Go 程序是怎样跑起来的
刚开始写这篇文章的时候,目标非常大,想要探索 Go 程序的一生:编码、编译、汇编、链接、运行、退出。它的每一步具体如何进行,力图弄清 Go 程序的这一生。
在这个过程中,我又复习了一遍《程序员的自我修养》。这是一本讲编译、链接的书,非常详细,值得一看!数年前,我第一次看到这本书的书名,就非常喜欢。因为它模仿了周星驰喜剧之王里出现的一本书 ——《演员的自我修养》。心向往之!
在开始本文之前,先推荐一位头条大佬的博客——《面向信仰编程》,他的 Go 编译系列文章,非常有深度,直接深入编译器源代码,我是看了很多遍了。博客链接可以从参考资料里获取。
理想很大,实现的难度也是非常大。为了避免砸了“深度解密”这个牌子,这次起了个更温和的名字,嘿嘿。
引入
我们从一个 Hello World 的例子开始:
package main
import "fmt"
func main() {
fmt.Println("hello world")
}
当我用我那价值 1800 元的 cherry 键盘潇洒地敲完上面的 hello world 代码时,保存在硬盘上的 hello.go 文件就是一个字节序列了,每个字节代表一个字符。
用 vim 打开 hello.go 文件,在命令行模式下,输入命令:
:%!xxd
就能在 vim 里以十六进制查看文件内容:

最左边的一列代表地址值,中间一列代表文本对应的 ASCII 字符,最右边的列就是我们的代码。再在终端里执行 man ascii:

和 ASCII 字符表一对比,就能发现,中间的列和最右边的列是一一对应的。也就是说,刚刚写完的 hello.go 文件都是由 ASCII 字符表示的,它被称为文本文件,其他文件被称为二进制文件。
当然,更深入地看,计算机中的所有数据,像磁盘文件、网络中的数据其实都是一串比特位组成,取决于如何看待它。在不同的情景下,一个相同的字节序列可能表示成一个整数、浮点数、字符串或者是机器指令。
而像 hello.go 这个文件,8 个 bit,也就是一个字节看成一个单位(假定源程序的字符都是 ASCII 码),最终解释成人类能读懂的 Go 源码。
Go 程序并不能直接运行,每条 Go 语句必须转化为一系列的低级机器语言指令,将这些指令打包到一起,并以二进制磁盘文件的形式存储起来,也就是可执行目标文件。
从源文件到可执行目标文件的转化过程:

完成以上各个阶段的就是 Go 编译系统。你肯定知道大名鼎鼎的 GCC(GNU Compile Collection),中文名为 GNU 编译器套装,它支持像 C,C++,Java,Python,Objective-C,Ada,Fortran,Pascal,能够为很多不同的机器生成机器码。
可执行目标文件可以直接在机器上执行。一般而言,先执行一些初始化的工作;找到 main 函数的入口,执行用户写的代码;执行完成后,main 函数退出;再执行一些收尾的工作,整个过程完毕。
在接下来的文章里,我们将探索编译和运行的过程。
编译链接概述
Go 源码里的编译器源码位于 src/cmd/compile 路径下,链接器源码位于 src/cmd/link 路径下。
编译过程
我比较喜欢用 IDE(集成开发环境)来写代码, Go 源码用的 Goland,有时候直接点击 IDE 菜单栏里的“运行”按钮,程序就跑起来了。这实际上隐含了编译和链接的过程,我们通常将编译和链接合并到一起的过程称为构建(Build)。
编译过程就是对源文件进行词法分析、语法分析、语义分析、优化,最后生成汇编代码文件,以 .s 作为文件后缀。
之后,汇编器会将汇编代码转变成机器可以执行的指令。由于每一条汇编语句几乎都与一条机器指令相对应,所以只是一个简单的一一对应,比较简单,没有语法、语义分析,也没有优化这些步骤。
编译器是将高级语言翻译成机器语言的一个工具,编译过程一般分为 6 步:扫描、语法分析、语义分析、源代码优化、代码生成、目标代码优化。下图来自《程序员的自我修养》:

词法分析
通过前面的例子,我们知道,Go 程序文件在机器看来不过是一堆二进制位。我们能读懂,是因为 Goland 按照 ASCII 码(实际上是 UTF-8)把这堆二进制位进行了编码。例如,把 8个 bit 位分成一组,对应一个字符,通过对照 ASCII 码表就可以查出来。
当把所有的二进制位都对应成了 ASCII 码字符后,我们就能看到有意义的字符串。它可能是关键字,例如:package;可能是字符串,例如:“Hello World”。
词法分析其实干的就是这个。输入是原始的 Go 程序文件,在词法分析器看来,就是一堆二进制位,根本不知道是什么东西,经过它的分析后,变成有意义的记号。简单来说,词法分析是计算机科学中将字符序列转换为标记(token)序列的过程。
我们来看一下维基百科上给出的定义:
词法分析(lexical analysis)是计算机科学中将字符序列转换为标记(token)序列的过程。进行词法分析的程序或者函数叫作词法分析器(lexical analyzer,简称lexer),也叫扫描器(scanner)。词法分析器一般以函数的形式存在,供语法分析器调用。
.go 文件被输入到扫描器(Scanner),它使用一种类似于有限状态机的算法,将源代码的字符系列分割成一系列的记号(Token)。
记号一般分为这几类:关键字、标识符、字面量(包含数字、字符串)、特殊符号(如加号、等号)。
例如,对于如下的代码:
slice[i] = i * (2 + 6)
总共包含 16 个非空字符,经过扫描后,
| 记号 | 类型 |
|---|---|
| slice | 标识符 |
| [ | 左方括号 |
| i | 标识符 |
| ] | 右方括号 |
| = | 赋值 |
| i | 标识符 |
| * | 乘号 |
| ( | 左圆括号 |
| 2 | 数字 |
| + | 加号 |
| 6 | 数字 |
| ) | 右圆括号 |
上面的例子源自《程序员的自我修养》,主要讲解编译、链接相关的内容,很精彩,推荐研读。
Go 语言(本文的 Go 版本是 1.9.2)扫描器支持的 Token 在源码中的路径:
src/cmd/compile/internal/syntax/token.go
感受一下:
var tokstrings = [...]string{
// source control
_EOF: "EOF",
// names and literals
_Name: "name",
_Literal: "literal",
// operators and operations
_Operator: "op",
_AssignOp: "op=",
_IncOp: "opop",
_Assign: "=",
_Define: ":=",
_Arrow: "<-",
_Star: "*",
// delimitors
_Lparen: "(",
_Lbrack: "[",
_Lbrace: "{",
_Rparen: ")",
_Rbrack: "]",
_Rbrace: "}",
_Comma: ",",
_Semi: ";",
_Colon: ":",
_Dot: ".",
_DotDotDot: "...",
// keywords
_Break: "break",
_Case: "case",
_Chan: "chan",
_Const: "const",
_Continue: "continue",
_Default: "default",
_Defer: "defer",
_Else: "else",
_Fallthrough: "fallthrough",
_For: "for",
_Func: "func",
_Go: "go",
_Goto: "goto",
_If: "if",
_Import: "import",
_Interface: "interface",
_Map: "map",
_Package: "package",
_Range: "range",
_Return: "return",
_Select: "select",
_Struct: "struct",
_Switch: "switch",
_Type: "type",
_Var: "var",
}
还是比较熟悉的,包括名称和字面量、操作符、分隔符和关键字。
而扫描器的路径是:
src/cmd/compile/internal/syntax/scanner.go
其中最关键的函数就是 next 函数,它不断地读取下一个字符(不是下一个字节,因为 Go 语言支持 Unicode 编码,并不是像我们前面举得 ASCII 码的例子,一个字符只有一个字节),直到这些字符可以构成一个 Token。
func (s *scanner) next() {
// ……
redo:
// skip white space
c := s.getr()
for c == ' ' || c == '\t' || c == '\n' && !nlsemi || c == '\r' {
c = s.getr()
}
// token start
s.line, s.col = s.source.line0, s.source.col0
if isLetter(c) || c >= utf8.RuneSelf && s.isIdentRune(c, true) {
s.ident()
return
}
switch c {
// ……
case '\n':
s.lit = "newline"
s.tok = _Semi
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9':
s.number(c)
// ……
default:
s.tok = 0
s.error(fmt.Sprintf("invalid character %#U", c))
goto redo
return
assignop:
if c == '=' {
s.tok = _AssignOp
return
}
s.ungetr()
s.tok = _Operator
}
代码的主要逻辑就是通过 c := s.getr() 获取下一个未被解析的字符,并且会跳过之后的空格、回车、换行、tab 字符,然后进入一个大的 switch-case 语句,匹配各种不同的情形,最终可以解析出一个 Token,并且把相关的行、列数字记录下来,这样就完成一次解析过程。
当前包中的词法分析器 scanner 也只是为上层提供了 next 方法,词法解析的过程都是惰性的,只有在上层的解析器需要时才会调用 next 获取最新的 Token。
语法分析
上一步生成的 Token 序列,需要经过进一步处理,生成一棵以表达式为结点的语法树。
比如最开始的那个例子,slice[i] = i * (2 + 6),得到的一棵语法树如下:

整个语句被看作是一个赋值表达式,左子树是一个数组表达式,右子树是一个乘法表达式;数组表达式由 2 个符号表达式组成;乘号表达式则是由一个符号表达式和一个加号表达式组成;加号表达式则是由两个数字组成。符号和数字是最小的表达式,它们不能再被分解,通常作为树的叶子节点。
语法分析的过程可以检测一些形式上的错误,例如:括号是否缺少一半,+ 号表达式缺少一个操作数等。
语法分析是根据某种特定的形式文法(Grammar)对 Token 序列构成的输入文本进行分析并确定其语法结构的一种过程。
语义分析
语法分析完成后,我们并不知道语句的具体意义是什么。像上面的 * 号的两棵子树如果是两个指针,这是不合法的,但语法分析检测不出来,语义分析就是干这个事。
编译期所能检查的是静态语义,可以认为这是在“代码”阶段,包括变量类型的匹配、转换等。例如,将一个浮点值赋给一个指针变量的时候,明显的类型不匹配,就会报编译错误。而对于运行期间才会出现的错误:不小心除了一个 0 ,语义分析是没办法检测的。
语义分析阶段完成之后,会在每个节点上标注上类型:

Go 语言编译器在这一阶段检查常量、类型、函数声明以及变量赋值语句的类型,然后检查哈希中键的类型。实现类型检查的函数通常都是几千行的巨型 switch/case 语句。
类型检查是 Go 语言编译的第二个阶段,在词法和语法分析之后我们得到了每个文件对应的抽象语法树,随后的类型检查会遍历抽象语法树中的节点,对每个节点的类型进行检验,找出其中存在的语法错误。
在这个过程中也可能会对抽象语法树进行改写,这不仅能够去除一些不会被执行的代码对编译进行优化提高执行效率,而且也会修改 make、new 等关键字对应节点的操作类型。
例如比较常用的 make 关键字,用它可以创建各种类型,如 slice,map,channel 等等。到这一步的时候,对于 make 关键字,也就是 OMAKE 节点,会先检查它的参数类型,根据类型的不同,进入相应的分支。如果参数类型是 slice,就会进入 TSLICE case 分支,检查 len 和 cap 是否满足要求,如 len <= cap。最后节点类型会从 OMAKE 改成 OMAKESLICE。
中间代码生成
我们知道,编译过程一般可以分为前端和后端,前端生成和平台无关的中间代码,后端会针对不同的平台,生成不同的机器码。
前面词法分析、语法分析、语义分析等都属于编译器前端,之后的阶段属于编译器后端。
编译过程有很多优化的环节,在这个环节是指源代码级别的优化。它将语法树转换成中间代码,它是语法树的顺序表示。
中间代码一般和目标机器以及运行时环境无关,它有几种常见的形式:三地址码、P-代码。例如,最基本的三地址码是这样的:
x = y op z
表示变量 y 和 变量 z 进行 op 操作后,赋值给 x。op 可以是数学运算,例如加减乘除。
前面我们举的例子可以写成如下的形式:
t1 = 2 + 6
t2 = i * t1
slice[i] = t2
这里 2 + 6 是可以直接计算出来的,这样就把 t1 这个临时变量“优化”掉了,而且 t1 变量可以重复利用,因此 t2 也可以“优化”掉。优化之后:
t1 = i * 8
slice[i] = t1
Go 语言的中间代码表示形式为 SSA(Static Single-Assignment,静态单赋值),之所以称之为单赋值,是因为每个名字在 SSA 中仅被赋值一次。。
这一阶段会根据 CPU 的架构设置相应的用于生成中间代码的变量,例如编译器使用的指针和寄存器的大小、可用寄存器列表等。中间代码生成和机器码生成这两部分会共享相同的设置。
在生成中间代码之前,会对抽象语法树中节点的一些元素进行替换。这里引用《面向信仰编程》编译原理相关博客里的一张图:

例如对于 map 的操作 m[i],在这里会被转换成 mapacess 或 mapassign。
Go 语言的主程序在执行时会调用 runtime 中的函数,也就是说关键字和内置函数的功能其实是由语言的编译器和运行时共同完成的。
中间代码的生成过程其实就是从 AST 抽象语法树到 SSA 中间代码的转换过程,在这期间会对语法树中的关键字在进行一次更新,更新后的语法树会经过多轮处理转变最后的 SSA 中间代码。
目标代码生成与优化
不同机器的机器字长、寄存器等等都不一样,意味着在不同机器上跑的机器码是不一样的。最后一步的目的就是要生成能在不同 CPU 架构上运行的代码。
为了榨干机器的每一滴油水,目标代码优化器会对一些指令进行优化,例如使用移位指令代替乘法指令等。
这块实在没能力深入,幸好也不需要深入。对于应用层的软件开发工程师来说,了解一下就可以了。
链接过程
编译过程是针对单个文件进行的,文件与文件之间不可避免地要引用定义在其他模块的全局变量或者函数,这些变量或函数的地址只有在此阶段才能确定。
链接过程就是要把编译器生成的一个个目标文件链接成可执行文件。最终得到的文件是分成各种段的,比如数据段、代码段、BSS段等等,运行时会被装载到内存中。各个段具有不同的读写、执行属性,保护了程序的安全运行。
这部分内容,推荐看《程序员的自我修养》和《深入理解计算机系统》。
Go 程序启动
仍然使用 hello-world 项目的例子。在项目根目录下执行:
go build -gcflags "-N -l" -o hello src/main.go
-gcflags "-N -l" 是为了关闭编译器优化和函数内联,防止后面在设置断点的时候找不到相对应的代码位置。
得到了可执行文件 hello,执行:
[qcrao@qcrao hello-world]$ gdb hello
进入 gdb 调试模式,执行 info files,得到可执行文件的文件头,列出了各种段:

同时,我们也得到了入口地址:0x450e20。
(gdb) b *0x450e20
Breakpoint 1 at 0x450e20: file /usr/local/go/src/runtime/rt0_linux_amd64.s, line 8.
这就是 Go 程序的入口地址,我是在 linux 上运行的,所以入口文件为 src/runtime/rt0_linux_amd64.s,runtime 目录下有各种不同名称的程序入口文件,支持各种操作系统和架构,代码为:
TEXT _rt0_amd64_linux(SB),NOSPLIT,$-8
LEAQ 8(SP), SI // argv
MOVQ 0(SP), DI // argc
MOVQ $main(SB), AX
JMP AX
主要是把 argc,argv 从内存拉到了寄存器。这里 LEAQ 是计算内存地址,然后把内存地址本身放进寄存器里,也就是把 argv 的地址放到了 SI 寄存器中。最后跳转到:
TEXT main(SB),NOSPLIT,$-8
MOVQ $runtime·rt0_go(SB), AX
JMP AX
继续跳转到 runtime·rt0_go(SB),位置:/usr/local/go/src/runtime/asm_amd64.s,代码:
TEXT runtime·rt0_go(SB),NOSPLIT,$0
// 省略很多 CPU 相关的特性标志位检查的代码
// 主要是看不懂,^_^
// ………………………………
// 下面是最后调用的一些函数,比较重要
// 初始化执行文件的绝对路径
CALL runtime·args(SB)
// 初始化 CPU 个数和内存页大小
CALL runtime·osinit(SB)
// 初始化命令行参数、环境变量、gc、栈空间、内存管理、所有 P 实例、HASH算法等
CALL runtime·schedinit(SB)
// 要在 main goroutine 上运行的函数
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
PUSHQ $0 // arg size
// 新建一个 goroutine,该 goroutine 绑定 runtime.main,放在 P 的本地队列,等待调度
CALL runtime·newproc(SB)
POPQ AX
POPQ AX
// 启动M,开始调度goroutine
CALL runtime·mstart(SB)
MOVL $0xf1, 0xf1 // crash
RET
DATA runtime·mainPC+0(SB)/8,$runtime·main(SB)
GLOBL runtime·mainPC(SB),RODATA,$8
参考文献里的一篇文章【探索 golang 程序启动过程】研究得比较深入,总结下:
- 检查运行平台的CPU,设置好程序运行需要相关标志。
- TLS的初始化。
- runtime.args、runtime.osinit、runtime.schedinit 三个方法做好程序运行需要的各种变量与调度器。
- runtime.newproc创建新的goroutine用于绑定用户写的main方法。
- runtime.mstart开始goroutine的调度。
最后用一张图来总结 go bootstrap 过程吧:
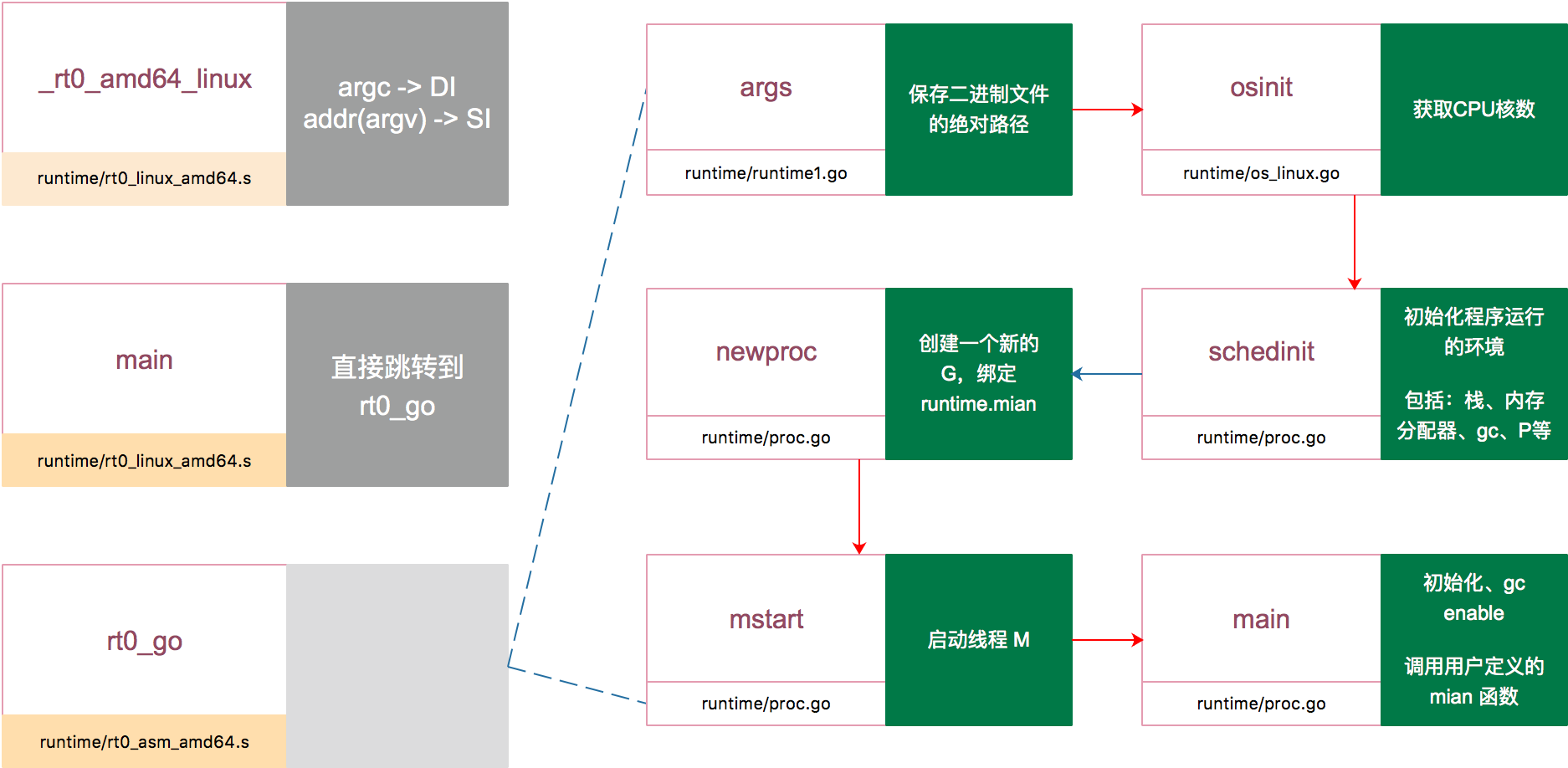
main 函数里执行的一些重要的操作包括:新建一个线程执行 sysmon 函数,定期垃圾回收和调度抢占;启动 gc;执行所有的 init 函数等等。
上面是启动过程,看一下退出过程:
当 main 函数执行结束之后,会执行 exit(0) 来退出进程。若执行 exit(0) 后,进程没有退出,main 函数最后的代码会一直访问非法地址:
exit(0)
for {
var x *int32
*x = 0
}
正常情况下,一旦出现非法地址访问,系统会把进程杀死,用这样的方法确保进程退出。
关于程序退出这一段的阐述来自群聊《golang runtime 阅读》,又是一个高阶的读源码的组织,github 主页见参考资料。
当然 Go 程序启动这一部分其实还会涉及到 fork 一个新进程、装载可执行文件,控制权转移等问题。还是推荐看前面的两本书,我觉得我不会写得更好,就不叙述了。
GoRoot 和 GoPath
GoRoot 是 Go 的安装路径。mac 或 unix 是在 /usr/local/go 路径上,来看下这里都装了些什么:

bin 目录下面:

pkg 目录下面:
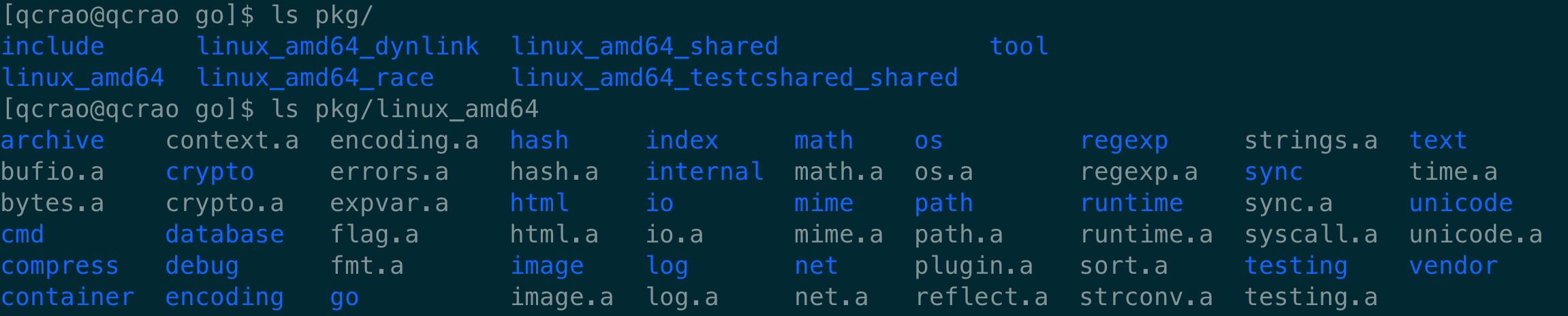
Go 工具目录如下,其中比较重要的有编译器 compile,链接器 link:

