python爬虫——简易天气爬取
通过爬虫,抓取http://www.weather.com.cn的天气信息
功能——输入城市代码,获取当日天气,简单的beautifulsoup和requests实现。(城市代码可百度查询,不全部展示)
代码如下:
from bs4 import BeautifulSoupimport requests def get(city):
citycode = {
'北京': '',
'海淀': '',
'朝阳': '',
'顺义': '',
'怀柔': ''
}
try:
url = 'http://www.weather.com.cn/weather/'+str(citycode[city])+'.shtml'
res = requests.get(url)
print(res)
res.encoding='utf-8'
soup = BeautifulSoup(res.text,'lxml')
day = soup.select('li.on > h1')[0].string weather = soup.select('p.wea')[0].string tem = soup.select(' p.tem > i')[0].string wind= soup.select(' p.win > i')[0].string content = day+weather+tem+windexcept:
content = "error"
return content city = raw_input()
get(city)
效果图:
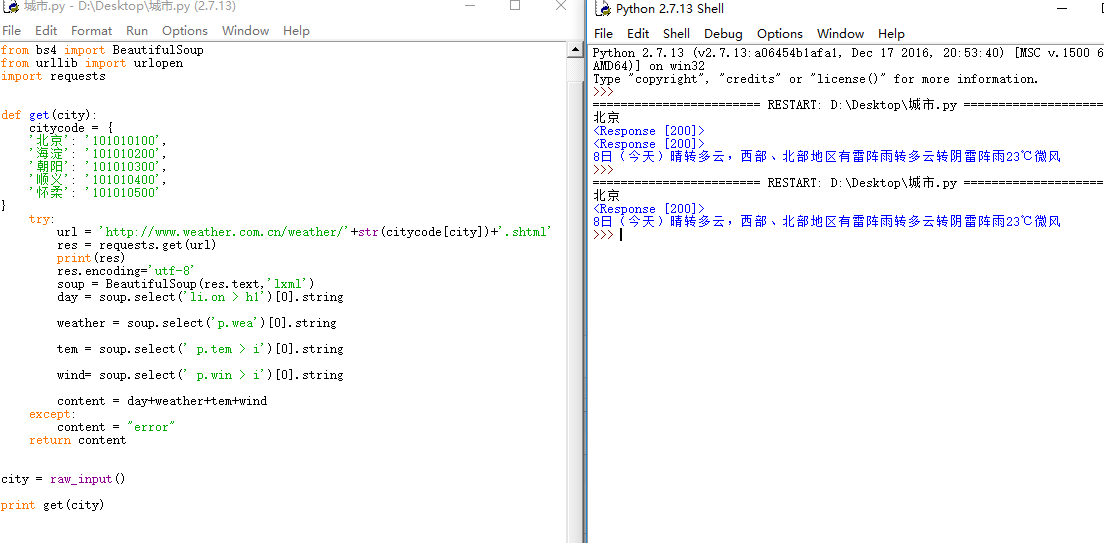
python爬虫——简易天气爬取的更多相关文章
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
随机推荐
- 09 Scrapy框架在爬虫中的使用
一.简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.它集成高性能异步下载,队列,分布式,解析,持久化等. Scrapy 是基于twisted框架开发而来,twisted是一个 ...
- Windows平台python验证码识别
参考: http://oatest.dragonbravo.com/Authenticate/SignIn?returnUrl=%2f http://drops.wooyun.org/tips/631 ...
- lightoj 1125 - Divisible Group Sums (dp)
Given a list of N numbers you will be allowed to choose any M of them. So you can choose in NCM ways ...
- 杭电多校第二场 hdu 6315 Naive Operations 线段树变形
Naive Operations Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 502768/502768 K (Java/Other ...
- WebGL2系列之采样器对象
前言 在WebGL1中,纹理的图片和采样信息都是写在纹理对象之中. 采样信息告诉GPU如何去读取贴图上图片的信息. 如果我们希望从同一个图片多次读取像素信息,但是每次读取的时候使用的过滤方式不一样, ...
- 一篇文章看懂JS执行上下文
壹 ❀ 引 我们都知道,JS代码的执行顺序总是与代码先后顺序有所差异,当先抛开异步问题你会发现就算是同步代码,它的执行也与你的预期不一致,比如: function f1() { console.lo ...
- python 整型、字符串常用方法、for循环
整型--int 定义:用于比较和计算 python2和python3: python2:python2中油int(整型)和long(长整型):1231312L+ 进制转换: 十进制转二进制:正除2,获 ...
- Netty源码分析 (六)----- 客户端连接接入accept过程
通读本文,你会了解到1.netty如何接受新的请求2.netty如何给新请求分配reactor线程3.netty如何给每个新连接增加ChannelHandler netty中的reactor线程 ne ...
- 手工释放服务器的swap分区缓存
时间 恢复时间 状态 信息 主机 问题 • 严重性 持续时间 确认 动作 2019-03-21 20:29:30 09:51:30 -ai-代理 Lack of free sw ...
- mariadb 远程访问报:Host xxx is not allowed to connect to this MariaDb server
刚开始试的是: 结果报错了,哎,这折腾的. 继续折腾,加个密码试试: 再用Navicat试试,果然成功了.