java架构之路(MQ专题)kafka集群配置和简单使用
前面我们说了RabbitMQ和RocketMQ的安装和简单的使用,这次我们说一下Kafka的安装配置,后面我会用几个真实案例来说一下MQ的真实使用场景。天冷了,不愿意伸手,最近没怎么写博客了,还请见谅。
一、目标
1.知道什么是Kafka
2.懂得kafka的单机和集群安装配置
3.了解内部参数的简单配置
二、Kafka简介

Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。——百度百科
三、Kafka使用场景
- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
- 消息系统:解耦和生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
四、相关术语
- Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker
- Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。
- Partition
Partition是物理上的概念,每个Topic包含一个或多个Partition.
- Producer
负责发布消息到Kafka broker
- Consumer
消息消费者,向Kafka broker读取消息的客户端。
- Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
五、单机安装
1.安装jdk,输入yum install -y java-1.8.0-openjdk* 耐心等待即可,安装完成以后,输入$ java -version,检查是否安装成功。
2.由于Kafka是基于Zookeeper环境的,我们安装一下Zookeeper(不安装也可以,最好配置一下,便于后期理解,建议安装3.*版本)。我以前写过Zookeeper的安装过程,想看的可以去了解一下https://www.cnblogs.com/cxiaocai/p/11597465.html
3.输入wget https://archive.apache.org/dist/kafka/1.1.0/kafka_2.11-1.1.0.tgz 等待下载完成,Kafka现在是0.*,1.*,2.*三个版本,这里建议使用1.*版本,你也可以下载最新的2.3.1版本,下载方式wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.3.1/kafka_2.12-2.3.1.tgz,这里说一下,kafka_2.12-2.3.1.tgz前面的2.12是Scala语言版本,后面的2.3.1才是我们的Kafka的版本。官网地址:http://kafka.apache.org/
4.解压tar -zxvf kafka_2.11-1.1.0.tgz
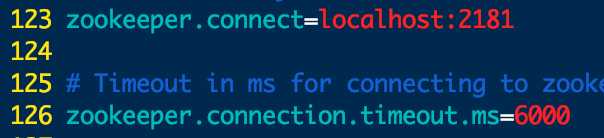
5.进入到config目录下,vim server.properties,我们在123行可以看到Zookeeper的配置如下(不是localhost的自己改一下)
6.启动$ ./bin/kafka-server-start.sh -daemon config/server.properties
7.进入Zookeeper下查看节点信息。
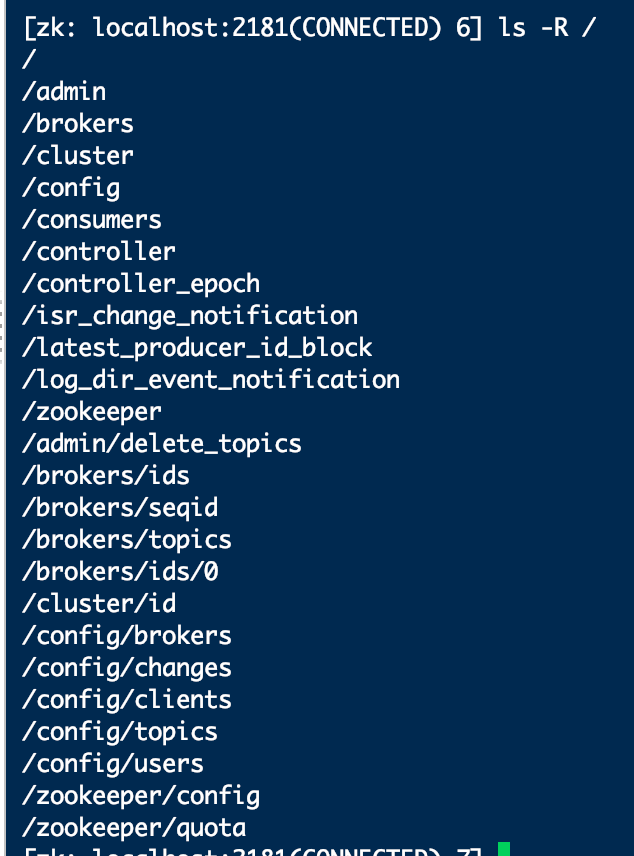
输入jps看到我们的进程kafka,单机配置成功。
六、集群安装
1.重复单机安装步骤。
2.修改配置文件,在21行broker.id设置为不同的数字,第一台可以设置0,第二台1,依次类推,在123行 zookeeper.connect写入Zookeeper集群连接,例如zookeeper.connect=47.105.137.93:2181,114.215.145.41:2181,115.29.151.4:2181。
3.分别启动三个Kafka。
4.测试集群,创建一个主题./bin/kafka-topics.sh --create --zookeeper 47.105.137.93:2181,114.215.145.41:2181,115.29.151.4:2181 --replication-factor 1 --partitions 1 --topic test
到其它服务器下查看现有主题即可。
七、简单使用
1.创建主题 ./bin/kafka-topics.sh --create --zookeeper IP:端口,IP:端口 --replication-factor 副本数 --partitions 分区数 --topic 主题名
例如:./bin/kafka-topics.sh --create --zookeeper 47.105.137.93:2181,114.215.145.41:2181,115.29.151.4:2181 --replication-factor 1 --partitions 1 --topic xiaocaijishu
2.查看现有主题 ./bin/kafka-topics.sh --list --zookeeper IP:端口,IP:端口
例如:./bin/kafka-topics.sh --list --zookeeper 47.105.137.93:2181,114.215.145.41:2181,115.29.151.4:2181
3.删除主题 ./bin/kafka-topics.sh --delete --topic xiaocaijishu2 --zookeeper IP:端口,IP:端口
例如:./bin/kafka-topics.sh --delete --topic xiaocaijishu2 --zookeeper 47.105.137.93:2181,114.215.145.41:2181,115.29.151.4:2181
4.发送消息 ./bin/kafka-console-producer.sh --broker-list Kafka服务器IP:9092 --topic 主题名
例如:./bin/kafka-console-producer.sh --broker-list 47.105.137.93:9092 --topic xiaocaijishu
5.消费消息./bin/kafka-console-consumer.sh --bootstrap-server Kafka服务器IP:9092 --consumer-property group.id=消费组名称 --topic 主题名
例如: ./bin/kafka-console-consumer.sh --bootstrap-server 47.105.137.93:9092 --consumer-property group.id=xiaocaiGroup --topic xiaocaijishu
6.查看现有消费组 ./bin/kafka-consumer-groups.sh --bootstrap-server Kafka服务器IP:9092 --list
例如:./bin/kafka-consumer-groups.sh --bootstrap-server 47.105.137.93:9092 --list

