c#Winform程序调用app.config文件配置数据库连接字符串 SQL Server文章目录 浅谈SQL Server中统计对于查询的影响 有关索引的DMV SQL Server中的执行引擎入门 【译】表变量和临时表的比较 对于表列数据类型选择的一点思考 SQL Server复制入门(一)----复制简介 操作系统中的进程与线程
你新建winform项目的时候,会有一个app.config的配置文件,写在里面的<connectionStrings name=" " connectionString=" "></connectionStrings >,
connectionString代表数据库链接字符串,name代表你想要引用的时候查找的名称。(其实asp里的web.config配置方式也跟这个方式基本一样)
1.打开app.config配置文件
例如:

<?xml version="1.0" encoding="utf-8" ?>
<configuration>
<startup>
<supportedRuntime version="v4.0" sku=".NETFramework,Version=v4.5.2" />
</startup>
<connectionStrings>
<add name ="TestDB" connectionString="Data Source=.;Initial Catalog=学生课表管理系统;Persist Security Info=True;User ID=;Password= "/>
</connectionStrings>
</configuration>
2.在c#后台代码调用这个数据连接字符串配置文件
完成以上配置,在后台代码要先引入using System.Configuration;
在你需要调用数据库的地方加入以下代码
string Stu = ConfigurationManager.ConnectionStrings["TestDB"].ConnectionString;
//TestDB这里是你刚才配置文件里连接的NAME
SqlConnection conn = new SqlConnection(Stu); //连接数据库
if (conn.State == ConnectionState.Closed)
{
conn.Open();
} //判断如果数据库关闭,就打开数据库
以上就是在app.config配置文件里配置连接字符串的方式
SQL Server文章目录
SQL Server的文章写了也不少了,一直没有做一个目录方便大家阅读。现在把之前写的关于SQL Server的文章做一个目录,方便大家阅读 
SQL入门
SQL进阶
T-SQL查询进阶--理解SQL Server中索引的概念,原理以及其他
T-SQL查询高级--理解SQL SERVER中非聚集索引的覆盖,连接,交叉和过滤
T-SQL查询高级—SQL Server索引中的碎片和填充因子
SQL日志
浅谈SQL Server中的事务日志(一)----事务日志的物理和逻辑构架
浅谈SQL Server中的事务日志(二)----事务日志在修改数据时的角色
浅谈SQL Server中的事务日志(三)----在简单恢复模式下日志的角色
浅谈SQL Server中的事务日志(四)----在完整恢复模式下日志的角色
浅谈SQL Server中的事务日志(五)----日志在高可用和灾难恢复中的作用
SQL Server高可用性
SQL的一些单篇
SQL Server中灾难时备份结尾日志(Tail of log)的两种方法
SQL Server 2012新特性探秘
SQL Server 2012中的ColumnStore Index尝试
SQL Server2012中的SequenceNumber尝试
SQL Server 2012中的Contained Database尝试
SQL Server2012中的Indirect CheckPoint
SQL Server 2014新特性探秘
SQL Server 2014新特性探秘(2)-SSD Buffer Pool Extension
SQL Server 2014新特性探秘(3)-可更新列存储聚集索引
SQL Server权限
理解SQL Server中的权限体系(下)----安全对象和权限
SQL Server复制
SQL Server一些有用的DMV
SQL Server索引进阶(翻译)
翻译的文章
http://www.cnblogs.com/CareySon/archive/2012/05/08/2489748.html
浅谈SQL Server中统计对于查询的影响
简介
SQL Server查询分析器是基于开销的。通常来讲,查询分析器会根据谓词来确定该如何选择高效的查询路线,比如该选择哪个索引。而每次查询分析器寻找路径时,并不会每一次都去统计索引中包含的行数,值的范围等,而是根据一定条件创建和更新这些信息后保存到数据库中,这也就是所谓的统计信息。
如何查看统计信息
查看SQL Server的统计信息非常简单,使用如下指令:
DBCC SHOW_STATISTICS('表名','索引名')
所得到的结果如图1所示。
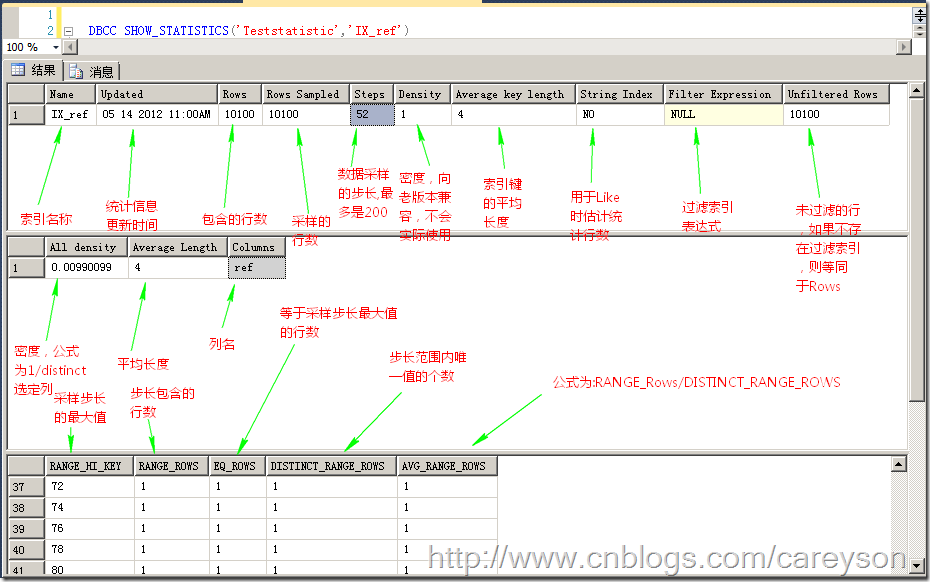
图1.统计信息
统计信息如何影响查询
下面我们通过一个简单的例子来看统计信息是如何影响查询分析器。我建立一个测试表,有两个INT值的列,其中id为自增,ref上建立非聚集索引,插入100条数据,从1到100,再插入9900条等于100的数据。图1中的统计信息就是示例数据的统计信息。
此时,我where后使用ref值作为查询条件,但是给定不同的值,我们可以看出根据统计信息,查询分析器做出了不同的选择,如图2所示。
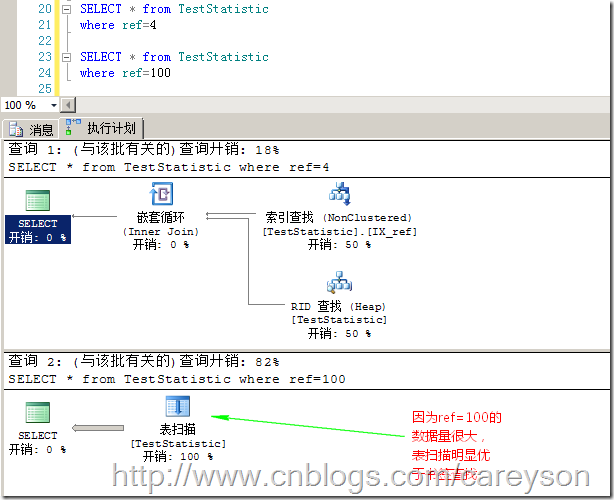
图2.根据不同的谓词,查询优化器做了不同的选择
其实,对于查询分析器来说,柱状图对于直接可以确定的谓词非常管用,这些谓词比如:
where date = getdate()
where id= 12345
where monthly_sales < 10000 / 12
where name like “Careyson” + “%”
但是对于比如
where price = @vari
where total_sales > (select sum(qty) from sales)
where a.id =b.ref_id
where col1 =1 and col2=2
这类在运行时才能知道值的查询,采样步长就明显不是那么好用了。另外,上面第四行如果谓词是两个查询条件,使用采样步长也并不好用。因为无论索引有多少列,采样步长仅仅存储索引的第一列。当柱状图不再好用时,SQL Server使用密度来确定最佳的查询路线。
密度的公式是:1/表中唯一值的 个数。当密度越小时,索引越容易被选中。比如图1中的第二个表,我们可以通过如下公式来计算一下密度:
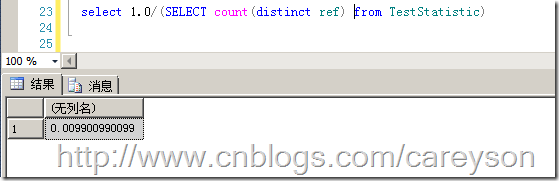
图3.某一列的密度
根据公式可以推断,当表中的数据量逐渐增大时,密度会越来越小。
对于那些不能根据采样步长做出选择的查询,查询分析器使用密度来估计行数,这个公式为:估计的行数=表中的行数*密度
那么,根据这个公式,如果我做查询时,估计的行数就会为如图4所示的数字。
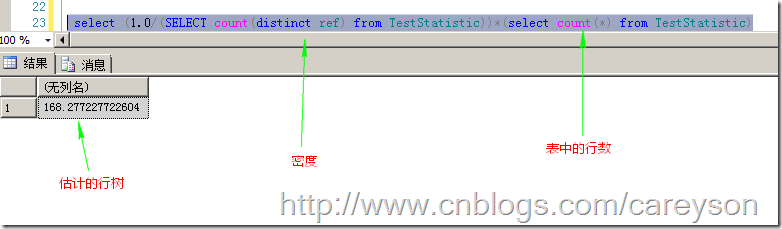
图4.估计的行数
我们来验证一下这个结论,如图5所示。
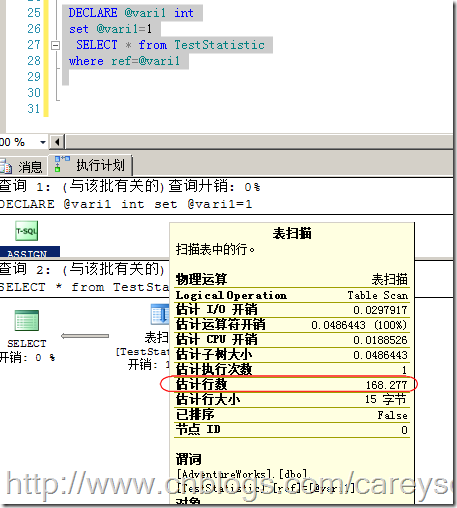
图5.估计的行数
因此,可以看出,估计的行数是和实际的行数有出入的,当数据分布均匀时,或者数据量大时,这个误差将会变的非常小。
统计信息的更新
由上面的例子可以看到,查询分析器由于依赖于统计信息进行查询,那么过时的统计信息则可能导致低效率的查询。统计信息既可以由SQL Server来进行管理,也可以手动进行更新,也可以由SQL Server管理更新时手动更新。
当开启了自动更新后,SQL Server监控表中的数据更改,当达到临界值时则会自动更新数据。这个标准是:
- 向空表插入数据时
- 少于500行的表增加500行或者更多
- 当表中行多于500行时,数据的变化量大于20%时
上述条件的满足均会导致统计被更新。
当然,我们也可以使用如下语句手动更新统计信息。
UPDATE STATISTICS 表名[索引名]
列级统计信息
SQL Server还可以针对不属于任何索引的列创建统计信息来帮助查询分析器获取”估计的行数“.当我们开启数据库级别的选项“自动创建统计信息”如图6所示。
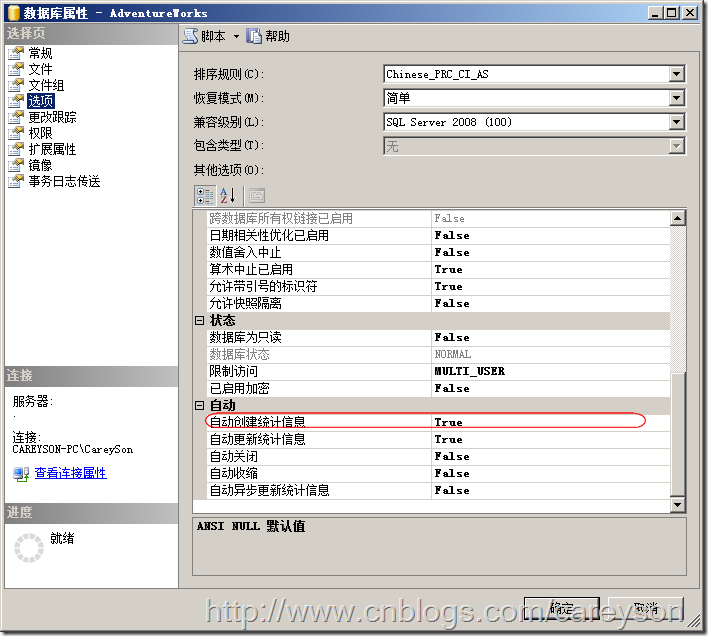
图6.自动创建统计信息
当这个选项设置为True时,当我们where谓词指定了不在任何索引上的列时,列的统计信息会被创建,但是会有以下两种情况例外:
- 创建统计信息的成本超过生成查询计划的成本
- 当SQL Server忙时不会自动生成统计信息
我们可以通过系统视图sys.stats来查看这些统计信息,如图7所示。
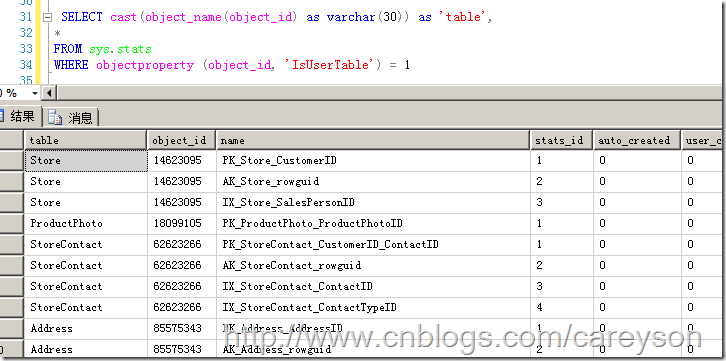
图7.通过系统视图查看统计信息
当然,也可以通过如下语句手动创建统计信息:
CREATE STATISTICS 统计名称 ON 表名 (列名 [,...n])
总结
本文简单谈了统计信息对于查询路径选择的影响。过时的统计信息很容易造成查询性能的降低。因此,定期更新统计信息是DBA重要的工作之一。
有关索引的DMV
有关索引的DMV
1.查看那些被大量更新,却很少被使用的索引
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
SELECT
DB_NAME() AS DatabaseName
, SCHEMA_NAME(o.Schema_ID) AS SchemaName
, OBJECT_NAME(s.[object_id]) AS TableName
, i.name AS IndexName
, s.user_updates
, s.system_seeks + s.system_scans + s.system_lookups
AS [System usage]
INTO #TempUnusedIndexes
FROM sys.dm_db_index_usage_stats s
INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id]
AND s.index_id = i.index_id
INNER JOIN sys.objects o ON i.object_id = O.object_id
WHERE 1=2
EXEC sp_MSForEachDB 'USE [?];
INSERT INTO #TempUnusedIndexes
SELECT TOP 20
DB_NAME() AS DatabaseName
, SCHEMA_NAME(o.Schema_ID) AS SchemaName
, OBJECT_NAME(s.[object_id]) AS TableName
, i.name AS IndexName
, s.user_updates
, s.system_seeks + s.system_scans + s.system_lookups
AS [System usage]
FROM sys.dm_db_index_usage_stats s
INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id]
AND s.index_id = i.index_id
INNER JOIN sys.objects o ON i.object_id = O.object_id
WHERE s.database_id = DB_ID()
AND OBJECTPROPERTY(s.[object_id], ''IsMsShipped'') = 0
AND s.user_seeks = 0
AND s.user_scans = 0
AND s.user_lookups = 0
AND i.name IS NOT NULL
ORDER BY s.user_updates DESC'
SELECT TOP 20 * FROM #TempUnusedIndexes ORDER BY [user_updates] DESC
DROP TABLE #TempUnusedIndexes
结果如图:
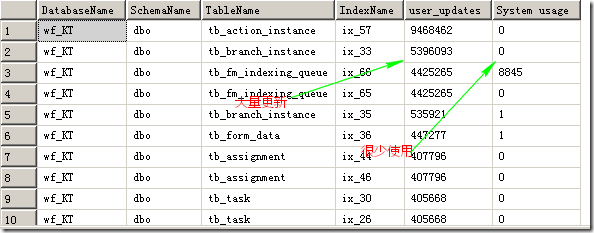
这类索引应该被Drop掉
最高维护代价的索引
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
SELECT
DB_NAME() AS DatabaseName
, SCHEMA_NAME(o.Schema_ID) AS SchemaName
, OBJECT_NAME(s.[object_id]) AS TableName
, i.name AS IndexName
, (s.user_updates ) AS [update usage]
, (s.user_seeks + s.user_scans + s.user_lookups) AS [Retrieval usage]
, (s.user_updates) -
(s.user_seeks + s.user_scans + s.user_lookups) AS [Maintenance cost]
, s.system_seeks + s.system_scans + s.system_lookups AS [System usage]
, s.last_user_seek
, s.last_user_scan
, s.last_user_lookup
INTO #TempMaintenanceCost
