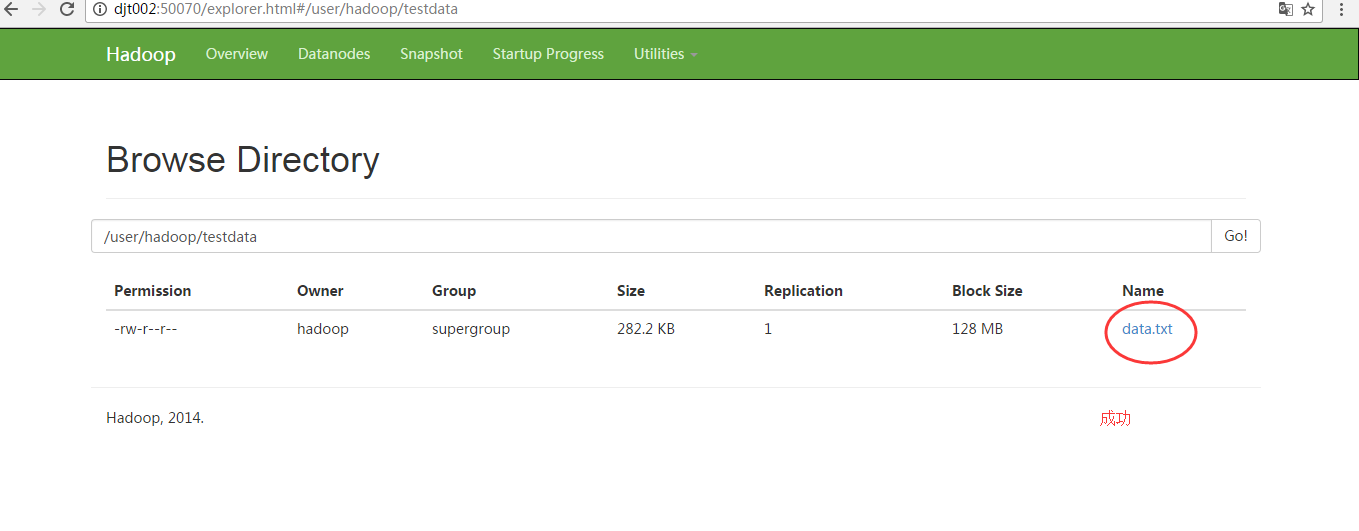
将练习数据(data.txt)上传到hdfs中对应的hdfs://djt002:9000/user/hadoop/testdata目录下即可。(这是样本数据集,可以适用各种算法)
我这里,上传测试数据。到我本地linux自己写的一个路径。(这里为了自己所需哈)
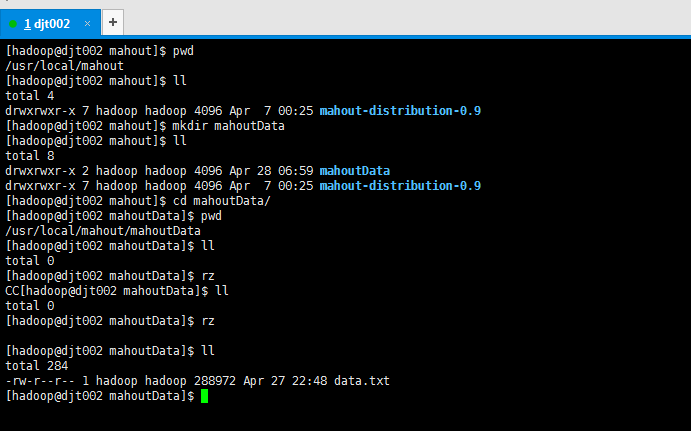
[hadoop@djt002 mahout]$ pwd
/usr/local/mahout
[hadoop@djt002 mahout]$ ll
total
drwxrwxr-x hadoop hadoop Apr : mahout-distribution-0.8
[hadoop@djt002 mahout]$ mkdir mahoutData
[hadoop@djt002 mahout]$ ll
total
drwxrwxr-x hadoop hadoop Apr : mahoutData
drwxrwxr-x hadoop hadoop Apr : mahout-distribution-0.8
[hadoop@djt002 mahout]$ cd mahoutData/
[hadoop@djt002 mahoutData]$ pwd
/usr/local/mahout/mahoutData
[hadoop@djt002 mahoutData]$ ll
total
[hadoop@djt002 mahoutData]$ rz
CC[hadoop@djt002 mahoutData]$ ll
total
[hadoop@djt002 mahoutData]$ rz [hadoop@djt002 mahoutData]$ ll
total
-rw-r--r-- hadoop hadoop Apr : data.txt
[hadoop@djt002 mahoutData]$
然后,将/usr/local/mahout/mahoutData/下的测试数据,上传到hdfs://djt002:9000/user/hadoop/testdata下

[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop fs -put /usr/local/mahout/mahoutData/data.txt hdfs://djt002:9000/user/hadoop/testdata
或者 [hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop fs -copyFromLocal /usr/local/mahout/mahoutData/data.txt hdfs://djt002:9000/user/hadoop/testdata/ [hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop fs -ls hdfs://djt002:9000/user/hadoop/testdata/
-rw-r--r-- hadoop supergroup -- : hdfs://djt002:9000/user/hadoop/testdata
也许中间会出现,这个数据集,你会上传不了。解决方案如下

[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop fs -put /usr/local/mahout/mahoutData/data.txt hdfs://djt002:9000/user/hadoop/testdata/
put: `hdfs://djt002:9000/user/hadoop/testdata': File exists
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop fs -rm hdfs://djt002:9000/user/hadoop/testdata/
// :: INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = minutes, Emptier interval = minutes.
