kafka+spark-streaming实时推荐系统性能优化笔记
2) --conf spark.streaming.concurrentJobs=10
someDF.repartition(sparkSession.sparkContext.getConf.getInt("spark.executor.instances", 10)).foreachPartition {
p =>
bcVariables.value.get("_")
}
5)去掉所有不必要的join
join确实有很多可以优化的配置,但是没必要把时间花在join的优化上,尤其是在可以用广播变量来作为代替方案的情况下。
需要注意的是,广播变量和broadcast join是不一样的,前者效率在大部分时候要更高。
6)kafka partition个数和executor个数的关系
executor个数要能被partition个数整除。例如,如果partition个数为24个,那么12个executor和18个executor处理数据的性能差距不大。如果集群可以分配的executor个数为18个,那么partition数可以从24个调整为18个(或者36个等等)。
原因比较明显,就不多提了。展示几个实验数据
下图为性能测试实验中3,6,12个executor下数据处理时间(纵坐标)和数据量(横坐标)的关系,是明显的线性关系。
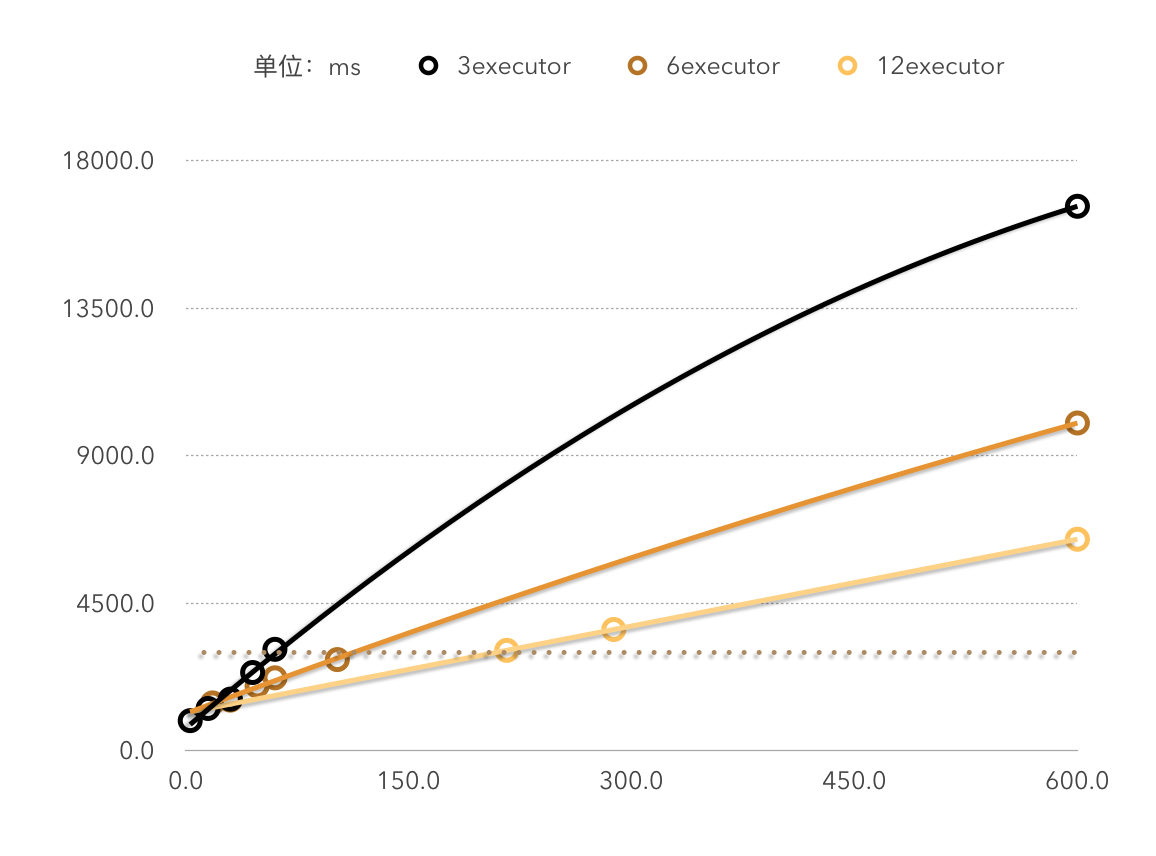
