用Python实现阿里钉钉机器人读取数据库内容自动发群通知
最近想把一些预警数据信息按照一定的要求自动发送到移动端APP,最终把目标放在了腾讯的微信和阿里的钉钉软件上,由于刚开始学习python,于是编程工具想用python来实现。微信使用群体最广,通过一天的研究用itchat库已经实现,但由于itchat需要用web微信方式登录,发现微信对新注册的用户关闭了web微信功能,于是考虑用备选方案阿里钉钉来实现,其实阿里钉钉虽然没有微信用户群体庞大,但是在企业应用方面比微信强大了太多,很多企业已经开始开始用钉钉作为内部沟通工具。
一、工作准备
1、Python工作环境搭建(略)
需要用到两个模块
# pip install apscheduler
# pip install pymysql
2、申请阿里钉钉webhok,首先在群设置里面添加自定义机器人

找到webhook地址复制备用。

二、编写代码如下
from datetime import datetime
import json
import urllib.request
import pymysql as pms
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.schedulers.background import BackgroundScheduler
import time
import os
#Mac下关闭ssl验证用到以下模块
import ssl '''
----------------------------------------------
# 需要CMD命令下安装以下支持库:
# pip install apscheduler
# pip install pymysql
# By wzy 2018-9-28
----------------------------------------------
'''
#Mac下关闭ssl验证,不然会报错
ssl._create_default_https_context = ssl._create_unverified_context #你的钉钉机器人url
global myurl
my_url = "https://oapi.dingtalk.com/robot/send?access_token=XXXXXXXXXXXX" def send_request(url, datas):
#传入url和内容发送请求
# 构建一下请求头部
header = {
"Content-Type": "application/json",
"Charset": "UTF-8"
}
sendData = json.dumps(datas) # 将字典类型数据转化为json格式
sendDatas = sendData.encode("utf-8") # python3的Request要求data为byte类型
# 发送请求
request = urllib.request.Request(url=url, data=sendDatas, headers=header)
# 将请求发回的数据构建成为文件格式
opener = urllib.request.urlopen(request)
# 打印返回的结果
print(opener.read()) def get_mysqldatas(sql):
# 一个传入sql导出数据的函数,实例为MySQL需要先安装pymysql库,cmd窗口命令:pip install pymysql
# 跟数据库建立连接
conn = pms.connect(host='服务器地址', user='用户名', passwd='密码', database='数据库', port=3306, charset="utf8")
# 使用 cursor() 方法创建一个游标对象
cur = conn.cursor()
# 使用 execute() 方法执行 SQL
cur.execute(sql) # 获取所需要的数据
datas = cur.fetchall() # 关闭连接
cur.close()
# 返回所需的数据
return datas def get_ddmodel_datas(type):