GoPath 的作用在于提供一个可以寻找 .go 源码的路径,它是一个工作空间的概念,可以设置多个目录。Go 官方要求,GoPath 下面需要包含三个文件夹:
src
pkg
bin
src 存放源文件,pkg 存放源文件编译后的库文件,后缀为 .a;bin 则存放可执行文件。
Go 命令详解
直接在终端执行:
go
就能得到和 go 相关的命令简介:

和编译相关的命令主要是:
go build
go install
go run
go build
go build 用来编译指定 packages 里的源码文件以及它们的依赖包,编译的时候会到 $GoPath/src/package 路径下寻找源码文件。go build 还可以直接编译指定的源码文件,并且可以同时指定多个。
通过执行 go help build 命令得到 go build 的使用方法:
usage: go build [-o output] [-i] [build flags] [packages]
-o 只能在编译单个包的时候出现,它指定输出的可执行文件的名字。
-i 会安装编译目标所依赖的包,安装是指生成与代码包相对应的 .a 文件,即静态库文件(后面要参与链接),并且放置到当前工作区的 pkg 目录下,且库文件的目录层级和源码层级一致。
至于 build flags 参数,build, clean, get, install, list, run, test 这些命令会共用一套:
| 参数 | 作用 |
|---|---|
| -a | 强制重新编译所有涉及到的包,包括标准库中的代码包,这会重写 /usr/local/go 目录下的 .a 文件 |
| -n | 打印命令执行过程,不真正执行 |
| -p n | 指定编译过程中命令执行的并行数,n 默认为 CPU 核数 |
| -race | 检测并报告程序中的数据竞争问题 |
| -v | 打印命令执行过程中所涉及到的代码包名称 |
| -x | 打印命令执行过程中所涉及到的命令,并执行 |
| -work | 打印编译过程中的临时文件夹。通常情况下,编译完成后会被删除 |
我们知道,Go 语言的源码文件分为三类:命令源码、库源码、测试源码。
命令源码文件:是 Go 程序的入口,包含
func main()函数,且第一行用package main声明属于 main 包。
库源码文件:主要是各种函数、接口等,例如工具类的函数。
测试源码文件:以
_test.go为后缀的文件,用于测试程序的功能和性能。
注意,go build 会忽略 *_test.go 文件。
我们通过一个很简单的例子来演示 go build 命令。我用 Goland 新建了一个 hello-world 项目(为了展示引用自定义的包,和之前的 hello-world 程序不同),项目的结构如下:
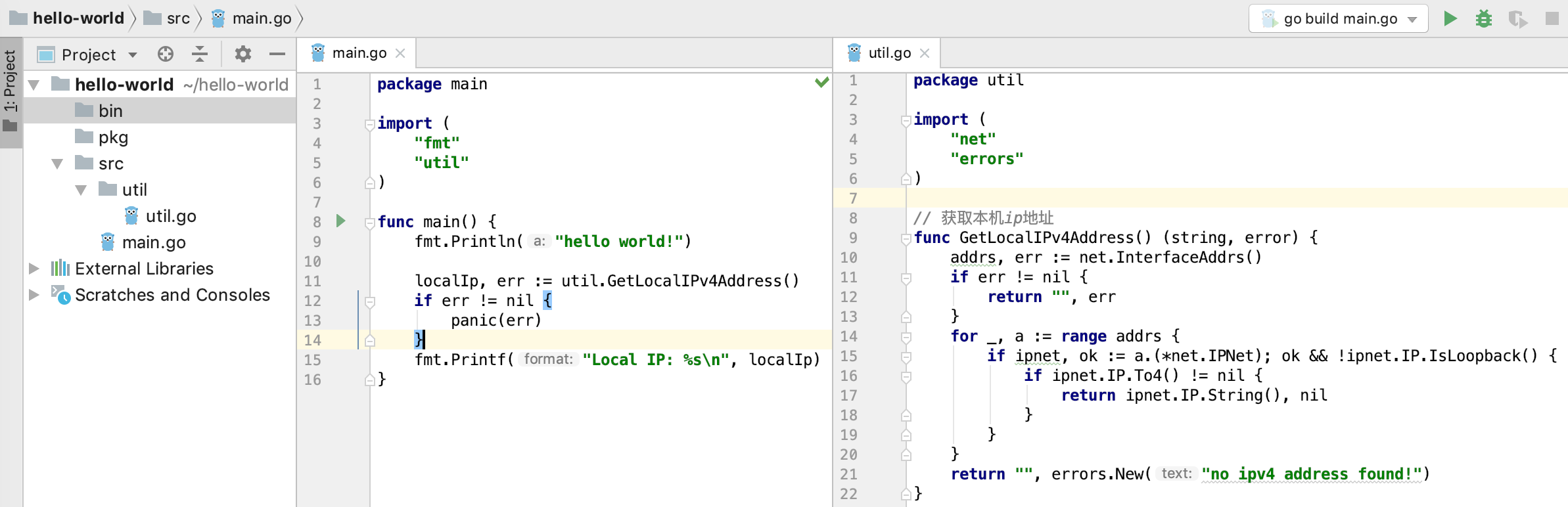
最左边可以看到项目的结构,包含三个文件夹:bin,pkg,src。其中 src 目录下有一个 main.go,里面定义了 main 函数,是整个项目的入口,也就是前面提过的所谓的命令源码文件;src 目录下还有一个 util 目录,里面有 util.go 文件,定义了一个可以获取本机 IP 地址的函数,也就是所谓的库源码文件。
中间是 main.go 的源码,引用了两个包,一个是标准库的 fmt;一个是 util 包,util 的导入路径是 util。所谓的导入路径是指相对于 Go 的源码目录 $GoRoot/src 或者 $GoPath/src 的下的子路径。例如 main 包里引用的 fmt 的源码路径是 /usr/local/go/src/fmt,而 util 的源码路径是 /Users/qcrao/hello-world/src/util,正好我们设置的 GoPath = /Users/qcrao/hello-world。