Deleted hdfs://djt002:9000/user/hadoop/testdata
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop fs -mkdir hdfs://djt002:9000/user/hadoop/testdata/
[hadoop@djt002 mahoutData]$


[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop fs -put /usr/local/mahout/mahoutData/data.txt hdfs://djt002:9000/user/hadoop/testdata/
[hadoop@djt002 mahoutData]$
使用kmeans算法
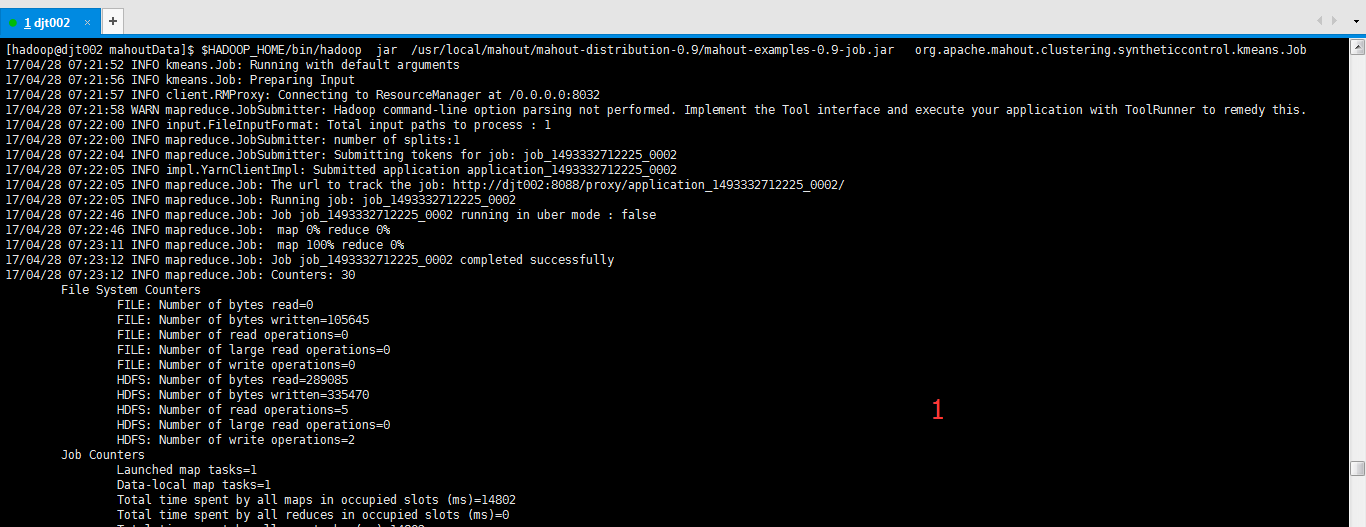
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop jar /usr/local/mahout/mahout-distribution-0.8/mahout-examples-0.8-job.jar org.apache.mahout.clustering.syntheticcontrol.kmeans.Job
注意,是不需输入路径和输出路径的啊!(自带的jar包里都已经写死了的)
(注意:如果你是选择用mahout压缩包里自带的kmeans算法的话,则它的输入路径是testdata是固定死的,
即hdfs:djt002://9000/user/hadoop/testdata/ )
并且每次运行hadoop都要删掉原来的output目录!
