node.js爬取数据并定时发送HTML邮件
node.js是前端程序员不可不学的一个框架,我们可以通过它来爬取数据、发送邮件、存取数据等等。下面我们通过koa2框架简单的只有一个小爬虫并使用定时任务来发送小邮件!
首先我们先来看一下效果图


差不多就是这样,其实之前已经有人做了类似的东西,我也只是想自己操作一遍,练习一下koa2框架,async+await,以及爬虫、定时器和发送邮件。下面我将带着各位刚刚学习node的小童鞋进入这个世界。
1.我们先来看一看这个项目用到的框架和依赖
- koa2框架--基于Node.js平台的下一代web开发框架,也就是我们的开发载体
- ejs--嵌入式JavaScript模板引擎
- superagent--客户端请求代理模块
- cheerio--抓取网页数据模块
- node-schedule--任务调度器模块(定时器)
- nodemailer--邮件发送模块
差不多就是这些模块,首先来初始化koa2项目,并进入目录
npm install -g koa-generator
koa2 test_koa
cd test_koa
然后安装各种依赖
npm install ejs superagent cheerio node-schedule nodemailer --save
2.编辑ejs模板
因为我们要展示最近三天的编号、天气、温度、污染程度、以及one网站的图片、图片来源和鸡汤。所以按照我们想要表现的数据编写ejs模板。这里我们留下待使用的数据接口,想要详细学习请点击ejs官方网站。
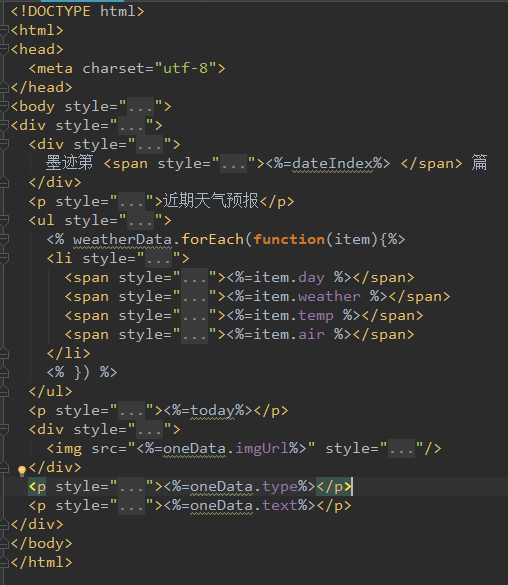
3.接下来我们编写util工具方法集
首先引入方法需要的依赖
const cheerio = require('cheerio');
const superagent = require('superagent');
const nodemailer = require('nodemailer');
具体是做什么的上面已经提及
1.首先编写爬虫爬取one网站的页面,然后获取第一张图片也就是今天的图片。
module.exports.getOneData = async (url) => {
return new Promise( resolve => {
superagent.get(url).end((err,res)=>{
if(err){
return err
}
let $ = cheerio.load(res.text);
let selectItem = $('#carousel-one .carousel-inner .item');
let todayOne = selectItem[0];
let todayOneData = {
imgUrl: $(todayOne).find('.fp-one-imagen').attr('src'),
type: $(todayOne).find('.fp-one-imagen-footer').text().replace(/(^\s*)|(\s*$)/g,""),
text: $(todayOne).find('.fp-one-cita').text().replace(/(^\s*)|(\s*$)/g,""),
}
resolve(todayOneData)
})
})
}
因为superagent.get(url).end方法是一个异步的方法,所以我们使用async方法返回一个Promise对象,superagent.get(url)中的url为客户端请求代理模块路径。end方法中有两个参数,第一返回错误,第二个是获取的网页结果对象,res.text就是网页源码。接下来使用cheerio模块转化整个网页源代码成jquery模式。
let $ = cheerio.load(res.text);
之后分别获取图片路径、图片来源和鸡汤文
imgUrl: $(todayOne).find('.fp-one-imagen').attr('src'),
type: $(todayOne).find('.fp-one-imagen-footer').text().replace(/(^\s*)|(\s*$)/g,""),
text: $(todayOne).find('.fp-one-cita').text().replace(/(^\s*)|(\s*$)/g,""),
并封装成对象,.replace(/(^\s*)|(\s*$)/g,"")是清除文本的前后导空格。
2.然后爬取天气预报网站的页面。
这个原理和上面的一样就不多做解释,直接贴代码
module.exports.getWeatherData = async (url) => {
return new Promise( resolve => {
superagent.get(url).end((err,res)=>{
if(err){
return err
}
let $ = cheerio.load(res.text);
let arr = [];
$('.table_day7').each((index,item)=>{
if (index < 3) {
arr.push({
day: $(item).find('dd:nth-of-type(1)').text(),
air: $(item).find('dd:nth-of-type(2) b').text(),
icon: "http:"+$(item).find('dd:nth-of-type(3) img').attr("src"),
weather: $(item).find('dd:nth-of-type(4)').text(),
temp: $(item).find('dd:nth-of-type(5)').text().replace(/℃/g,"°"),
})
}
})
resolve(arr)
})
})
}
3.接下来我们编写方法,发送email的天数
module.exports.getDateIndex = () => Math.ceil((new Date().getTime() - 1553085879604) / ( 24 * 60 * 60 *1000 ));
