Java 集合的简单理解
集合(容器)
Java的集合类分别是Collection接口和Map接口派生而来。
Collection接口

对于实现Collection接口的子类,都会实现Collection接口中抽象方法,所以他们子类都包含一部分相同的方法(从Collection中继承过来的)。
下面是Collection接口中的方法列表:

简单的泛型
这里只是简单提一下泛型,不做深入讲解。
泛型可以理解为:指定容器存放的元素的类型,比如Collection<T>,则容器中的元素就应该是T类型。
List
List是有序、可重复的容器。
有序,表示精确地可以使用索引(下标)来访问容器中元素,使用get(int index)。
可重复,表示允许e1.equals(e2)的元素重复加入容器。
有三个实现类:ArrayList、LinkedList、Vector。
ArrayList
底层使用数组实现,特点:查询效率高,增删效率低,线程不安全。
增加元素的原理:ArrayList的size可以不断扩充,在放入新元素之前,会先检测如果放入当前元素,容器的size是否会超过容器的初始容量,如果超过了容器的初始容量,就创建一个更大的新数组,然后将原容器中的元素拷贝到新的数组中,然后改变引用。
删除元素的原理:假设删除第i个元素,则会将发生复制操作,从i+1开始的元素,拷贝到第i个位置,相当于所有元素都向前移动一个位置。
LinkedList
底层使用双向链表实现,特点:查询效率低,增删效率高,线程不安全。
Vector
底层使用数组来实现,但是相关的方法都加了同步检查(synchronized),所以线程安全,但效率低。
Vector几乎和ArrayList几乎相同,只是在某些方法前面加了synchronized关键字。
Map接口
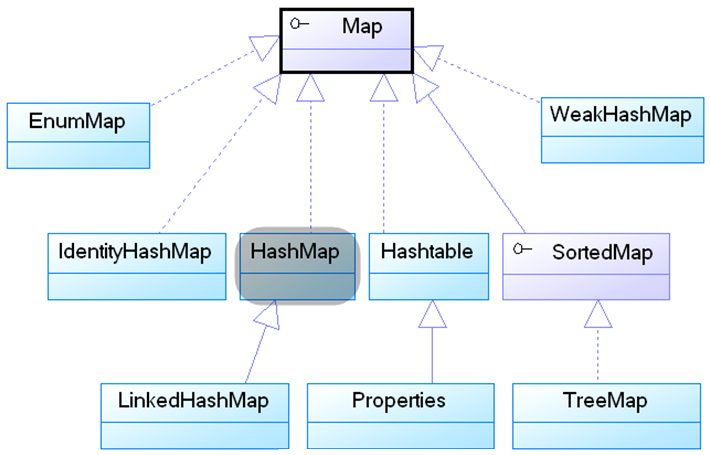
Map使用key-value格式来存储对象,Map中通过key来标识value,所以key不能重复,但是value可以重复;如果key重复了,那么后面的value就会覆盖前面的value。
Map接口中声明的方法列表如下:

HashMap
底层采用了哈希表(取模 + 拉链法),计算key的hashCode,根据散列算法计算后,得出hash值,根据这个值去数组对影位置存取元素。
在新增(put)元素的时候,将新增元素存入数组hash值所对应的位置。数组每个元素会存放(hashCode、key、value、next),如果数组中对应的位置已经有元素存在了,则将新增的元素挂在已有元素的后面(挂在原有元素的next上)。Java 8做了修改,如果拉链的链表长度大于8的时候,会采用红黑树来存储。
在获取(get)元素的时候,首先根据hash值,根据hash值去数组中对应位置,然后和链表的每一个key值相比较(调用key的equals()方法),返回相等的那个元素。
TreeMap
底层使用红黑树实现。
会将key递增进行排序之后存储。注意,如果要自定义key的排序,需要实现Comparable接口,并且重写compareTo()方法
import java.util.Map;
import java.util.TreeMap; public class TestCollection {
public static void main(String[] args) {
Map<Student, String> m = new TreeMap<>();
m.put(new Student(1001, "张三", 99), "学习委员");
m.put(new Student(1002, "李四", 60), "体育委员");
m.put(new Student(1003, "王五", 100), "班长");
m.put(new Student(1000, "赵六", 99), "学习委员"); for (Student key : m.keySet()) {
System.out.println(key + " position: " + m.get(key));
}
// id: 1002, name: 李四, score: 60 position: 体育委员
// id: 1000, name: 赵六, score: 99 position: 学习委员
// id: 1001, name: 张三, score: 99 position: 学习委员
// id: 1003, name: 王五, score: 100 position: 班长
}
} class Student implements Comparable<Student>{
private int id;
private String name;
private int score; public Student(int id, String name, int score) {
this.id = id;
this.name = name;
this.score = score;
} public String toString() {
return "id: " + this.id + ", name: " +this.name + ", score: " + this.score;
} @Override
public int compareTo(Student o) {
// 首先按照score升序排序,score相同,则按照id升序排序。
if (this.score < o.score) {
return -1;
} else if (this.score > o.score) {
return 1;
} else {
if (this.id > o.id) {
return 1;
} else if (this.id < o.id) {
return -1;
} else {
return 0;
}
}
}
}
Set
Set接口是实现了Collection接口的接口,所以Collection中的方法,Set接口的实现类都可以调用。
Set是无序,不可重复的容器。底层使用Map来实现。
无序,是指元素没有索引,如果要查找一个元素,就需要遍历容器。
不可重复,是指调用元素的equals()方法,如果比较结果为true,则不能重复加入。
Set接口的实现类有HastSet和TreeSet。
HashSet
HashSet的底层使用HashMap来实现,存入HashSet的元素会被作为底层HashMap的key,底层HashMap的key对应的value为一个Object对象。
TreeSet
TreeSet的底层使用TreeMap来实现。
使用迭代器来遍历容器
迭代器主要是Iterator接口。
遍历Collection(List、Set)
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List; public class Demo {
public static void main(String[] args) {
traverseCollection();
} // 遍历Collection接口的实现类对象的元素
public static void traverseCollection() {
List<String> list = new ArrayList<>();
list.add("aaaaa");
list.add("zzzzz");
list.add("yyyyy");
System.out.println(list); // [aaaaa, zzzzz, yyyyy] Iterator<String> iter = list.iterator();
