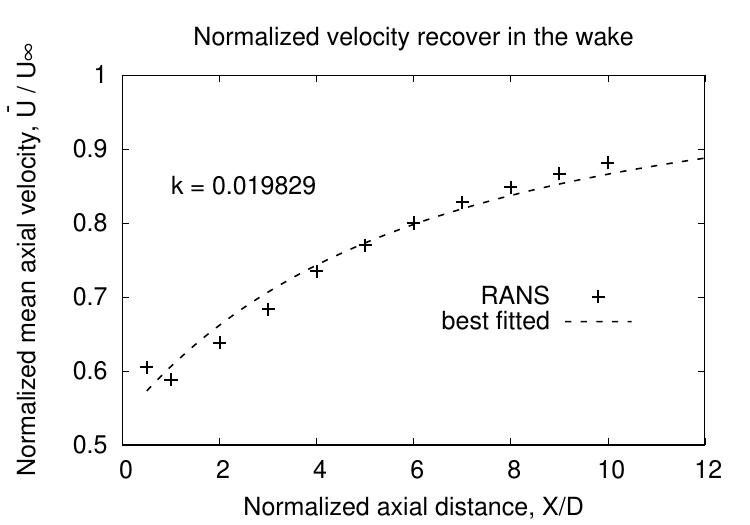
k fit in Park Model
software: Gnuplot
input: area_averaged_axial_mean_velocity_TI_1.txt
# One Rotor, front, eldad blade
# TSR , TI =%
#X/D X half width, Ux U Ux/U
0.5 0.23 0.275 0.363 0.6 0.605
0.46 0.93 0.353 0.6 0.588333333
0.92 0.316 0.383 0.6 0.638333333
1.38 0.334 0.41 0.6 0.683333333
1.84 0.349 0.441 0.6 0.735
2.3 0.365 0.462 0.6 0.77
2.76 0.379 0.48 0.6 0.8
3.22 0.39 0.497 0.6 0.828333333
3.68 0.405 0.509 0.6 0.848333333
4.14 0.42 0.52 0.6 0.866666667
4.6 0.431 0.529 0.6 0.881666667
gnuplot code
a = 0.6*(1-sqrt(1-0.7133))
d=0.46
f(x) = (0.6-a*d*d/((d+2*k*x)*(d+2*k*x)))/0.6
fit f(x) 'area_averaged_axial_mean_velocity_TI_1.txt' using 1:6 via k
# plotting
set terminal postscript eps font 24
set out 'k_fit_ti_1_tsr5.eps'
set autoscale
unset log
unset label
unset pm3d
set xtic auto
set ytic auto
unset grid
# set title 'Normalized velocity recover in the wake'
set xlabel "Normalized axial distance, X/D"
set xrange [*:12]
# r0 initial pulse
set yrange [0.5:1]
set ylabel "Normalized mean axial velocity, ~U{0.8-} / U{/Symbol \245}"
set style line 1 lt 1 lc rgb "black" lw 4 pt 1 ps 2
set style line 2 lt 2 lc rgb "black" lw 4 pt 3 ps 2
set style line 3 lt 3 lc rgb "black" lw 4 pt 5 ps 2
set style line 4 lt 4 lc rgb "black" lw 4 pt 7 ps 2
set style line 5 lt 5 lc rgb "black" lw 4
set style line 6 lt 6 lc rgb "brown" lw 4
k_value = sprintf("k = %.3f", k)
set label 1 at 1, 0.85 k_value
set key at graph 0.9, 0.3
set key spacing 1
plot 'area_averaged_axial_mean_velocity_TI_1.txt' using 1:6 ls 1 with points title 'RANS', f(x) lw 3 title "best fitted"
output:
k fit in Park Model的更多相关文章
- Python的主成分分析PCA算法
这篇文章很不错:https://blog.csdn.net/u013082989/article/details/53792010 为什么数据处理之前要进行归一化???(这个一直不明白) 这个也很不错 ...
