C4.5和ID3的差别
C4.5和ID3的差别
决策树分为两大类:分类树和回归树,前者用于分类标签值,后者用于预测连续值,常用算法有ID3、C4.5、CART等。
信息熵
信息量:
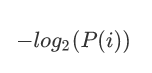
信息熵:
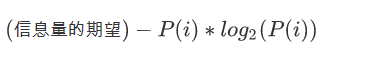
信息增益
当计算出各个特征属性的量化纯度值后使用信息增益度来选择出当前数据集的分割特征属性;如果信息增益度的值越大,表示在该特征属性上会损失的纯度越大 ,那么该属性就越应该在决策树的上层,计算公式为:

Gain为A为特征对训练数据集D的信息增益,它为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差。
ID3
ID3算法是决策树的一个经典的构造算法,内部使用信息熵以及信息增益来进行构建;每次迭代选择信息增益最大的特征属性作为分割属性。
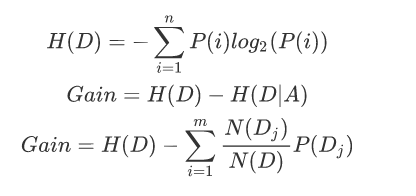
优点:
决策树构建速度快;实现简单;
缺点:
计算依赖于特征数目较多的特征,而属性值最多的属性并不一定最优ID3算法不是递增算法ID3算法是单变量决策树,对于特征属性之间的关系不会考虑抗噪性差只适合小规模数据集,需要将数据放到内存中
C4.5
在ID3算法的基础上,进行算法优化提出的一种算法(C4.5);现在C4.5已经是特别经典的一种决策树构造算法;使用信息增益率来取代ID3算法中的信息增益,在树的构造过程中会进行剪枝操作进行优化;能够自动完成对连续属性的离散化处理;C4.5算法在选中分割属性的时候选择信息增益率最大的属性,涉及到的公式为:
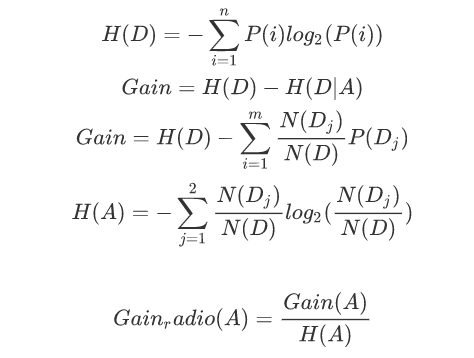
优点:
产生的规则易于理解准确率较高实现简单
缺点:
对数据集需要进行多次顺序扫描和排序,所以效率较低只适合小规模数据集,需要将数据放到内存中
CART
使用基尼系数作为数据纯度的量化指标来构建的决策树算法就叫做CART(Classification And Regression Tree,分类回归树)算法。CART算法使用GINI增益作为分割属性选择的标准,选择GINI增益最大的作为当前数据集的分割属性;可用于分类和回归两类问题。强调备注:CART构建是二叉树。
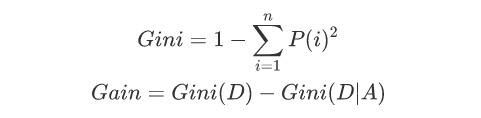
ID3和C4.5算法均只适合在小规模数据集上使用
ID3和C4.5算法都是单变量决策树
当属性值取值比较多的时候,最好考虑C4.5算法,ID3得出的效果会比较差
决策树分类一般情况只适合小数据量的情况(数据可以放内存)
CART算法是三种算法中最常用的一种决策树构建算法。
三种算法的区别仅仅只是对于当前树的评价标准不同而已,ID3使用信息增益、
C4.5使用信息增益率、CART使用基尼系数。
CART算法构建的一定是二叉树,ID3和C4.5构建的不一定是二叉树。
案例


C4.5和ID3的差别的更多相关文章
- C4.5较ID3的改进
1.ID3选择最大化Information Gain的属性进行划分 C4.5选择最大化Gain Ratio的属性进行划分 规避问题:ID3偏好将数据分为很多份的属性 解决:将划分后数据集的个数考虑 ...
- 【机器学习】决策树C4.5、ID3
一.算法流程 step1:计算信息熵 step2: 划分数据集 step3: 创建决策树 step4: 利用决策树分类 二.信息熵Entropy.信息增益Gain 重点:选择一个属性进行分支.注意信息 ...
