2018.5.12 storm数据源kafka堆积
问题现象:
storm代码依赖4个源数据topic,2018.5.12上午8点左右开始收到告警短信,源头的4个topic数据严重堆积。
排查:
1、查看stormUI,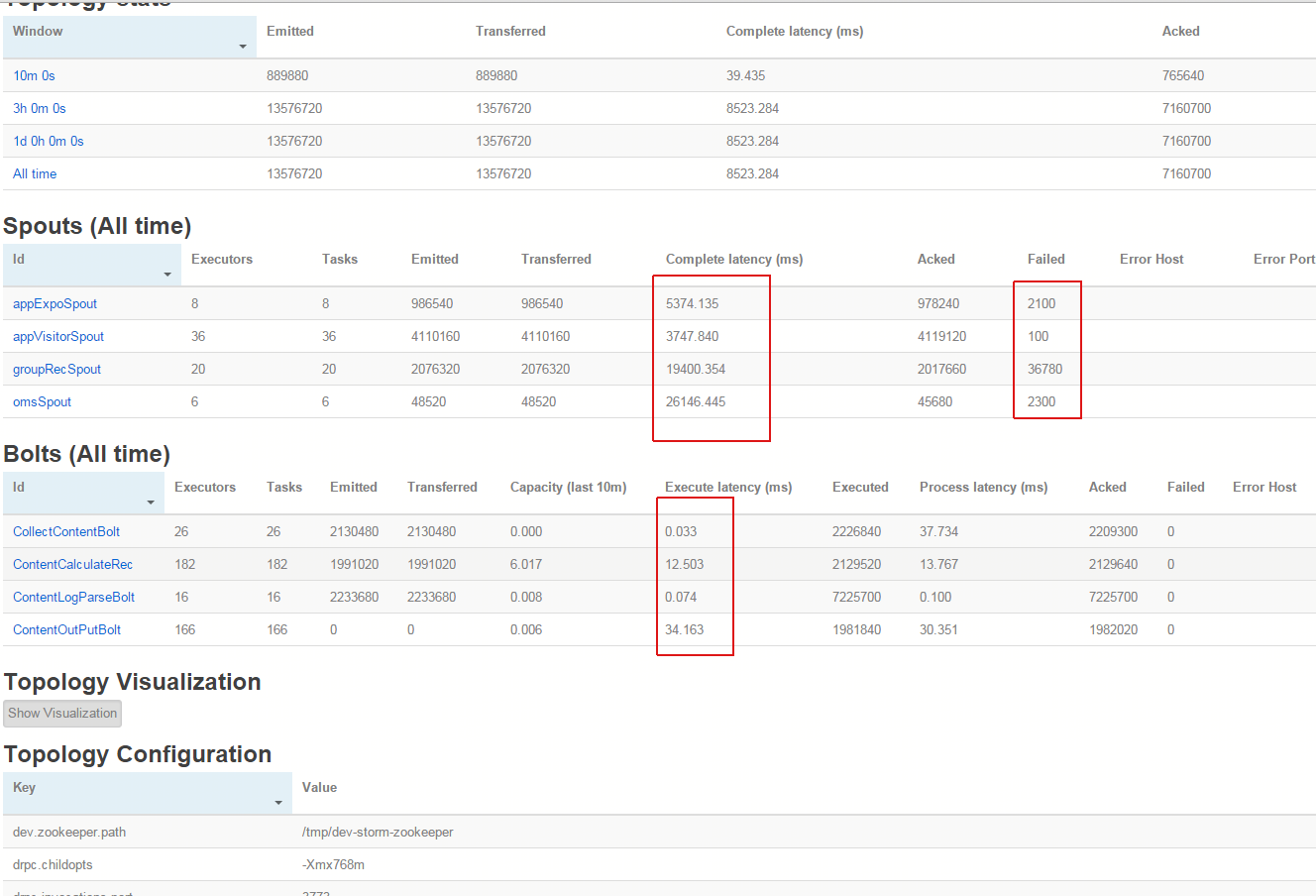
storm拓扑结构如下:
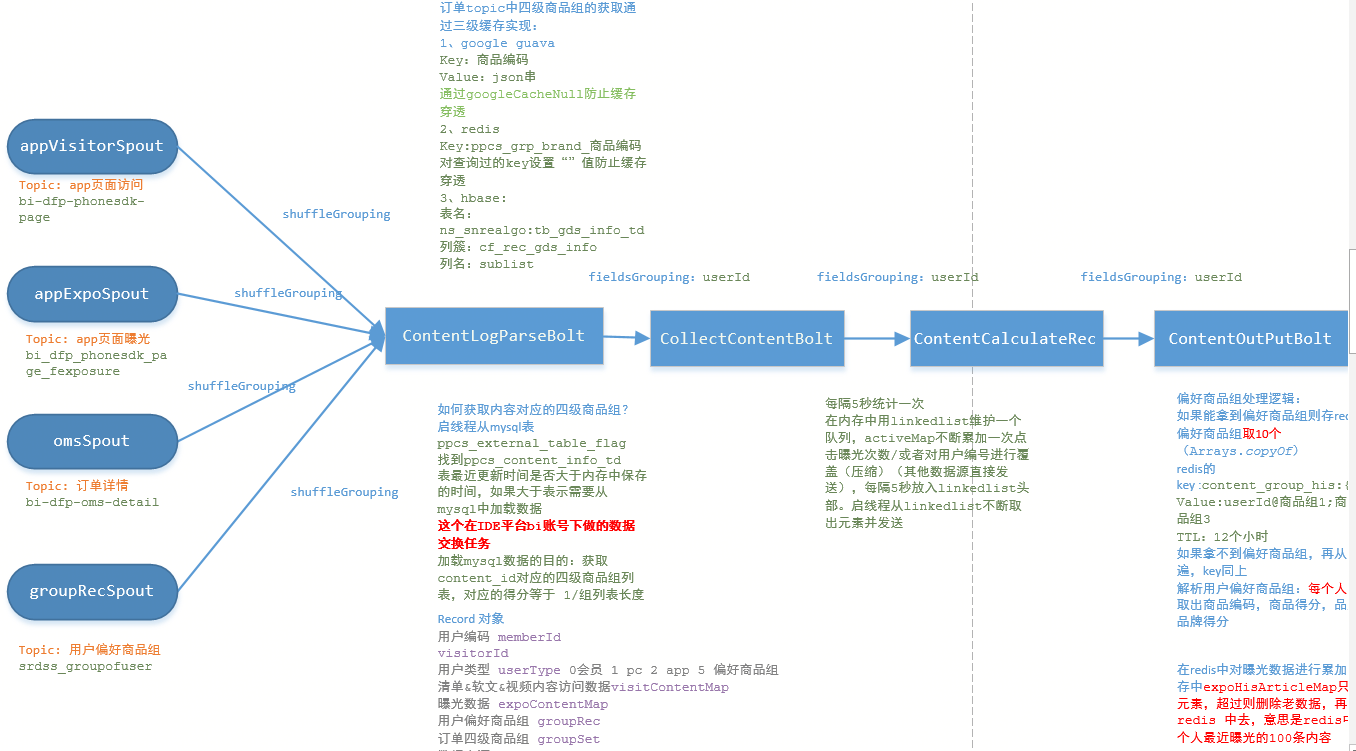
看现象:
a、storm代码2月份上线,已经平稳运行3个月,没有任何代码改动;
b、四个spout发出消息的complete latency 延时较高,高的可达30s,failed数量较多;
c、Topology Visualization中最后一个bolt:ContentOutPutBolt变为红色。
定位步骤:
a、bolt中有脏数据忘记ACK,导致该类数据重发,经检查不存在这个现象,排除这个原因;