#返回钉钉模型数据,1:文本;2:markdown所有人;3:markdown带图片,@接收人;4:link类型
if type == 1:
my_data = {
"msgtype": "text",
"text": {
"content": " "
},
"at": {
"atMobiles": [
"188XXXXXXX"
],
"isAtAll": False
}
}
elif type == 2:
my_data = {
"msgtype": "markdown",
"markdown": {"title": " ",
"text": " "
},
"at": {
"isAtAll": True
}
}
elif type == 3:
my_data = {
"msgtype": "markdown",
"markdown": {"title":" ",
"text":" "
},
"at": {
"atMobiles": [
"188XXXXXXXX"
],
"isAtAll": False
}
}
elif type == 4:
my_data = {
"msgtype": "link",
"link": {
"text":" ",
"title": " ",
"picUrl": "",
"messageUrl": " "
}
}
return my_data def main():
print('Main! The time is: %s' % datetime.now())
#按照钉钉给的数据格式设计请求内容 链接https://open-doc.dingtalk.com/docs/doc.htm?spm=a219a.7629140.0.0.p7hJKp&treeId=257&articleId=105735&docType=1
#调用钉钉机器人全局变量myurl
global myurl #1.Text类型群发消息
#合并标题和数据
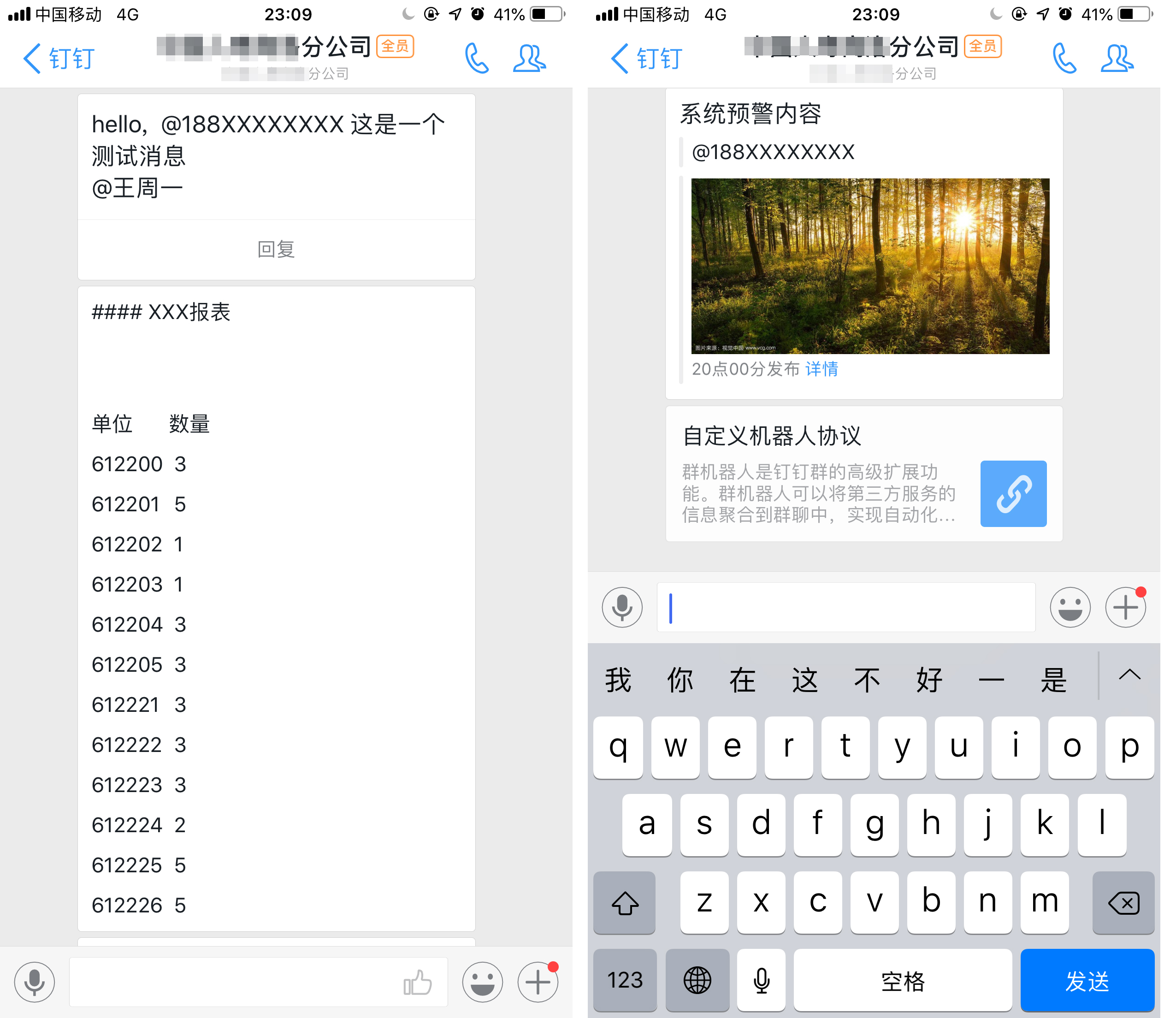
My_content = "hello, @188XXXXXXXX 这是一个测试消息"
my_data = get_ddmodel_datas(1)
#把文本内容写入请求格式中
my_data["text"]["content"] = My_content
send_request(my_url, my_data) #2.Markdown类型群发消息(MySQL查询结果发送)
#获取sql数据
sql = "SELECT branch_no,count(*) from wzy_customer_user group by branch_no order by branch_no"
my_mydata = get_mysqldatas(sql)
str1 = '\t\n\r'
seq = []
for i in range(len(my_mydata)):
seq.append(str(my_mydata[i]))
data = str1.join(seq)
data = data.replace('\'','')
data = data.replace('(','')
data = data.replace(')','')
data = data.replace(',','\t')
print(data) Mytitle = "#### XXX报表\r\n单位\t数量\t\n\r %s"
my_Mytitle = Mytitle.join('\t\n') % data
my_data = get_ddmodel_datas(2)
my_data["markdown"]["title"] ="XXXX 通报"
my_data["markdown"]["text"] = my_Mytitle
send_request(my_url, my_data) #3.Markdown(带图片@对象)
my_data = get_ddmodel_datas(3)
my_data["markdown"]["title"] = "系统预警"
my_data["markdown"]["text"] = "#### 系统预警内容 \n > @188XXXXXXXX \n\n > \n > ###### 20点00分发布 [详情](http://www.baidu.cn/)"