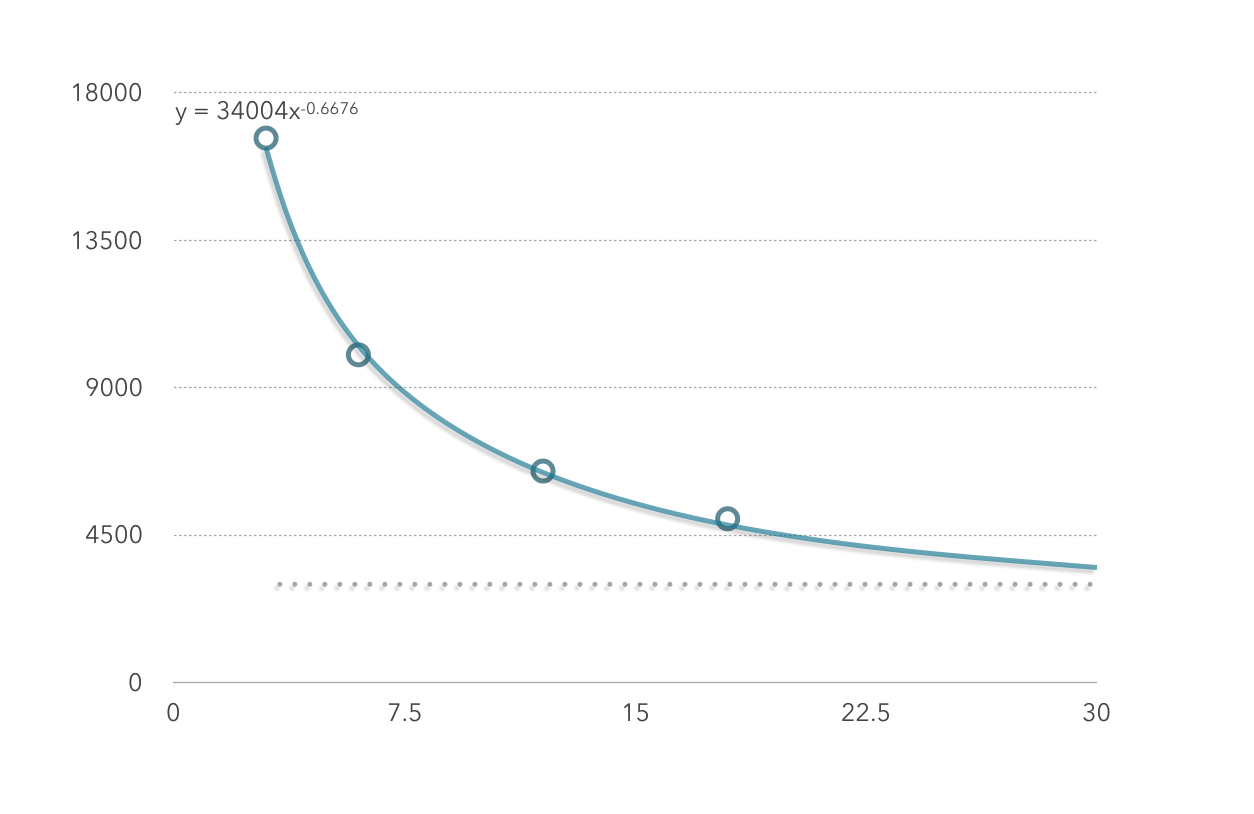
下图为性能测试实验中在处理600条数据时,executor数(横坐标)和时间(纵坐标)的关系(分区个数为executor的整数倍)
由图一的三组数据也可以看出,每秒能处理的数据的条数和executor的个数约等于线性关系。即如果当前集群每3秒能处理x条数据,那么集群扩容一倍后,每3秒应该能处理2x条数据。
由图二可看出,executor数和数据的处理时间不是简单的线性关系,也就是说,如果当前集群处理100条数据耗时6秒,并不能保证将集群扩容一倍后100条数据的处理时间变为3秒。
7)kafka的hash分区
kafka的各个分区处理的数据应该保证尽量按照某一特征(比如用户id)hash分区,这样能够保证某一用户的所有记录都在某一个partition,这样spark-streaming在处理reduceByKey时会提升效率。
8)提交任务时指定sql shuffle partition ,否则默认是200
--conf spark.sql.shuffle.partitions=6
kafka+spark-streaming实时推荐系统性能优化笔记的更多相关文章
- 【转】Spark Streaming 实时计算在甜橙金融监控系统中的应用及优化
系统架构介绍 整个实时监控系统的架构是先由 Flume 收集服务器产生的日志 Log 和前端埋点数据, 然后实时把这些信息发送到 Kafka 分布式发布订阅消息系统,接着由 Spark Streami ...