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop fs -rm -r hdfs://djt002:9000/user/hadoop/output/*

....
由于聚类算法是一种迭代的过程(之后会讲解)
所以,它会一直重复的执行mr任务到符合要求(这其中的过程可能有点久。。。)

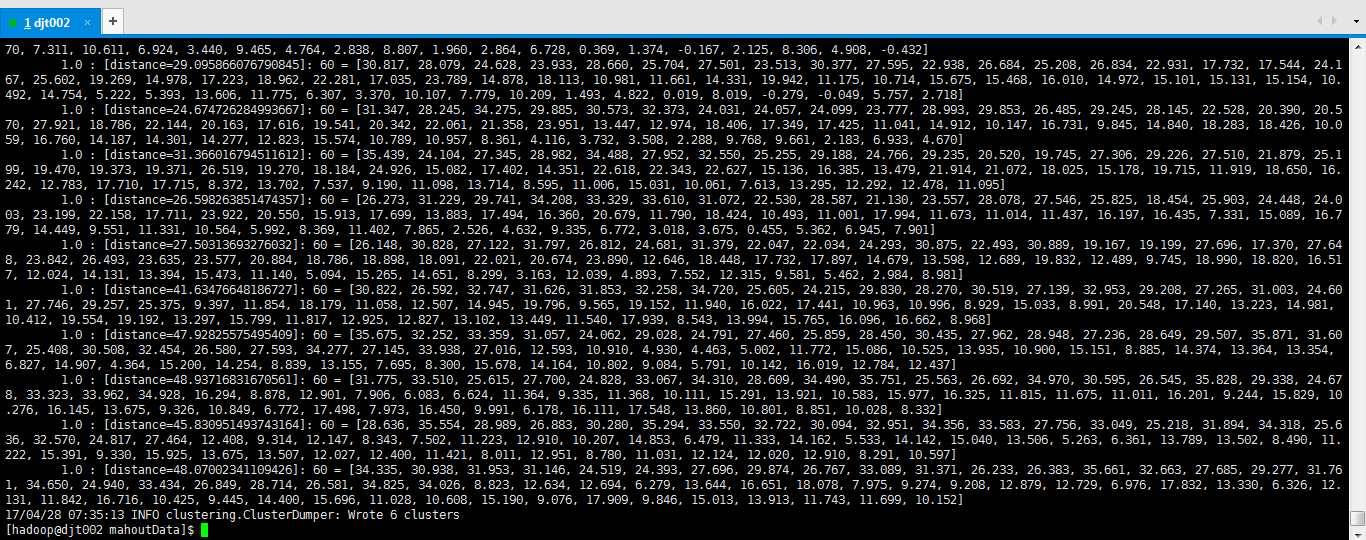
Kmeans运行结果如下:
, 7.311, 10.611, 6.924, 3.440, 9.465, 4.764, 2.838, 8.807, 1.960, 2.864, 6.728, 0.369, 1.374, -0.167, 2.125, 8.306, 4.908, -0.432]
1.0 : [distance=29.095866076790845]: = [30.817, 28.079, 24.628, 23.933, 28.660, 25.704, 27.501, 23.513, 30.377, 27.595, 22.938, 26.684, 25.208, 26.834, 22.931, 17.732, 17.544, 24.167, 25.602, 19.269, 14.978, 17.223, 18.962, 22.281, 17.035, 23.789, 14.878, 18.113, 10.981, 11.661, 14.331, 19.942, 11.175, 10.714, 15.675, 15.468, 16.010, 14.972, 15.101, 15.131, 15.154, 10.492, 14.754, 5.222, 5.393, 13.606, 11.775, 6.307, 3.370, 10.107, 7.779, 10.209, 1.493, 4.822, 0.019, 8.019, -0.279, -0.049, 5.757, 2.718]
1.0 : [distance=24.674726284993667]: = [31.347, 28.245, 34.275, 29.885, 30.573, 32.373, 24.031, 24.057, 24.099, 23.777, 28.993, 29.853, 26.485, 29.245, 28.145, 22.528, 20.390, 20.570, 27.921, 18.786, 22.144, 20.163, 17.616, 19.541, 20.342, 22.061, 21.358, 23.951, 13.447, 12.974, 18.406, 17.349, 17.425, 11.041, 14.912, 10.147, 16.731, 9.845, 14.840, 18.283, 18.426, 10.059, 16.760, 14.187, 14.301, 14.277, 12.823, 15.574, 10.789, 10.957, 8.361, 4.116, 3.732, 3.508, 2.288, 9.768, 9.661, 2.183, 6.933, 4.670]
1.0 : [distance=31.366016794511612]: = [35.439, 24.104, 27.345, 28.982, 34.488, 27.952, 32.550, 25.255, 29.188, 24.766, 29.235, 20.520, 19.745, 27.306, 29.226, 27.510, 21.879, 25.199, 19.470, 19.373, 19.371, 26.519, 19.270, 18.184, 24.926, 15.082, 17.402, 14.351, 22.618, 22.343, 22.627, 15.136, 16.385, 13.479, 21.914, 21.072, 18.025, 15.178, 19.715, 11.919, 18.650, 16.242, 12.783, 17.710, 17.715, 8.372, 13.702, 7.537, 9.190, 11.098, 13.714, 8.595, 11.006, 15.031, 10.061, 7.613, 13.295, 12.292, 12.478, 11.095]
1.0 : [distance=26.598263851474357]: = [26.273, 31.229, 29.741, 34.208, 33.329, 33.610, 31.072, 22.530, 28.587, 21.130, 23.557, 28.078, 27.546, 25.825, 18.454, 25.903, 24.448, 24.003, 23.199, 22.158, 17.711, 23.922, 20.550, 15.913, 17.699, 13.883, 17.494, 16.360, 20.679, 11.790, 18.424, 10.493, 11.001, 17.994, 11.673, 11.014, 11.437, 16.197, 16.435, 7.331, 15.089, 16.779, 14.449, 9.551, 11.331, 10.564, 5.992, 8.369, 11.402, 7.865, 2.526, 4.632, 9.335, 6.772, 3.018, 3.675, 0.455, 5.362, 6.945, 7.901]