b、对最后一个bolt的关键步骤打日志,记录每个步骤的时间,发现在ACK前最后一步写 kafka耗时不稳定,高的可达40s,将问题锁定在写kafka这里;
c、查看storm网卡流量,发现网卡发送数据流量也是从8点开始变高,一直居高不下;
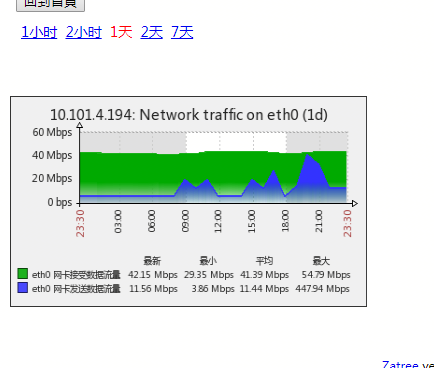
d、联系网络,查看storm与kafka之间的网路是否有延时或丢包,结果情况还好,实际是向kafka域名发送数据,但测的是IP,不知道会不会在域名解析这一层有问题!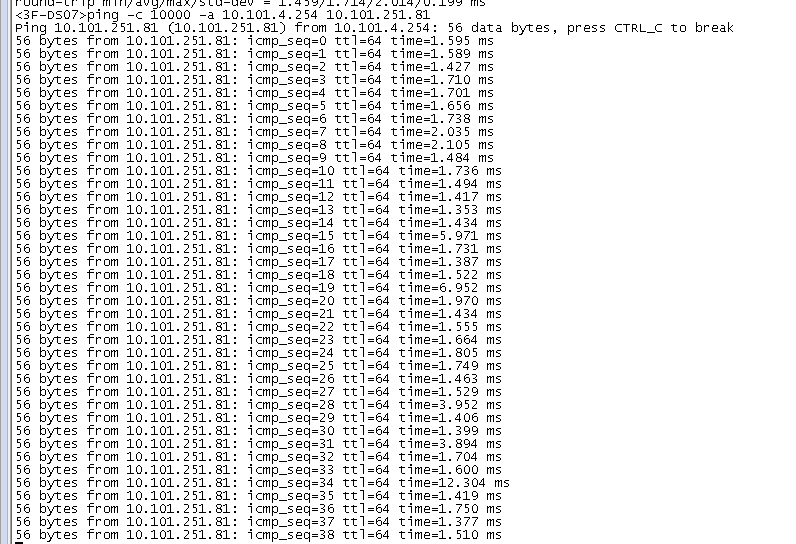
e、为了先解决问题,将源头堆积的数据先消费掉,改了两个地方:1、将ACK放到写KAFKA之前;2、修改写KAFKA的消息长度,改为一半。发现堆积的数据慢慢消费掉,网卡发送流量也趋于平稳,之后将代码回滚,系统依然正常运行,没有再出现堆积,问题解决!
