leveldb 源码--总体架构分析
一 本文目的
对leveldb的总体设计框架分析(关于leveldb基本原理,此文不做阐述,读者可以自行检索文章阅读即可),对leveldb中底层数据存储数据格式,内存数据模型,compact,版本管理,快照等机制实现介绍以及整个leveldb实现源码中各文件的源码实现职责,方便快速对leveldb有个总体的掌握
二 各特性机制的实现
1.leveldb的底层数据格式存储
leveldb底层数据格式,网上很多文章都有介绍,在此不做赘述,主要介绍一下上层怎么讲数据写入磁盘中。
leveldb中k-v数据写入磁盘就是通过数据压缩写入的( CompactMemTable[内存压缩至sst] & BackgroundCompaction[层间sst文件压缩] ),上层都是通过TableBuilder对象来实现数据持久化的
主要的两个接口:
# Add:将一行记录加入一块buffer中
#Finish:将k-v的记录,按照table的格式(生成filter,metaindex,index,footer 块),然后分配对各块写入到sst文件中
compact的使用大致过程:
1.压缩过程中使用迭代器模式,按序遍历输入需要压缩的sst文件中key-val键值对。
2. 丢弃key过期记录(比如:一个key的多次修改,只保留最新的一条记录,另外还有快照,这是后话),对没有过期的记录,将会调用TableBuilder.Add接口添加到TableBuilder的缓存区中,
3. 直到缓存区中数据大小达到阈值(用户指定)。将会调用TableBuilder.Finish 生成sst表格式数据并持久化。
2. 内存数据模型
内存模型是使用跳表的数据结构的方式来进行管理维护的。
# 跳表在leveldb中定义的是一个通用的数据结构,需要外部传入节点key的compare对象。
#MemTable 使用组合的方式使用跳表,自定义compare对象。
# 其中需要注意有意思的一点MemTable 存储到跳表结构中的节点是包含(key+val),跳表中key值得比较对象是通过外部定义传入的,MemTable使用的是下面的比较函数,从函数中可以看出需要对节点提取真正的userKey进行比较。
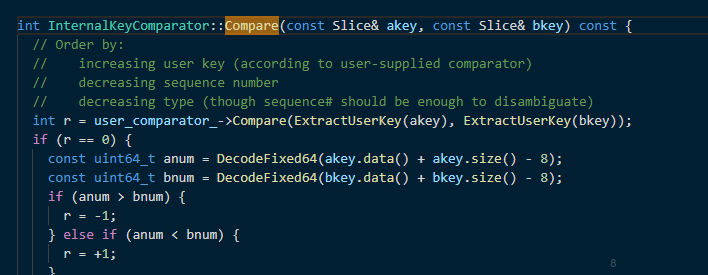
3 Compact过程:
compact主要分为一下几步
1.选择需要compact的level,通过VersionSet.PickCompaction函数来决定需要compact哪一层,改层哪些文件需要compact
#至于为什么由VersionSet来决定,是因为VersionSet管理当前整个leveldb的文件组织结构等信息,后面再版本管理中会进行详细说明
2.对需要compact的文件建立迭代器,迭代器按key的排序依次访问所有的记录
3.依次遍历所有的记录,判断需要丢弃记录,对需要保留的记录,会调用TableBuilder.Add接口加入sst缓存区中
记录丢弃的判断条件
#同一个key非第一次出现,并且记录对应的序列号小于最旧的快照的序列号(说明该记录不需要快照备份)
# 该key值插入一个删除操作,并且不需要快照备份
4.sst缓存区写满,就会生成一个完整的sst文件格式,然后持久化到磁盘上
5.将压缩过程中涉及到的文件变更(例如:老sst删除,新sst生成)加入到版本管理中的version_edit中
#注:此处不涉及老sst文件的清理,只是记录当前一次compact操作导致哪些文件需要被删除,真正删除操作由其他过程执行
6.删除过期文件
# 当前compact出来的新sst文件 & 所有版本version管理的sst文件,都会加入livefiles集合中
#不在livefiles集合中的文件全部认为是过期文件,需要删除。
4. 版本管理
版本管理是leveldb中极其重要的模块,要想理解整个leveldb必须理解其为什么需要 & 如何实现版本管理的
4.1 为什么需要版本管理
1.假设一种场景:一个用户发起对某个sst文件读取操作,数据读取到了一半,此时compact完成,由于compact是独立的一个线程,此时sst文件会被清理掉了,此时用户读操作出错
所以一句话就是:管理磁盘上的文件,保证leveldbdb数据的准确性
4.2 如何实现版本管理
基本概念:
version :一个version对应一次数据文件变更的记录,比如compact会导致文件发现变化(老的sst文件,新生成sst文件),所以需要记录当前compact过程结束后,在当前数据库状态下有哪些文件,
