Python之字符编码与文件操作
目录
字符编码
什么是字符编码?
'''
字符编码就是制定的一个将人类的语言的字符与二进制数据一一对应地翻译过来的标准。
'''
字符编码的发展史与分类:
计算机最早的字符编码为ASCII,只规定了英文字母、数字和一些特殊字符与数字一一对应关系。最多只能用8位来表示一字节(0~255),即2**8-1=255。但是由于不能语言的人的 需要,ASCII是不能适用所有人的需求的,因此有了不同类型的字符编码,如中文的字符编码就是GBK。而要表示中文,只用一个字节是不够的,解决办法就是一个字符占更多的bit。在GBK中,一个中文字符占两个字节,而一个英文字符只占一个字节。其他国家也有自己制定的字符编码,但是问题是如果在一个文档里同时用好几种语言,那么就会出现乱码,所以需要unicode。
unicode是只认字符的,用两个字节代表一个字符,生僻字要用四个字节。unicode虽然是万国码,能解决不语言的表达问题,但是无法兼容之前的已用其他字符编码编写的文件。于是unicode被逼无奈只能加入其他字符编码的转换、兼容功能(现在内存中的编码固定就是unicode)。
一切看起来都完美了,只等大家慢慢放弃使用那些其他字符编码。但是unicode也没停止改进。unicode的问题是无论是什么字符它都用两个字节保存,因为英文字母、数字及一些特殊字符是可以用一个字节表示的,这样就徒增了I/O次数,效率变低了。所以出了unicode的升级版,utf-8。
总结:
1.保证不乱码的根本方法就是:按照哪种字符编码编写的就用那种字符编码解码。
2.内存中所有字符都是unicode编码。
Python2和Python3中字符串类型的差别
一Python2中有两种字符串类型str和unicode:
str类型
当Python解释器执行到产生字符串的代码上时,会申请新的内存地址,将编码成文件头制定的编码格式。
想看该字符串在内存中的真实格式,可以放到列表中再打印,不要直接打印,因为直接print会自动转换编码,这是python的优化机制。
内存中数据 通常使用16进制表示,一个字节GBK需要两个bytes,存一个英文需要一个bytes。那么是怎样区分中英文呢?原来GBK会用每个bytes的 第一位作为标志,第一位是1则表示是中文字符,如果是0则表示是个英文字符。也就是说,GBK每个bytes留给我们真正存值的有效位数只有七位,而unicode中存放的只是这有效的七位,至于首位的标识符与具体的编码有关。
unicode类型
当Python解释器执行到产生unicode编码的字符串的代码时,会申请新的内存地址,然后以unicode的格式存放在内存空间,所以该字符串只能用于编码而不用于解码。
二Python3中的两种字符串类型:
str类型是unicode的,在Python3中的bytes类型在Python2中是str类型。
文件操作
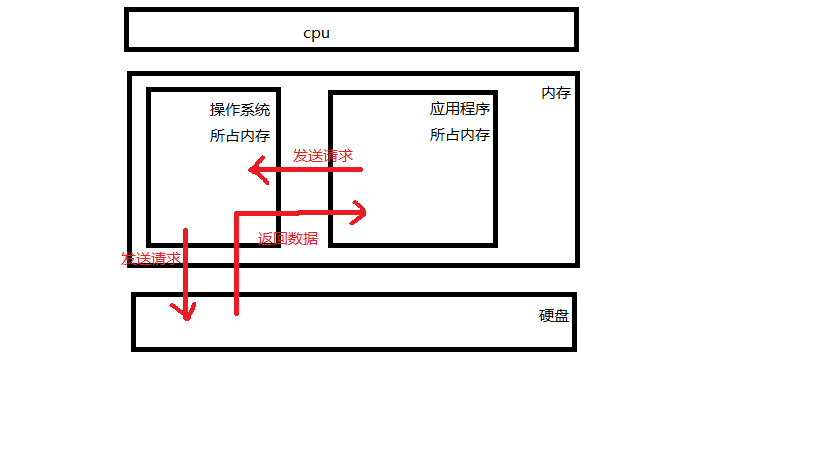
计算机系统分为三大部分:应用程序、操作系统、计算机硬件。
我们要是想把数据永久保存下来就必须保存在硬盘,但是应用程序是无法直操作硬件的。计算机操作系统把复杂的硬件封装成简单的接口给用户或操作系统用,其中的文件就是操作系统提供给应用程序来操作硬盘的虚拟概念。有了文件的概念,我们就无需考虑操作硬盘的细节而只需要关注操作 文件的流程:
#1.打开文件,得到文件句柄并赋值给一个变量
#2.通过句柄操作文件
#3.关闭文件
'''
文件句柄就是文件描述符,在文件I/O中想要读取文件的数据,应用程序首先要调用操作系统函数并传送文件名,并选一个到该文件的路径打开文件。该函数取回一个顺序号就是文件句柄,该文件句柄
是打开文件的唯一标识符。
'''

值得注意的是:
每打开一个文件都占用了操作系统和应用程序两方资源。每打开一个文件操作系统都会给文件一个编号(文件描述符),完成之后就要回收资源,顺序是先回收系统级资源再回收应用程序级资源。在python中应用级资源不写回收的del f也没关系,因为python有自动回收机制,但是要记得系统级资源回收。
如果实在不记得回收,那最好用这种方式操作文件:
with open('a.txt','w') as f:
pass
with open('a.txt','r') as f1,open('b.txt','w') as f2:
data=f1.read()
f2.write(data)
文件操作的方式
f.read() #读取所有内容,光标移动到文件末尾
f.readline() #读取一行内容,光标移动到第二行首部
f.readlines() #读取每一行内容,存放于列表中 f.write('1111\n222\n') #针对文本模式的写,需要自己写换行符
f.write('1111\n222\n'.encode('utf-8')) #针对b模式的写,需要自己写换行符
f.writelines(['333\n','444\n']) #文件模式
f.writelines([bytes('333\n',encoding='utf-8'),'444\n'.encode('utf-8')]) #b模式 f.readable() #文件是否可读
f.writable() #文件是否可读
f.closed #文件是否关闭
f.encoding #如果文件打开模式为b,则没有该属性
f.flush() #立刻将文件内容从内存刷到硬盘
f.name
示例:
#rb模式