先生成一个当天的时间戳,我这里是1553085879604,然后通过这个时间戳计算是第几天发送信息,这个很简单。
4.当天的日期
这个也不用说,直接贴代码
module.exports.getToday = () => new Date().getFullYear() + " / " + new Date().getMonth() + " / " + new Date().getDate();
5.我们使用nodemailer模块发送
module.exports.sendEmail = (html) => {
nodemailer.createTestAccount(() => {
let transporter = nodemailer.createTransport({
service: 'qq',
port: 568,
secure: false,
auth: {
user: '1149967915@qq.com',
pass: '这里填写你自己的SMTP授权码'
}
});
let mailOptions = {
from: '"郭志强" <1149967915@qq.com>',
to: '15045160109@163.com',
subject: '一碗鸡汤趁热喝!',
html: html
};
transporter.sendMail(mailOptions, (error, info) => {
if (error) {
return console.log(error);
}
console.log('发送成功----', info.accepted[0], new Date());
});
});
}
这里需要注意的是auth的pass不是密码,而是SMTP授权码,想知道怎么得到SMTP授权码的点这里。上面这五个方法基本就够了。
4.在项目根目录下创建schedule.js并调用定时器方法
这里我们写一个定时器并且调用上面写的方法,首先引入依赖
const schedule = require('node-schedule');
const fs = require('fs');
const path = require('path');
const ejs = require('ejs');
接下来引入util工具库中的方法
const { getOneData, getWeatherData, getDateIndex, getToday, sendEmail } = require('./util/index');
在调用getOneData方法和getWeatherData方法时。
const oneUrl = "http://wufazhuce.com";
const weatherUrl = "http://www.tianqi.com/beijing/7/";
const oneData = await getOneData(oneUrl);
const weatherData= await getWeatherData(weatherUrl);
像上面这样写显然是不合理的,我们并不需要等待getOneData方法执行完才去执行getWeatherData。node社区从不会辜负我们,我们可以采取await Promise.all方法同时执行这两个异步方法。之后是获取ejs模板,并通过接口渲染数据。
const template = ejs.compile(fs.readFileSync(path.resolve(__dirname, 'views/index.ejs'), 'utf8'));
最后调用sendEmail方法发送邮件。
sendEmail(html)
schedule定时任务模块就不多讲,详情请看点击这里,下面贴上schedule.js所有代码
const schedule = require('node-schedule');
const fs = require('fs');
const path = require('path');
const ejs = require('ejs');
const { getOneData, getWeatherData, getDateIndex, getToday, sendEmail } = require('./util/index');
module.exports = function () {
//定时任务
schedule.scheduleJob('0 0 7 * * *', async () => {
const oneUrl = "http://wufazhuce.com";
const weatherUrl = "http://www.tianqi.com/beijing/7/";
const [oneData, weatherData] = await Promise.all([getOneData(oneUrl), getWeatherData(weatherUrl)]);
const dateIndex = getDateIndex();
const today = getToday();
const template = ejs.compile(fs.readFileSync(path.resolve(__dirname, 'views/index.ejs'), 'utf8'));
let ejsModelObject = {
oneData: oneData,
weatherData: weatherData,
dateIndex: dateIndex,
today: today,
}
const html = template(ejsModelObject);
sendEmail(html)
});
}
到这里就可以收工了,你也可以给心爱人送上暖心的邮件,这就自由发挥了。感谢大家支持,喜欢就收藏吧。博客园同步更新。
原创博客:转载请注明node.js爬取数据并定时发送HTML邮件
node.js爬取数据并定时发送HTML邮件的更多相关文章
- Node.js爬取豆瓣数据
一直自以为自己vue还可以,一直自以为webpack还可以,今天在慕课逛node的时候,才发现,自己还差的很远.众所周知,vue-cli基于webpack,而webpack基于node,对node不了 ...
