python机器学习——随机梯度下降
上一篇我们实现了使用梯度下降法的自适应线性神经元,这个方法会使用所有的训练样本来对权重向量进行更新,也可以称之为批量梯度下降(batch gradient descent)。假设现在我们数据集中拥有大量的样本,比如百万条样本,那么如果我们现在使用批量梯度下降来训练模型,每更新一次权重向量,我们都要使用百万条样本,训练时间很长,效率很低,我们能不能找到一种方法,既能使用梯度下降法,但是又不要每次更新权重都要使用到所有的样本,于是随机梯度下降法(stochastic gradient descent)便被提出来了。
随机梯度下降法可以只用一个训练样本来对权重向量进行更新:
\[
\eta(y^i-\phi(z^i))x^i
\]
这种方法比批量梯度下降法收敛的更快,因为它可以更加频繁的更新权重向量,并且使用当个样本来更新权重,相比于使用全部的样本来更新更具有随机性,有助于算法避免陷入到局部最小值,使用这个方法的要注意在选取样本进行更新时一定要随机选取,每次迭代前都要打乱所有的样本顺序,保证训练的随机性,并且在训练时的学习率也不是固定不变的,可以随着迭代次数的增加,学习率逐渐减小,这种方法可以有助于算法收敛。
现在我们有了使用全部样本的批量梯度下降法,也有了使用单个样本的随机梯度下降法,那么一种折中的方法,称为最小批学习(mini-batch learning),它每次使用一部分训练样本来更新权重向量。
接下来我们实现使用随机梯度下降法的Adaline
from numpy.random import seedclass AdalineSGD(object):
"""ADAptive LInear NEuron classifier.
Parameters
----------
eta:float
Learning rate(between 0.0 and 1.0
n_iter:int
Passes over the training dataset.
Attributes
----------
w_: 1d-array
weights after fitting.
errors_: list
Number of miscalssifications in every epoch.
shuffle:bool(default: True)
Shuffle training data every epoch
if True to prevent cycles.
random_state: int(default: None)
Set random state for shuffling
and initalizing the weights.
"""
def __init__(self, eta=0.01, n_iter=10, shuffle=True, random_state=None):
self.eta = eta
self.n_iter = n_iter
self.w_initialized = False
self.shuffle = shuffle
if random_state:
seed(random_state)
def fit(self, X, y):
"""Fit training data.
:param X:{array-like}, shape=[n_samples, n_features]
:param y: array-like, shape=[n_samples]
:return:
self:object
"""
self._initialize_weights(X.shape[1])
self.cost_ = []
for i in range(self.n_iter):
if self.shuffle:
X, y = self._shuffle(X, y)
cost = []
for xi, target in zip(X, y):
cost.append(self._update_weights(xi, target))
avg_cost = sum(cost)/len(y)
self.cost_.append(avg_cost)
return self
def partial_fit(self, X, y):
"""Fit training data without reinitializing the weights."""
if not self.w_initialized:
self._initialize_weights(X.shape[1])
if y.ravel().shape[0] > 1:
for xi, target in zip(X, y):
self._update_weights(xi, target)
else:
self._update_weights(X, y)
return self
def _shuffle(self, X, y):
"""Shuffle training data"""
r = np.random.permutation(len(y))
return X[r], y[r]
def _initialize_weights(self, m):
"""Initialize weights to zeros"""
self.w_ = np.zeros(1 + m)
self.w_initialized = True
def _update_weights(self, xi, target):
"""Apply Adaline learning rule to update the weights"""
output = self.net_input(xi)
error = (target - output)
self.w_[1:] += self.eta * xi.dot(error)
self.w_[0] += self.eta * error
cost = 0.5 * error ** 2
return cost
def net_input(self, X):
"""Calculate net input"""
return np.dot(X, self.w_[1:]) + self.w_[0]
def activation(self, X):
"""Computer linear activation"""
return self.net_input(X)
def predict(self, X):
"""Return class label after unit step"""
return np.where(self.activation(X) >= 0.0, 1, -1)
其中_shuffle方法中,调用numpy.random中的permutation函数得到0-100的一个随机序列,然后这个序列作为特征矩阵和类别向量的下标,就可以起到打乱样本顺序的功能。
现在开始训练
ada = AdalineSGD(n_iter=15, eta=0.01, random_state=1)
ada.fit(X_std, y)画出分界图和训练曲线图
plot_decision_region(X_std, y, classifier=ada)
plt.title('Adaline - Stochastic Gradient Desent')
plt.xlabel('sepal length [standardized]')
plt.ylabel('petal length [standardized]')
plt.legend(loc = 'upper left')
plt.show()
plt.plot(range(1, len(ada.cost_) + 1), ada.cost_, marker='o')
plt.xlabel('Epochs')
plt.ylabel('Average Cost')
plt.show()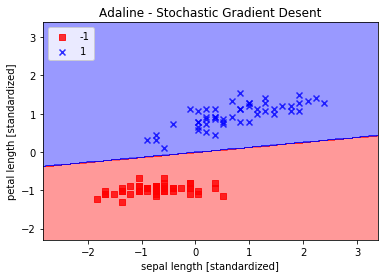

从上图可以看出,平均损失下降很快,在大概第15次迭代后,分界线和使用批量梯度下降的Adaline分界线很类似。
python机器学习——随机梯度下降的更多相关文章
- 机器学习-随机梯度下降(Stochastic gradient descent)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 机器学习-随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )
梯度下降(GD)是最小化风险函数.损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正. 下面的h(x)是要拟 ...