1.0 : [distance=27.50313693276032]: = [26.148, 30.828, 27.122, 31.797, 26.812, 24.681, 31.379, 22.047, 22.034, 24.293, 30.875, 22.493, 30.889, 19.167, 19.199, 27.696, 17.370, 27.648, 23.842, 26.493, 23.635, 23.577, 20.884, 18.786, 18.898, 18.091, 22.021, 20.674, 23.890, 12.646, 18.448, 17.732, 17.897, 14.679, 13.598, 12.689, 19.832, 12.489, 9.745, 18.990, 18.820, 16.517, 12.024, 14.131, 13.394, 15.473, 11.140, 5.094, 15.265, 14.651, 8.299, 3.163, 12.039, 4.893, 7.552, 12.315, 9.581, 5.462, 2.984, 8.981]
1.0 : [distance=41.63476648186727]: = [30.822, 26.592, 32.747, 31.626, 31.853, 32.258, 34.720, 25.605, 24.215, 29.830, 28.270, 30.519, 27.139, 32.953, 29.208, 27.265, 31.003, 24.601, 27.746, 29.257, 25.375, 9.397, 11.854, 18.179, 11.058, 12.507, 14.945, 19.796, 9.565, 19.152, 11.940, 16.022, 17.441, 10.963, 10.996, 8.929, 15.033, 8.991, 20.548, 17.140, 13.223, 14.981, 10.412, 19.554, 19.192, 13.297, 15.799, 11.817, 12.925, 12.827, 13.102, 13.449, 11.540, 17.939, 8.543, 13.994, 15.765, 16.096, 16.662, 8.968]
1.0 : [distance=47.92825575495409]: = [35.675, 32.252, 33.359, 31.057, 24.062, 29.028, 24.791, 27.460, 25.859, 28.450, 30.435, 27.962, 28.948, 27.236, 28.649, 29.507, 35.871, 31.607, 25.408, 30.508, 32.454, 26.580, 27.593, 34.277, 27.145, 33.938, 27.016, 12.593, 10.910, 4.930, 4.463, 5.002, 11.772, 15.086, 10.525, 13.935, 10.900, 15.151, 8.885, 14.374, 13.364, 13.354, 6.827, 14.907, 4.364, 15.200, 14.254, 8.839, 13.155, 7.695, 8.300, 15.678, 14.164, 10.802, 9.084, 5.791, 10.142, 16.019, 12.784, 12.437]
1.0 : [distance=48.93716831670561]: = [31.775, 33.510, 25.615, 27.700, 24.828, 33.067, 34.310, 28.609, 34.490, 35.751, 25.563, 26.692, 34.970, 30.595, 26.545, 35.828, 29.338, 24.678, 33.323, 33.962, 34.928, 16.294, 8.878, 12.901, 7.906, 6.083, 6.624, 11.364, 9.335, 11.368, 10.111, 15.291, 13.921, 10.583, 15.977, 16.325, 11.815, 11.675, 11.011, 16.201, 9.244, 15.829, 10.276, 16.145, 13.675, 9.326, 10.849, 6.772, 17.498, 7.973, 16.450, 9.991, 6.178, 16.111, 17.548, 13.860, 10.801, 8.851, 10.028, 8.332]
