elasticSearch新认知
之前已经学习使用过ElasticSearch的使用,今天补充巩固一下...
上一次的环境是在 linux下使用 EalsticSearch(安装教程详见:https://www.cnblogs.com/msi-chen/p/10335794.html),
今天的笔记内容为:
1.今天的环境我windows本地使用和 docker内的使用;
2.Head插件在windows和docker的简单配套使用;
3.logstash 完成mysql 和 ES 的数据同步;
ES相对于solr:在面对实时查询大数据量数据时提供强劲的查询速度,无需过多配置支持分布式,开箱即用,
ES的体系结构: 索引 ( index ) ——> 类型 ( type ) ——> 文档 ( document )
在 windows 上的使用:
ES 在windows上的使用,没有 Linux上的复杂配置,解压开箱即用即可
提供服务的ES提供了两个接口以供调用 9200(其他), 9300 (java)
ES是基于Resyful web接口的,我们可以使用 rest请求 对其进行简单操作
比如put提交新建索引,post提交新建文档,get提交查询文档,delete提交删除文档...不多赘述
Head插件的安装与使用:
ES有跨域保护,默认不允许跨域调用,Head想调用需要修改相关配置:
elasticsearch.yml 追加两个配置:
http.cors.enabled: true
http.cors.allow‐origin: "*"
安装node js ,安装cnpm : npm install ‐g cnpm ‐‐registry=https://registry.npm.taobao.org
将 grunt 安装我全局命令 : npm install ‐g grunt‐cli
安装依赖 : cnpm install
cmd 找到解压目录 : grunt server 运行即可,访问:localhost:9100
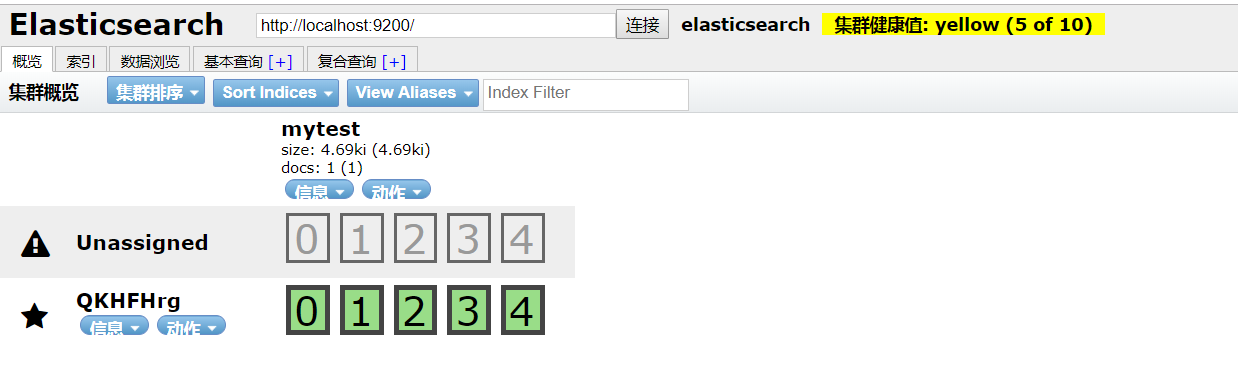
在这里,我们可以看到我们创建了一个名为 myTest 的索引,这个工具着实是简陋,下面我们来粗略的了解一下
创建索引:
整个页面很简单,多熟悉熟悉即可(put 可用于创建,如果已经被创建,则视为修改)
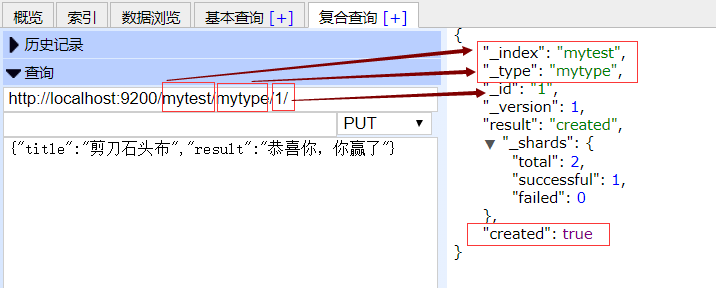
接下来就是了解一下 IK 分词器:
ES 默认自带的中文分词器是一个字为一个词,显然这个不是偶棉想要的结果
于是便引入了现在很流行的 IK分词器,配置也很简单:
将 IK分词器解压到 elasticsearch/plugins / 重启ES服务即可
IK分词器 提供了两种分词算法:
ik_smart :最少切分
iik_max_word :最细粒度划分
测试:
http://127.0.0.1:9200/_analyze?analyzer=ik_smart&pretty=true&text=我喜欢快乐
http://127.0.0.1:9200/_analyze?analyzer=ik_max_word&pretty=true&text=我喜欢快乐
然后就是自定义词库,会把一些没有收纳为词条的字段自定义为词条
自定义以 .dic为尾缀的文件 比如: custom.dic
在其内部第一行空格 下一行键入你要的词条: 比如 人艰不拆(注意保存格式诶utf-8)
人艰不拆这个词本来不是词语,现在我们将其作为自定义词条加入分词器
再次测试:

接下来就是 java 代码的运用了,在与数据库的交互中,我们都要创建一个实体类作为结果反射的容器,
在ES中也是一样的,也需要创建一个实体类,用作装载查询到的数据

在ES中有三个概念比较重要,可以理解一下:
是否索引:就是看该字段是否能被作为检索字段被搜索
是否分词 : 搜索的时候是整体匹配,还是分词词条匹配
是否存储:就是在查询结果上,设置是否显示出来
其次就是配置整合需要的 ES 的ip 及 port (java的端口是 : 9300)