FROM sys.dm_db_index_usage_stats s
INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id]
AND s.index_id = i.index_id
INNER JOIN sys.objects o ON i.object_id = O.object_id
WHERE 1=2
EXEC sp_MSForEachDB 'USE [?];
INSERT INTO #TempMaintenanceCost
SELECT TOP 20
DB_NAME() AS DatabaseName
, SCHEMA_NAME(o.Schema_ID) AS SchemaName
, OBJECT_NAME(s.[object_id]) AS TableName
, i.name AS IndexName
, (s.user_updates ) AS [update usage]
, (s.user_seeks + s.user_scans + s.user_lookups)
AS [Retrieval usage]
, (s.user_updates) -
(s.user_seeks + user_scans +
s.user_lookups) AS [Maintenance cost]
, s.system_seeks + s.system_scans + s.system_lookups AS [System usage]
, s.last_user_seek
, s.last_user_scan
, s.last_user_lookup
FROM sys.dm_db_index_usage_stats s
INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id]
AND s.index_id = i.index_id
INNER JOIN sys.objects o ON i.object_id = O.object_id
WHERE s.database_id = DB_ID()
AND i.name IS NOT NULL
AND OBJECTPROPERTY(s.[object_id], ''IsMsShipped'') = 0
AND (s.user_seeks + s.user_scans + s.user_lookups) > 0
ORDER BY [Maintenance cost] DESC'
SELECT top 20 * FROM #TempMaintenanceCost ORDER BY [Maintenance cost] DESC
DROP TABLE #TempMaintenanceCost
结果如图:
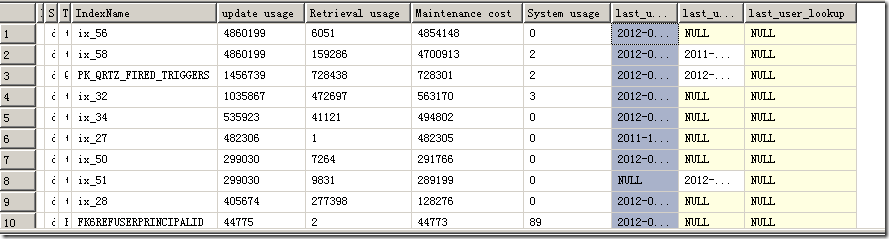
Maintenance cost高的应该被Drop掉
使用频繁的索引
--使用频繁的索引
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
SELECT
DB_NAME() AS DatabaseName
, SCHEMA_NAME(o.Schema_ID) AS SchemaName
, OBJECT_NAME(s.[object_id]) AS TableName
, i.name AS IndexName
, (s.user_seeks + s.user_scans + s.user_lookups) AS [Usage]
, s.user_updates
, i.fill_factor
INTO #TempUsage
FROM sys.dm_db_index_usage_stats s
INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id]
AND s.index_id = i.index_id
INNER JOIN sys.objects o ON i.object_id = O.object_id
WHERE 1=2
EXEC sp_MSForEachDB 'USE [?];
INSERT INTO #TempUsage
SELECT TOP 20
DB_NAME() AS DatabaseName
, SCHEMA_NAME(o.Schema_ID) AS SchemaName
, OBJECT_NAME(s.[object_id]) AS TableName
, i.name AS IndexName
, (s.user_seeks + s.user_scans + s.user_lookups) AS [Usage]
, s.user_updates
, i.fill_factor
FROM sys.dm_db_index_usage_stats s
INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id]
AND s.index_id = i.index_id
INNER JOIN sys.objects o ON i.object_id = O.object_id
WHERE s.database_id = DB_ID()
AND i.name IS NOT NULL
AND OBJECTPROPERTY(s.[object_id], ''IsMsShipped'') = 0
ORDER BY [Usage] DESC'
SELECT TOP 20 * FROM #TempUsage ORDER BY [Usage] DESC
DROP TABLE #TempUsage
结果如图
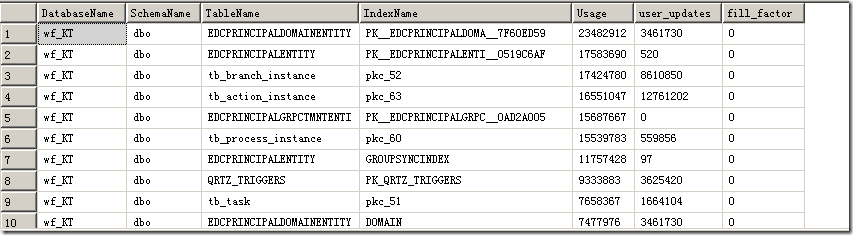
这类索引需要格外注意,不要在优化的时候干掉
碎片最多的索引
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
SELECT
DB_NAME() AS DatbaseName
, SCHEMA_NAME(o.Schema_ID) AS SchemaName
, OBJECT_NAME(s.[object_id]) AS TableName
, i.name AS IndexName
, ROUND(s.avg_fragmentation_in_percent,2) AS [Fragmentation %]
INTO #TempFragmentation
FROM sys.dm_db_index_physical_stats(db_id(),null, null, null, null) s
INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id]
AND s.index_id = i.index_id
INNER JOIN sys.objects o ON i.object_id = O.object_id
WHERE 1=2
EXEC sp_MSForEachDB 'USE [?];
INSERT INTO #TempFragmentation
SELECT TOP 20
DB_NAME() AS DatbaseName
, SCHEMA_NAME(o.Schema_ID) AS SchemaName
, OBJECT_NAME(s.[object_id]) AS TableName
, i.name AS IndexName
, ROUND(s.avg_fragmentation_in_percent,2) AS [Fragmentation %]
FROM sys.dm_db_index_physical_stats(db_id(),null, null, null, null) s
INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id]
AND s.index_id = i.index_id
INNER JOIN sys.objects o ON i.object_id = O.object_id
WHERE s.database_id = DB_ID()
AND i.name IS NOT NULL
AND OBJECTPROPERTY(s.[object_id], ''IsMsShipped'') = 0
ORDER BY [Fragmentation %] DESC'
SELECT top 20 * FROM #TempFragmentation ORDER BY [Fragmentation %] DESC
DROP TABLE #TempFragmentation
结果如下:
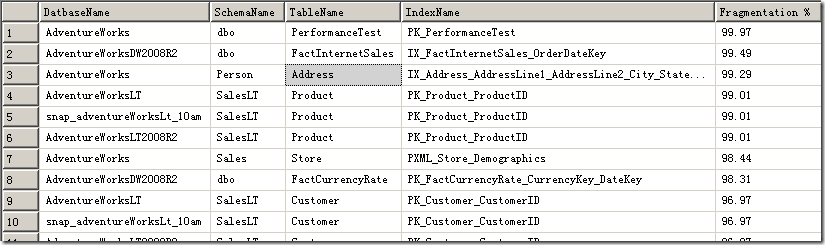
这类索引需要Rebuild,否则会严重拖累数据库性能
自上次SQL Server重启后,找出完全没有使用的索引
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
SELECT
DB_NAME() AS DatbaseName
, SCHEMA_NAME(O.Schema_ID) AS SchemaName
, OBJECT_NAME(I.object_id) AS TableName
, I.name AS IndexName
INTO #TempNeverUsedIndexes
FROM sys.indexes I INNER JOIN sys.objects O ON I.object_id = O.object_id
WHERE 1=2
EXEC sp_MSForEachDB 'USE [?];
INSERT INTO #TempNeverUsedIndexes
SELECT
DB_NAME() AS DatbaseName
, SCHEMA_NAME(O.Schema_ID) AS SchemaName
, OBJECT_NAME(I.object_id) AS TableName
, I.NAME AS IndexName
FROM sys.indexes I INNER JOIN sys.objects O ON I.object_id = O.object_id
LEFT OUTER JOIN sys.dm_db_index_usage_stats S ON S.object_id = I.object_id
AND I.index_id = S.index_id
AND DATABASE_ID = DB_ID()
WHERE OBJECTPROPERTY(O.object_id,''IsMsShipped'') = 0
AND I.name IS NOT NULL
AND S.object_id IS NULL'
SELECT * FROM #TempNeverUsedIndexes
ORDER BY DatbaseName, SchemaName, TableName, IndexName
DROP TABLE #TempNeverUsedIndexes
结果如图:
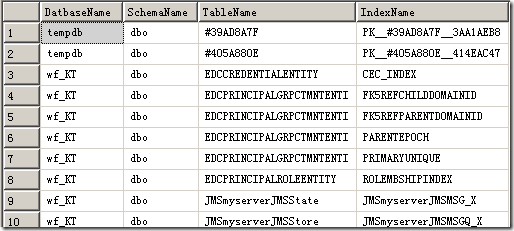
这类索引应该小心对待,不能一概而论,要看是什么原因导致这种问题
查看索引统计的相关信息
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
SELECT
ss.name AS SchemaName
, st.name AS TableName
, s.name AS IndexName
, STATS_DATE(s.id,s.indid) AS 'Statistics Last Updated'
, s.rowcnt AS 'Row Count'
, s.rowmodctr AS 'Number Of Changes'
, CAST((CAST(s.rowmodctr AS DECIMAL(28,8))/CAST(s.rowcnt AS
DECIMAL(28,2)) * 100.0)
AS DECIMAL(28,2)) AS '% Rows Changed'
FROM sys.sysindexes s
INNER JOIN sys.tables st ON st.[object_id] = s.[id]
INNER JOIN sys.schemas ss ON ss.[schema_id] = st.[schema_id]
WHERE s.id > 100
AND s.indid > 0
AND s.rowcnt >= 500
ORDER BY SchemaName, TableName, IndexName
结果如下:
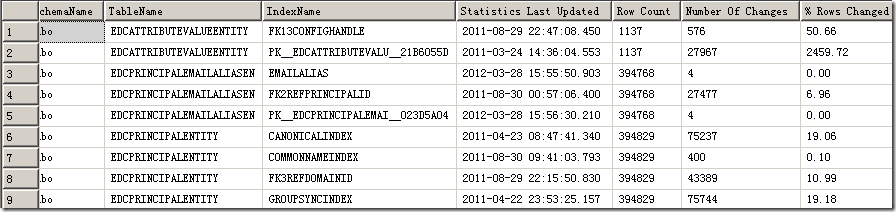
因为查询计划是根据统计信息来的,索引的选择同样取决于统计信息,所以根据统计信息更新的多寡可以看出数据库的大体状况,20%的自动更新对于大表来说非常慢。
SQL Server中的执行引擎入门
简介
当查询优化器(Query Optimizer)将T-SQL语句解析后并从执行计划中选择最低消耗的执行计划后,具体的执行就会交由执行引擎(Execution Engine)来进行执行。本文旨在分类讲述执行计划中每一种操作的相关信息。
数据访问操作
首先最基本的操作就是访问数据。这既可以通过直接访问表,也可以通过访问索引来进行。表内数据的组织方式分为堆(Heap)和B树,其中表中没有建立聚集索引时数据是通过堆进行组织的,这个是无序的,表中建立聚集索引后和非聚集索引的数据都是以B树方式进行组织,这种方式数据是有序存储的。通常来说,非聚集索引仅仅包含整个表的部分列,对于过滤索引,还仅仅包含部分行。
除去数据的组织方式不同外,访问数据也分为两种方式,扫描(Scan)和查找(Seek),扫描是扫描整个结构的所有数据,而查找只是查找整个结构中的部分数据。因此可以看出,由于堆是无序的,所以不可能在堆上面进行查找(Seek)操作,而相对于B树的有序,使得在B树中进行查找成为可能。当针对一个以堆组织的表进行数据访问时,就会进行堆扫描,如图1所示。