1.0 : [distance=45.830951493743164]: = [28.636, 35.554, 28.989, 26.883, 30.280, 35.294, 33.550, 32.722, 30.094, 32.951, 34.356, 33.583, 27.756, 33.049, 25.218, 31.894, 34.318, 25.636, 32.570, 24.817, 27.464, 12.408, 9.314, 12.147, 8.343, 7.502, 11.223, 12.910, 10.207, 14.853, 6.479, 11.333, 14.162, 5.533, 14.142, 15.040, 13.506, 5.263, 6.361, 13.789, 13.502, 8.490, 11.222, 15.391, 9.330, 15.925, 13.675, 13.507, 12.027, 12.400, 11.421, 8.011, 12.951, 8.780, 11.031, 12.124, 12.020, 12.910, 8.291, 10.597]
1.0 : [distance=48.07002341109426]: = [34.335, 30.938, 31.953, 31.146, 24.519, 24.393, 27.696, 29.874, 26.767, 33.089, 31.371, 26.233, 26.383, 35.661, 32.663, 27.685, 29.277, 31.761, 34.650, 24.940, 33.434, 26.849, 28.714, 26.581, 34.825, 34.026, 8.823, 12.634, 12.694, 6.279, 13.644, 16.651, 18.078, 7.975, 9.274, 9.208, 12.879, 12.729, 6.976, 17.832, 13.330, 6.326, 12.131, 11.842, 16.716, 10.425, 9.445, 14.400, 15.696, 11.028, 10.608, 15.190, 9.076, 17.909, 9.846, 15.013, 13.913, 11.743, 11.699, 10.152]
// :: INFO clustering.ClusterDumper: Wrote clusters
[hadoop@djt002 mahoutData]$
mahout无异常!!!
注意:执行完这个kmeans算法之后产生的文件按普通方式是查看不了的,看到的只是一堆莫名其妙的数据!!!
查看聚类分析的结果:
需要用mahout的seqdumper命令来下载到本地linux上才能查看正常结果。
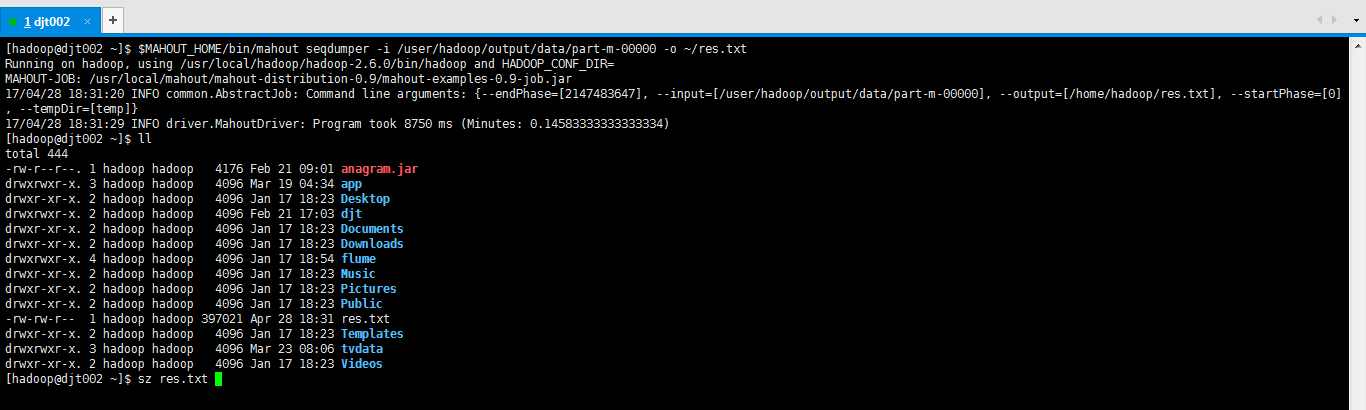
[hadoop@djt002 ~]$ $MAHOUT_HOME/bin/mahout seqdumper -i /user/hadoop/output/data/part-m-00000 -o ~/res.txt
[hadoop@djt002 ~]$ $MAHOUT_HOME/bin/mahout seqdumper -i /user/hadoop/output/data/part-m- -o ~/res.txt
Running on hadoop, using /usr/local/hadoop/hadoop-2.6./bin/hadoop and HADOOP_CONF_DIR=
MAHOUT-JOB: /usr/local/mahout/mahout-distribution-0.9/mahout-examples-0.9-job.jar
// :: INFO common.AbstractJob: Command line arguments: {--endPhase=[], --input=[/user/hadoop/output/data/part-m-], --output=[/home/hadoop/res.txt], --startPhase=[], --tempDir=[temp]}
// :: INFO driver.MahoutDriver: Program took ms (Minutes: 0.14583333333333334)
[hadoop@djt002 ~]$ ll
total
-rw-r--r--. hadoop hadoop Feb : anagram.jar
drwxrwxr-x. hadoop hadoop Mar : app
drwxr-xr-x. hadoop hadoop Jan : Desktop
drwxrwxr-x. hadoop hadoop Feb : djt
drwxr-xr-x. hadoop hadoop Jan : Documents
drwxr-xr-x. hadoop hadoop Jan : Downloads
drwxrwxr-x. hadoop hadoop Jan : flume
drwxr-xr-x. hadoop hadoop Jan : Music
drwxr-xr-x. hadoop hadoop Jan : Pictures
drwxr-xr-x. hadoop hadoop Jan : Public
-rw-rw-r-- hadoop hadoop Apr : res.txt
drwxr-xr-x. hadoop hadoop Jan : Templates
drwxrwxr-x. hadoop hadoop Mar : tvdata
drwxr-xr-x. hadoop hadoop Jan : Videos
[hadoop@djt002 ~]$ sz res.txt
