损失函数———有关L1和L2正则项的理解
一、损失函:
模型的结构风险函数包括了 经验风险项 和 正则项,如下所示:
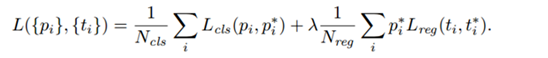
二、损失函数中的正则项
1.正则化的概念:
机器学习中都会看到损失函数之后会添加一个额外项,常用的额外项一般有2种,L1正则化和L2正则化。L1和L2可以看做是损失函数的惩罚项,所谓惩罚项是指对损失函数中某些参数做一些限制,以降低模型的复杂度。
L1正则化通过稀疏参数(特征稀疏化,降低权重参数的数量)来降低模型的复杂度;
L2正则化通过降低权重的数值大小来降低模型复杂度。
对于线性回归模型,使用L1正则化的模型叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。
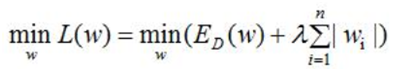
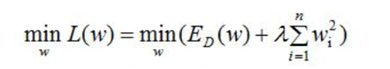
一般正则化项前面添加一个系数λ,数值大小需要用户自己指定,称权重衰减系数weight_decay,表示衰减的快慢。
2.L1正则化和L2正则化的作用:
·L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择。
·L2正则化可以减小参数大小,防止模型过拟合;一定程度上L1也可以防止过拟合
稀疏矩阵的概念:
·在矩阵中,若数值为0的元素数目远远超过非0元素的数目时,则该矩阵为稀疏矩阵。与之相反,若非0元素数目占大多数时,则称该矩阵为稠密矩阵。
3、正则项的直观理解
引用文档链接:
https://baijiahao.baidu.com/s?id=1621054167310242353&wfr=spider&for=pc
分别从以下角度对L1和L2正则化进行解释:
1、 优化角度分析
2、 梯度角度分析
3、 图形角度分析
4、 PRML的图形角度分析
优化角度分析:
L2正则化的优化角度分析:

即在限定区域 找到使得ED(W)最小的权重W。
找到使得ED(W)最小的权重W。
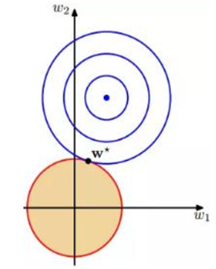
假设n=2,即只有2个参数w1和w2;作图如下:

图中红色的圆即是限定区域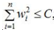 ,简化为2个参数就是w1和w2,限定区域w12+w22≤C即是以原点为圆心的圆。蓝色实线和虚线是等高线,外高内低,越靠里面的等高圆ED(W)越小。梯度下降的方向(梯度的反方向-▽ED(W)),即图上灰色箭头的方向,由外圆指向内圆的方向
,简化为2个参数就是w1和w2,限定区域w12+w22≤C即是以原点为圆心的圆。蓝色实线和虚线是等高线,外高内低,越靠里面的等高圆ED(W)越小。梯度下降的方向(梯度的反方向-▽ED(W)),即图上灰色箭头的方向,由外圆指向内圆的方向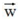 表示;正则项边界上运动点P1和P2的切线用绿色箭头表示,法向量用实黑色箭头表示。切点P1上的切线在梯度下降方向有分量,仍有往负梯度方向运动的趋势;而切点P2上的法向量正好是梯度下降的方向,切线方向在梯度下降方向无分量,所以往梯度下降方向没有运动趋势,已是梯度最小的点。
表示;正则项边界上运动点P1和P2的切线用绿色箭头表示,法向量用实黑色箭头表示。切点P1上的切线在梯度下降方向有分量,仍有往负梯度方向运动的趋势;而切点P2上的法向量正好是梯度下降的方向,切线方向在梯度下降方向无分量,所以往梯度下降方向没有运动趋势,已是梯度最小的点。