图1.表扫描
可以看出,表扫描的图标很清晰的表明表扫描的性质,在一个无序组织表中从头到尾扫描一遍。
而对于B树结构的聚集索引和非聚集索引,同样可以进行扫描,通常来讲,为了获取索引表中的所有数据或是获得索引行树占了数据大多数使得扫描的成本小于查找时,会进行聚集索引扫描。如图2所示。

图2.聚集索引扫描
聚集索引扫描的图标也同样能够清晰的表明聚集索引扫描的性质,找到最左边的叶子节点后,依次扫描所有叶子节点,达到扫描整个结构的作用。当然对于非聚集索引也是同样的概念,如图3所示。

图3.非聚集索引的扫描
而对于仅仅选择B树结构中的部分数据,索引查找(Seek)使得B树变得有意义。根据所查找的关键值,可以使得从仅仅从B树根部向下走单一路径,因此免去了扫描不必要页的消耗,图4是查询计划中的一个索引查找。

图4.聚集索引查找
索引查找的图标也是很传神的,可以看到图标那根线从根节点一路向下到叶子节点。也就是找到所求数据所在的页,不难看出,如果我们需要查找多条数据且分散在不同的页中,这个查找操作需要重复执行很多回,当这个次数大到一定程度时,SQL Server会选择消耗比较低的索引扫描而不是再去重复索引查找。对于非聚集索引查找,概念是一样的,就不再上图片了。
书签查找(Bookmark Lookup)
你也许会想,假如非聚集索引可以快速的找到所求的数据,但遗憾的是,非聚集索引却不包含所有所求列时该怎么办?这时SQL Server会面临两个选择,直接访问基本表去获取数据或是在非聚集索引中找到数据后,再去基本表获得非聚集索引没有覆盖到的所求列。这个选择取决于所估计的行数等统计信息。查询分析器会选择消耗比较少的那个。
一个简单的书签查找如图5所示。

图5.一个简单的书签查找
从图5可以看出,首先通过非聚集索引找到所求的行,但这个索引并不包含所有的列,因此还要额外去基本表中找到这些列,因此要进行键查找,如果基本表是以堆进行组织的,那么这个键查找(Key Lookup)就会变成RID查找(RID Lookup),键查找和RID查找统称为书签查找。
不过有时候索引查找所返回的行数过多导致书签查找的性能远不如直接进行扫描操作,因此SQL Server这时会选择扫描而不是书签查找。如图6所示。

图6.StateProvinceID列有非聚集索引,但由于返回行数过多,分析器会选择扫描而不是书签查找
这个估计是根据统计信息进行的,关于统计信息,可以看我之前的一篇博文:浅谈SQL Server中统计对于查询的影响
聚合操作(Aggregation)
聚合函数会导致聚合操作。聚合函数是将一个集合的数据按照某种规则汇总成1个数据,或基于分组按照规则汇总成多个数据的过程。一些聚合函数比如:avg,sum,min,另外还有distinct关键字都有可能导致两类聚合操作:流聚合(Stream Aggregation)和哈希聚合(Hash Aggregation)。
流聚合(Stream Aggregation)
流聚合需要再执行聚合函数之前,被聚合的数据集合是有序的,这个有序数据既可以通过执行计划中的Sort进行,也可以直接从聚集或是非聚集索引中直接获得有序数据,另外,没有Group by的聚合操作被成为标量聚合,这类操作一定是会执行流聚合。
比如,我们直接进行标量聚合,如图7所示。

图7.流聚合
但对于加了Group by的子句,因为需要数据按照group by 后面的列有序,就需要Sort来保证排序。注意,Sort操作是占用内存的操作,当内存不足时还会去占用tempdb。SQL Server总是会在Sort操作和散列匹配中选择成本最低的。一个需要Sort的操作如图8所示。

图8.需要排序的流聚合
图8中排序操作按照ProductLine进行排序后,然后就根据各自的分组做聚合操作了。
散列聚合(Hash aggregation)
上面的流聚合适合比较少的数据,但是对于相对大一点的表。使用散列集合成本会比排序要低。散列集合通过在内存中建立散列表来实现聚合,因此无需对数据集合进行排序。内存中所建立的散列表以Group by后面的列作为键值,如图9所示。

图9.散列聚合
在内存中建立好散列表后,会按照group by后面的值作为键,然后依次处理集合中的每条数据,当键在散列表中不存在时,向散列表添加条目,当键已经在散列表中存在时,按照规则(规则是聚合函数,比如Sum,avg什么的)计算散列表中的值(Value)。
连接(Join)
当多表连接时(书签查找,索引之间的连接都算),SQL Server会采用三类不同的连接方式:循环嵌套连接(Nested Loops Join),合并连接(Merge Join),散列连接(Hash Join)。这几种连接并不是哪种会比另一种更好,而是每种连接方式都会适应特定场景。
循环嵌套连接(Nested Loops Join)
由图10可以看到一个简单的循环嵌套连接。

图10.一个循环嵌套连接的实例
循环嵌套连接的图标同样十分传神,处在上面的外部输入(Outer input),这里也就是聚集索引扫描。和处在下面的内部输入(Inner Input),这里也就是聚集索引查找。外部输入仅仅执行一次,根据外部输入满足Join条件的每一行,对内部输入进行查找。这里由于是290行,对于内部输入执行290次。
可以通过属性窗口看到.如图11所示:

图11.内部输入的执行次数
根据嵌套循环的原理不难看出,由于外部输入是扫描,内部输入是查找,当两个Join的表外部输入结果集比较小,而内部输入所查找的表非常大时,查询优化器更倾向于选择循环嵌套方式。
合并连接(Merge Join)
不同于循环嵌套的是,合并连接是从每个表仅仅执行一次访问。从这个原理来看,合并连接要比循环嵌套要快了不少。下面来看一个典型的合并连接,如图12所示。

图12.合并连接
从合并连接的原理不难想象,首先合并连接需要双方有序.并且要求Join的条件为等于号。因为两个输入条件已经有序,所以从每一个输入集合中取一行进行比较,相等的返回,不相等的舍弃,从这里也不难看出Merge join为什么只允许Join后面是等于号。从图11的图标中我们可以看出这个原理。
如果输入数据的双方无序,则查询分析器不会选择合并连接,我们也可以通过索引提示强制使用合并连接,为了达到这一目的,执行计划必须加上一个排序步骤来实现有序,如图13所示。

图13.通过排序来实现Merge Join
散列连接(Hash Join)
散列连接同样仅仅只需要只访问1次双方的数据。散列连接通过在内存中建立散列表实现。这比较消耗内存,如果内存不足还会占用tempdb。但并不像合并连接那样需要双方有序。一个典型的散列连接如图14所示。

图14.散列连接
这里我删除了Costomer的聚集索引,否则两个有序输入SQL Server会选择代价更低的合并连接。SQL Server利用两个上面的输入生成哈希表,下面的输入来探测,可以在属性窗口看到这些信息,如图15所示。

图15.散列键生成和散列键探测
通常来说,在两个输入数据比较大,且所求数据在其中一方或双方没有排序的条件达成时,会选用散列匹配。
并行
当多个表连接时,SQL Server还允许在多CPU或多核的情况下允许查询并行,这样无疑提高了效率,一个并行的例子如图16所示。