Input Path: /user/hadoop/output/data/part-m-
Key class: class org.apache.hadoop.io.Text Value Class: class org.apache.mahout.math.VectorWritable
Key: : Value: {:28.7812,:26.6311,:29.1495,:28.9207,:35.6541,:33.7596,:35.2479,:25.3969,:25.0293,:33.0292,:34.9424,:26.5235,:24.5556,:26.1927,:36.0253,:29.5054,:25.4652,:29.27,:29.2171,:32.8717,:32.8717,:27.7849,:26.1203,:28.0721,:28.4353,:34.9879,:34.9318,:25.04,:31.2834,:29.747,:26.2353,:34.4632,:28.9167,:31.0558,:33.3182,:32.4721,:28.9964,:24.3437,:31.4333,:34.1173,:35.5344,:35.4973,:27.0443,:27.1159,:33.7431,:32.337,:32.0036,:26.3693,:25.8717,:31.3381,:25.7744,:27.6623,:30.7326,:28.1584,:33.3759,:34.2553,:30.9772,:28.9402,:34.5249,:25.0466}
Key: : Value: {:24.8923,:32.5981,:26.9414,:27.8789,:28.3038,:31.5926,:27.9516,:31.4861,:34.0765,:31.9874,:25.0701,:35.6273,:31.0205,:33.1089,:27.4867,:30.4719,:32.1005,:24.1311,:31.1887,:27.5415,:24.488,:35.5469,:33.6472,:26.3458,:26.1471,:26.4244,:33.6564,:33.6615,:32.8217,:29.4047,:26.5301,:25.741,:25.5511,:32.8357,:24.1491,:28.4661,:24.8578,:30.4686,:32.5577,:27.5918,:35.9519,:28.9861,:25.7906,:31.6595,:26.6418,:31.391,:25.9562,:31.4167,:26.691,:27.5532,:30.7447,:35.4102,:35.1422,:31.5203,:34.2484,:28.5322,:28.5157,:30.6213,:27.811,:28.4331}
Key: : Value: {:31.3987,:24.246,:31.6114,:27.8613,:26.9631,:28.5491,:25.2239,:24.9717,:27.3086,:24.3323,:28.8778,:32.5614,:26.5966,:27.4809,:28.2572,:32.3851,:29.5446,:31.4781,:27.2587,:31.8387,:35.0625,:32.4358,:31.5137,:29.6082,:25.2919,:29.9897,:25.5772,:30.2001,:24.2905,:27.1717,:31.0561,:30.6316,:31.2452,:31.4391,:24.2075,:31.351,:26.3583,:26.6814,:33.6318,:31.5717,:32.6293,:34.1444,:35.1253,:27.3068,:25.5387,:26.5819,:28.0861,:34.1202,:29.343,:26.3983,:26.9337,:31.0308,:35.0173,:24.7131,:33.9002,:27.3057,:26.8059,:35.9725,:24.0455,:32.5434}
Key: : Value: {:25.774,:28.3714,:35.9346,:27.97,:32.3667,:25.2702,:31.4549,:28.132,:27.5587,:29.2806,:24.824,:35.0966,:28.7261,:24.3749,:29.9578,:31.6264,:27.3659,:25.0102,:28.9916,:28.9564,:24.3037,:29.4268,:25.5265,:35.769,:26.9752,:32.5492,:34.6156,:34.2021,:25.6033,:31.156,:26.8908,:30.5262,:26.5077,:34.3336,:27.6083,:30.9827,:31.3209,:32.2279,:34.6292,:24.314,:32.4185,:34.2054,:29.8557,:27.32,:28.2979,:30.2773,:29.3849,:32.0968,:25.3069,:35.4209,:33.3303,:25.3679,:35.3155,:35.1146,:24.8938,:24.7381,:27.8433,:31.8725,:30.4447,:31.5787}