# f=open(r'a.txt','rb')
# print(f.readable())#判断是否可读
# f.close() # with open('a.txt','rb') as f:
# for line in f:
# print(line)#循环文件内容 # with open(r'a.txt','rb') as f:
# print(f.read())
# print(type(f.read())) # with open('a.txt','rb') as f1,\
# open('1.jpg','rb') as f2:
# data=f1.read()
# print(data,type(data))
# print(data.decode('utf-8'))
#
# data2=f2.read()
# print(data2)
# print(type(data2)) #ab模式
# with open('a.txt','ab') as f:
# f.write('你好\n这里是一个小测试。\n为了测试追加模式'.encode('utf-8')) #wb模式
# with open('a.txt','wb') as f:
# f.write('在弗兰德斯的战场上\n罂粟花随风飘扬\n一朵又一朵地在殇者的十字架间绽放'.encode('utf-8'))
# f.close() # f=open(r'a.txt','wb')
# print(f.writable())
# f.close() #rt模式
# f=open('b.txt','r',encoding='utf-8')
# print(f.read())#第一种循环方式
# f.close() # f=open('b.txt','r',encoding='utf-8')
# for line in f:
# print(line,end='')#第二种循环
# f.close() # f=open('b.txt','r',encoding='utf-8')
# print(f.readlines())
# f.close() #wt模式
# with open('a.txt','w',encoding='utf-8') as f,\
# open('t.txt','w',encoding='utf-8') as f1:
# print(f.writable()) # f=open('a.txt','w',encoding='utf-8')
# f.writelines(['在弗兰德斯的战场\n','罂粟花随风飘扬\n','一朵又一朵\n','绽放在殇者的十字架之间'])
# f.close() # f=open('a.txt','w',encoding='utf-8')
# f.write('这是一个长字符串,\n想换行要用转义符,\n转义成功了吗?')
# f.close() #at追加模式
# f=open('a.txt','a',encoding='utf-8')
# f.write('\n在弗兰德斯的战场\n罂粟花随风飘扬\n一朵又一朵\n绽放在殇者的十字架之间')
# f.close()
注意:
b模式、t模式都是不能单独使用的,必须是配合的rb/t、wb/t、ab/t。
b模式是以bytes为单位的,t模式是以字符为单位的。
b模式下不能指定字符编码。
文件内光标的移动
一: read(3):
1. 文件打开方式为文本模式时,代表读取3个字符
2. 文件打开方式为b模式时,代表读取3个字节
二: 其余的文件内光标移动都是以字节为单位如seek,tell,truncate
注意:
1. seek有三种移动方式0,1,2,其中1和2必须在b模式下进行,但无论哪种模式,都是以bytes为单位移动的
2. truncate是截断文件,所以文件的打开方式必须可写,但是不能用w或w+等方式打开,因为那样直接清空文件了,所以truncate要在r+或a或a+等模式下测试效果
文件修改
文件是存在硬盘上的,因此不存在文件修改,而是文件覆盖。我们平时看到的修改只是模拟出来的效果。
具体方式:
一.将文件读到内存,在内存中修改,保存时再由内存覆盖硬盘。
with open('a.txt','r',encoding='utf-8') as f:
data=f.read()
data=data.replace('我曾是少年','我也曾是少年')
with open('a.txt','w',encoding='utf-8') as f:
f.write(data)
二:将文件一行一行读入内存,在内存中修改,修改完写入新文件,保存时用新文件覆盖旧文件。
import os
with open('a.txt','r',encoding='utf-8') as f,\
open('b.txt','w',encoding='utf-8') as fb:
for line in f:
if '我也曾是少年' in line:
line=line.replace('我也曾是少年','昨日,我也曾是少年')
fb.write(line)
os.remove('a.txt')
os.rename('b.txt','a.txt')
Python之字符编码与文件操作的更多相关文章
- python基础--字符编码以及文件操作
字符编码: 1.运行程序的三个核心硬件:cpu.内存.硬盘 任何一个程序要是想要运算,肯定是先从硬盘加载到当前的内存中,然后cpu根据指定的指令去执行操作 2.python解释器运行一个py文件的步骤 ...