图16.并行提高效率
总结
本文简单介绍了SQL Server执行计划中常见的操作极其原理,了解这些步骤和原理是优化查询的基本功。
【译】表变量和临时表的比较
关于表变量是什么(和表变量不是什么),以及和临时表的比较让很多人非常困惑。虽然网上已经有了很多关于它们的文章,但我并没有发现一篇比较全面的。在本篇文章中,我们将探索表变量和临时表是什么(以及不是什么),然后我们通过使用临时表和表变量对其解密。
表变量
表变量在SQL Server 2000中首次被引入,那么,什么是表变量呢?微软在BOL (Declare @local_variable)中定义其为一个类型为表的变量。它的具体定义包括列定义,列名,数据类型和约束。而在表变量中可以使用的约束包括主键约束,唯一约束,Null约束和Check约束(外键约束不能在表变量中使用).定义表变量的语句是和正常使用Create table定义表语句的子集。只是表变量通过DECLARE @local_variable 语句进行定义。
通过参考1可以知道:
1) 表变量拥有特定作用域(在当前批处理语句中,但不在任何当前批处理语句调用的存储过程和函数中),表变量在批处理结束后自动被清除。
2) 参考6中在"Recompilations Due to Certain Temporary Table Operations" 环节讨论了临时表在会导致存储过程强制被重复编译的各种原因,但这些原因并不适用于表变量。表变量和临时表比起来会产生更少的存储过程重编译。
3) 针对表变量的事务仅仅在更新数据时生效,所以锁和日志产生的数量会更少。
4) 由于表变量的作用域如此之小,而且不属于数据库的持久部分,所以事务回滚不会影响表变量。
表变量可以在其作用域内像正常的表一样使用。更确切的说,表变量可以被当成正常的表或者表表达式一样在select,delete,update,insert语句中使用。但是表变量不能在类似“SELECT select_list INTO table_variable” 这样的语句中使用。而在SQL Server 2000中,表变量也不能被用于“INSERT INTO table_variable EXEC stored_procedure”这样的语句中。
表变量不能做如下事情:
1.虽然表变量是一个变量,但是其不能赋值给另一个变量。
2.check约束,默认值,和计算列不能引用自定义函数。
3.不能为约束命名。
4.不能Truncate表变量
5.不能向标识列中插入显式值(也就是说表变量不支持SET IDENTITY_INSERT ON)
临时表
在深入临时表之前,我们首先需要讨论一下会话(Session),一个会话仅仅是一个客户端到数据引擎的连接。在SQL Server Management Studio(SSMS)中,每一个查询窗口都会和数据库引擎建立连接。一个应用程序可以和数据库建立一个或多个连接,除此之外,应用程序还可能建立连接后一直不释放直到应用程序结束,也可能使用完释放连接需要时建立连接。
那么,什么是临时表?在BOL (CREATE TABLE)中,我们可以知道临时表和以Create table语句创建的表有着相同的物理构成,但临时表与正常的表不同之处有:
1) 临时表的名字不能超过116个字符,这是由于数据库引擎为了辨别不同会话建立不同的临时表,所以会自动在临时表的名字后附加一串
2) 局部临时表(以“#”开头命名的)作用域仅仅在当前的连接内,从在存储过程中建立局部临时表的角度来看,局部临时表会在下列情况被Drop:
a.显式调用DROP Table语句
b.当局部临时表在存储过程内被创建时,存储过程结束也就意味着局部临时表被DROP
c.当前会话结束,在会话内创建的所有局部临时表都会被Drop
3) 全局临时表(以“##”开头命名的)在所有的会话内可见,所以在创建全局临时表之前首先检查其是否存在,否则如果已经存在,你将会得到重复创建对象的错误.
a.全局临时表会在创建其的会话结束后被DROP,其它会话将不能对全局临时表进行引用。
b.引用是在语句级别进行,比如说下面例子:
i.建立新的查询窗口,运行如下语句:
create table ##temp (RowID int)
ii.再次开启一个新的查询创建,使用如下语句每5秒中对全局临时表进行引用
while 1=1 begin
select * from ##temp
waitfor delay '00:00:05'
end
iii.回到第一个窗口,关闭窗口
iv.在下一个循环引用全局临时表时,将产生错误
4) 不能对临时表进行分区。
5) 不能对临时表加外键约束
6) 临时表内列的数据类型不能定义成没有在TempDb中没有定义自定义数据类型(自定义数据类型是数据库级别的对象,而临时表属于TempDb),由于TempDb在每次SQL Server重启后会被自动创建,所以你必须使用startup stored procedure来为TempDb创建自定义数据类型。你也可以通过修改Model数据库来达到这一目标。
7) XML列不能定义成XML集合的形式,除非这个集合已经在TempDb中定义
临时表既可以通过Create Table语句创建,也可以通过”SELECT <select_list> INTO #table”语句创建。你还可以针对临时表使用”INSERT INTO #table EXEC stored_procedure”这样的语句。
临时表可以拥有命名的约束和索引。但是,当两个用户在同一时间调用同一存储过程时,将会产生”There is already an object named ‘<objectname>’ in the database”这样的错误。所以最好的做法是不用为建立的对象进行命名,而使用系统分配的在TempDb中唯一的。6
参考6谈论了很多由于临时表而导致的存储过程重编译的原因以及避免的方法。
误区
误区1.表变量仅仅在内存中。
误区2.临时表仅仅存储在物理介质中
这两种观点都是明显的误区,在参考1的Q4节。表变量都是在TempDb数据库中创建,因为表变量存储的数据有可能超过物理内存。除此之外,我们发现只要内存足够,表变量和临时表都会在内存中创建和处理。它们也同样可以在任何时间被存入磁盘。
如何证明这点?请看下面代码(在SQL Server 2000到2008中都有效)
-- make a list of all of the user tables currently active in the
-- TempDB database
if object_id('tempdb..#tempTables') is not null drop table #tempTables
select name into #tempTables from tempdb..sysobjects where type ='U'
-- prove that even this new temporary table is in the list.
-- Note the suffix at the end of it to uniquely identify the table across sessions.
select * from #tempTables where name like '#tempTables%'
GO
-- create a table variable
declare @MyTableVariable table (RowID int)
-- show all of the new user tables in the TempDB database.
select name from tempdb..sysobjects
where type ='U' and name not in (select name from #tempTables)
还有一些“证明”临时表仅仅存在于内存中谬误,下面我来指出其中一个:
注意表变量的名字是系统分配的,表变量的第一个字符”@”并不是一个字母,所以它并不是一个有效的变量名。系统会在TempDb中为表变量创建一个系统分配的名称,所以任何在sysobjects或sys.tables查找表变量的方法都会失败。
正确的方法应该是我前面例子中的方法,我看到很多人使用如下查询查表变量:
select * from sysobjects where name like'#tempTables%'
上述代码看上去貌似很好用,但会产生多用户的问题。你建立两个连接,在第一个连接中创建临时表,在第二个窗口中运行上面的语句能看到第一个连接创建的临时表,如果你在第二个连接中尝试操作这个临时表,那么可能会产生错误,因为这个临时表不属于你的会话。
误区3.表变量不能拥有索引。
这个误区也同样错误。虽然一旦你创建一个表变量之后,就不能对其进行DDL语句了,这包括Create Index语句。然而你可以在表变量定义的时候为其创建索引)比如如下语句.
declare @MyTableVariable table (RowID intPRIMARY KEY CLUSTERED)
这个语句将会创建一个拥有聚集索引的表变量。由于主键有了对应的聚集索引,所以一个系统命名的索引将会被创建在RowID列上。
下面的例子演示你可以在一个表变量的列上创建唯一约束以及如何建立符合索引。
declare @temp TABLE ( RowID int NOT NULL, ColA int NOT NULL, ColB char(1)UNIQUE, PRIMARY KEY CLUSTERED(RowID, ColA))
1) SQL 并不能为表变量建立统计信息,就像其能为临时表建立统计信息一样。这意味着对于表变量,执行引擎认为其只有1行,这也意味着针对表变量的执行计划并不是最优。虽然估计的执行计划对于表变量和临时表都为1,但是实际的执行计划对于临时表会根据每次存储过程的重编译而改变(看参考1,Q2部分).如果临时表不存在,在生成执行计划的时候会产生错误。
2) 前面提到,一定建立表变量后就无法对其进行DDL语句操作。因此如果需要为表建立索引或者加一列,你需要临时表。
3) 表变量不能使用select …into语句,而临时表可以
4) 在SQL Server 2008中,你可以将表变量作为参数传入存储过程。但是临时表不行。在SQL Server 2000和2005中表变量也不行。
5) 作用域:表变量仅仅在当前的批处理中有效,并且对任何在其中嵌套的存储过程等不可见。局部临时表只在当前会话中有效,这也包括嵌套的存储过程。但对父存储过程不可见。全局临时表可以在任何会话中可见,但是会随着创建其的会话终止而DROP,其它会话这时就不能再引用全局临时表。
6) 排序规则:表变量使用当前数据库的排序规则,临时表使用TempDb的排序规则。如果它们不兼容,你还需要在查询或者表定义中进行指定(参考7.Table Variables and Temporary Tables)
7) 你如果希望在动态SQL中使用表变量,你必须在动态SQL中定义表变量。而临时表可以提前定义,在动态SQL中进行引用。
说了这么多,那么,我该如何选择呢?
微软推荐使用表变量(看参考4),如果表中的行数非常小,则使用表变量。很多”网络专家”会告诉你100是一个分界线,因为这是统计信息创建查询计划效率高低的开始。但是我还是希望告诉你针对你的特定需求对临时表和表变量进行测试。很多人在自定义函数中使用表变量,如果你需要在表变量中使用主键和唯一索引,你会发现包含数千行的表变量也依然性能卓越。但如果你需要将表变量和其它表进行join,你会发现由于不精准的执行计划,性能往往会非常差。
为了证明这点,请看本文的附件。附件中代码创建了表变量和临时表.并装入了AdventureWorks数据库的Sales.SalesOrderDetail表。为了得到足够的测试数据,我将这个表中的数据插入了10遍。然后以ModifiedDate 列作为条件将临时表和表变量与原始的Sales.SalesOrderDetail表进行了Join操作,从统计信息来看IO差别显著。从时间来看表变量做join花了50多秒,而临时表仅仅花了8秒。
如果你需要在表建立后对表进行DLL操作,那么选择临时表吧。
临时表和表变量有很多类似的地方。所以有时候并没有具体的细则规定如何选择哪一个。对任何特定的情况,你都需要考虑其各自优缺点并做一些性能测试。下面的表格会让你比较其优略有了更详细的参考。
总结
| 特性 | 表变量 | 临时表 |
| 作用域 | 当前批处理 | 当前会话,嵌套存储过程,全局:所有会话 |
| 使用场景 | 自定义函数,存储过程,批处理 | 自定义函数,存储过程,批处理 |
| 创建方式 | DECLARE statement only.只能通过DECLEARE语句创建 |
CREATE TABLE 语句 SELECT INTO 语句. |
| 表名长度 | 最多128字节 | 最多116字节 |
| 列类型 |
可以使用自定义数据类型 可以使用XML集合 |
自定义数据类型和XML集合必须在TempDb内定义 |
| Collation | 字符串排序规则继承自当前数据库 | 字符串排序规则继承自TempDb数据库 |
| 索引 | 索引必须在表定义时建立 | 索引可以在表创建后建立 |
| 约束 | PRIMARY KEY, UNIQUE, NULL, CHECK约束可以使用,但必须在表建立时声明 | PRIMARY KEY, UNIQUE, NULL, CHECK. 约束可以使用,可以在任何时后添加,但不能有外键约束 |
| 表建立后使用DDL (索引,列) | 不允许 | 允许. |
| 数据插入方式 | INSERT 语句 (SQL 2000: 不能使用INSERT/EXEC). |
INSERT 语句, 包括 INSERT/EXEC. SELECT INTO 语句. |
| Insert explicit values into identity columns (SET IDENTITY_INSERT). | 不支持SET IDENTITY_INSERT语句 | 支持SET IDENTITY_INSERT语句 |
| Truncate table | 不允许 | 允许 |
| 析构方式 | 批处理结束后自动析构 | 显式调用 DROP TABLE 语句. 当前会话结束自动析构 (全局临时表: 还包括当其它会话语句不在引用表.) |
| 事务 | 只会在更新表的时候有事务,持续时间比临时表短 | 正常的事务长度,比表变量长 |
| 存储过程重编译 | 否 | 会导致重编译 |
| 回滚 | 不会被回滚影响 | 会被回滚影响 |
| 统计数据 | 不创建统计数据,所以所有的估计行数都为1,所以生成执行计划会不精准 | 创建统计数据,通过实际的行数生成执行计划。 |
| 作为参数传入存储过程 | 仅仅在SQL Server2008, 并且必须预定义 user-defined table type. | 不允许 |
| 显式命名对象 (索引, 约束). | 不允许 | 允许,但是要注意多用户的问题 |
| 动态SQL | 必须在动态SQL中定义表变量 | 可以在调用动态SQL之前定义临时表 |
参考:
1) INF: Frequently Asked Questions - SQL Server 2000 - Table Variables
2) T-SQL BOL (SQL 2000), table data type
3) T-SQL BOL (SQL 2008), Declare @local_variable
4) T-SQL BOL (SQL 2008), CREATE TABLE
5) Table-Valued Parameters (Database Engine)
6) Troubleshooting stored procedure recompilation
7) Local Temporary Tables and Table Variables
9) Data Definition Language (DDL)
其它值得阅读的文章:
1) Things You Didn’t Know About Temp Tables and Table Variables
-----------------------------------------------------------------------
原文链接:http://www.sqlservercentral.com/articles/Temporary+Tables/66720/
Translated by:CareySon
对于表列数据类型选择的一点思考
简介
SQL Server每个表中各列的数据类型的选择通常显得很简单,但是对于具体数据类型的选择的不同对性能的影响还是略有差别。本篇文章对SQL Server表列数据类型的选择进行一些探索。
一些数据存储的基础知识
在SQL Server中,数据的存储以页为单位。八个页为一个区。一页为8K,一个区为64K,这个意味着1M的空间可以容纳16个区。如图1所示:

图1.SQL Server中的页和区
如图1(PS:发现用windows自带的画图程序画博客中的图片也不错 )可以看出,SQL Server中的分配单元分为三种,分别为存储行内数据的In_Row_Data,存储Lob对象的LOB_Data,存储溢出数据的Row_Overflow_data。下面我们通过一个更具体的例子来理解这三种分配单元。
)可以看出,SQL Server中的分配单元分为三种,分别为存储行内数据的In_Row_Data,存储Lob对象的LOB_Data,存储溢出数据的Row_Overflow_data。下面我们通过一个更具体的例子来理解这三种分配单元。
我建立如图2所示的表。

图2.测试表
图2的测试表不难看出,通过插入数据使得每一行的长度会超过每页所能容纳的最大长度8060字节。使得不仅产生了行溢出(Row_Overflow_Data),还需要存储LOB的页.测试的插入语句和通过DBCC IND看到的分配情况如图3所示。

图3.超过8060字节的行所分配的页
除去IAM页,这1行数据所需要三个页来存储。首先是LOB页,这类是用于存储存在数据库的二进制文件所设计,当这个类型的列出现时,在原有的列会存储一个24字节的指针,而将具体的二进制数据存在LOB页中,除去Text之外,VarBinary(max)也是存在LOB页中的。然后是溢出行,在SQL Server 2000中,一行超过8060字节是不被允许的,在SQL Server 2005之后的版本对这个特性进行了改进,使用Varchar,nvarchar等数据类型时,当行的大小不超过8060字节时,全部存在行内In-row data,当varchar中存储的数据过多使得整行超过8060字节时,会将额外的部分存于Row-overflow data页中,如果update这列使得行大小减少到小于8060字节,则这行又会全部回到in-row data页。
数据类型的选择
在了解了一些基础知识之后。我们知道SQL Server读取数据是以页为单位,更少的页不仅仅意味着更少的IO,还有更少的内存和CPU资源消耗。所以对于数据选择的主旨是:
尽量使得每行的大小更小
这个听起来非常简单,但实际上还需要对SQL Server的数据类型有更多的了解。
比如存储INT类型的数据,按照业务规则,能用INT就不用BIGINT,能用SMALLINT就不用INT,能用TINYINT就不用SMALLINT。
所以为了使每行的数据更小,则使用占字节最小的数据类型。
1.比如不要使用DateTime类型,而根据业务使用更精确的类型,如下表:
| 类型 | 所占字节 |
| Date(仅日期) | 3 |
| Time(仅时间) | 5 |
| DateTime2(时间和日期) | 8 |
| DateTimeOffSet(外加时区) | 10 |
2.使用VarChar(Max),Nvarchar(Max),varbinary(Max)来代替text,ntext和image类型
根据前面的基础知识可以知道,对于text,ntext和image类型来说,每一列只要不为null,即使占用很小的数据,也需要额外分配一个LOB页,这无疑占用了更多的页。而对于Varchar(Max)等数据类型来说,当数据量很小的时候,存在In-row-data中就能满足要求,而不用额外的LOB页,只有当数据溢出时,才会额外分配LOB页,除此之外,Varchar(Max)等类型支持字符串操作函数比如:
- COL_LENGTH
- CHARINDEX
- PATINDEX
- LEN
- DATALENGTH
- SUBSTRING
3.对于仅仅存储数字的列,使用数字类型而不是Varchar等。
因为数字类型占用更小的存储空间。比如存储123456789使用INT类型只需要4个字节,而使用Varchar就需要9个字节(这还不包括Varchar还需要占用4个字节记录长度)。
4.如果没有必要,不要使用Nvarchar,Nchar等以“字”为单位存储的数据类型。这类数据类型相比varchar或是char需要更多的存储空间。
5.关于Char和VarChar的选择
这类比较其实有一些了。如果懒得记忆,大多数情况下使用Varchar都是正确的选择。我们知道Varchar所占用的存储空间由其存储的内容决定,而Char所占用的存储空间由定义其的长度决定。因此Char的长度无论存储多少数据,都会占用其定义的空间。所以如果列存储着像邮政编码这样的固定长度的数据,选择Char吧,否则选择Varchar会比较好。除此之外,Varchar相比Char要多占用几个字节存储其长度,下面我们来做个简单的实验。
首先我们建立表,这个表中只有两个列,一个INT类型的列,另一个类型定义为Char(5),向其中插入两条测试数据,然后通过DBCC PAGE来查看其页内结构,如图4所示。

图4.使用char(5)类型,每行所占的空间为16字节
下面我们再来看改为Varchar(5),此时的页信息,如图5所示。

图5.Varchar(5),每行所占用的空间为20字节
因此可以看出,Varchar需要额外4个字节来记录其内容长度。因此,当实际列存储的内容长度小于5字节时,使用char而不是varchar会更节省空间。
关于Null的使用
关于Null的使用也是略有争议。有些人建议不要允许Null,全部设置成Not Null+Default。这样做是由于SQL Server比较时就不会使用三值逻辑(TRUE,FALSE,UNKNOWN),而使用二值逻辑(True,False),并且查询的时候也不再需要IsNull函数来替换Null值。
但这也引出了一些问题,比如聚合函数的时候,Null值是不参与运算的,而使用Not Null+Default这个值就需要做排除处理。
因此Null的使用还需要按照具体的业务来看。
考虑使用稀疏列(Sparse)
稀疏列是对 Null 值采用优化的存储方式的普通列。 稀疏列减少了 Null 值的空间需求,但代价是检索非 Null 值的开销增加。 当至少能够节省 20% 到 40% 的空间时,才应考虑使用稀疏列。
稀疏列在SSMS中的设置如图6所示。