while (iter.hasNext()) {
String s = iter.next();
System.out.println(s);
}
//aaaaa
//zzzzz
//yyyyy
}
}
遍历Map
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set; public class Demo {
public static void main(String[] args) {
traverseMap();
} // 遍历Map接口的实现类对象的元素
public static void traverseMap() {
Map<String, String> m = new HashMap<>();
m.put("one", "11111111");
m.put("two", "22222222");
m.put("three", "3333333"); System.out.println(m);
//{one=11111111, two=22222222, three=3333333} //Set<K> keySet();功能是返回一个包含所有Key的Set
//System.out.println(m.keySet());
//[one, two, three] //Set<Map.Entry<K, V>> entrySet()功能是返回一个包含所有K=V的Set
//System.out.println(m.entrySet());
//[one=11111111, two=22222222, three=3333333] // 遍历Map的第一种方式
Set<Entry<String, String>> ss = m.entrySet();
Iterator<Entry<String, String>> iter = ss.iterator();
while (iter.hasNext()) {
Entry<String, String> item = iter.next();
System.out.println(item.getKey() + " = " + item.getValue());
}
//one = 11111111
//two = 22222222
//three = 3333333 // 遍历Map的第二种方式-> 转化为遍历List
Set<String> s = m.keySet();
Iterator<String> iter2 = s.iterator();
while (iter2.hasNext()) {
String key = iter2.next();
System.out.println(key + " = " + m.get(key));
}
//one = 11111111
//two = 22222222
//three = 3333333
}
}
使用for循环遍历List
for (int i = 0; i < list.size(); i++) {
String s = (String)list.get(i);
System.out.println(s);
}
for (String s : list) {
System.out.println(s);
}
使用for循环来遍历List的时候,比较方便,一般只是用来查看List,不对其进行操作的情况。
使用Collections工具类
使用java.util.Collections工具类,可以对实现了Collection接口的子类对象进行操作,包括List、Set,但是不能操作Map。
import java.util.ArrayList;
import java.util.List;
import java.util.Collections; public class Demo {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("xxxx");
list.add("zzzz");
list.add("yyyy");
System.out.println(list); //[xxxx, zzzz, yyyy] Collections.shuffle(list);//打乱顺序
System.out.println(list); //[zzzz, yyyy, xxxx] Collections.reverse(list);//翻转
System.out.println(list); //[xxxx, zzzz, yyyy] Collections.sort(list); //递增排序,自定义类需要实现Comparable接口
System.out.println(list); //[xxxx, yyyy, zzzz] System.out.println(Collections.binarySearch(list, "yyyy")); //1
System.out.println(Collections.binarySearch(list, "wwww")); //-1
}
}
利用List和Map保存一张二维表
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Set; public class Demo {
public static void main(String[] args) {
Map<String, Object> m1 = new HashMap<>();
m1.put("id", 1001);
m1.put("name", "aaaaaa");
m1.put("salary", 10000); Map<String, Object> m2 = new HashMap<>();
m2.put("id", 1002);
m2.put("name", "cccccc");
m2.put("salary", 199999); Map<String, Object> m3 = new HashMap<>();
m3.put("id", 1003);
m3.put("name", "bbbbb");
m3.put("salary", 20000); List<Map<String, Object>> list = new ArrayList<>();
list.add(m1);
list.add(m2);
list.add(m3); for (Map<String, Object> m : list) {
Set<String> keys = m.keySet();
for (String key : keys) {
System.out.print(key + ": " + m.get(key) + "\t");
}
System.out.println();
}
}
} 输出:
name: aaaaaa id: 1001 salary: 10000
name: cccccc id: 1002 salary: 199999
name: bbbbb id: 1003 salary: 20000
Java 集合的简单理解的更多相关文章
- Laravel集合的简单理解
本篇文章给大家带来的内容是关于Laravel集合的简单理解,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助. 前言 集合通过 Illuminate\Database\Eloquent\C ...