- python学习道路(day3note)(元组,字典 ,集合,字符编码,文件操作)
1.元组()元组跟列表一样,但是不能增删改,能查.元组又叫只读列表2个方法 一个 count 一个 index2.字典{}字典是通过key来寻找value因为这里功能比较多,所以写入了一个Code里面 ...
- Python-字典、集合、字符编码、文件操作整理-Day3
1.字典 1.1.为什么有字典: 有个需求,存所有人的信息 这时候列表就不能轻易的表示完全names = ['stone','liang'] 1.2.元组: 定义符号()t = (1,2,3)tupl ...
- Python 字符编码及其文件操作
本章节内容导航: 1.字符编码:人识别的语言与机器机器识别的语言转化的媒介. 2.字符与字节:字符占多少个字节,字符串转化 3.文件操作:操作硬盘中的一块区域:读写操作 注:浅拷贝与深拷贝 用法: d ...
- Python全栈开发之路 【第三篇】:Python基础之字符编码和文件操作
本节内容 一.三元运算 三元运算又称三目运算,是对简单的条件语句的简写,如: 简单条件语句: if 条件成立: val = 1 else: val = 2 改成三元运算: val = 1 if 条件成 ...
- Python 入门基础6 --字符编码、文件操作1
今日内容: 1.字符编码 2.字符与字节 3.文件操作 一.字符编码 了解: cpu:将数据渲染给用户 内存:临时存放数据,断电消失 硬盘:永久存放数据,断电后不消失 1.1 什么是编码? 人类能够识 ...
- Python基础之字符编码,文件操作流与函数
一.字符编码 1.字符编码的发展史 阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII ASCII:一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit ...
- python基础——6(字符编码,文件操作)
今日内容: 1.字符编码: 人识别的语言与机器识别的语言转化的媒介 ***** 2.字符与字节: 字符占多少字节,字符串转化 *** 3.文件操作: 操作硬盘中的一块区域:读写操作 ...
- python字符编码与文件操作
目录 字符编码 字符编码是什么 字符编码的发展史 字符编码实际应用 编码与解码 乱码问题 python解释器层面 文件操作 文件操作简介 文件的内置方法 文件的读写模式 文件的操作模式 作业 答案 第 ...
随机推荐
- React 学习(六) ---- 父子组件之间的通信
当有多个组件需要共享状态的时候,这就需要把状态放到这些组件共有的父组件中,相应地,这些组件就变成了子组件,从而涉及到父子组件之间的通信.父组件通过props 给子组件传递数据,子组件则是通过调用父组件 ...
- Tomcat服务的安装与配置
介绍 百度百科 Tomcat是Apache 软件基金会(Apache Software Foundation)的Jakarta 项目中的一个核心项目,由Apache.Sun 和其他一些公司及个人共同开 ...
- 以计算斐波那契数列为例说说动态规划算法(Dynamic Programming Algorithm Overlapping subproblems Optimal substructure Memoization Tabulation)
动态规划(Dynamic Programming)是求解决策过程(decision process)最优化的数学方法.它的名字和动态没有关系,是Richard Bellman为了唬人而取的. 动态规划 ...
- Linux查看实时网卡流量的几种方式
Linux查看实时网卡流量的几种方式 来源 https://www.jianshu.com/p/b9e942f3682c 在工作中,我们经常需要查看服务器的实时网卡流量.通常,我们会通过这几种方式查 ...
- Equivalent Sets HDU - 3836 (Tarjan)
题目说给出一些子集,如果A是B的子集,B是A的子集,那么A和B就是相等的,然后给出n个集合m个关系,m个关系表示u是v的子集,问你最小再添加多少个关系可以让这n个集合都是相等的 如果这n个几个都是互相 ...
- pandas to_html
如何将表格数据以图片的形式展现,主要目的则是为了防止爬虫. 为了解决这个问题,刚开始选择的是matplotlib.pyplot.table,但由于随着数据的字段长短不一,且matplotlib实际落地 ...
- lnmp架构搭建实例
lamp->lnmp nginx survey.netcraft.net 查看各大网站使用的web服务器,使用下面的命令 # curl -I www.sina.com 结论:现在大型网站几乎统一 ...
- 小白眼中的AI之~Numpy基础
周末码一文,明天见矩阵- 其实Numpy之类的单讲特别没意思,但不稍微说下后面说实际应用又不行,所以大家就练练手吧 代码裤子: https://github.com/lotapp/BaseCode ...
- Spring -- <mvc:annotation-driven />
<mvc:annotation-driven /> 会自动注册:RequestMappingHandlerMapping .RequestMappingHandlerAdapter 与Ex ...
- uWSGI+Nginx安装、配置
1.关闭SELINUX: [root@PYTHON27 /]# vim /etc/selinux/config 将SELINUX=enforcing修改为SELINUX=disabled 2.关闭防火 ...