最右边是库函数的源码,实现了获取本机 IP 的函数。
在 src 目录下,直接执行 go build 命令,在同级目录生成了一个可执行文件,文件名为 src,使用 ./src 命令直接执行,输出:
hello world!
Local IP: 192.168.1.3
我们也可以指定生成的可执行文件的名称:
go build -o bin/hello
这样,在 bin 目录下会生成一个可执行文件,运行结果和上面的 src 一样。
其实,util 包可以单独被编译。我们可以在项目根目录下执行:
go build util
编译程序会去 $GoPath/src 路径找 util 包(其实是找文件夹)。还可以在 ./src/util 目录下直接执行 go build 编译。
当然,直接编译库源码文件不会生成 .a 文件,因为:
go build 命令在编译只包含库源码文件的代码包(或者同时编译多个代码包)时,只会做检查性的编译,而不会输出任何结果文件。
为了展示整个编译链接的运行过程,我们在项目根目录执行如下的命令:
go build -v -x -work -o bin/hello src/main.go
-v 会打印所编译过的包名字,-x 打印编译期间所执行的命令,-work 打印编译期间生成的临时文件路径,并且编译完成之后不会被删除。
执行结果:
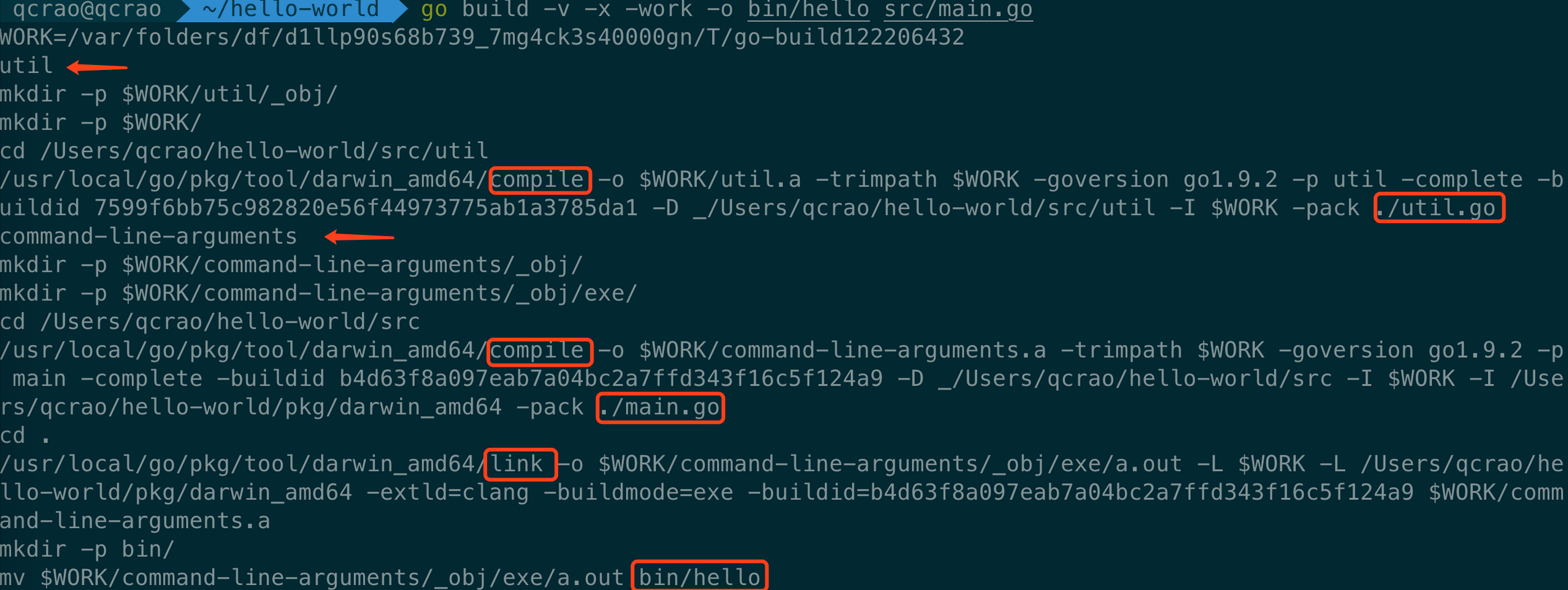
从结果来看,图中用箭头标注了本次编译过程涉及 2 个包:util,command-line-arguments。第二个包比较诡异,源码里根本就没有这个名字好吗?其实这是 go build 命令检测到 [packages] 处填的是一个 .go 文件,因此创建了一个虚拟的包:command-line-arguments。
同时,用红框圈出了 compile, link,也就是先编译了 util 包和 main.go 文件,分别得到 .a 文件,之后将两者进行链接,最终生成可执行文件,并且移动到 bin 目录下,改名为 hello。
另外,第一行显示了编译过程中的工作目录,此目录的文件结构是:
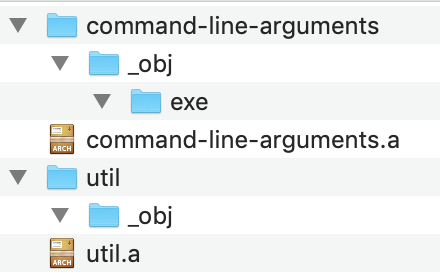
可以看到,和 hello-world 目录的层级基本一致。command-line-arguments 就是虚拟的 main.go 文件所处的包。exe 目录下的可执行文件在最后一步被移动到了 bin 目录下,所以这里是空的。
整体来看,go build 在执行时,会先递归寻找 main.go 所依赖的包,以及依赖的依赖,直至最底层的包。这里可以是深度优先遍历也可以是宽度优先遍历。如果发现有循环依赖,就会直接退出,这也是经常会发生的循环引用编译错误。
正常情况下,这些依赖关系会形成一棵倒着生长的树,树根在最上面,就是 main.go 文件,最下面是没有任何其他依赖的包。编译器会从最左的节点所代表的包开始挨个编译,完成之后,再去编译上一层的包。
这里,引用郝林老师几年前在 github 上发表的 go 命令教程,可以从参考资料找到原文地址。
从代码包编译的角度来说,如果代码包 A 依赖代码包 B,则称代码包 B 是代码包 A 的依赖代码包(以下简称依赖包),代码包 A 是代码包 B 的触发代码包(以下简称触发包)。
执行
go build命令的计算机如果拥有多个逻辑 CPU 核心,那么编译代码包的顺序可能会存在一些不确定性。但是,它一定会满足这样的约束条件:依赖代码包 -> 当前代码包 -> 触发代码包。
顺便推荐一个浏览器插件 Octotree,在看 github 项目的时候,此插件可以在浏览器里直接展示整个项目的文件结构,非常方便:

到这里,你一定会发现,对于 hello-wrold 文件夹下的 pkg 目录好像一直没有涉及到。
其实,pkg 目录下面应该存放的是涉及到的库文件编译后的包,也就是一些 .a 文件。但是 go build 执行过程中,这些 .a 文件放在临时文件夹中,编译完成后会被直接删掉,因此一般不会用到。
前面我们提到过,在 go build 命令里加上 -i 参数会安装这些库文件编译的包,也就是这些 .a 文件会放到 pkg 目录下。
在项目根目录执行 go build -i src/main.go 后,pkg 目录里增加了 util.a 文件:

darwin_amd64 表示的是:
GOOS 和 GOARCH。这两个环境变量不用我们设置,系统默认的。
GOOS 是 Go 所在的操作系统类型,GOARCH 是 Go 所在的计算架构。
Mac 平台上这个目录名就是 darwin_amd64。
生成了 util.a 文件后,再次编译的时候,就不会再重新编译 util.go 文件,加快了编译速度。
同时,在根目录下生成了名称为 main 的可执行文件,这是以 main.go 的文件名命令的。
hello-world 这个项目的代码已经上传到了 github 项目 Go-Questions,这个项目由问题导入,企图串连 Go 的所有知识点,正在完善,期待你的 star。 地址见参考资料【Go-Questions hello-world项目】。
go install
go install 用于编译并安装指定的代码包及它们的依赖包。相比 go build,它只是多了一个“安装编译后的结果文件到指定目录”的步骤。
还是使用之前 hello-world 项目的例子,我们先将 pkg 目录删掉,在项目根目录执行:
go install src/main.go
或者
go install util
两者都会在根目录下新建一个 pkg 目录,并且生成一个 util.a 文件。
并且,在执行前者的时候,会在 GOBIN 目录下生成名为 main 的可执行文件。
所以,运行 go install 命令,库源码包对应的 .a 文件会被放置到 pkg 目录下,命令源码包生成的可执行文件会被放到 GOBIN 目录。
go install 在 GoPath 有多个目录的时候,会产生一些问题,具体可以去看郝林老师的 Go 命令教程,这里不展开了。
go run
go run 用于编译并运行命令源码文件。
在 hello-world 项目的根目录,执行 go run 命令:
go run -x -work src/main.go
-x 可以打印整个过程涉及到的命令,-work 可以看到临时的工作目录:

从上图中可以看到,仍然是先编译,再连接,最后直接执行,并打印出了执行结果。
第一行打印的就是工作目录,最终生成的可执行文件就是放置于此:

main 就是最终生成的可执行文件。
总结
这次的话题太大了,困难重重。从编译原理到 go 启动时的流程,到 go 命令原理,每个话题单独抽出来都可以写很多。
幸好有一些很不错的书和博客文章可以去参考。这篇文章就作为一个引子,你可以跟随参考资料里推荐的一些内容去发散。
参考资料
【《程序员的自我修养》全书】https://book.douban.com/subject/3652388/
【面向信仰编程 编译过程概述】https://draveness.me/golang-compile-intro
【golang runtime 阅读】https://github.com/zboya/golang_runtime_reading
【Go-Questions hello-world项目】https://github.com/qcrao/Go-Questions/tree/master/examples/hello-world
【雨痕大佬的 Go 语言学习笔记】https://github.com/qyuhen/book
【vim 以 16 进制文本】https://www.cnblogs.com/meibenjin/archive/2012/12/06/2806396.html
【Go 编译命令执行过程】https://halfrost.com/go_command/
【Go 命令执行过程】https://github.com/hyper0x/go_command_tutorial
【Go 词法分析】https://ggaaooppeenngg.github.io/zh-CN/2016/04/01/go-lexer-词法分析/
【曹大博客 golang 与 ast】http://xargin.com/ast/
【Golang 词法解析器,scanner 源码分析】https://blog.csdn.net/zhaoruixiang1111/article/details/89892435
【Gopath Explained】https://flaviocopes.com/go-gopath/
【Understanding the GOPATH】https://www.digitalocean.com/community/tutorials/understanding-the-gopath
【讨论】https://stackoverflow.com/questions/7970390/what-should-be-the-values-of-gopath-and-goroot
【Go 官方 Gopath】https://golang.org/cmd/go/#hdr-GOPATH_environment_variable
【Go package 的探索】https://mp.weixin.qq.com/s/OizVLXfZ6EC1jI-NL7HqeA
【Go 官方 关于 Go 项目的组织结构】https://golang.org/doc/code.html
【Go modules】https://www.melvinvivas.com/go-version-1-11-modules/
【Golang Installation, Setup, GOPATH, and Go Workspace】https://www.callicoder.com/golang-installation-setup-gopath-workspace/
【编译、链接过程链接】https://mikespook.com/2013/11/翻译-go-build-命令是如何工作的?/
【1.5 编译器由 go 语言完成】https://www.infoq.cn/article/2015/08/go-1-5
【Go 编译过程系列文章】https://www.ctolib.com/topics-3724.html
【曹大 go bootstrap】https://github.com/cch123/golang-notes/blob/master/bootstrap.md
【golang 启动流程】https://blog.iceinto.com/posts/go/start/
【探索 golang 程序启动过程】http://cbsheng.github.io/posts/探索golang程序启动过程/
【探索 goroutine 的创建】http://cbsheng.github.io/posts/探索goroutine的创建/

