基于开源中文分词工具pkuseg-python,我用张小龙的3万字演讲做了测试
做过搜索的同学都知道,分词的好坏直接决定了搜索的质量,在英文中分词比中文要简单,因为英文是一个个单词通过空格来划分每个词的,而中文都一个个句子,单独一个汉字没有任何意义,必须联系前后文字才能正确表达它的意思。
因此,中文分词技术一直是nlp领域中的一大挑战。Python 中有个比较著名的分词库是结巴分词,从易用性来说对用户是非常友好的,但是准确度不怎么好。这几天发现另外一个库,pkuseg-python,看起来应该是北大的某个学生团队弄出来的,因为这方面没看到过多的介绍,pkuseg-python 的亮点是领域细分的中文分词工具,简单易用,跟现有开源工具相比提高了分词的准确率。
于是我想起用张小龙的3万字演讲做下测试,前几天在朋友圈流传了一张图,采铜统计出张小龙演讲中各个词出现的频率,不知他是怎么统计的,不过作为技术人,我们用更专业的工具来试试会是什么效果。
安装 pkuseg
pip3 install pkuseg
第一步是将演讲内容下载下来,保存到一个txt文件中,然后将内容加载到内存
content = []
with open("yanjiang.txt", encoding="utf-8") as f:
content = f.read()
我统计了一下,文字总数是32546个。
接下来我们用pkuseg对内容进行分词处理,并统计出现频率最高的前20个词语是哪些。
import pkuseg
from collections import Counter
import pprint content = []
with open("yanjiang.txt", encoding="utf-8") as f:
content = f.read() seg = pkuseg.pkuseg()
text = seg.cut(content)
counter = Counter(text)
pprint.pprint(counter.most_common(20))
输出结果:
[(',', 1445),
('的', 1378),
('。', 755),
('是', 707),
('一', 706),
('个', 591),
('我', 337),
('我们', 335),
('不', 279),
('你', 231),
('在', 230),
('会', 220),
('了', 214),
('有', 197),
('人', 190),
('就', 178),
('这', 172),
('它', 170),
('微信', 163),
('做', 149)]
什么鬼,这都是些啥玩意,别急,其实啊,分词领域还有一个概念叫做停用词,所谓停用词就是在语境中没有具体含义的文字,例如这个、那个,你我他,的得地,以及标点符合等等。因为没人在搜索的时候去用这些没意义的停用词搜索,为了使得分词效果更好,我们就要把这些停用词过去掉,我们去网上找个停用词库。
第二版代码:
import pkuseg
from collections import Counter
import pprint content = []
with open("yanjiang.txt", encoding="utf-8") as f:
content = f.read() seg = pkuseg.pkuseg()
text = seg.cut(content) stopwords = [] with open("stopword.txt", encoding="utf-8") as f:
stopwords = f.read() new_text = [] for w in text:
