掌握Spark机器学习库-09.3-kmeans算法实现分类
数据集
iris.data
数据集概览
代码
package org.apache.spark.examples.hust.hml.examplesforml
import org.apache.spark.ml.clustering.{KMeans, LDA}
import org.apache.spark.SparkConf
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.sql.SparkSession
import scala.util.Random
object kmeans1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("iris")
val spark = SparkSession.builder().config(conf).getOrCreate()
val file = spark.read.format("csv").load("D:\\9-1kmeans\\iris.data")
file.show()
import spark.implicits._
val random = new Random()
val data = file.map(row => {
val label = row.getString(4) match {
case "Iris-setosa" => 0
case "Iris-versicolor" => 1
case "Iris-virginica" => 2
}
(row.getString(0).toDouble,
row.getString(1).toDouble,
row.getString(2).toDouble,
row.getString(3).toDouble,
label,
random.nextDouble())
}).toDF("_c0", "_c1", "_c2", "_c3", "label", "rand").sort("rand")
val assembler = new VectorAssembler()
.setInputCols(Array("_c0", "_c1", "_c2", "_c3"))
.setOutputCol("features")
val dataset = assembler.transform(data)
val Array(train, test) = dataset.randomSplit(Array(0.8, 0.2))
train.show()
val kmeans = new KMeans().setFeaturesCol("features").setK(3).setMaxIter(20)
val model = kmeans.fit(train)
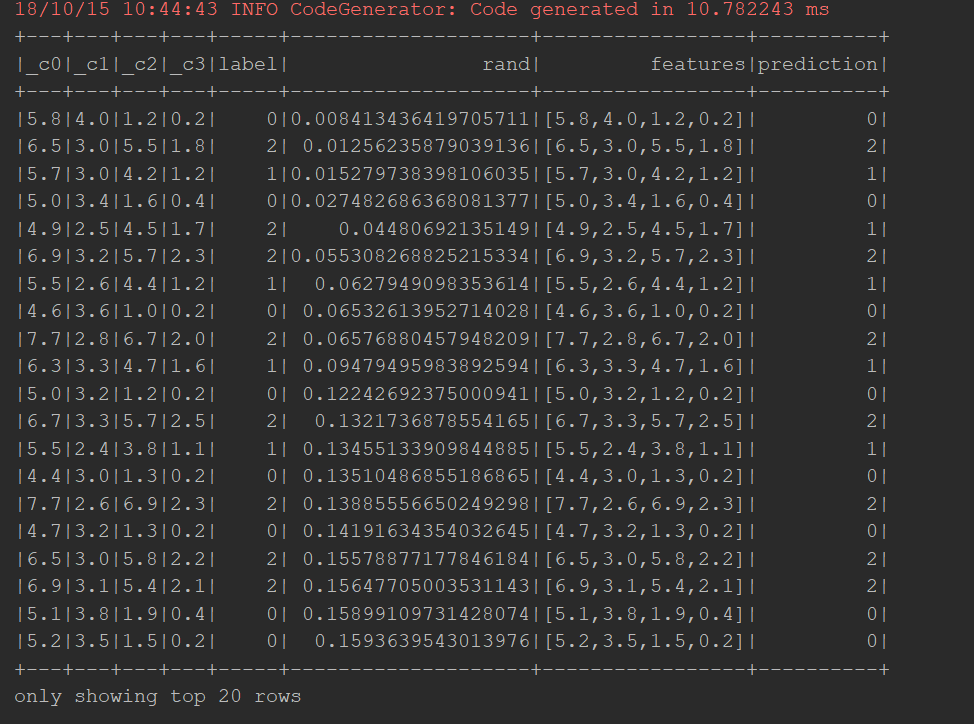
model.transform(train).show()
}
}
输出结果
掌握Spark机器学习库-09.3-kmeans算法实现分类的更多相关文章
- 掌握Spark机器学习库-09.6-LDA算法
数据集 iris.data 数据集概览 代码 package org.apache.spark.examples.examplesforml import org.apache.spark.ml.cl ...