Key: : Value: {:27.1798,:33.4129,:29.6526,:24.6555,:26.9245,:28.9446,:24.5596,:35.798,:33.1247,:24.6081,:28.0295,:31.1274,:27.9601,:24.5119,:35.4154,:33.0321,:31.1057,:31.6565,:25.3216,:27.9634,:29.4686,:34.9446,:35.8773,:29.1348,:30.2123,:29.9993,:35.3375,:33.2025,:25.6264,:34.9244,:27.9072,:29.2498,:27.4335,:33.833,:33.9931,:34.2149,:35.111,:32.6355,:27.7218,:33.1739,:31.2651,:32.3223,:33.204,:34.2366,:35.7198,:34.862,:35.0757,:26.5173,:31.0179,:33.6928,:28.6486,:31.3701,:35.9497,:30.8644,:33.1276,:25.9481,:33.3094,:24.2875,:25.1472,:27.576}
....
....


当然,你可以去看输出目录下/user/hadoop/output的其他的,比如clusters-0、clusters-1等,我这里仅仅是
看的是/user/hadoop/output/data/下的。
使用canopy算法
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop jar /usr/local/mahout/mahout-distribution-0.8/mahout-examples-0.8-job.jar org.apache.mahout.clustering.syntheticcontrol.canopy.Job
这里不多赘述。
使用dirichlet 算法
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop jar /usr/local/mahout/mahout-distribution-0.8/mahout-examples-0.8-job.jar org.apache.mahout.clustering.syntheticcontrol.dirichlet.Job
这里不多赘述。
使用meanshift算法
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop jar /usr/local/mahout/mahout-distribution-0.8/mahout-examples-0.8-job.jar org.apache.mahout.clustering.syntheticcontrol.meanshift.Job
这里不多赘述。
总结
mahout压缩包,给我们的默认输入路径是/user/hadoop/testdata 和 输出路径是 /user/hadoop/output
其实,我们是自己可以跟上自定义的输入路径和自定义输出路径的。
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop jar /usr/local/mahout/mahout-distribution-0.8/mahout-examples-0.8-job.jar org.apache.mahout.clustering.syntheticcontrol.kmeans.Job
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop jar /usr/local/mahout/mahout-distribution-0.8/mahout-examples-0.8-job.jar org.apache.mahout.clustering.syntheticcontrol.kmeans.Job -i /user/hadoop/mahoutData/data.txt -o /user/hadoop/output
mahout-distribution-0.9.tar.gz的安装的与配置、启动与运行自带的mahout算法的更多相关文章
- Linux下编译安装mysql-5.0.45.tar.gz
安装环境:VMware9(桥接模式) + Linux bogon 2.6.32-642.3.1.el6.x86_64(查看linux版本信息:uname -a) 先给出MySQL For Linux ...
- Centos6.5 安装 MariaDB-10.0.20-linux-x86_64.tar.gz
下载mariadb :https://downloads.mariadb.org/ 我选择mariadb-10.0.20-linux-x86_64.tar.gz这个版本 复制安装文件 /opt 目录 ...
- 手动安装mysql-5.0.45.tar.gz
Linux下编译安装 安装环境:VMware9(桥接模式) + Linux bogon 2.6.32-642.3.1.el6.x86_64(查看linux版本信息:uname -a) 先给出MySQL ...