#主要数据结构:std::vector<FileMetaData*> files_[config::kNumLevels];记录管理每一层sst文件
versionSet:由于每一次compact后都会产生一个version,所以需要将这些version管理起来,采用双向链表version按先后生成的顺序管理起来
versionEdit:变化增量,每次compact时记录增量,主要是增加了哪些文件,需要删除哪些文件,通过上一次Version+versionEdit就会得到当前的Version
#主要数据结构:
#DeletedFileSet deleted_files_;
#std::vector<std::pair<int, FileMetaData>> new_files_;
# 管理数据结构:快照双向链表,将所有的快照使用双向链表维护管理起来
# 快照数据结构主要字段
SnapshotImpl* prev_; //链表相关
SnapshotImpl* next_; //链表相关
const SequenceNumber sequence_number_; //快照的sequence_number_
#实现的主要思想:
对于一个快照,获取快照的sequence_number_,读取key时,可以获取key的多次插入的值,其中获取seq不大于sequence_number_的最大的seq的val。
#如何保证快照的记录不被删除呢?
所有删除的过程只有compact时进行,compact逻辑中,遍历所有需要压缩的文件的key值,会判断该key能否丢弃
其中有一个条件是,如果当前key有快照引用,就不能compact掉,从而保证打了快照的数据不会被丢弃。
三 源码结构
主要通过源码的目录结构以及阐述关键目录和源文件的职责的方式来展示源码的整个架构。
cmake:cmake的相关文件
db:主要机制的实现,包括版本管理,compact,业务读写等功能机制实现;
doc:文档;
helpers/memenv:简单完全内存的文件系统,提供操作目录文件接口;
include/leveldb:头文件,外部工程使用leveldb时引用的头文件;
port:平台相关的实现,主要提供posix/android相关支持;
table:定义了整个leveldb的持久化存储的数据结构
util:通用功能实现。
主要介绍的是db & table,这两部分是整个leveldb的精髓
table:完成了整个leveldb持久化层的数据格式的定义以及实现
# block + block_builder :定义了block格式以及block如何生成的实现,包括block块中重启点等技术细节,将block的访问抽象成对迭代器模式的访问
# filter_block:定义了过滤器的实现
# two_level_iterator & iterator_wrapper & iterator & merger & two_level_iterator:定义了各种迭代器,从而屏蔽底层数据访问细节
#其中two_level_iterator:封装了索引迭代器和数据迭代器的操作,本质上是一个二重循环,来实现key的有序遍历
for(遍历索引){
for(遍历当前索引指向的block)
}
# table & table_build:定义了sst文件的数据格式以及如何生成sst的过程
db:实现了包括上面提到的各种机制,主要包括版本管理,compact,容灾恢复等具体的实现细节
#db_impl:定义个数据库的各种接口以及compact等数据库特性
#log_format & log_reader & log_writer:定义了log文件格式和读写,此处的log文件用来实现备份容灾的功能的
#memtable & skiplist:定义了leveldb如何使用跳表来实现数据在内存中的有序存储
#snapshot:负责管理快照,使用链表的方式对快照进行管理
#version_edit & version_set:负责版本管理的操作

leveldb 源码--总体架构分析的更多相关文章
- leveldb源码分析--SSTable之block
在SSTable中主要存储数据的地方是data block,block_builder就是这个专门进行block的组织的地方,我们来详细看看其中的内容,其主要有Add,Finish和CurrentSi ...
- leveldb源码分析--日志
我们知道在一个数据库系统中为了保证数据的可靠性,我们都会记录对系统的操作日志.日志的功能就是用来在系统down掉的时候对数据进行恢复,所以日志系统对一个要求可靠性的存储系统是极其重要的.接下来我们分析 ...