if w not in stopwords:
new_text.append(w) counter = Counter(new_text)
pprint.pprint(counter.most_common(20))
打印的结果:
[('微信', 163),
('用户', 112),
('产品', 89),
('朋友', 81),
('工具', 56),
('程序', 55),
('社交', 55),
('圈', 47),
('视频', 40),
('希望', 39),
('时间', 39),
('游戏', 36),
('阅读', 33),
('内容', 32),
('平台', 31),
('文章', 30),
('信息', 29),
('团队', 27),
('AI', 27),
('APP', 26)]
看起来比第一次好多了,因为停用词都过滤掉了,跟采铜那张图片有点像了,不过他挑出来的词可能是从另外一个维度来的,毕竟人家是搞心理学的。但是我们选出来的前20个高频词还是不准确,有些不应该分词的也被拆分了,例如朋友圈,公众号,小程序等词,我们认为这是一个整体。
对于这些专有名词,我们只需要指定一个用户词典, 分词时用户词典中的词固定不分开,重新进行分词。
lexicon = ['小程序', '朋友圈', '公众号'] #
seg = pkuseg.pkuseg(user_dict=lexicon) # 加载模型,给定用户词典
text = seg.cut(content)
最后的出来的结果前50个高频词是这样的
163 微信
112 用户
89 产品
72 朋友圈
56 工具
55 社交
53 小程序
40 视频
39 希望
39 时间
36 游戏
33 阅读
32 内容
31 朋友
31 平台
30 文章
29 信息
27 团队
27 AI
26 APP
25 公众号
25 服务
24 好友
22 照片
21 时代
21 记录
20 手机
20 推荐
20 企业
19 原动力
18 功能
18 真实
18 生活
17 流量
16 电脑
15 空间
15 发现
15 创意
15 体现
15 公司
15 价值
14 版本
14 分享
14 未来
13 互联网
13 发布
13 能力
13 讨论
13 动态
12 设计
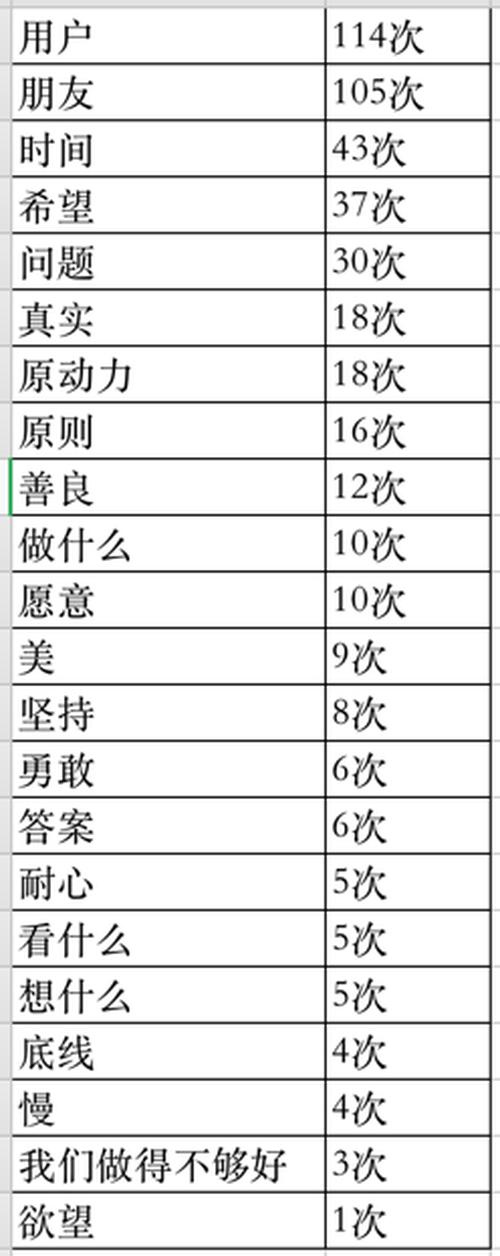
张小龙讲得最多的词就是用户、朋友、原动力、价值、分享、创意、发现等这些词,这些词正是互联网的精神,如果我们把这些做成词云的话,可能效果会更好

代码传送门:https://github.com/lzjun567/crawler_html2pdf/tree/master/fencitongji
基于开源中文分词工具pkuseg-python,我用张小龙的3万字演讲做了测试的更多相关文章
- 开源中文分词工具探析(三):Ansj
Ansj是由孙健(ansjsun)开源的一个中文分词器,为ICTLAS的Java版本,也采用了Bigram + HMM分词模型(可参考我之前写的文章):在Bigram分词的基础上,识别未登录词,以提高 ...
- 开源中文分词工具探析(四):THULAC
THULAC是一款相当不错的中文分词工具,准确率高.分词速度蛮快的:并且在工程上做了很多优化,比如:用DAT存储训练特征(压缩训练模型),加入了标点符号的特征(提高分词准确率)等. 1. 前言 THU ...
- 开源中文分词工具探析(五):FNLP
FNLP是由Fudan NLP实验室的邱锡鹏老师开源的一套Java写就的中文NLP工具包,提供诸如分词.词性标注.文本分类.依存句法分析等功能. [开源中文分词工具探析]系列: 中文分词工具探析(一) ...
