python机器学习——使用scikit-learn训练感知机模型
这一篇我们将开始使用scikit-learn的API来实现模型并进行训练,这个包大大方便了我们的学习过程,其中包含了对常用算法的实现,并进行高度优化,以及含有数据预处理、调参和模型评估的很多方法。
我们来看一个之前看过的实例,不过这次我们使用sklearn来训练一个感知器模型,数据集还是Iris,使用其中两维度的特征,样本数据使用三个类别的全部150个样本
%matplotlib inline
import numpy as np
from sklearn import datasetsiris = datasets.load_iris()
X = iris.data[:, [2, 3]]
y = iris.targetnp.unique(y)array([0, 1, 2])为了评估训练好的模型对新数据的预测能力,我们这里将Iris数据集分为训练集和测试集,这里我们通过调用trian_test_split方法来将数据集分为两部分,其中测试集占30%,训练集占70%
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)我们再将特征进行缩放操作,这里调用StandardScaler来对特征进行标准化:
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)新对象sc使用fit方法对数据集中每一维的特征计算出样本平均值和标准差,然后调用transform方法对数据集进行标准化,我们这里使用相同的标准化参数对待训练集和测试集。接下来我们训练一个感知器模型
from sklearn.linear_model import Perceptronppn = Perceptron(max_iter=40, eta0=0.1, random_state=0)ppn.fit(X_train_std, y_train)
Perceptron(alpha=0.0001, class_weight=None, early_stopping=False, eta0=0.1,
fit_intercept=True, max_iter=40, n_iter_no_change=5, n_jobs=None,
penalty=None, random_state=0, shuffle=True, tol=0.001,
validation_fraction=0.1, verbose=0, warm_start=False)y_pred = ppn.predict(X_test_std)
print('Misclassified samples: %d' % (y_test != y_pred).sum())
Misclassified samples: 5可以看出测试集中有5个样本被分错类了,因此错误分类率是0.11,则分类准确率为1-0.11=0.89,我们也可以直接计算分类准确率:
from sklearn.metrics import accuracy_score
print('Accuracy: %.2f' % accuracy_score(y_test, y_pred))
Accuracy: 0.89最后我们画出分界区域,这里我们将plot_decision_regions函数进行一些修改,使我们可以区分训练集和测试集的样本
from matplotlib.colors import ListedColormap
import matplotlib.pyplot as plt
def plot_decision_regions(X, y, classifier, test_idx=None, resolution=0.02):
# setup marker generator and color map
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
# plot the decision surface
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, slpha=0.4, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
# plot all samples
X_test, y_test = X[test_idx, :], y[test_idx]
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1], alpha=0.8,
c=cmap(idx), marker=markers[idx], label=cl)
# highlight test samples
if test_idx:
X_test, y_test = X[test_idx, :], y[test_idx]
plt.scatter(X_test[:, 0], X_test[:, 1], c='',alpha=1.0,
linewidth=1, marker='o', s=55, label='test set')
X_combined_std = np.vstack((X_train_std, X_test_std))
y_combined = np.hstack((y_train, y_test))
plot_decision_regions(X=X_combined_std, y=y_combined, classifier=ppn,
test_idx=range(105, 150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.show()
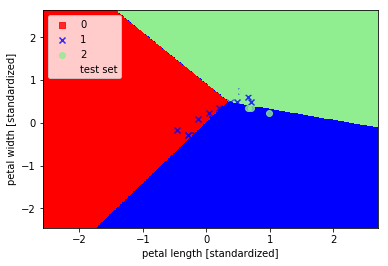
可以看出三个类别并没有被完美分类,这是由于这三类花并不是线性可分的数据。
python机器学习——使用scikit-learn训练感知机模型的更多相关文章
- 吴裕雄 python 机器学习——人工神经网络与原始感知机模型
import numpy as np from matplotlib import pyplot as plt from mpl_toolkits.mplot3d import Axes3D from ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- 机器学习框架Scikit Learn的学习
一 安装 安装pip 代码如下:# wget "https://pypi.python.org/packages/source/p/pip/pip-1.5.4.tar.gz#md5=83 ...
- 使用SKlearn(Sci-Kit Learn)进行SVR模型学习
今天了解到sklearn这个库,简直太酷炫,一行代码完成机器学习. 贴一个自动生成数据,SVR进行数据拟合的代码,附带网格搜索(GridSearch, 帮助你选择合适的参数)以及模型保存.读取以及结果 ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——支持向量机SVM非线性分类SVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——等度量映射Isomap降维模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——多维缩放降维MDS模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
随机推荐
- TCP/IP协议介绍
一.什么是TCP/IP TCP/IP是一类协议系统,它是用于网络通信的一套协议集合 TCP/IP是供已连接因特网的计算机进行通信的通信协议 TCP/IP指传输控制协议/网际协议 TCP/IP定义了电子 ...
- 想转行做3D游戏模型,如何快速入行
随着技术和硬件迭代,3D建模,广泛运用在游戏,影视,动画,VR等领域,而且就业面非常广. 由于3D美术设计师薪资和前景确实都不错,很多同学想进入这个行业,从事相关工作,但是没有一个整体的学习思路和规划 ...
- 介绍ArcGIS中各种数据的打开方法——mxd(地图文档)
1.加载地图文档 在ArcGIS中,以mxd作为扩展名的文件叫地图文档. 地图文档中只是包含图层的引用,即存储当前地图的图层路径.符号.状态.修饰等信息,并不存储真实的数据层. ArcGIS Map中 ...
- Python 之Re模块(正则表达式)
一.简介 正则表达式本身是一种小型的.高度专业化的编程语言,而在python中,通过内嵌集成re模块,程序媛们可以直接调用来实现正则匹配. 二.正则表达式中常用的字符含义 1.普通字符和11个元字符: ...
- 线段树区间取max区间查询
要线段树资瓷区间max和询问区间和. 设要把$[L, R]$对mx取max. 我们可以在线段树上二分出小于mx的区间然后变成区间修改了. 具体实现是,维护区间最小值和区间最大值,我们递归进入一个区间, ...
- .Net Core 3.0 IdentityServer4 快速入门
.Net Core 3.0 IdentityServer4 快速入门 一.简介 IdentityServer4是用于ASP.NET Core的OpenID Connect和OAuth 2.0框架. 将 ...
- HDU 5616 Jam's balance(01背包)
题目网址:http://acm.hdu.edu.cn/showproblem.php?pid=5616 题目: Jam's balance Time Limit: 2000/1000 MS (Java ...
- halcon学习方法小结及以后的学习计划
学了这么久的halcon,感觉还是没有摸到门路. 记录一下这么久以来经历过的学习阶段: 看冈萨雷斯<数字图像处理>这本书,使用halcon做练习. 我实际上只比较完整地看了这本书的形态学处 ...
- Jackson替换fastjson
为什么要替换fastjson 工程里大量使用了fastjson作为序列化和反序列化框架,甚至ORM在处理部分字段也依赖fastjson进行序列化和反序列化.那么作为大量使用的基础框架,为什么还要进行替 ...
- [AHOI2002]哈利·波特与魔法石
这道题比较简单,就是一个最短路(SSSP).数据水,用Floyd即可AC.这里用了Dijkstra. #include <iostream> #include <cstdio> ...