最进弄了一个公众号,小菜技术,欢迎大家的加入

java架构之路(MQ专题)kafka集群配置和简单使用的更多相关文章
- Kafka集群配置---Windows版
Kafka是一种高吞吐量的分布式发布订阅的消息队列系统,Kafka对消息进行保存时是通过tipic进行分组的.今天我们仅实现Kafka集群的配置.理论的抽空在聊 前言 最近研究kafka,发现网上很多 ...
- HyperLedger Fabric基于zookeeper和kafka集群配置解析
简述 在搭建HyperLedger Fabric环境的过程中,我们会用到一个configtx.yaml文件(可参考Hyperledger Fabric 1.0 从零开始(八)--Fabric多节点集群 ...
- Kafka 集群配置SASL+ACL
一.简介 在Kafka0.9版本之前,Kafka集群时没有安全机制的.Kafka Client应用可以通过连接Zookeeper地址,例如zk1:2181:zk2:2181,zk3:2181等.来获取 ...
- kafka集群配置与测试
刚接触一些Apache Kafka的内容,用了两天时间研究了一下,仅以此文做相关记录,以供学习交流. 概念: kafka依赖的项: 1. 硬件上,kafka利用线性存储来进行硬盘直接读写. 2. k ...
- kafka能做什么?kafka集群配置 (卡夫卡 大数据)
什么是Kafka 官网介绍: 几个概念: 详细介绍 : 操作kafka: kafka集群 消息测试 问题检测 什么是Kafka 官网介绍: ApacheKafka是一个分布式流媒体平台.这到底是什么意 ...
- kafka集群配置和java编写生产者消费者操作例子
kafka 安装 修改配置文件 java操作kafka kafka kafka的操作相对来说简单很多 安装 下载kafka http://kafka.apache.org/downloads tar ...
- linux运维、架构之路-Hadoop完全分布式集群搭建
一.介绍 Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS.HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件 ...
- Kafka集群配置
kafka_2.11-0.9.0.1.tgz 1.进入项目前的目录 cd /home/dongshanxia mkdir kafka #创建项目目录 cd kafka #进入项目目录 mkdir ka ...
- kafka集群安装及简单使用
关于kafka是什么及原理,请参考kafka官方文档的介绍:http://kafka.apache.org/documentation/#introduction ,英文不好的同学可以看这里http: ...
随机推荐
- session与cookie,django中间件
0819自我总结 一.session与cookie 1.django设置session request.session['name'] = username request.session['age' ...
- mysql 延时注入新思路
转自先知社区https://xz.aliyun.com/t/2288 在4月的pwnhub比赛中,我们遇到了一个比较神奇的问题,如果在注入中遇到需要延时注入的情况,但服务端过滤了我们一般使用的slee ...
- 微信小程序尺寸单位rpx以及样式相关介绍
rpx单位是微信小程序中css的尺寸单位,rpx可以根据屏幕宽度进行自适应.规定屏幕宽为750rpx.如在 iPhone6 上,屏幕宽度为375px,共有750个物理像素,则750rpx = 375p ...
- 利用WinRM实现内网无文件攻击反弹shell
利用WinRM实现内网无文件攻击反弹shell 原文转自:https://www.freebuf.com/column/212749.html 前言 WinRM是Windows Remote Mana ...
- vue3.0 + ueditor
公司有个需求,需要做个发送邮件的模版(富文本对于模版的扩展性更好吧) 关于富文本,也找了一些好看且支持vue的,但是功能都没有百度全面 反正这个系统也是自己人用,颜值无所谓了 关于vue2.0+ued ...
- 浅谈K-means聚类算法
K-means算法的起源 1967年,James MacQueen在他的论文<用于多变量观测分类和分析的一些方法>中首次提出 “K-means”这一术语.1957年,贝尔实验室也将标准算法 ...
- MyBatis 概念
简介 什么是 MyBatis? MyBatis 是一款优秀的持久层框架,它支持定制化 SQL.存储过程以及高级映射.MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集.MyB ...
- 09 python学习笔记-操作excel(九)
python操作excel使用xlrd.xlwt和xlutils模块,xlrd模块是读取excel的,xlwt模块是写excel的,xlutils是用来修改excel的.这几个模块可以使用pip安装, ...
- node项目发布+域名及其二级域名配置+nginx反向代理+pm2
学习node的时候也写了一些demo.但是只是限于本地测试,从来没有发布.今天尝试发布项目. 需要准备的东西 node 项目:为了突出重点,说明主要问题.我只是拿express 写了很简单的demo. ...
- 在jupyter中调用R
目录 安装R 关联jupyter notebook 安装R 系统:Ubuntu:16.04 步骤1.添加镜像源 $ sudo echo "deb http://cran.rstudio.co ...