然后就是持久层对 ES 的访问了,我们只需要定义接口继承 ElasticsearchRepository<T, ID>
是不是很这种玩法很熟悉,再给你一个列子看
换汤不换药,还是原来的味道,还是原来的配方。然后就可以愉快的搬砖了......
接下来的笔记为 ES 和 MySQL 的数据同步: LogStash
网上对LogStash的介绍为 : Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。
在 ES 上的运用表现为: 定时将 MySQL中的数据 刷新到 ES ,完成数据更新同步
开箱即用,bin目录中调用 cmd : logstash -e 'input { stdin { } } output { stdout {} }' (测试语法)
-e :是执行,当命令很短时,可以运用这个语法,一般我们都是运行文件
-f : 跟路径,读取配置文件执行命令,一般用这种
开箱使用:
在解压文件夹内创建一个文件夹(随意,读取里面的配置文件)
在该文件夹内创建一个以 .conf 为尾缀的配置文件
文件内容如下: (酌情改动,以自己的配置为主)
input {
jdbc {
# mysql jdbc connection string to our backup databse
jdbc_connection_string => "jdbc:mysql://192.168.41.130:3306/article?characterEncoding=UTF8"
# the user we wish to excute our statement as
jdbc_user => "root"
jdbc_password => "123456"
# the path to our downloaded jdbc driver
jdbc_driver_library => "C:\MyFrame\logstash-5.6.8\mysqletc\mysql-connector-java-5.1.46.jar"
# the name of the driver class for mysql
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
#以下对应着要执行的sql的绝对路径。
#statement_filepath => ""
statement => "select id,title,content from tb_article"
#定时字段 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新(测试结果,不同的话请留言指出)
schedule => "* * * * *"
}
}
output {
elasticsearch {
#ESIP地址与端口
hosts => "127.0.0.1:9200"
#ES索引名称(自己定义的)
index => "article_es"
#自增ID编号
document_id => "%{id}"
document_type => "article"
}
stdout {
#以JSON格式输出
codec => json_lines
}
}
然后在 bin 中执行 : logstash -f ../mysqletc/mysql.conf
然后就可以看到控制台在为我们刷数据到 ES中的,一分钟后刷新 Head


已经实现数据的同步,接下里我们启动代码看看
elasticSearch新认知的更多相关文章
- Elasticsearch 新机型发布,性能提升30%
跨年迎双节,2020 年最后一次囤货的机会来啦! Elasticsearch Service 星星海新机型发布,更高性能,更低价格. 爆款机型限时特惠,帮助您顺畅体验 Elasticsearch 云上 ...
- es6 解构赋值 新认知/新习惯
es6 的解构赋值其实很早就学习了,但一直纠结于习惯和可读性问题,所以没有大规模使用.最近被 react调教一番之后.已经完全融入认知和习惯中去了.总结一下三个常用的技巧: 对象取值 取值并重命名 剩 ...