send_request(my_url, my_data) #4.Link类型群发消息
my_data = get_ddmodel_datas(4)
my_data["link"]["text"] = "群机器人是钉钉群的高级扩展功能。群机器人可以将第三方服务的信息聚合到群聊中,实现自动化的信息同步。 "
my_data["link"]["title"] = "自定义机器人协议"
my_data["link"]["messageUrl"] = "https://open-doc.dingtalk.com/docs/doc.htm?spm=a219a.7629140.0.0.Rqyvqo&treeId=257&articleId=105735&docType=1"
send_request(my_url, my_data) if __name__ == "__main__":
#定时执行任务,需要先安装apscheduler库,cmd窗口命令:pip install apscheduler
#随脚本执行
#scheduler = BlockingScheduler()
#后台执行
scheduler = BackgroundScheduler() #每隔20秒执行一次
scheduler.add_job(main, 'interval', seconds=20)
'''
***定时执行示例***
#固定时间执行一次
#sched.add_job(main, 'cron', year=2018, month=9, day=28, hour=15, minute=40, second=30)
#表示2017年3月22日17时19分07秒执行该程序
scheduler.add_job(my_job, 'cron', year=2017,month = 03,day = 22,hour = 17,minute = 19,second = 07) #表示任务在6,7,8,11,12月份的第三个星期五的00:00,01:00,02:00,03:00 执行该程序
scheduler.add_job(my_job, 'cron', month='6-8,11-12', day='3rd fri', hour='0-3') #表示从星期一到星期五5:30(AM)直到2014-05-30 00:00:00
scheduler.add_job(my_job(), 'cron', day_of_week='mon-fri', hour=5, minute=30,end_date='2014-05-30') #表示每5秒执行该程序一次,相当于interval 间隔调度中seconds = 5
scheduler.add_job(my_job, 'cron',second = '*/5')
'''
scheduler.start()
print('Press Ctrl+{0} to exit'.format('Break' if os.name == 'nt' else 'C'))
try:
# 其他任务是独立的线程执行
while True:
pass
#time.sleep(60)
#print('进程正在执行!')
except (KeyboardInterrupt, SystemExit):
#终止任务
scheduler.shutdown()
print('Exit The Job!')
三、测试运行效果
用Python实现阿里钉钉机器人读取数据库内容自动发群通知的更多相关文章
- python如何转换word格式、读取word内容、转成html
# python如何转换word格式.读取word内容.转成html? import docx from win32com import client as wc # 首先将doc转换成docx wo ...
- SQLite之读取数据库内容
1.打开已有数据库. //打开数据库 - (BOOL )openDB {// 红色部分修改为自己的数据库路径 return (SQLITE_OK == sqlite3_open([@"/Us ...