- Python之随机梯度下降
实现:# -*- coding: UTF-8 -*-""" 练习使用随机梯度下降算法"""import numpy as npimport ...
- 机器学习算法(优化)之一:梯度下降算法、随机梯度下降(应用于线性回归、Logistic回归等等)
本文介绍了机器学习中基本的优化算法—梯度下降算法和随机梯度下降算法,以及实际应用到线性回归.Logistic回归.矩阵分解推荐算法等ML中. 梯度下降算法基本公式 常见的符号说明和损失函数 X :所有 ...
- 机器学习(ML)十五之梯度下降和随机梯度下降
梯度下降和随机梯度下降 梯度下降在深度学习中很少被直接使用,但理解梯度的意义以及沿着梯度反方向更新自变量可能降低目标函数值的原因是学习后续优化算法的基础.随后,将引出随机梯度下降(stochastic ...
- 随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )的公式对比、实现对比[转]
梯度下降(GD)是最小化风险函数.损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正. 下面的h(x)是要拟 ...
- 梯度下降之随机梯度下降 -minibatch 与并行化方法
问题的引入: 考虑一个典型的有监督机器学习问题,给定m个训练样本S={x(i),y(i)},通过经验风险最小化来得到一组权值w,则现在对于整个训练集待优化目标函数为: 其中为单个训练样本(x(i),y ...
- 【转】 随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )的公式对比、实现对比
梯度下降(GD)是最小化风险函数.损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正. 下面的h(x)是要拟 ...
- 批量梯度下降(BGD)、随机梯度下降(SGD)以及小批量梯度下降(MBGD)的理解
梯度下降法作为机器学习中较常使用的优化算法,其有着三种不同的形式:批量梯度下降(Batch Gradient Descent).随机梯度下降(Stochastic Gradient Descent ...
随机推荐
- GDB使用总结
1. GDB概述 GNU发布的调试器,可以查看程序如何运行或崩溃时的状态. 主要功能: 启动程序,可以按照自定义的要求运行程序. 可让被调试的程序在你所指定的断点处停住. 当程序被停住时,可以检查此时 ...
- JavaScript ES6函数式编程(一):闭包与高阶函数
函数式编程的历史 函数的第一原则是要小,第二原则则是要更小 -- ROBERT C. MARTIN 解释一下上面那句话,就是我们常说的一个函数只做一件事,比如:将字符串首字母和尾字母都改成大写,我们此 ...
- RegExp实现字符替换
将字符串组中的所有Paul替换成Ringo,g:执行全局匹配,查找所有匹配而非在找到第一个匹配后停止;\b:匹配单词边界,划分匹配字符的起始范围 <!DOCTYPE html> <h ...
- POWERSPLOIT-Exfiltration(信息收集)脚本渗透实战
Exfiltration模块 a) 调用Get-Keystrokes记录用户的键盘输入. 1)通过IEX下载并调用Get-Keystrokes. PS C:\Users\Administrator&g ...
- 机器学习:eclipse中调用weka的Classifier分类器代码Demo
weka中实现了很多机器学习算法,不管实验室研究或者公司研发,都会或多或少的要使用weka,我的理解是weka是在本地的SparkML,SparkML是分布式的大数据处理机器学习算法,数据量不是很大的 ...
- [CF722C] Destroying Array
C. Destroying Array time limit per test 1 second memory limit per test 256 megabytes input standard ...
- 关于Mapper.xml生效的问题
昨天在新建Springboot启动后,发现执行相关的SQL报错,具体报错信息如下: org.apache.ibatis.binding.BindingException: Invalid bound ...
- opencv::像素重映射
像素重映射(cv::remap) 简单点说就是把输入图像中各个像素按照一定的规则映射到另外一张图像的对应位置上去,形成一张新的图像. Remap( InputArray src, // 输入图像 Ou ...
- python编程系列---tcp客户端的简单实现
实现流程如下: """ TCP客户端实现流程1. 创建一个tcp 客户端对象2. 与服务端建立连接3. 通过tcp socket 收发数据4. 关闭连接 关闭tcp &q ...
- Windows下Python虚拟环境的配置
一.了解Python虚拟环境 所谓虚拟环境可以理解为不同的不连通的本地设备,打个比方就是在一台电脑上能做到多台电脑能做的事情. 例如:现在我们有两个项目需要不同的配置,记为A项目需要库a------- ...