- elasticsearch新加入节点不能识别问题
向ES集群中新加入节点,配置文件也没有什么问题,但是就是加不进去,这时候就需要检查一下防火墙是否开启.关闭即可
- 有关Asp.net 中数据请求的处理的新认知:利用httpHandlers
转自csdn:HttpHandler HttpHandler是HTTP请求的处理中心,真正地对客户端请求的服务器页面做出编译和执行,并将处理过后的信息附加在HTTP请求信息流中再次返回到Http ...
- Echarts 新认知 地图的label到底怎么居中?
试过了offset和很多Api,都无法实现label居中 后来无意中发现,原来在geojson注册的时候,可以定义 properties.cp 属性,实现文本的坐标自定义,实现居中. echarts. ...
- 温故而知新: 关于 js Form 方式提交的一些新认知
这里介绍的是通过js进行异步form提交,而不是表单Form Submit提交. 提交方式主要有以下两种: 参数为字符串方式的提交,如:a=b&c=d formData方式提交, 如:new ...
- PHP error_log 新认知
//error_log 简介及使用方法 // error_log("消息","类型","路径"); //message //type ...
- 新认知之WinForm窗体程序
Windows应用程序和控制台应用程序有很大的区别 >Form1.cs :窗体文件,程序员对窗体编写的代码一般都存放在这个文件中. >Form1.Designer.cs :窗体设计文件, ...
- 工控PLC中,关于定时器TON,TOF,的一点新认知,或者说醒悟吧!
PLC 中的定时器,都是放在一个具体PRG任务单元中的,而PRG单元需要放在具体固定的周期循环任务中才能被执行,而这个周期循环任务的循环周期 T: 与定时器的定时时间T0: T与T0 的数量级 ...
随机推荐
- CVTE C/C++开发工程师笔试题(二)
问题描述:打印重复元素 给定一个数组,内容可能包含1到N的整数,N最大为40000,数组可能含有重复的值,且N的取值不定.若只剩余5KB内存可用,请设计函数尽可能快的答应数组中所有重复的元素. voi ...
- Win10下windows mobile设备中心连接不上的方法无法启动
微软Win10自动更细补丁后windows mobile设备中心就无法启动了 需要重新启动相关的服务并授予 本机登录用户 权限 1.点击屏幕左下角“开始”图标,点击“运行”,在弹出的输入框中输入“se ...
- github 生成配置ssh 秘钥方法详解
如果安装github成功后,当从本地提交文件到github的时候,提交不成功,报错,可能问题就是你还没有生成ssh秘钥 1.当你提交文件到github,不成功,出现如下的情况,就代表着github上面 ...
- python psycopg2 连接pg 建立连接池
# -*- coding: utf-8 -*-from psycopg2.pool import ThreadedConnectionPool,SimpleConnectionPool,Persist ...
- python写注册
# coding = UTF-8 注释格式 import datetime 引用日期 today = datetime.datetime.today().strftime("%Y-%m-%d ...
- GUI学习之五——QAbstractButton类学习笔记
今天总结一下AbstractButton类的学习笔记. 一.描述 AbstractButton是对各种按键的抽象类他的继承关系是这样的 首先,QAbstractButton继承了QWidget类的各种 ...
- identityserver4 代码系列
链接:https://pan.baidu.com/s/1ePLwUxGpIPObwA8nnfDT9w 提取码:gr0x
- Jenkins构建maven项目跳过测试用例的命令
在Jenkins构建项目的时候,有时候执行大量的单元测试用例需要浪费很多时间,又或者测试环境与其他dubbo,zookeeper服务器环境不通执行失败, 为了更快速的构建,可在build选项中使用如下 ...
- 循环调用dll库的界面时,首次正常,再次无响应
消息循环错误: 在为使用CPaintManagerUI::MessageLoop()的情况下退出,但却发送了PostQuitMessage(0).
- Codeforces Round #532 (Div. 2) F 线性基(新坑) + 贪心 + 离线处理
https://codeforces.com/contest/1100/problem/F 题意 一个有n个数组c[],q次询问,每次询问一个区间的子集最大异或和 题解 单问区间子集最大异或和,线性基 ...