可是问题来了!到底什么原因导致网卡发送流量变高的呢?查看了数据源头的topic并没有突增的情况,难道是查看的方式有问题?费解!
2018.5.12 storm数据源kafka堆积的更多相关文章
- Storm集成Kafka应用的开发
我们知道storm的作用主要是进行流式计算,对于源源不断的均匀数据流流入处理是非常有效的,而现实生活中大部分场景并不是均匀的数据流,而是时而多时而少的数据流入,这种情况下显然用批量处理是不合适的,如果 ...
- Storm 学习之路(九)—— Storm集成Kafka
一.整合说明 Storm官方对Kafka的整合分为两个版本,官方说明文档分别如下: Storm Kafka Integration : 主要是针对0.8.x版本的Kafka提供整合支持: Storm ...
- Storm 系列(九)—— Storm 集成 Kafka
一.整合说明 Storm 官方对 Kafka 的整合分为两个版本,官方说明文档分别如下: Storm Kafka Integration : 主要是针对 0.8.x 版本的 Kafka 提供整合支持: ...
- storm集成kafka
kafkautil: import java.util.Properties; import kafka.javaapi.producer.Producer; import kafka.produce ...
- storm消费kafka实现实时计算
大致架构 * 每个应用实例部署一个日志agent * agent实时将日志发送到kafka * storm实时计算日志 * storm计算结果保存到hbase storm消费kafka 创建实时计算项 ...
- 2018年12月8日广州.NET微软技术俱乐部活动总结
吕毅写了一篇活动总结,写得很好!原文地址是:https://blog.walterlv.com/post/december-event-microsoft-technology-salon.html ...
- storm集成kafka的应用,从kafka读取,写入kafka
storm集成kafka的应用,从kafka读取,写入kafka by 小闪电 0前言 storm的主要作用是进行流式的实时计算,对于一直产生的数据流处理是非常迅速的,然而大部分数据并不是均匀的数据流 ...
- Artificial Intelligence Computing Conference(2018.09.12)
时间:2018.09.12地点:北京国际饭店会议中心
- China Internet Conference(2018.07.12)
中国互联网大会 时间:2018.07.12地点:北京国家会议中心
随机推荐
- 【MatConvNet代码解析】 vl_nnsoftmaxloss
背景知识:http://deeplearning.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92 假设softmax层的输入(softmax ...
- [ZZ] 如何在多版本anaconda python环境下转换spyder
https://www.zhihu.com/people/alexwhu/answers 使用anaconda的话,可以参考以下步骤: 1.打开anaconda navigator,选择左侧的环境菜单 ...
- CentOS下Redis的安装(转)
目录 CentOS下Redis的安装 前言 下载安装包 解压安装包并安装 启动和停止Redis 启动Redis 停止Redis 参考资料 CentOS下Redis的安装 前言 安装Redis需要知道自 ...
- springmvc功能以及源码实现分析
每当我学习一个新技术时,我总是会问自己这个技术有哪些功能,能帮我解决哪些问题. 但是当我在网上进行搜索时,答案并不让我满意. 在使用springmvc很久以后,我将在这篇文章里对springmvc功能 ...
- php对函数的引用
function &example($tmp=0){ //定义一个函数,别忘了加“&”符 return $tmp; ...
- TensorFlow的介绍和安装
TensorFlow概要 由google Brain开源,设计初衷是加速机器学习的研究,2015年11月在GitHub上开源,2016年4月分布式版本,2017年发布了1.0版本,趋于稳定. Tens ...
- IO多路复用(Python)
1. select: 监听多个文件描述符(当文件描述符条件不满足时,select会阻塞),当某个文件描述符状态改变后,将该文件描述符添加到对应返回的列表 调用: fd_r_list, fd_w_lis ...
- send_keys results in Expected 【object Undefined】undefined to be a string解决方法:更新selenium+geckodriver+firefox
很久之前在win10上配置的测试环境: python 3.6.1+ selenium 3.3.3+ geckodriver 0.15.0以前run case是正常的,今天去run 同样的case时发现 ...
- scikit-learn框架学习笔记(一)
sklearn于2006年问世于Google,是使用python语言编写的.基于numpy.scipy和matplotlib的一个机器学习算法库,设计的非常优雅,它让我们能够使用同样的接口来实现所有不 ...
- Oracle层级询语句connect by 用法详解
如果表中包含层级数据,那么你就可以使用层级查询从句选择行层级顺序. 1.层级查询从句语法 层级查询从句语法: { CONNECT BY [ NOCYCLE ] condition [AND condi ...