结论:L2正则项使E最小时对应的参数W变小(离原点的距离更小)
L1正则化的优化角度分析:

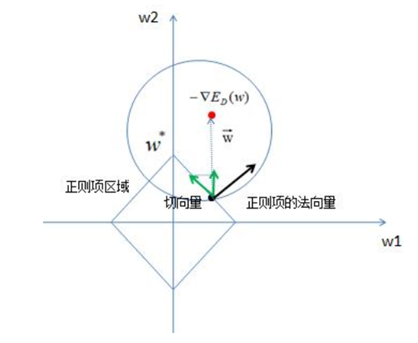
在限定区域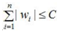 ,找到使ED(w)的最小值。
,找到使ED(w)的最小值。
同上,假设参数数量为2:w1和w2,限定区域为|w1|+|w2|≤C ,即为如下矩形限定区域,限定区域边界上的点的切向量的方向始终指向w2轴,使得w1=0,所以L1正则化容易使得参数为0,即使参数稀疏化。
梯度角度分析:
L1正则化:
L1正则化的损失函数为:
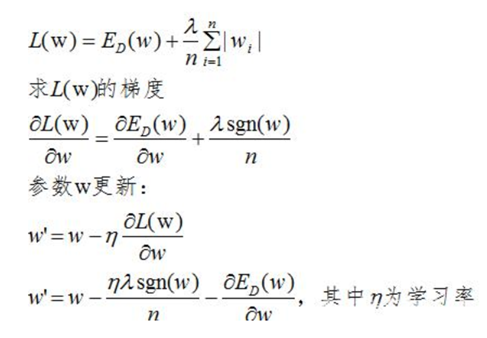
L1正则项的添加使参数w的更新增加了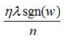 ,sgn(w)为阶跃函数,当w大于0,sgn(w)>0,参数w变小;当w小于0时,更新参数w变大,所以总体趋势使得参数变为0,即特征稀疏化。
,sgn(w)为阶跃函数,当w大于0,sgn(w)>0,参数w变小;当w小于0时,更新参数w变大,所以总体趋势使得参数变为0,即特征稀疏化。
L2正则化:
L2正则化的损失函数为:
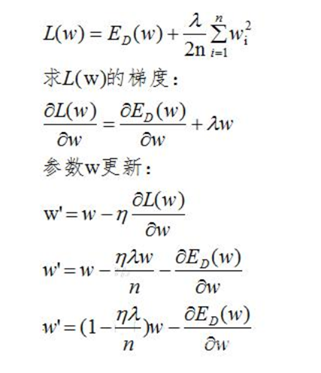
由上式可以看出,正则化的更新参数相比没有加正则项的更新参数多了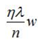 ,当w>0时,正则项使得参数增大变慢(减去一个数值,增大的没那么快),当w<0时,正则项使得参数减小变慢(加上一个数值,减小的没那么快),总体趋势变得很小,但不为0。
,当w>0时,正则项使得参数增大变慢(减去一个数值,增大的没那么快),当w<0时,正则项使得参数减小变慢(加上一个数值,减小的没那么快),总体趋势变得很小,但不为0。
PRML的图形角度分析
L1正则化在零点附近具有很明显的棱角,L2正则化则在零附近是比较光滑的曲线。所以L1正则化更容易使参数为零,L2正则化则减小参数值,如下图。
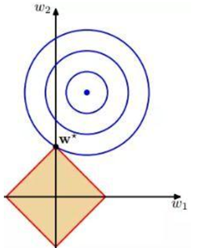
L1正则项
L2正则项
以上是根据阅读百度网友文章做的笔记(其中包括自己的理解),感谢该文档作者,引用链接:
https://baijiahao.baidu.com/s?id=1621054167310242353
损失函数———有关L1和L2正则项的理解的更多相关文章
- 『科学计算』L0、L1与L2范数_理解
『教程』L0.L1与L2范数 一.L0范数.L1范数.参数稀疏 L0范数是指向量中非0的元素的个数.如果我们用L0范数来规则化一个参数矩阵W的话,就是希望W的大部分元素都是0,换句话说,让参数W是稀 ...
- 回归损失函数:L1,L2,Huber,Log-Cosh,Quantile Loss
回归损失函数:L1,L2,Huber,Log-Cosh,Quantile Loss 2019-06-04 20:09:34 clover_my 阅读数 430更多 分类专栏: 阅读笔记 版权声明: ...
- 机器学习中正则化项L1和L2的直观理解
正则化(Regularization) 概念 L0正则化的值是模型参数中非零参数的个数. L1正则化表示各个参数绝对值之和. L2正则化标识各个参数的平方的和的开方值. L0正则化 稀疏的参数可以防止 ...