Go 程序是怎样跑起来的的更多相关文章
- 微信小程序里实现跑马灯效果
在微信小程序 里实现跑马灯效果,类似滚动字幕或者滚动广告之类的,使用简单的CSS样式控制,没用到JS wxml: <!-- 复制的跑马灯效果 --> <view class=&quo ...
- 微信小程序实现文字跑马灯
wxml: <view>1 显示完后再显示</view> <view class="example"> <view class=" ...
- 程序是怎么跑起来的? —— CPU 是什么?C/C++程序的运行
1. 概念初步 程序:计算机的程序,和做饭.运动会的程序一样,指的是"做事的先后次序": 程序的组成:程序是指令(及物动词)和数据(宾语)的组合体: C 语言 printf(&qu ...
- 《程序是怎样跑起来的》读书笔记——第一章 对程序员来说CPU是什么
1 程序的运行流程 2 CPU的组成 3 寄存器的主要种类和功能 "程序计数器"--决定程序流程的 4 条件分支和循环机制 4.1 顺序执行 4.2 选择分支 5 函数的调用机制 ...
- 微信小程序-实现文字跑马灯-wepy
百度蛮多例子的,但是代码太长懒得看了 前言 要实现跑马灯主要就是获得判断开始定界和结束定界, 1.9.3新增的wxml操作接口 就可以拿到节点长宽等属性,当然你也可以直接用 文字数量 * 文字大小(注 ...
- hadoop下跑mapreduce程序报错
mapreduce真的是门学问,遇到的问题逼着我把它从MRv1摸索到MRv2,从年前就牵挂在心里,连过年回家的旅途上都是心情凝重,今天终于在eclipse控制台看到了job completed suc ...
- 为你的Web程序加个启动画面
.Net开发者一定熟悉下面这个画面: 这就是宇宙第一IDE Visual Studio的启动画面,学名叫Splash Screen(或者Splash Window).同样,Javar们一定对Eclip ...
- 使用 CUDA范例精解通用GPU编程 配套程序的方法
用vs新建一个cuda的项目,然后将系统自动生成的那个.cu里头的内容,除了头文件引用外,全部替代成先有代码的内容. 然后程序就能跑了. 因为新建的是cuda的项目,所以所有的头文件和库的引用系统都会 ...
- Android入门(五):程序架构——MVC设计模式在Android中的应用
刚刚接触编程的的人,可能会这样认为:只要代码写完了能够跑起来就算完工了.如果只是写一个小程序,“能够跑起来”这样的标准也就可以了,但是如果你是在公司进行程序的开发,那么仅仅让程序成功的跑起来是不行的, ...
随机推荐
- CMake生成OpenCV解决方案&&编译OpenCV源码
生成OpenCV工程需要用到CMake,所以第一步需要下载CMake软件,下载链接:CMake下载 目前最新的版本是3.7.1,这里选择下载Platform下的Windows win32-x86 ZI ...
- 从DOS bat启动停止SQL Server (MSSQLSERVER)服务
由于机器上装了SQL Server2008,导致机器开机变慢,没办法只能让SQL Server (MSSQLSERVER) 服务默认不启动.但是每次要使用SQL Server时就必须从控制面板-管理 ...
- 基于WPF实现双色球
原文:基于WPF实现双色球 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/m0_37591671/article/details/82959625 ...
- objective-c启用ARC时的内存管理
PDF版下载:http://download.csdn.net/detail/cuibo1123/7443125 在objective-c中,内存的引用计数一直是一个让人比較头疼的问题.尤其 ...
- 从源码角度看MySQL memcached plugin——1. 系统结构和引擎初始化
本章尝试回答两个问题: 一.memcached plugin与MySQL的关系: 二.MySQL系统如何启动memcached plugin. 1. memcached plugin与MySQL的关系 ...
- 百度地图 Android SDK - 新的版本号(v3.2.0)正式上线
百度地图 Android SDK v3.2.0 在版本号 2014 年 11 月 07 日本正式推出工作完成! watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQ ...
- @RequestBody标记的形参,与APP接口不能直接用
用ajax请求传JSON串,在服务端形参用@RequestBody标记可以直接转为对应的对象: 在APP调用该接口时,服务端用@RequestBody标记无法转为对应对象,将形参改为String类型, ...
- 你所不知道的 Kindle - 阅读微信公众号文章
Kindle 是一款非常优秀的阅读设备,它为我们提供了非常舒服的阅读体验,并且配合强大的亚马逊图书资源,应该是目前最好的阅读设备之一.Kindle 在已有的成就下还一直在努力提升用户体验.为中国用户开 ...
- [转]Nodejs开发框架Express4.x开发手记
Express: ?web application framework for?Node.js? Express 是一个简洁.灵活的 node.js Web 应用开发框架, 它提供一系列强大的特性,帮 ...
- 属性更改通知(INotifyPropertyChanged)——针对ObservableCollection
问题 在开发webform中,wpf中的ObservableCollection<T>,MSDN中说,在添加项,移除项时此集合通知控件,我们知道对一个集合的操作是CURD但是恰恰没有Upd ...