- 掌握Spark机器学习库-07-线性回归算法概述
1)简介 自变量,因变量,线性关系,相关系数,一元线性关系,多元线性关系(平面,超平面) 2)使用线性回归算法的前提 3)应用例子 沸点与气压 浮力与表面积
- 掌握Spark机器学习库-08.7-决策树算法实现分类
数据集 iris.data 数据集概览 代码 package org.apache.spark.examples.examplesforml import org.apache.spark.Spark ...
- 掌握Spark机器学习库(课程目录)
第1章 初识机器学习 在本章中将带领大家概要了解什么是机器学习.机器学习在当前有哪些典型应用.机器学习的核心思想.常用的框架有哪些,该如何进行选型等相关问题. 1-1 导学 1-2 机器学习概述 1- ...
- UCI机器学习库和一些相关算法(转载)
UCI机器学习库和一些相关算法 各种机器学习任务的顶级结果(论文)汇总 https://github.com//RedditSota/state-of-the-art-result-for-machi ...
- Stanford机器学习笔记-9. 聚类(K-means算法)
9. Clustering Content 9. Clustering 9.1 Supervised Learning and Unsupervised Learning 9.2 K-means al ...
- 掌握Spark机器学习库-07.14-保序回归算法实现房价预测
数据集 house.csv 数据集概览 代码 package org.apache.spark.examples.examplesforml import org.apache.spark.ml.cl ...
- 掌握Spark机器学习库-08.2-朴素贝叶斯算法
数据集 iris.data 数据集概览 代码 import org.apache.spark.SparkConf import org.apache.spark.ml.classification.{ ...
- 掌握Spark机器学习库-07-回归算法原理
1)机器学习模型理解 统计学习,神经网络 2)预测结果的衡量 代价函数(cost function).损失函数(loss function) 3)线性回归是监督学习
随机推荐
- [学习笔记]渗透测试metasploit
1.渗透成功后,在meterpreter命令行,需要使用如下命令切换当前目录.更多信息,可以参考: meterpreter > pwd C:\ meterpreter > cd /&quo ...
- http的session和cookie
1 http session和http请求之间的关系 http协议是无状态的,一次会话服务端需要处理多次http请求,就算是长连接,也是要发送多次请求的,由于http无状态所有每次的请求都是独立的,服 ...
- Struts 1 Struts 2
Key Technologies Primer https://struts.apache.org/primer.html Threads With Struts 1 you were require ...
- 在做java 的web开发,为什么要使用框架
现在做项目都会使用框架,现在很常见的框架就是SSH(Struts+SpringMVC+spring+hibernate),SSM(Struts/springMVC+Spring+Hibernate), ...
- HDU1074 Doing Homework —— 状压DP
题目链接:http://acm.split.hdu.edu.cn/showproblem.php?pid=1074 Doing Homework Time Limit: 2000/1000 MS (J ...
- add environment path to powershell
https://4sysops.com/archives/use-powershell-to-execute-an-exe/ https://stackoverflow.com/questions/7 ...
- JS处理空格
JS处理空格 2010-10-27 11:48:32| 分类: 技术-JS | 标签:js 空格 |字号 订阅 /*删除两侧空格*/ function trim(ui){ ...
- 并不对劲的manacher算法
有些时候,后缀自动机并不能解决某些问题,或者解决很麻烦.这时就有各种神奇的字符串算法了. manacher算法用来O(|S|)地求出字符串S的最长的回文子串的长度.这是怎么做到的呢? 并不对劲的暴力选 ...
- 逆向分析一个完整的C++程序包含寄存器与参数传递详解
最近在分析C++ dump 文件的时候觉得有必要将一些必要的反汇编东西总结一下以备别人参考,自己有时间的时候也可以进行更多的改进.下面通过一个简单的C++代码转成汇编代码后的详细解释说明一下C++和汇 ...
- go语言godep使用命令
godep 看见他的star比govendor,所以我使用它.官方地址 https://github.com/tools/godep install 1 go get github.com/too ...