- leveldb源码分析--WriteBatch
从[leveldb源码分析--插入删除流程]和WriteBatch其名我们就很轻易的知道,这个是leveldb内部的一个批量写的结构,在leveldb为了提高插入和删除的效率,在其插入过程中都采用了批 ...
- leveldb源码分析--Key结构
[注]本文参考了sparkliang的专栏的Leveldb源码分析--3并进行了一定的重组和排版 经过上一篇文章的分析我们队leveldb的插入流程有了一定的认识,而该文设计最多的又是Batch的概念 ...
- Leveldb源码分析--1
coming from http://blog.csdn.net/sparkliang/article/details/8567602 [前言:看了一点oceanbase,没有意志力继续坚持下去了,暂 ...
- leveldb源码分析之Slice
转自:http://luodw.cc/2015/10/15/leveldb-02/ leveldb和redis这样的优秀开源框架都没有使用C++自带的字符串string,redis自己写了个sds,l ...
- qt creator源码全方面分析(3-5)
目录 qtcreatorlibrary.pri 使用实例 上半部 下半部 结果 qtcreatorlibrary.pri 上一章节,我们介绍了src.pro,这里乘此机会,把src目录下的所有项目文件 ...
- leveldb源码学习系列
楼主从2014年7月份开始学习<>,由于书籍比较抽象,为了加深思考,同时开始了Google leveldb的源码学习,主要是想学习leveldb的设计思想和Google的C++编程规范.目 ...
- LevelDB源码剖析
LevelDB的公共部件并不复杂,但为了更好的理解其各个核心模块的实现,此处挑几个关键的部件先行备忘. Arena(内存领地) Arena类用于内存管理,其存在的价值在于: 提高程序性能,减少Heap ...
随机推荐
- sql server创建序列sequence
1.创建一个序列对象 CREATE SEQUENCE [schema_name . ] sequence_name START WITH <constant> INCREMENT BY & ...
- 《GO Home Trash!》UML类图,ER图以及数据库设计
<Go Home Trash!>UML类图 ER图以及数据库中数据表 分析: 这款软件经过我们前期的讨论以及需求分析,确定了用户,客服以及管理员三个实体.在设计UML类图时,对各个实体之间 ...
- PHP学习—了解篇
了解PHP 了解神器:PhpStudy 一键搭建PHP环境 语法: PHP是一种可以嵌套在HTML页面的脚本语言 嵌套HTML文件: <!DOCTYPE html> <html& ...
- Immutable Object模式 - 多线程
Immutable Object模式 - 多线程 前言 在多线程编程中,我们常会碰到修改一个对象的值,如果在不加锁的情况下 ,就会出现值不一致的问题,那么有没有一种方式可以不通过加锁的方式也可以保证数 ...
- git 如何实现进行多人协作开发(远程仓库)
第一.Git作为分布式的版本控制系统,你是你本地仓库的主人,但是想要实现多人的协作开发,你就要将你本地的开发推送到远程共享仓库中供大家下载,本篇主要以github作为远程服务器来介绍有关远程仓库这块内 ...
- 选择排序&冒泡排序&折半查找
//选择排序 void test2(int a[],int len){ //每次找出一个最小值,最小值依次与原数组交换位置,通过下标来完成交换,最小值下标每次都在变,变量存储 // 假如第一个是 ...
- ccpc网赛 hdu6703 array(权值线段树
http://acm.hdu.edu.cn/showproblem.php?pid=6703 大意:给一个n个元素的数组,其中所有元素都是不重复的[1,n]. 两种操作: 将pos位置元素+1e7 查 ...
- CodeForces 293E Close Vertices 点分治
题目传送门 题意:现在有一棵树,每条边的长度都为1,然后有一个权值,求存在多少个(u,v)点对,他们的路劲长度 <= l, 总权重 <= w. 题解: 1.找到树的重心. 2.求出每个点到 ...
- CodeForces 804C Ice cream coloring
Ice cream coloring 题解: 这个题目中最关键的一句话是, 把任意一种类型的冰激凌所在的所有节点拿下来之后,这些节点是一个连通图(树). 所以就不会存在多个set+起来之后是一个新的完 ...
- HDU 1087 Super Jumping! Jumping! Jumping! 最长递增子序列(求可能的递增序列的和的最大值) *
Super Jumping! Jumping! Jumping! Time Limit:1000MS Memory Limit:32768KB 64bit IO Format:%I64 ...