图6.稀疏列
更具体的稀疏列如何能节省空间,请参看MSDN。
对于主键的选择
对于主键的选择是表设计的重中之重,因为主键不仅关系到业务模型,更关系到对表数据操作的的效率(因为主键会处于B树的非叶子节点中,对树的高度的影响最多)。关于主键的选择,我之前已经有一篇文章关于这点:从性能的角度谈SQL Server聚集索引键的选择,这里就不再细说了。
总结
本篇文章对于设计表时,数据列的选择进行了一些探寻。好的表设计不仅仅是能满足业务需求,还能够满足对性能的优化。
SQL Server复制入门(一)----复制简介
简介
SQL Server中的复制(Replication)是SQL Server高可用性的核心功能之一,在我看来,复制指的并不仅仅是一项技术,而是一些列技术的集合,包括从存储转发数据到同步数据到维护数据一致性。使用复制功能不仅仅需要你对业务的熟悉,还需要对复制功能的整体有一个全面的了解,本系列文章旨在对SQL Server中的复制进行一个简单全面的探讨。(PS:在我的上篇文章中我发现某些文章的图片使用mspaint手绘更有感觉,但被很多人吐槽,因此在不考虑个人羞耻感的前提下,本系列文章中的一些图片继续使用mspaint )。
)。
复制是什么
复制,英文是Replication,这个词源自于拉丁文replicare,原意是重复。SQL Server中的复制也是这个意思,复制的核心功能是存储转发,意味着在一个在一个位置增删改了数据以后,重复这个动作到其他的数据源,概念如图1所示。
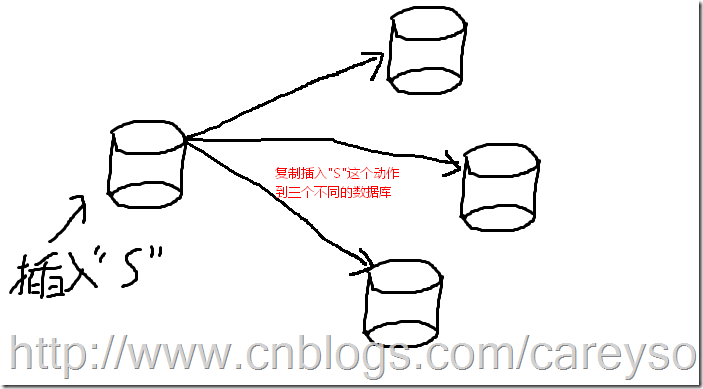
图1.复制的基本概念
当然,上面的这个模型是复制最简单的模型,实际中的模型可能会复杂很多,但是大多数使用复制的原因可以分为如下几类:
1.负载均衡----通过将数据复制到其它数据库服务器来减少当前服务器的负载,比如说最典型的应用就是分发数据来分离OLTP和OLAP环境。
2.分区----将经常使用的数据和历史数据隔离,将历史数据复制到其它数据库中
3.授权----将一部分数据提供给需要使用数据的人,以供其使用
4.数据合并-每个区域都有其各自的数据,将其数据进行合并。比如一个大公司,每个地区都有其各自的销售数据,总部需要汇总这些数据。
5.故障转移----复制所有数据,以便故障时进行转移。
虽然需要使用复制的原因多种多样,但是在使用之前你首先要了解复制技术所需的组成元素。
复制的组成部分
复制的概念很像发行杂志的模型,从发行商那里出版后,需要通过报刊亭等地方分发到订阅杂志的人手里。对于SQL Server复制来说,这个概念也是如此。对于SQL Server复制来说,发行商,报刊亭,订阅者分别对应的是发布服务器,分发服务器,订阅服务器。概念如图2所示。
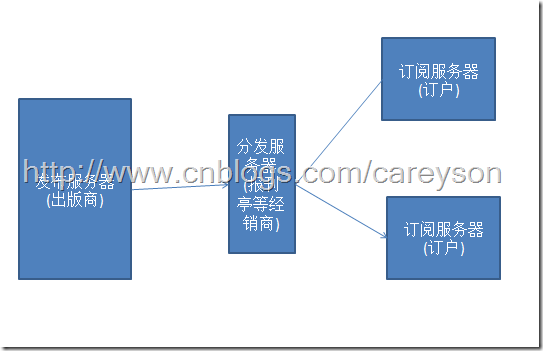
图2.发布分发订阅的基本概念
发布服务器
图2中的发布服务器包含了需要被发布的数据库。也就是需要向其它数据源分发内容的源数据库。当然,被发布的数据首先需要被允许发布。关于这里的详细设置会在文章后面提到。
分发服务器
图2中的分发服务器包含了分发数据库,分发数据库的作用是存储转发发布服务器发过来的数据。一个分发服务器支持多个发布服务器,就像一个报刊亭可以出售多个出版社所出的杂志一样。同理,分发服务器也可以和发布服务器是同一个实例,这就像出版商不通过报刊亭,自己直接贩卖杂志一样。
订阅服务器
图2中的订阅服务器包含了发布服务器所发布的数据的副本。这个副本可以是一个数据库,或者一个表,甚至是一个表的子集。根据不同的设置,有些发布服务器发布的更新到订阅服务器就是只读的(比如说用于出报表的OLAP环境),或者是订阅服务器也可以进行更新来将这些改变提交到发布服务器。
发布和文章
发布指的是可以发布的文章的集合,这些文章包括表,存储过程,视图和用户自定义函数,如图3所示。
图3.可以发布的内容
当我们发布表时,还可以根据限定条件只发布表的子集。
订阅
订阅是相对发布的一个概念,订阅定义了订阅服务器从哪个分发服务器接收发布。有两类订阅方式,推送订阅(Push)和请求订阅(Pull),根据名字就可以望文生义的知道,在推送订阅的情况下,当发布服务器产生更新时,分发服务器直接更新订阅的内容,而请求订阅需要订阅服务器定期查看分发服务器是否有可用更新,如果存在可用更新,则订阅服务器更新数据。
复制类型
SQL Server将复制方式分为三大类,每一个发布只能有一种复制类型,分别为:快照复制,事务复制和合并复制。
快照复制
快照复制将发布的所有表做成一个镜像,然后一次性复制到订阅服务器。中间的更新不会像其它复制类型那样自动传送到订阅服务器。由这个概念不难看出,快照复制的特点会是:
1.占用网络宽带,因为一次性传输整个镜像,所以快照复制的内容不应该太大。
2.适合那些更新不频繁,但每次更新都比较大的数据。比如企业员工信息表,每半年更新一次这类的业务场景。
3.适合订阅服务器是OLAP只读的环境。
来自MSDN的配图能很好的阐述快照复制,如图4所示。
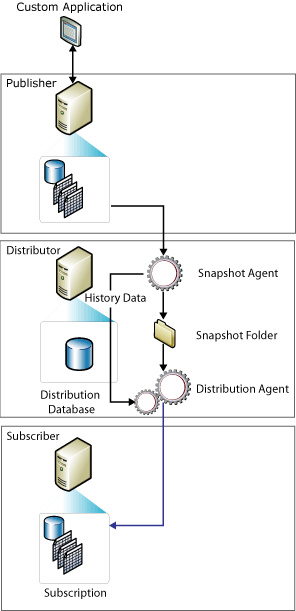
图4.快照复制
事务复制
事务复制就像其名字一样,复制事务。在第一次设置好事务复制后,发布的表、存储过程等将会被镜像,之后每次对于发布服务器所做的改动都会以日志的方式传送到订阅服务器。使得发布服务器和订阅服务器几乎可以保持同步。因此,可以看出事务复制的特点是:
1.发布服务器和订阅服务器内容基本可以同步
2.发布服务器,分发服务器,订阅服务器之间的网络连接要保持畅通。
3.订阅服务器也可以设置成请求订阅,使得订阅服务器也可以不用一直和分发服务器保持连接。
4.适用于要求实时性的环境。
来自MSDN的配图能很好的阐述事务复制,如图5所示
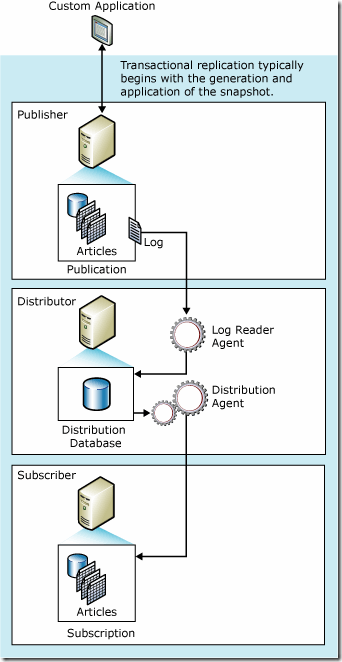
图5.事务复制
合并复制
合并复制即允许发布服务器更新数据库,也允许订阅服务器更新数据。定期将这些更新进行合并,使得发布的数据在所有的节点上保持一致。因此,有可能发布服务器和订阅服务器更新了同样的数据,当冲突产生时,并不是完全按照发布服务器优先来处理冲突,而是根据设置进行处理,这些会在后续文章中讲到。
来自MSDN的配图能很好的阐述合并复制,如图6所示。
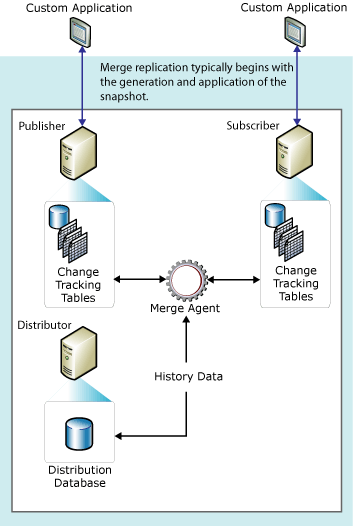
图6.合并复制
建立一个简单的事务复制
下面我进行一个简单的事务复制。首先,在本地安装两个SQL Server实例,我本机安装的两个实例分别为SQL Server 2008R2和SQL Server 2012,其中,SQL Server 2008R2作为发布和分发服务器,SQL Server 2012作为订阅服务器,如图7所示。
图7.复制的两个实例
首先在SQL Server 2008R2上配置发布服务器和分发服务器,选择配置分发,如图8所示。
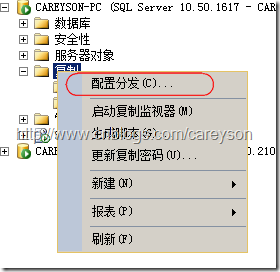
图8.配置分发
将发布服务器和分发服务器选择为同1台,如图9所示。
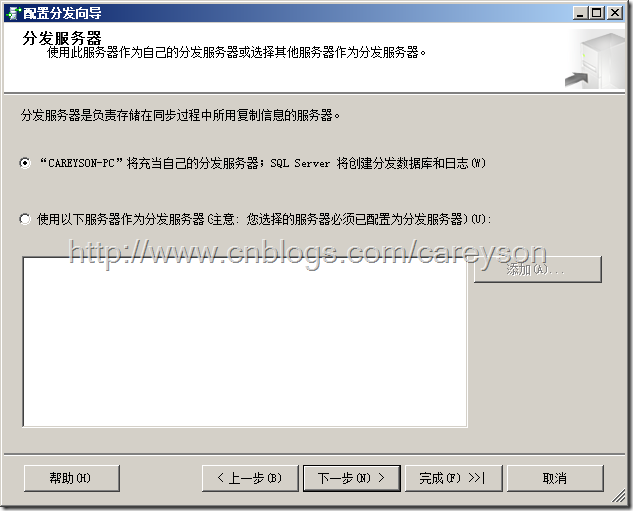
图9.设置发布服务器和分发服务器为同一台服务器
设置快照文件夹,由上面MSDN的图可知,快照代理是需要在分发服务器上暂存快照的,设置这个目录,如图10所示。
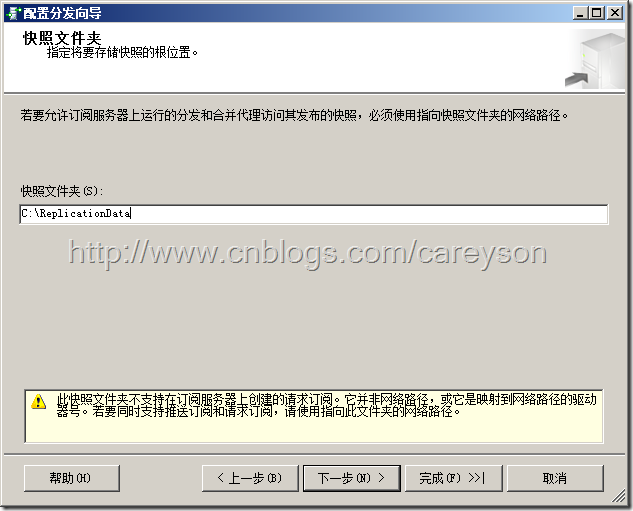
图10.设置快照文件夹
这里值得注意的是,需要给这个目录对于Everyone设置读取权限,如图11所示。
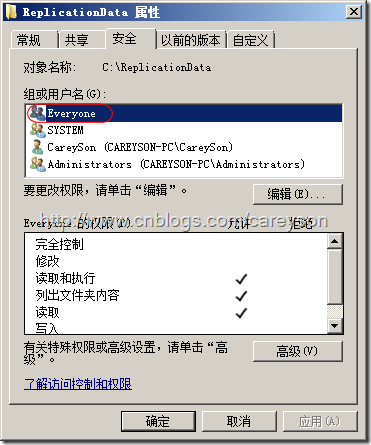
图11.设置读取权限
下一步配置分发向导就按照默认值来,如图12所示。

