zepplin0.7.2报错ERROR, exception: null, result: %text java.lang.NullPointerException的处理
zepplin0.7.2报错ERROR, exception: null, result: %text java.lang.NullPointerException的处理
问题描述:
使用zepplin查询业务系统数据时报错空指针,具体如下:
interpreter.remote.RemoteInterpretershared_session736569169
INFO [2018-01-05 14:54:50,040] ({pool-2-thread-5} Paragraph.java[jobRun]:362) - run paragraph 20180105-103927_694288565 using null org.apache.zeppelin.interpreter.LazyOpenInterpreter@1392e985
WARN [2018-01-05 14:55:29,579] ({pool-2-thread-8} NotebookServer.java[afterStatusChange]:2058) - Job 20180105-103053_111827741 is finished, status: ERROR, exception: null, result: %text java.lang.NullPointerException
at org.apache.zeppelin.spark.Utils.invokeMethod(Utils.java:38)
at org.apache.zeppelin.spark.Utils.invokeMethod(Utils.java:33)
at org.apache.zeppelin.spark.SparkInterpreter.createSparkContext_2(SparkInterpreter.java:391)
at org.apache.zeppelin.spark.SparkInterpreter.createSparkContext(SparkInterpreter.java:380)
at org.apache.zeppelin.spark.SparkInterpreter.getSparkContext(SparkInterpreter.java:146)
at org.apache.zeppelin.spark.SparkInterpreter.open(SparkInterpreter.java:828)
at org.apache.zeppelin.interpreter.LazyOpenInterpreter.open(LazyOpenInterpreter.java:70)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:491)
at org.apache.zeppelin.scheduler.Job.run(Job.java:175)
at org.apache.zeppelin.scheduler.FIFOScheduler$1.run(FIFOScheduler.java:139)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
INFO [2018-01-05 14:55:29,611] ({pool-2-thread-8} SchedulerFactory.java[jobFinished]:137) - Job paragraph_1515119453288_-2049614157 finished by scheduler org.apache.zeppelin.interpreter.remote.RemoteInterpretershared_session736569169
WARN [2018-01-05 14:55:31,227] ({pool-2-thread-5} NotebookServer.java[afterStatusChange]:2058) - Job 20180105-103927_694288565 is finished, status: ERROR, exception: null, result: %text java.lang.OutOfMemoryError: GC overhead limit exceeded
看了下语句:
(hive)
select appid,count(distinct yunvaid) as c1 from t_user_login
where day='20171228'
group by appid
order by c1 desc
分析:
1.在zepplin的这个任务中查询select * from t_user_login limit 10无法查出数据
2.在另外的查询后台hue中是可以查询这条语句的
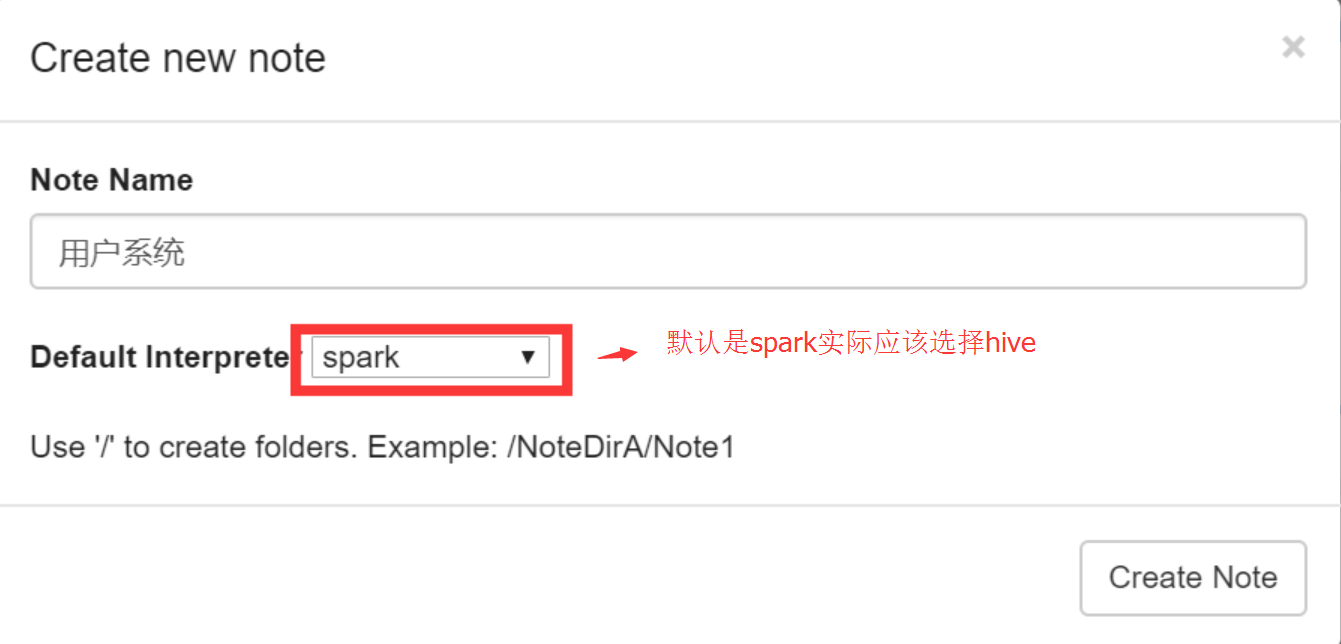
3.新建一个任务hive_tst使用hive类型的,是没问题的
后面直接运行这个任务也可以正常执行
(hive)
select appid,count(distinct yunvaid) as c1 from t_user_login
where day='20171228'
group by appid
order by c1 desc
发现是运营的同事新建任务的时候选择了默认的spark类型所以无法进行查询,我们没有用spark

zepplin0.7.2报错ERROR, exception: null, result: %text java.lang.NullPointerException的处理的更多相关文章
- 给内部类对象数组属性赋值时报错:Exception in thread "main" java.lang.NullPointerException
前言 1255: 打怪升级(Java),写这个题目程序的时候,控制台提示如下错误: Exception in thread "main" java.lang.NullPointer ...