- Apache-kylin-2.0.0-bin-hbase1x.tar.gz的下载与安装(图文详解)
首先,对于Apache Kylin的安装,我有话要说. 由于Apache Kylin本身只是一个Server,所以安装部署还是比较简单的.但是它的前提要求是Hadoop.Hive.HBase必须已经安 ...
- redis-5.0.5.tar.gz 安装
参考5.0安装,地址:https://my.oschina.net/u/3367404/blog/2979102 前言 安装Redis需要知道自己需要哪个版本,有针对性的安装. 比如如果需要redis ...
- 编译安装 keepalived-2.0.16.tar.gz
一.下载安装包 wget https://www.keepalived.org/software/keepalived-2.0.16.tar.gz 安装相关依赖 把所有的rpm包放在一个目录下. rp ...
- linux安装 redis(redis-3.0.2.tar.gz) 和 mongodb(mongodb-linux-x86_64-rhel62-4.0.0)
1:首先 要下载 这两个 压缩包 注意:liunx是否已经安装过 gcc没安装的话 先安装:yum install gcc-c++ 2:安装 redis:redis-3.0.2.tar.gz (1): ...
- linux下安装nginx(nginx(nginx-1.8.0.tar.gz),openssl(openssl-fips-2.0.9.tar.gz) ,zlib(zlib-1.2.11.tar.gz),pcre(pcre-8.39.tar.gz))
:要按顺序安装: 1:先检查是否安装 gcc ,没有先安装:通过yum install gcc-c++完成安 2:openssl : tar -zxf openssl-fips-2.0.9.tar. ...
- 在Foreda上安装apache-tomcat-7.0.42.tar.gz
开发环境JDK和Tomcat应该和部署环境一致,要不容易出现奇奇怪怪的问题.所以Aspire机器上的Tomcat要装一个新版本了. 装Tomcat基本等于一个解压和移动的过程,确实简单. 第一步:解压 ...
随机推荐
- COGS——T 21. [HAOI2005] 希望小学
http://www.cogs.pro/cogs/problem/problem.php?pid=21 ★★ 输入文件:hopeschool.in 输出文件:hopeschool.out ...
- vmware启动虚拟机报错VMware Workstation has paused this virtual machine because the disk on which the virtual machine is stored is almost full. To continue, free an additional 1.4 GB of disk space.
报错VMware Workstation has paused this virtual machine because the disk on which the virtual machine i ...
- Codeforces 558C Amr and Chemistry 全都变相等
题意:给定一个数列,每次操作仅仅能将某个数乘以2或者除以2(向下取整). 求最小的操作次数使得全部的数都变为同样值. 比赛的时候最后没实现.唉.之后才A掉.開始一直在想二分次数,可是半天想不出怎 ...
- 理解ThreadLocal类
1 ThreadLocal是什么 早在JDK 1.2的版本号中就提供java.lang.ThreadLocal,ThreadLocal为解决多线程程序的并发问题提供了一种新的思路. 使用这个工具类能够 ...
- 特定位取反(js实现)
去华为面试的时候.没有做好准备工作.面试的流程没有问清也没有查,结果一过去就让上机做题,着实有点措手不及.笔者是擅长前端的Java Webproject师啊,主要的底层编程知识早已生疏了.机试题碰到了 ...
- Hadoop的多节点集群详细启动步骤(3或5节点)
版本1 利用自己写的脚本来启动,见如下博客 hadoop-2.6.0-cdh5.4.5.tar.gz(CDH)的3节点集群搭建 hadoop-2.6.0.tar.gz的集群搭建(3节点) hadoop ...
- 【实用篇】获取Android通讯录中联系人信息
第一步,在Main.xml布局文件中声明一个Button控件,布局文件代码如下: <LinearLayout xmlns:android="http://schemas.android ...
- Alternating Sum
http://codeforces.com/problemset/problem/963/A 不考虑正负的话,每两项之间之间公比为b/a,考虑正负,则把k段作为循环节,循环节育循环节之间公比为(b/a ...
- PatentTips - Virtual translation lookaside buffer
BACKGROUND OF THE INVENTION A conventional virtual-machine monitor (VM monitor) typically runs on a ...
- OCP-1Z0-051-题目解析-第26题
26. Which is the valid CREATE TABLE statement? A. CREATE TABLE emp9$# (emp_no NUMBER (4)); B. CRE ...