图12.配置分发向导
剩下的步骤都保持默认值,最后成功在SQL Server 2008R2实例上配置发布服务器和分发服务器,如图13所示。
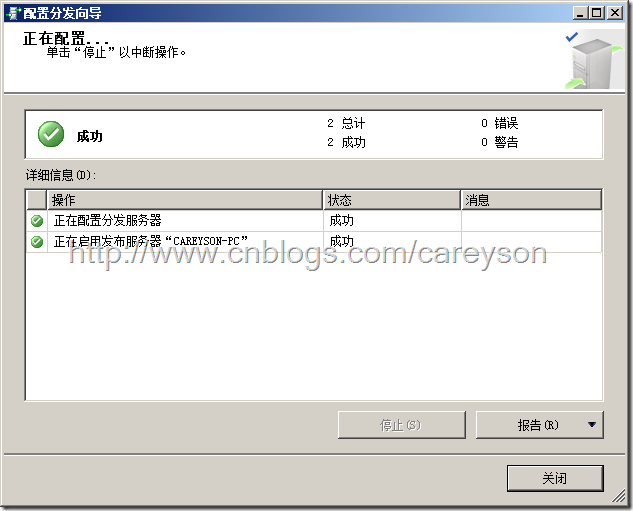
图13.成功配置发布和分发服务器
下面就要建立一个发布了,选择新建发布,如图14所示。
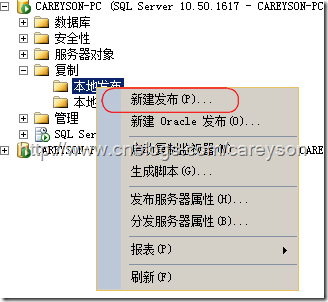
图14.新建发布
一路next,在选择发布类型时选择事务发布,如图15所示。
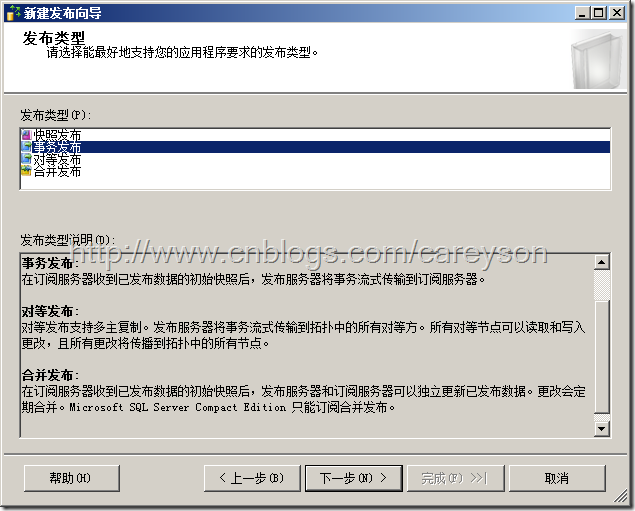
图15.选择事务发布
发布用于测试的一个表,只有两个列,一个为自增的int型主键id,另一个为随便设置的列,如图16所示。
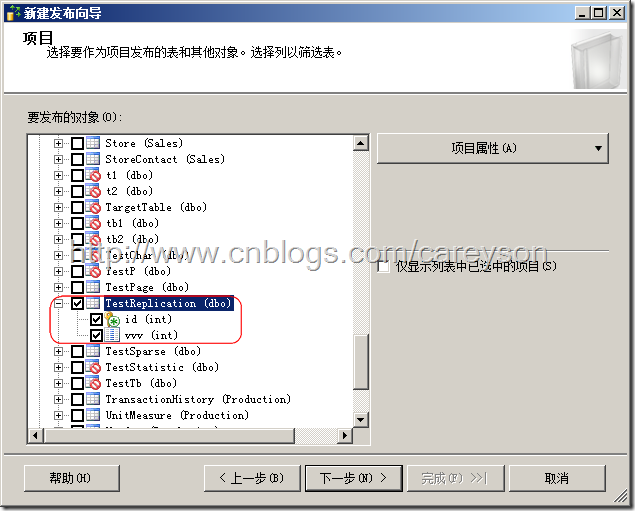
图16.设置发布的表(文章)
下一个页面不过滤文章,直接保持默认值下一步。在下一个窗口中选择立即创建快照并初始化..如图17所示。
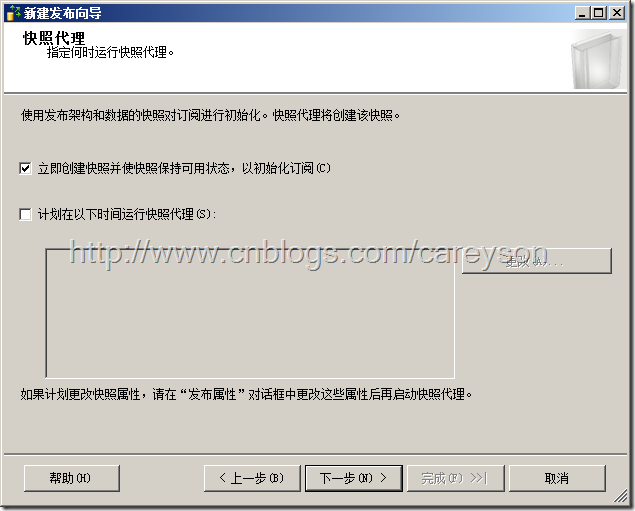
图17.立即创造快照并初始化
安全设置保持和SQL Server Agent一样的账户,如图18所示。
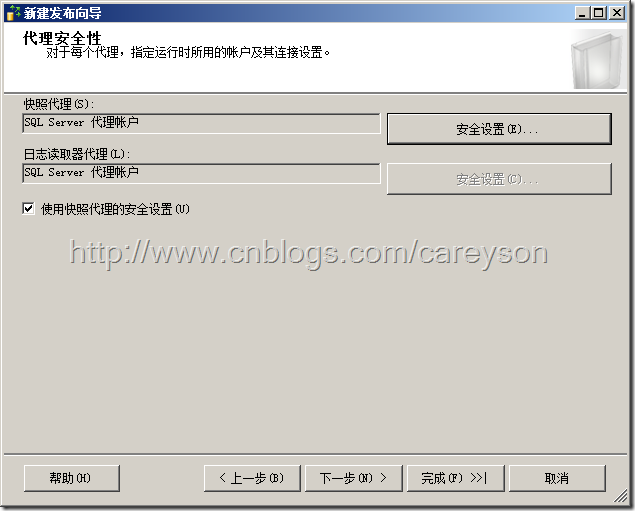
图18.快照代理和日志读取代理设置和SQL Server Agent同一个账户
剩下的步骤一路下一步,设置好发布名称后,成功创建发布,如图19所示。
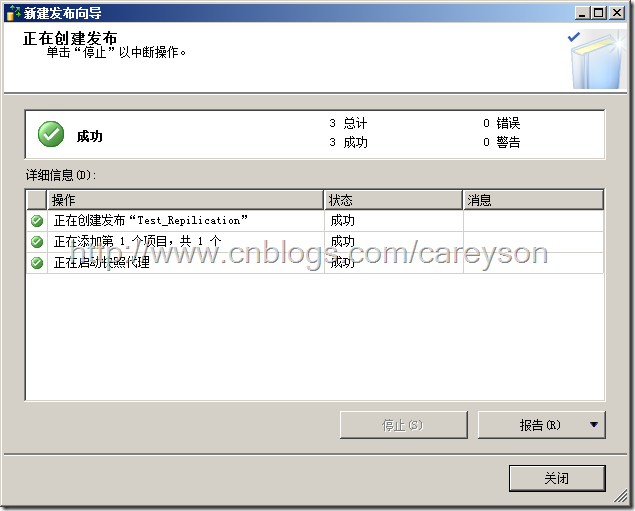
图19.成功创建发布
下面我们来在SQL Server 2012的实例上创建订阅,选择新建订阅,如图20所示。
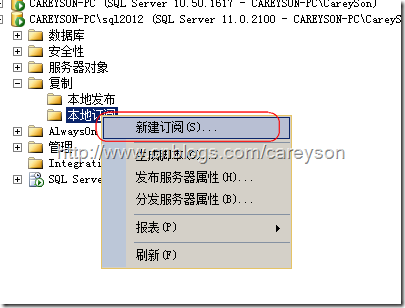
图20.新建订阅
在欢迎界面选择下一步后,选择刚刚创建的发布,如图21所示。
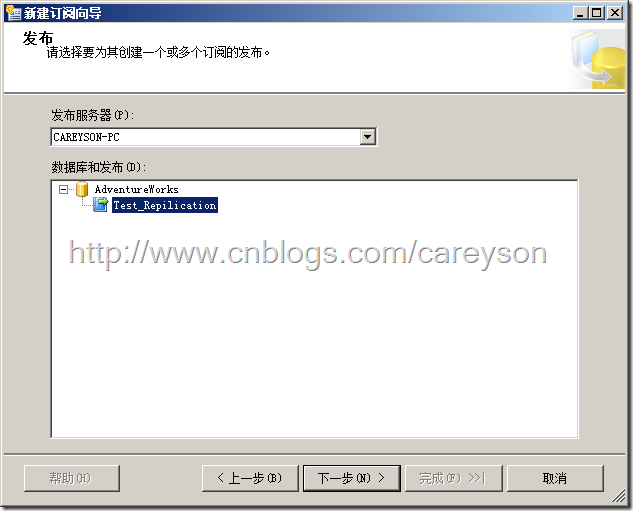
图21.选择发布服务器
下一步选择推送订阅,以便发布服务器所做的改动能自动更改到订阅服务器,如图22所示。
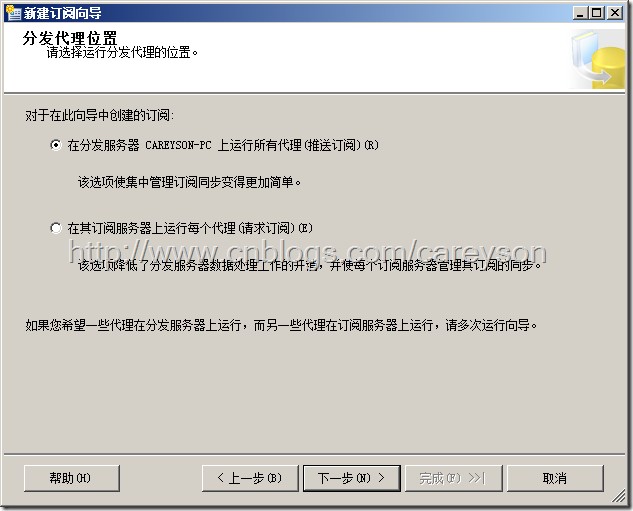
图23.选择推送订阅
选择保持连接,下一步保持默认值,然后在分发代理安全性下选择模拟进程账户。如图24所示。
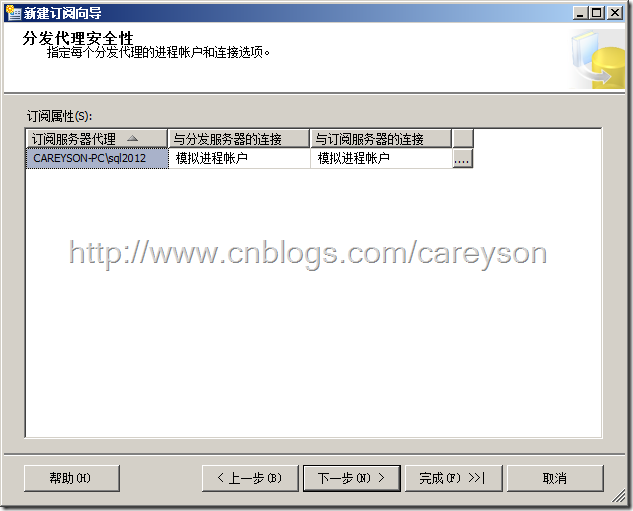
图24.选择模拟进程账户
保持默认值,一路下一步直到订阅创建完成,如图25所示。
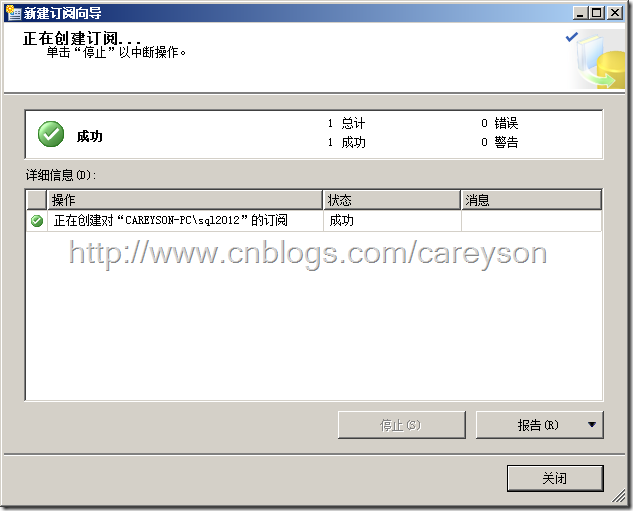
图25.创建订阅成功
现在我们进行测试,向表中插入100条数据,监视状态,发现100个事务已经成功传到了订阅服务器,如图26所示。
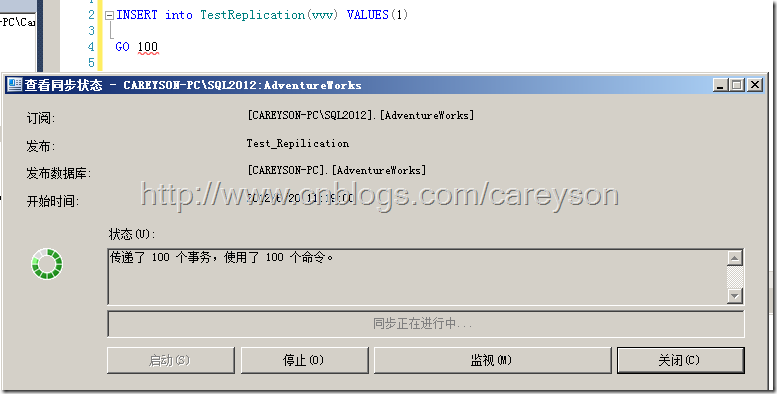
图26.插入的100条数据已经成功传送到订阅服务器
现在我们再来看订阅服务器(SQL Server 2012),在发布服务器插入的100条数据已经成功存在于订阅服务器,如图27所示。
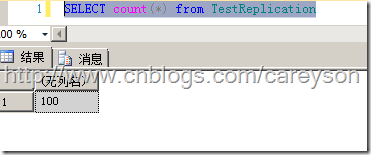
图27.100条数据已经成功发布到了订阅服务器
总结
本文对SQL Server的复制进行了大致的讲解,并实现了一个简单的复制。复制的概念需要对SQL Server的各个方面都要有所涉猎,本系列文章的下一篇将会将复制应用的一些模式。
操作系统中的进程与线程
简介
在传统的操作系统中,进程拥有独立的内存地址空间和一个用于控制的线程。但是,现在的情况更多的情况下要求在同一地址空间下拥有多个线程并发执行。因此线程被引入操作系统。
为什么需要线程?
如果非要说是为什么需要线程,还不如说为什么需要进程中还有其它进程。这些进程中包含的其它迷你进程就是线程。
线程之所以说是迷你进程,是因为线程和进程有很多相似之处,比如线程和进程的状态都有运行,就绪,阻塞状态。这几种状态理解起来非常简单,当进程所需的资源没有到位时会是阻塞状态,当进程所需的资源到位时但CPU没有到位时是就绪状态,当进程既有所需的资源,又有CPU时,就为运行状态。
下面我们来看一个具体的例子:
就拿我写博客的LiveWriter来说,LiveWriter需要监听我打字输入的状态,还需要每隔5分钟对草稿进行自动保存。假设如果这个进程只有一个线程的话,那么当对草稿进行保存时,因为此时需要访问硬盘,而访问硬盘的时间线程是阻塞状态的,这时我的任何输入都会没有响应,这种用户体验是无法接受的,或许我们可以通过键盘或者鼠标的输入去中断保存草稿的过程,但这种方案也并不讨好。而使用多线程,每个线程仅仅需要处理自己那一部分应该完成的任务,而不用去关心和其它线程的冲突。因此简化了编程模型。如图1所示。
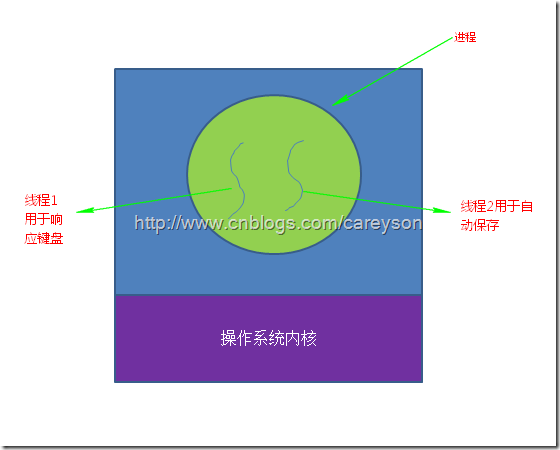
图1.两条线程满足各自的功能
更具体的说,线程的好处如下:
1.在很多程序中,需要多个线程互相同步或互斥的并行完成工作,而将这些工作分解到不同的线程中去无疑简化了编程模型。
2.因为线程相比进程来说,更加的轻量,所以线程的创建和销毁的代价变得更小。
3.线程提高了性能,虽然线程宏观上是并行的,但微观上却是串行。从CPU角度线程并无法提升性能,但如果某些线程涉及到等待资源(比如IO,等待输入)时,多线程允许进程中的其它线程继续执行而不是整个进程被阻塞,因此提高了CPU的利用率,从这个角度会提升性能。
4.在多CPU或多核的情况下,使用线程不仅仅在宏观上并行,在微观上也是并行的。
这里值得注意的是,上面的两个线程如果改成两个进程,那么达不到所要的效果,因为进程有自己独立的内存地址空间,而线程共享进程的内存地址空间。
经典线程模型
另一个看进程和线程的角度是进程模型基于两类不同的概念:资源的组织和执行。在过去没有线程的操作系统中,资源的组织和执行都是由进程完成的。但区分这两者很多时候需要加以区分,这也是为什么需要引入线程。
进程是用于组织资源的单位,进程将相关的资源组织在一起,这些资源包括:内存地址空间,程序,数据等,将这些以进程的形式组织起来可以使得操作系统管理这些资源更为容易。
而线程,是每一个进程中执行的一个条线。线程虽然共享进程中的大多数资源,但线程也需要自己的一些资源,比如:用于标识下一条执行指令的程序计数器,一些容纳局部变量的寄存器,以及用于表示执行的历史的栈。
总而言之:进程是组织资源的最小单位,而线程是安排CPU执行的最小单位。
其实在一个进程中多个线程并行和在操作系统中多个进程并行非常类似,只是线程共享的是地址空间,而进程共享的是物理内存,打印机,键盘等资源……
每一个进程和线程所独自占有的资源如表1所示。
| 进程占有的资源 | 线程占有的资源 |
| 地址空间 全局变量 打开的文件 子进程 信号量 账户信息 |
栈 寄存器 状态 程序计数器 |
表1.进程和线程所独占的资源
其中,线程可以共享进程独占的资源。
我们常用的术语“多线程”一般指的是在同一个进程中多个线程的并发执行。如图2所示。