- node.js爬取ajax接口数据
爬取页面数据与爬取接口数据,我还是觉得爬取接口数据更加简单一点,主要爬取一些分页的数据. 爬取步骤: 1.明确目标接口地址,举个例子 : https://www.vcg.com/api/common/ ...
- node.js抓取数据(fake小爬虫)
在node.js中,有了 cheerio 模块.request 模块,抓取特定URL页面的数据已经非常方便. 一个简单的就如下 var request = require('request'); va ...
- 关于js渲染网页时爬取数据的思路和全过程(附源码)
于js渲染网页时爬取数据的思路 首先可以先去用requests库访问url来测试一下能不能拿到数据,如果能拿到那么就是一个普通的网页,如果出现403类的错误代码可以在requests.get()方法里 ...
- Node.js 抓取电影天堂新上电影节目单及ftp链接
代码地址如下:http://www.demodashi.com/demo/12368.html 1 概述 本实例主要使用Node.js去抓取电影的节目单,方便大家使用下载. 2 node packag ...
- 借助Chrome和插件爬取数据
工具 Chrome浏览器 TamperMonkey ReRes Chrome浏览器 chrome浏览器是目前最受欢迎的浏览器,没有之一,它兼容大部分的w3c标准和ecma标准,对于前端工程师在开发过程 ...
- 【个人】爬虫实践,利用xpath方式爬取数据之爬取虾米音乐排行榜
实验网站:虾米音乐排行榜 网站地址:http://www.xiami.com/chart 难度系数:★☆☆☆☆ 依赖库:request.lxml的etree (安装lxml:pip install ...
- Node.js 本地Xhr取得Node.js服务端数据的例子
本以为用XHR取Nodejs http出的一段文字很简单,因为xhr取值和nodejs http出文字都是好弄的,谁知一试不是这回事,中间有个关键步骤需要实现. nodejs http出文字显示在浏览 ...
- Node.js 返回 JSON 数据
Node.js 返回 JSON 数据 request.end([data[, encoding]][, callback]) var http = require('http'); const log ...
随机推荐
- Confluence 6 手动运行和修改
手动运行一个任务 希望手动运行一个计划任务,进入计划任务的列表中,找到你希望手动运行的计划任务,在这个计划任务的边上选择 运行(Run).这个计划任务将会马上执行. 不是所有的计划任务都可以手动运行的 ...
- Confluence 6 MySQL 创建数据库和数据库用户
一旦你成功的安装和配置了 MySQL 数据库服务器,你需要为你的 Confluence 创建数据库和数据库用户: 在 MySQL 中以超级用户运行 'mysql' .默认的用户为 'root' 同时密 ...
- 性能测试四十六:Linux 从网卡模拟延时和丢包的实现
Linux 中模拟延时和丢包的实现 使用ifconfig命令查看网卡 Linux 中使用 tc 进行流量管理.具体命令的使用参考 tc 的 man 手册,这里简单记录一下使用 tc 模拟延时和丢包的命 ...
- Spring Boot的Listener机制的用法和实现原理详解
之前在介绍了在spring-boot启动过程中调用runner的原理,今天我们介绍另外一种可以实现相似功能的机制:spring-boot的Listener机制. 通过注册Listener,可以实现对于 ...
- Plain Old Data (POD) (转)
定义 POD类型包括下述C++类型,以及其cv-qualified的类型,还有以其为基类型的数组类型: 标量类型(scalar type) POD类类型(POD class type) 标量类型 术语 ...
- loss函数学习笔记
一直对机器学习里的loss函数不太懂,这里做点笔记. 符号表示的含义,主要根据Andrew Ng的课程来的,\(m\)个样本,第\(i\)个样本为\(\vec x^{(i)}\),对应ground t ...
- SSD垃圾回收
A complete GC typically:includes four steps: selecting some blocks that contain somestale data as vi ...
- 微信小程序API 登录-wx.login(OBJECT) + 获取微信用户唯一标识openid | 小程序
wx.login(OBJECT) 调用接口获取登录凭证(code)进而换取用户登录态信息,包括用户的唯一标识(openid) 及本次登录的 会话密钥(session_key).用户数据的加解密通讯需要 ...
- 解决h5网页微信分享链接不能显示缩略
<script type="text/javascript" src="http://res.wx.qq.com/open/js/jweixin-1.2.0.js& ...
- 基于nopcommerce b2c开源项目的精简版开发框架Nop.Framework
http://www.17ky.net/soft/70612.html?v=1#0-sqq-1-39009-9737f6f9e09dfaf5d3fd14d775bfee85 项目详细介绍 该开源项目是 ...