- idea 运行scala代码 报错:Exception in thread "main" java.lang.NoClassDefFoundError: scala/Predef$ java.lang.NoClassDefFoundError: scala/Function0 Error: A JNI error has occurred, please check your installati
各种报错信息如下: java.lang.NoClassDefFoundError: scala/Function0 at java.lang.Class.getDeclaredMethods0(Nat ...
- storm报错:Exception in thread "main" java.lang.RuntimeException: InvalidTopologyException(msg:Component: [mybolt] subscribes from non-existent stream: [default] of component [kafka_spout])
问题描述: storm版本:1.2.2,kafka版本:2.11. 在使用storm去消费kafka中的数据时,发生了如下错误. [root@node01 jars]# /opt/storm-1. ...
- spark-shell报错:Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/fs/FSDataInputStream
环境: openSUSE42.2 hadoop2.6.0-cdh5.10.0 spark1.6.0-cdh5.10.0 按照网上的spark安装教程安装完之后,启动spark-shell,出现如下报错 ...
- 报错:Exception in thread "main" java.lang.NoClassDefFoundError: Lorg/apache/hadoop/fs/FileSystem
报错现象: Exception in thread "main" java.lang.NoClassDefFoundError: Lorg/apache/hadoop/fs/Fil ...
- SSH整合后tomcat启动报错SEVERE: Exception starting filter struts2 java.lang.NoClassDefFoundError: org/objectweb/asm/ClassVisitor
错误信息: SEVERE: Exception starting filter struts2 java.lang.NoClassDefFoundError: org/objectweb/asm/C ...
- JFinal启动报错:Exception in thread "main" java.lang.NoClassDefFoundError: org/eclipse/jetty/server/Connector
- 错误: Exception in thread "main" java.lang.NoClassDefFoundError: org/eclipse/jetty/server/ ...
- java报错:Exception in thread "main" java.lang.NoSuchFieldError: INSTANCE
Exception in thread "main" java.lang.NoSuchFieldError: INSTANCE at org.apache.http.conn.ss ...
- Storm本地启动拓扑报错:Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/storm/topology/IRichSpout
问题描述: Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/storm/topology ...
随机推荐
- [leetcode-128] 最长连续序列
给定一个未排序的整数数组,找出最长连续序列的长度. 要求算法的时间复杂度为 O(n). 示例: 输入: [100, 4, 200, 1, 3, 2] 输出: 4 解释: 最长连续序列是 [1, 2, ...
- Spark常见问题汇总
原文地址:https://my.oschina.net/tearsky/blog/629201 摘要: 1.Operation category READ is not supported in st ...
- windows10 下使用Pycharm2016 基于Anaconda3 Python3.6 安装Mysql驱动总结
本文记录:在PyCharm2016.3.3 中基于Anaconda3 Python3.6版本安装Python for Mysql驱动.尝试了安装Mysql-Connector成功,但是连接数据库时驱动 ...
- SQL Server进阶 遍历表的几种方法
https://www.cnblogs.com/mcgrady/p/4182486.html
- 使用 CROSS APPLY 与 OUTER APPLY 连接查询
Ø 前言 日常开发中遇到多表查询时,首先会想到 INNER JOIN 或 LEFT OUTER JOIN 等等,但是这两种查询有时候不能满足需求.比如,左表一条关联右表多条记录时,我需要控制右表的某 ...
- JVM学习(一)简介
一.java程序编译到运行大概流程 1.Source Code Files为.java文件 2.通过编译产生可执行的字节码. 3.通过jvm得到机器可以执行的机器码 4.操作系统运行机器码,并与硬件进 ...
- oracle 问题查找 error ora-
Error ORA-03113: 通信通道的文件结尾进程 ID: 2232会话 ID: 1250 序列号: 这是oracle 报的错误, 可能这个03113这个编码的错误有很多. 但是要找到是什么原因 ...
- CSS强制英文、中文换行与不换行
.p1{ word-break:break-all; width:150px;}/*只对英文起作用,以字母作为换行依据*/ .p2{ word-wrap:break-word; width:150px ...
- javascript文档
DOM Document <html> Document 对象 每个载入浏览器的 HTML 文档都会成为 Document 对象. Document 对象使我们可以从脚本中对 HTML 页 ...
- Hbase使用MapReduce编程导出数据到HDFS
废话少说,直接上代码! package cn.com.oozie.demo; import java.io.IOException; import org.apache.hadoop.conf.C ...