图2.没有多线程的系统一个进程只能由一个线程
在多线程的进程中,每个线程轮流使用CPU,因此实际上线程并不是并行的,但从宏观上看,是并行的。
在多线程模型中,每一个进程初始创建时只有一个线程。这个线程可以通过调用系统的库函数去创建其它线程。线程创建的线程并必须要为其指定地址,因为新的线程自动在创建它的地址空间内工作。虽然一个线程可以创建另一个线程,但通常来讲,线程之间是并列的,并不存在层级关系。
当一个进程完成其工作后,可以通过调用系统库函数进行销毁。
操作系统实现线程的几种模式
在操作系统中,线程可以实现在用户模式下,也可以实现在内核模式下,也可以两者结合实现。
线程实现在用户空间下
当线程在用户空间下实现时,操作系统对线程的存在一无所知,操作系统只能看到进程,而不能看到线程。所有的线程都是在用户空间实现。在操作系统看来,每一个进程只有一个线程。过去的操作系统大部分是这种实现方式,这种方式的好处之一就是即使操作系统不支持线程,也可以通过库函数来支持线程。
在这种模式下,每一个进程中都维护着一个线程表来追踪本进程中的线程,这个表中包含表1中每个线程独占的资源,比如栈,寄存器,状态等,如图3所示。
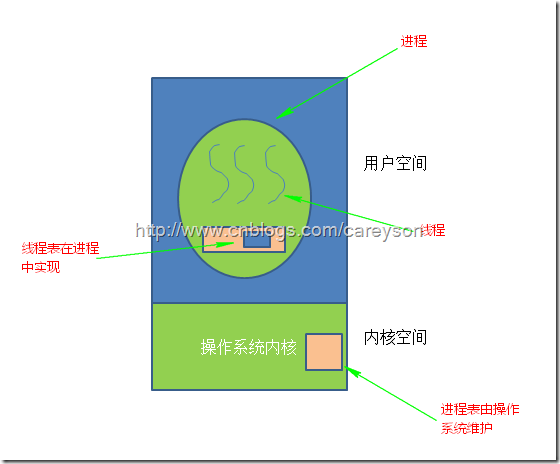
图3.在用户空间中实现线程
这种模式当一个线程完成了其工作或等待需要被阻塞时,其调用系统过程阻塞自身,然后将CPU交由其它线程。
这种的模式的好处,首先,是在用户空间下进行进程切换的速度要远快于在操作系统内核中实现。其次,在用户空间下实现线程使得程序员可以实现自己的线程调度算法。比如进程可以实现垃圾回收器来回收线程。还有,当线程数量过多时,由于在用户空间维护线程表,不会占用大量的操作系统空间。
有好处就有坏处,这种模式最致命的缺点也是由于操作系统不知道线程的存在,因此当一个进程中的某一个线程进行系统调用时,比如缺页中断而导致线程阻塞,此时操作系统会阻塞整个进程,即使这个进程中其它线程还在工作。还有一个问题是假如进程中一个线程长时间不释放CPU,因为用户空间并没有时钟中断机制,会导致此进程中的其它线程得不到CPU而持续等待。
线程实现在操作系统内核中
在这种模式下,操作系统知道线程的存在。此时线程表存在操作系统内核中,如图4所示。
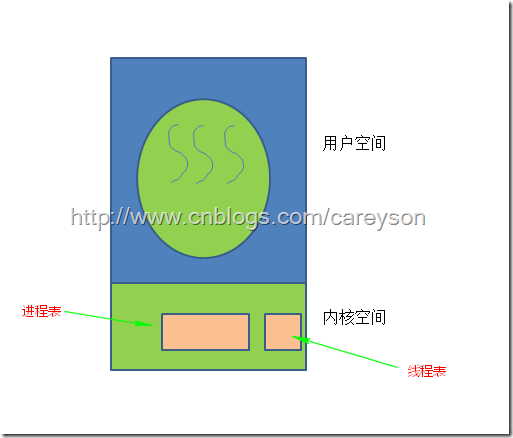
图4.线程在操作系统内核中实现
在这种模式下,所有可能阻塞线程的调用都以系统调用(System Call)的方式实现,相比在用户空间下实现线程造成阻塞的运行时调用(System runtime call)成本会高出很多。当一个线程阻塞时,操作系统可以选择将CPU交给同一进程中的其它线程,或是其它进程中的线程,而在用户空间下实现线程时,调度只能在本进程中执行,直到操作系统剥夺了当前进程的CPU。
因为在内核模式下实现进程的成本更高,一个比较好的做法是另线程回收利用,当一个线程需要被销毁时,仅仅是修改标记位,而不是直接销毁其内容,当一个新的线程需要被创建时,也同样修改被“销毁”的线程其标记位即可。
这种模式下同样还是有一些弊端,比如接收系统信号的单位是进程,而不是线程,那么由进程中的哪一个线程接收系统信号呢?如果使用了表来记录,那么多个线程注册则通过哪一个线程处理系统信号?
混合模式
还有一种实现方式是将上面两种模式进行混合,用户空间中进程管理自己的线程,操作系统内核中有一部分内核级别的线程,如图5所示。

图5.混合模式
在这种模式下,操作系统只能看到内核线程。用户空间线程基于操作系统线程运行。因此,程序员可以决定使用多少用户空间线程以及操作系统线程,这无疑具有更大的灵活性。而用户空间线程的调度和前面所说的在用户空间下执行实现线程是一样的,同样可以自定义实现。
c#Winform程序调用app.config文件配置数据库连接字符串 SQL Server文章目录 浅谈SQL Server中统计对于查询的影响 有关索引的DMV SQL Server中的执行引擎入门 【译】表变量和临时表的比较 对于表列数据类型选择的一点思考 SQL Server复制入门(一)----复制简介 操作系统中的进程与线程的更多相关文章
- c#Winform程序调用app.config文件配置数据库连接字符串
你新建winform项目的时候,会有一个app.config的配置文件,写在里面的<connectionStrings name=" " connectionString= ...
- Winform 数据库连接app.config文件配置 数据库连接字符串
1.添加配置文件 新建一个winform应用程序,类似webfrom下有个web.config,winform下也有个App.config;不过 App.config不是自动生成的需要手动添加,鼠标右 ...
- 获取不到app.config里面的数据库连接字符串的解决方法
今天在自己的类库里添加了对app.config文件的数据库连接字符串的引用,但是返回的居然是Null,纳闷了.然后在网上找到了答案原来是我的app.config文件加错了地方,应该加到启动项目里面,而 ...
- JavaScript日历控件开发 C# 读取 appconfig文件配置数据库连接字符串,和配置文件 List<T>.ForEach 调用异步方法的意外 ef 增加或者更新的习惯思维 asp.net core导入excel 一个二级联动
JavaScript日历控件开发 概述 在开篇之前,先附上日历的代码地址和演示地址,代码是本文要分析的代码,演示效果是本文要实现的效果代码地址:https://github.com/aspwebc ...
- 第19课-数据库开发及ado.net ADO.NET--SQLDataReader使用.SqlProFiler演示.ADoNET连接池,参数化查询.SQLHelper .通过App.Config文件获得连接字符串
第19课-数据库开发及ado.net ADO.NET--SQLDataReader使用.SqlProFiler演示.ADoNET连接池,参数化查询.SQLHelper .通过App.Config文件获 ...
- 如何使用App.config文件,读取字符串?
如何使用App.config文件,读取字符串? .在项目里添加App.config文件,内容如下: <?xml version="1.0" encoding="ut ...
- 通过读取配置文件App.config来获取数据库连接字符串
有两种方式://通过读取配置文件来获取连接字符串 第一种方式: App.config 文件的格式: <?xml version="1.0" encoding="ut ...
- Winform数据库连接app.config文件配置
1.添加配置文件 新建一个winform应用程序,类似webfrom下有个web.config,winform下也有个App.config;不过 App.config不是自动生成的需要手动添加,鼠标右 ...
- winform客户端程序实时读写app.config文件
新接到需求,wcf客户端程序运行时,能实时修改程序的打印机名称: 使用XmlHelper读写 winform.exe.config文件修改后始终,不能实时读取出来,查询博客园,原来已有大神解释了: 获 ...
随机推荐
- install docker-ce for ubuntu
may need login vpn first docker-ce for ubuntu chinese version docker-ce for ubuntu
- mysql查询速度慢的原因[整理版]
在以前的博客中陆续记录了有关查询效率方面的文章.今天在整理一下,写上自己的一些心得记录如下:常见查询慢的原因常见的话会有如下几种:1.没有索引或没有用到索引.PS:索引用来快速地寻找那些具有特定值的记 ...
- 利用JS动态生成隔行换色HTML表格
用JS生成动态生成表格,行.列由用户输入,并使表格隔行换色 方法一. 代码: <!DOCTYPE html> 2 <html> 3 <head> 4 <tit ...
- BZOJ 1968_P1403 [AHOI2005]约数研究--p2260bzoj2956-模积和∑----信息学中的数论分块
第一部分 P1403 [AHOI2005]约数研究 题目描述 科学家们在Samuel星球上的探险得到了丰富的能源储备,这使得空间站中大型计算机“Samuel II”的长时间运算成为了可能.由于在去年一 ...
- poj3537 Crosses ans Crosses
题目描述 题解: 一道非常简单的$SG$函数应用. 对于一个长度求它的$SG$函数,然后判断是否为$0$即可. 代码: #include<cstdio> #include<cstri ...
- mysql5.7配置
my3306.cnf [client] port = 3306 #端口socket = /data/mysql3306/mysql3306.sock #mysql以socket方式运行的soc ...
- 5. COLUMNS
5. COLUMNS 表COLUMNS提供表中列的信息. INFORMATION_SCHEMA Name SHOW Name Remarks TABLE_CATALOG TABLE_SCHEMA TA ...
- InnoDB体系架构总结(一)
缓冲池: 是一块内存区域,通过内存的速度来弥补磁盘速度较慢对数据库性能的影响.在数据库中读取的页数据会存放到缓冲池中,下次再读取相同页的时候,会首先判断该页是否在缓冲池中.对于数据库中页的修改操 ...
- SpringMVC最核心
如图所示:
- asp网页无法打开
环境:Window 2003.IIS6.Framework1.1 .VS2003 一个WebForm项目里面包含一些asp网页 运行后发现asp页面无法访问 提示:无法找到该页 解决方案: 1. [ ...