- 开源中文分词工具探析(五):Stanford CoreNLP
CoreNLP是由斯坦福大学开源的一套Java NLP工具,提供诸如:词性标注(part-of-speech (POS) tagger).命名实体识别(named entity recognizer ...
- 开源中文分词工具探析(七):LTP
LTP是哈工大开源的一套中文语言处理系统,涵盖了基本功能:分词.词性标注.命名实体识别.依存句法分析.语义角色标注.语义依存分析等. [开源中文分词工具探析]系列: 开源中文分词工具探析(一):ICT ...
- 开源中文分词工具探析(六):Stanford CoreNLP
CoreNLP是由斯坦福大学开源的一套Java NLP工具,提供诸如:词性标注(part-of-speech (POS) tagger).命名实体识别(named entity recognizer ...
- 中文分词工具探析(二):Jieba
1. 前言 Jieba是由fxsjy大神开源的一款中文分词工具,一款属于工业界的分词工具--模型易用简单.代码清晰可读,推荐有志学习NLP或Python的读一下源码.与采用分词模型Bigram + H ...
- 中文分词工具探析(一):ICTCLAS (NLPIR)
1. 前言 ICTCLAS是张华平在2000年推出的中文分词系统,于2009年更名为NLPIR.ICTCLAS是中文分词界元老级工具了,作者开放出了free版本的源代码(1.0整理版本在此). 作者在 ...
- 中文分词工具简介与安装教程(jieba、nlpir、hanlp、pkuseg、foolnltk、snownlp、thulac)
2.1 jieba 2.1.1 jieba简介 Jieba中文含义结巴,jieba库是目前做的最好的python分词组件.首先它的安装十分便捷,只需要使用pip安装:其次,它不需要另外下载其它的数据包 ...
随机推荐
- JAVA AES文件加解密
AES加解密算法,代码如下: /** * Created by hua on 2017/6/30. */ import javax.crypto.Cipher; import javax.crypto ...
- UVA514 铁轨 Rails:题解
题目链接:https://www.luogu.org/problemnew/show/UVA514 分析: 入站序列是1-n,入站后判断如果等于出站序列的当前值,则直接出站.否则就在栈里待着不动.模拟 ...
- [leetcode] 21. Merge Two Sorted Lists (Easy)
合并链表 Runtime: 4 ms, faster than 100.00% of C++ online submissions for Merge Two Sorted Lists. class ...
- 小白学python-day05-作业(购物车程序)
购物车需求: 开始输入工资,然后出现购买商品的相关信息,输入编号进行购买 价格>工资提示余额不足,价格<工资提示 成功加入购物车,并且显示余额 然后将购买环节进行循环,直到用户退出购买 然 ...
- vue教程(四)--其他实用用法补充
一.vue生命周期简单介绍 var App={ template:'', data(){ }, beforeCreated:function(){ //不能操作数据,只是初始化了事件等.. }, cr ...
- springboot集成shiro集成mybatis-plus、redis、quartz定时任务
完整项目代码位于码云上,点击获取:Git地址 主要介绍一下重点配置地方: 一.application.yml文件 server: port: 8084 servlet: context-path: / ...
- Vue 报错 listen EADDRINUSE :::8080
今天在重启vue项目的时候,发现报了错, listen EADDRINUSE :::8080错误提示 原因:因为另一个项目占用了8080端口,我直接在命令行npm run dev第二个项目,就给出了这 ...
- javaweb入门-----request与response的作用
request对象和request对象的原理 1.request和response对象request对象和request对象的原理时由服务器创建的,我们来使用它们 2.request对象是来获取请求消 ...
- Linux命令(部分)
LINUX:实现某一功能,命令执行依赖于解释器程序. 内部:属于shell部分 外部:独立于shell解释器程序. 系统结构由外到内:用户 ⇢ 外围程序 ⇢ 硬件 ...
- 【Android】未引入包问题
Mac 上配置 Android 开发环境,遇到了下面问题: /Users/***/Documents/SVN/Android/***/1.0.3/res/values/styles.xml:21: e ...