- ID3、C4.5、CART、RandomForest的原理
决策树意义: 分类决策树模型是表示基于特征对实例进行分类的树形结构.决策树可以转换为一个if_then规则的集合,也可以看作是定义在特征空间划分上的类的条件概率分布. 它着眼于从一组无次序.无规则的样 ...
- 用于分类的决策树(Decision Tree)-ID3 C4.5
决策树(Decision Tree)是一种基本的分类与回归方法(ID3.C4.5和基于 Gini 的 CART 可用于分类,CART还可用于回归).决策树在分类过程中,表示的是基于特征对实例进行划分, ...
- 小啃机器学习(1)-----ID3和C4.5决策树
第一部分:简介 ID3和C4.5算法都是被Quinlan提出的,用于分类模型,也被叫做决策树.我们给一组数据,每一行数据都含有相同的结构,包含了一系列的attribute/value对. 其中一个属性 ...
- 决策树(ID3、C4.5、CART)
ID3决策树 ID3决策树分类的根据是样本集分类前后的信息增益. 假设我们有一个样本集,里面每个样本都有自己的分类结果. 而信息熵可以理解为:“样本集中分类结果的平均不确定性”,俗称信息的纯度. 即熵 ...
- 机器学习算法总结(二)——决策树(ID3, C4.5, CART)
决策树是既可以作为分类算法,又可以作为回归算法,而且在经常被用作为集成算法中的基学习器.决策树是一种很古老的算法,也是很好理解的一种算法,构建决策树的过程本质上是一个递归的过程,采用if-then的规 ...
- ID3和C4.5分类决策树算法 - 数据挖掘算法(7)
(2017-05-18 银河统计) 决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来判断其可行性的决策分析方法,是直观运用概率分析的一种图解法.由于这种决策分支画 ...
- 2. 决策树(Decision Tree)-ID3、C4.5、CART比较
1. 决策树(Decision Tree)-决策树原理 2. 决策树(Decision Tree)-ID3.C4.5.CART比较 1. 前言 上文决策树(Decision Tree)1-决策树原理介 ...
随机推荐
- 安装使用Cloudera Impala
安装与使用Cloudera Impala Cloudera Impala提供快速的.交互式的SQL查询方式,直接基于Apache Hadoop存储在HDFS或HBase中的数据进行查询.除了使用与Ap ...
- JS数据结构第三篇---双向链表和循环链表之约瑟夫问题
一.双向链表 在上文<JS数据结构第二篇---链表>中描述的是单向链表.单向链表是指每个节点都存有指向下一个节点的地址,双向链表则是在单向链表的基础上,给每个节点增加一个指向上一个节点的地 ...
- spring之@value详解二(转载)
1.1 前提 测试属性文件:advance_value_inject.properties server.name=server1,server2,server3 #spelDefault.value ...
- Python基础(七) 闭包与装饰器
闭包的定义 闭包是嵌套在函数中的函数. 闭包必须是内层函数对外层函数的变量(非全局变量)的引用. 闭包格式: def func(): lst=[] def inner(a): lst.append(a ...
- Elasticsearch-head插件使用小结
1.ElasticSearch-head是什么? ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasti ...
- IM推送保障及网络优化详解(一):如何实现不影响用户体验的后台保活
对于移动APP来说,IM功能正变得越来越重要,它能够创建起人与人之间的连接.社交类产品中,用户与用户之间的沟通可以产生出更好的用户粘性. 在复杂的 Android 生态环境下,多种因素都会造成消息推送 ...
- OVS实现VXLAN隔离
一.实验环境 1.准备3个CentOS7 mini版本的虚拟机,每个主机3个网卡.如图: 图中OVS-1.OVS-2.OVS-3分别为三台CentOS7 mini版虚拟机,分别配备3个虚拟网卡.如图中 ...
- 【面试】MySQL 中NULL和空值的区别?
做一个积极的人 编码.改bug.提升自己 我有一个乐园,面向编程,春暖花开! 01 小木的故事 作为后台开发,在日常工作中如果要接触Mysql数据库,那么不可避免会遇到Mysql中的NULL和空值.那 ...
- List中的set方法和add方法
public class TestList {public static void main(String[] args){ List l1 = new LinkedList(); for(i ...
- memcached分布式一致性哈希算法
<span style="font-family: FangSong_GB2312; background-color: rgb(255, 255, 255);">如果 ...