- java集合的简单用法
typora-root-url: iamge [TOC] 1.集合接口 1.1将集合的接口与实现分离 与现代的数据结构类库的常见情况一样,Java集合类库也将接口(interface)与实现(im ...
- Java 层级的简单理解
在J2EE项目中,开发的都是分层来做的: 1.service层:用于暴露给网络调用 2.Impl层:统一规范接口 3.bean层:实体对象,也就是表 4.DAO(Data Access Object) ...
- Java集合(5):理解Collection
Collection是List.Set.Queue的共同接口.Collection主要方法有: int size():返回当前集合中元素的数量 boolean add(E e):添加对象到集合 boo ...
- java双指针的简单理解
一.什么是双指针 双指针我所理解地是在遍历对象时,不是使用单个指针进行访问,而是使用两个相同方向或者相反方向的指针进行遍历,从而达到相应的目的. 在JAVA中并没有像C/C++指针地概念,所以这里所说 ...
- Java 集合的简单实现 (ArrayList & LinkedList & Queue & Stack)
ArrayList 就是数组实现的啦,没什么好说的,如果数组不够了就扩容到原来的1.5倍 实现了迭代器 package com.wenr.collection; import java.io.Seri ...
- Java接口的简单理解和总结
1.抽象层次:普通类 -> 抽象类 -> 接口 普通类:就是我们常用的类: 抽象类:专门用来被子类继承的,主要是为了符合现实世界的规律 如: Animal类:(每个现实的对象都有类与它相对 ...
- java 的 IO简单理解
首先要先理解什么是 stream ? stream代表的是任何有能力产出数据的数据源,或是任何有能力接收数据的接收源. 一.不同导向的 stream 1)以字节为单位从 stream 中读取或往 st ...
- Java虚拟机JVM简单理解
Java虚拟机JVM的作用: Java源文件(.java)通过编译器编译成.class文件,.class文件通过JVM中的解释器解释成特定机器上的机器代码,从而实现Java语言的跨平台. JVM的体系 ...
随机推荐
- JAVA API的下载和中文查看API
一.JAVA API的下载 1.1 JAVA由SUN公司开发,2006年SUN公司宣布将Java技术作为免费软件对外发布,标志着JAVA的公开免费.2009年,SUN公司被甲骨文公司收购,因此我们现在 ...
- 17.基于scrapy-redis两种形式的分布式爬虫
redis分布式部署 1.scrapy框架是否可以自己实现分布式? - 不可以.原因有二. 其一:因为多台机器上部署的scrapy会各自拥有各自的调度器,这样就使得多台机器无法分配start_urls ...
- Scrapy 框架 增量式
增量式: 用来检测网站中数据的更新情况 from scrapy.linkextractors import LinkExtractor from scrapy.spiders import Crawl ...
- bs4 解析 以及用法
bs4解析 bs4: 环境安装: lxml bs4 bs4编码流程: 1.实例化一个bs4对象,且将页面源码数据加载到该对象中 2.bs相关的方法或者属性实现标签定位 3.取文本或者取属性 bs的属性 ...
- mac下安装redis详细步骤
Linux下安装redis也可以参照下面的步骤哦!!!! 1.到官网上下载redis,我下载的版本是redis-3.2.5.tar 官网地址:http://redis.io/ 2.将下载下来的tar. ...
- 2.03-handler_openner
import urllib.request def handler_openner(): #系统的urlopen并没有添加代理的功能所以需要我们自定义这个功能 #安全 套接层 ssl第三方的CA数字证 ...
- 清除tomcat日志文件的shell脚本
#! /bin/bash d=`date +%F` exec >> /mydata/script/logs/$d>& echo "开始执行清除tomcat日志文件& ...
- 转://Oracle not in查不到应有的结果(NULL、IN、EXISTS详解)
问题: 语句1 : Select * from table1 A where A.col1 not in ( select col1 from table2 B ) ...
- 微信硬件平台(八) 3 ESP8266向微信服务器请求设备绑定的用户
https://api.weixin.qq.com/device/get_openid?access_token=自己申请微信token&device_type=gh_e93c1b3098b9 ...
- list.remove操作注意点
通过源码分析一下结果public class Test { public static void main(String[] args) { // test1(); // test2(); test3 ...