- The Model Complexity Myth
The Model Complexity Myth (or, Yes You Can Fit Models With More Parameters Than Data Points) An oft- ...
- 高斯混合模型Gaussian Mixture Model (GMM)——通过增加 Model 的个数,我们可以任意地逼近任何连续的概率密分布
从几何上讲,单高斯分布模型在二维空间应该近似于椭圆,在三维空间上近似于椭球.遗憾的是在很多分类问题中,属于同一类别的样本点并不满足“椭圆”分布的特性.这就引入了高斯混合模型.——可以认为是基本假设! ...
- k近邻聚类简介
简介 在所有机器学习算法中,k近邻(K-Nearest Neighbors,KNN)相对是比较简单的. 尽管它很简单,但事实证明它在某些任务中非常有效,甚至更好.它可以用于分类和回归问题! 然而,它更 ...
- 4.K均值算法应用
一.课堂练习 from sklearn.cluster import KMeans import matplotlib.pyplot as plt import numpy as np from sk ...
- Scikit-learn:模型评估Model evaluation
http://blog.csdn.net/pipisorry/article/details/52250760 模型评估Model evaluation: quantifying the qualit ...
- 最大似然估计实例 | Fitting a Model by Maximum Likelihood (MLE)
参考:Fitting a Model by Maximum Likelihood 最大似然估计是用于估计模型参数的,首先我们必须选定一个模型,然后比对有给定的数据集,然后构建一个联合概率函数,因为给定 ...
- Coxph model Pvalue Select
I am calculating cox propotional hazards models with the coxph function from the survival package. ...
- 1.K近邻算法
(一)K近邻算法基础 K近邻(KNN)算法优点 思想极度简单 应用数学知识少(近乎为0) 效果好 可以解释机器学习算法使用过程中的很多细节问题 更完整的刻画机器学习应用的流程 图解K近邻算法 上图是以 ...
随机推荐
- LuoguP2115 [USACO14MAR]破坏Sabotage【二分答案】By cellur925
本来是想找一道生成树的题做的...结果被洛咕的标签骗到了这题...结果是二分答案与生成树一点mao关系都没有.... 题目大意:给你一个序列,请你删去某一个$l~r$区间的值($2<=i< ...
- 【原创】《从0开始学Elasticsearch》—document的单/批量crud
内容目录 1.新建文档2.查询文档3.修改文档4.删除文档 1.新建文档 1). 语法1,手动指定document 的id: PUT /index_name/type_name/id{ &quo ...
- logrotate日志转储
1 工具目录 ***系统开启selinux,logrotate会不生效*** linux默认会安装logrotate工具,自身的boot.log就是通过它分割转储的. [root@webmaster ...
- net 配置文件处理视频
1. 视频 <staticContent> <mimeMap fileExtension=".mp4" mimeType="video/mp4 ...
- Educational Codeforces Round 24 A
There are n students who have taken part in an olympiad. Now it's time to award the students. Some o ...
- 中国剩余定理 POJ 1006 Biorhythms
题目传送门 题意:POJ有中文题面 分析:其实就是求一次同余方程组:(n+d)=p(%23), (n+d)=e(%28), (n+d)=i(%33),套用中国剩余定理模板 代码: /********* ...
- 题解报告:hdu 4607 Park Visit(最长链)
Problem Description Claire and her little friend, ykwd, are travelling in Shevchenko's Park! The par ...
- 482 License Key Formatting 注册码格式化
详见:https://leetcode.com/problems/license-key-formatting/description/ C++: class Solution { public: s ...
- HDU 5808 Price List Strike Back bitset优化的背包。。水过去了
http://acm.hdu.edu.cn/showproblem.php?pid=5808 用bitset<120>dp,表示dp[0] = true,表示0出现过,dp[100] = ...
- MySQLDump在使用之前一定要想到的事情 [转载]
转载于:http://blog.itpub.net/29254281/viewspace-1392757/ MySQLDump经常用于迁移数据和备份. 下面创建实验数据,两个数据库和若干表create ...