- JSP + JDBC + MySQL 读取数据库内容到网页
创建数据库表 导入JDCB驱动 mysql.jsp <%@ page language="java" %> <%@ page contentType=" ...
- c#读取数据库内容
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- C#读取数据库内容并转换成xml文件
OleDbConnection conn = new OleDbConnection(@"Provider=Microsoft.Jet.OLEDB.4.0;Data Source=D:\bi ...
- 钉钉机器人-实现监控通知功能-python
1. 首先得创建有 一个 钉钉群.(因为只能发群通知) 2. 添加机器人,得到一个url: 3. 开始写Python脚本: # -*- coding: utf-8 -*- ""&q ...
- 怎么用python 3 开发钉钉群机器人
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:Python绿色通道 PS:如有需要Python学习资料的小伙伴可以加 ...
- python 小脚本升级-- 钉钉群聊天机器人
一则小脚本(工作中用) 在这篇文章中写的监控的脚本,发送监控的时候 是利用的邮箱,其实在实际,邮箱查收有着不方便性,于是乎升级, 我们工作中,经常用钉钉,那么如果要是能用到钉钉多好,这样我们的监控成功 ...
- 用python写一个预警机器人(支持微信和钉钉)
背景 线上的系统在运行中,发生故障时怎么及时的通过手机通知到相关人员?当然这是个很简单的需求,现有的方法有很多,例如: 如果我们用的云产品,那么一般都会有配套对应的监控预警功能,根据需要配置一下即可, ...
随机推荐
- 在MAC端查看win7
在MAC端查看win7,在finder中打开网络,输入win7地址,填入用户名和密码,就可以了
- ZOJ 3964 Yet Another Game of Stones Nim游戏变种
ZOJ3964 解题思路 此题的题意比较容易理解,可以简单的看着 Nim 博弈的变种.但问题在于 Alice 对第 i 堆石子的取法必须根据 bi 确定.所以如果这个问题能够归结到正常的 Nim 博弈 ...
- git删除远程分支和本地分支以及更改本地和分支名字
问题描述: 当我们集体进行项目时,将自定义分支push到主分支master之后,如何删除远程的自定义分支呢 问题解决: (1)使用命令git branch -a 查看所有分支 注: 其中,remote ...
- GitHub上README.md教程(copy)
[说明:转载于http://blog.csdn.net/kaitiren/article/details/38513715] 最近对它的README.md文件颇为感兴趣.便写下这贴,帮助更多的还不会编 ...
- P3953 逛公园(dp,最短路)
P3953 逛公园 题目描述 策策同学特别喜欢逛公园.公园可以看成一张NN个点MM条边构成的有向图,且没有 自环和重边.其中1号点是公园的入口,NN号点是公园的出口,每条边有一个非负权值, 代表策策经 ...
- 清北考前刷题da5下午好
/* (4,1)*(3,1)*(2,1)的话1变成2然后一直是2 2变成1然后变成3 3变成1然后变成4 4变成1 */ #include<iostream> #include<cs ...
- Windows平台下Oracle 11g R2监听文件日志过大,造成客户端无法连接的问题处理
近期部署在生产环境的应用突然无法访问,查看应用日志发现无法获取数据库连接. SystemErr R Caused by: oracle.net.ns.NetException: The Network ...
- QT开发之旅-Udp聊天室编程
一.概要设计 登录对话框(继承自QDialog类)进行用户登录查询数据库用户是否存在,注册插入数据到用户表.用户表字段: (chatid int primary key, passwd varchar ...
- PAT 甲级1135. Is It A Red-Black Tree (30)
链接:1135. Is It A Red-Black Tree (30) 红黑树的性质: (1) Every node is either red or black. (2) The root is ...
- Sublime——基本操作
基本安装 程序下载地址:https://www.sublimetext.com/ package control安装 View -> Show Console打开控制台或者用快捷键ctrl+~打 ...