- demo2 Kafka+Spark Streaming+Redis实时计算整合实践 foreachRDD输出到redis
基于Spark通用计算平台,可以很好地扩展各种计算类型的应用,尤其是Spark提供了内建的计算库支持,像Spark Streaming.Spark SQL.MLlib.GraphX,这些内建库都提供了 ...
- Spark Streaming实时计算框架介绍
随着大数据的发展,人们对大数据的处理要求也越来越高,原有的批处理框架MapReduce适合离线计算,却无法满足实时性要求较高的业务,如实时推荐.用户行为分析等. Spark Streaming是建立在 ...
- 【Streaming】30分钟概览Spark Streaming 实时计算
本文主要介绍四个问题: 什么是Spark Streaming实时计算? Spark实时计算原理流程是什么? Spark 2.X下一代实时计算框架Structured Streaming Spark S ...
- Apache Kafka + Spark Streaming Integration
1.目标 为了构建实时应用程序,Apache Kafka - Spark Streaming Integration是最佳组合.因此,在本文中,我们将详细了解Kafka中Spark Streamin ...
- Spark练习之通过Spark Streaming实时计算wordcount程序
Spark练习之通过Spark Streaming实时计算wordcount程序 Java版本 Scala版本 pom.xml Java版本 import org.apache.spark.Spark ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十一)NIFI1.7.1安装
一.nifi基本配置 1. 修改各节点主机名,修改/etc/hosts文件内容. 192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 sla ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十三)kafka+spark streaming打包好的程序提交时提示虚拟内存不足(Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical memory used; 2.2 GB of 2.1 G)
异常问题:Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical mem ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十二)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。
Centos7出现异常:Failed to start LSB: Bring up/down networking. 按照<Kafka:ZK+Kafka+Spark Streaming集群环境搭 ...
随机推荐
- Linux重启和关机命令
Linux重启命令: 方式1:shutdown –r now 方式2:reboot Linux关机命令: shutdown –h now
- IKanalyzer、ansj_seg、jcseg三种中文分词器的实战较量
转自:http://lies-joker.iteye.com/blog/2173086 选手:IKanalyzer.ansj_seg.jcseg 硬件:i5-3470 3.2GHz 8GB win7 ...
- Scala-基础-数组(1)
import junit.framework.TestCase import scala.collection.mutable.ArrayBuffer; //数组(1) //知识点-定义数组,变长数组 ...
- CF540C Ice Cave
思路: 搜索. 加回溯会超时,不加回溯就过了,不是很理解. 实现: #include <iostream> #include <cstdio> using namespace ...
- CSS 按钮特效(二)
1 案例 2. HTML 代码 <div class="arrow arrow-left-middle"> arrow-left-middle </div> ...
- 完成fcc作业2时思路
1.设置导航链接按钮栏时,不能用文档流,要用position:fixed;固定在窗口上方, 其他普通流盒子按上下顺序就用position:relative:后面发现导航栏被普通流盒子挡在了下面,就设置 ...
- SQL函数-汉字首字母查询
汉字首字母查询处理用户定义函数 CREATE FUNCTION f_GetPY1(@str nvarchar(4000))RETURNS nvarchar(4000)ASBEGIN DECLARE @ ...
- NVIDIA各个领域芯片现阶段的性能和适应范围
NVIDIA作为老牌显卡厂商,在AI领域深耕多年.功夫不负有心人,一朝AI火,NVIDIA大爆发,NVIDIA每年送给科研院所和高校的大量显卡,大力推广Physix和CUDA,终于钓了产业的大鱼. 由 ...
- Handling unhandled exceptions and signals
there are two ways to catch otherwise uncaught conditions that will lead to a crash: Use the functio ...
- Mybatis学习总结四(关联查询)
一.一对一查询 实例:查询所有订单信息,关联查询下单用户信息. Method1:使用resultType,定义订单信息po类,此po类中包括了订单信息和用户信息. public class Order ...