- L1和L2:损失函数和正则化
作为损失函数 L1范数损失函数 L1范数损失函数,也被称之为最小绝对值误差.总的来说,它把目标值$Y_i$与估计值$f(x_i)$的绝对差值的总和最小化. $$S=\sum_{i=1}^n|Y_i-f ...
- L0、L1与L2范数
监督机器学习问题无非就是“minimize your error while regularizing your parameters”,也就是在正则化参数的同时最小化误差.最小化误差是为了让我们的模 ...
- 机器学习中的L1、L2正则化
目录 1. 什么是正则化?正则化有什么作用? 1.1 什么是正则化? 1.2 正则化有什么作用? 2. L1,L2正则化? 2.1 L1.L2范数 2.2 监督学习中的L1.L2正则化 3. L1.L ...
- 深入理解L1、L2正则化
过节福利,我们来深入理解下L1与L2正则化. 1 正则化的概念 正则化(Regularization) 是机器学习中对原始损失函数引入额外信息,以便防止过拟合和提高模型泛化性能的一类方法的统称.也就是 ...
- 《机器学习实战》学习笔记第八章 —— 线性回归、L1、L2范数正则项
相关笔记: 吴恩达机器学习笔记(一) —— 线性回归 吴恩达机器学习笔记(三) —— Regularization正则化 ( 问题遗留: 小可只知道引入正则项能降低参数的取值,但为什么能保证 Σθ2 ...
- L1与L2损失函数和正则化的区别
本文翻译自文章:Differences between L1 and L2 as Loss Function and Regularization,如有翻译不当之处,欢迎拍砖,谢谢~ 在机器学习实 ...
随机推荐
- Java的值类型和引用类型
一.问题描述 前几天因为一个需求出现了Bug.说高级点也挺高级,说白点也很简单.其实也就是一个很简单的Java基础入门时候的值类型和引用类型的区别.只是开发的时候由于自己的问题,导致小问题的出现.还好 ...
- HihoCoder1466-后缀自动机六·重复旋律9
小Hi平时的一大兴趣爱好就是演奏钢琴.我们知道一段音乐旋律可以被表示为一段字符构成的字符串. 现在小Hi已经不满足于单单演奏了!他通过向一位造诣很高的前辈请教,通过几周时间学习了创作钢琴曲的基本理论, ...
- HDU-3727 Jewel
Jimmy wants to make a special necklace for his girlfriend. He bought many beads with various sizes, ...
- 基于iCamera测试高清摄像头SIV100B(替代ov7670)小结
基于iCamera测试高清摄像头SIV100B(替代ov7670)小结 先看看siv100b主要关键参数 SIV100B与OV7670分辨率和基本特性都差不多,而siv100b,像素尺寸更小,灵敏度更 ...
- VIP 视频开发板 上位机 测试软件 下载地址,玩转各自分辨率(V201抢先版)
本上位机最高测试帧率 133fps 目前支持分辨率:更多分辨率支持,敬请期待或给我留言VGA:640*4801.3M:1280*10242M:1600*1200786p:1024*768 格式兼容:1 ...
- 利用PyCharm操作Github(二):分支新建、切换、合并、删除
在文章利用PyCharm操作Github:仓库新建.更新,代码回滚中,我们已经学习到了如何利用PyCharm来操作Github,其中包括了一些常见的Github操作:仓库的新建.更新以及代码回滚. ...
- Linux中的 date 使用
01. 日期格式字符串列表 %H 小时(以00-23来表示). %I 小时(以01-12来表示). %K 小时(以0-23来表示). %l 小时(以0-12来表示). %M 分钟(以00-59来表示) ...
- keras实现mnist手写数字数据集的训练
网络:两层卷积,两层全连接,一层softmax 代码: import numpy as np from keras.utils import to_categorical from keras imp ...
- 优先队列与TopK
一.简介 前文介绍了<最大堆>的实现,本章节在最大堆的基础上实现一个简单的优先队列.优先队列的实现本身没什么难度,所以本文我们从优先队列的场景出发介绍topK问题. 后面会持续更新数据结构 ...
- laravel身份验证-Auth的使用
laravel自带了auth类和User模型来帮助我们很方便的实现用户登陆.判断.首先,先配置一下相关参数 app/config/auth.php: model 指定模型table 指定用户表这里我只 ...