k-means实战-RFM客户价值分群
数据挖掘的十大算法

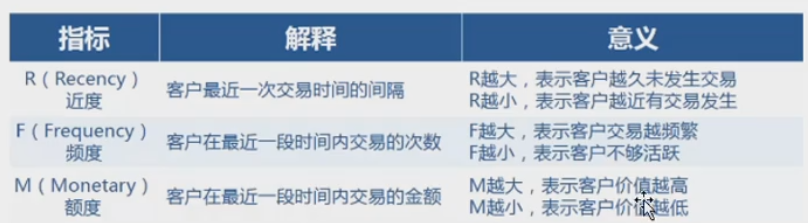
基本概念

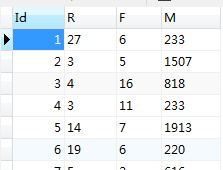
1、数据预处理:处理成 用户ID,R ,F,M四个字段
2、调用KMeans算法 进行聚类 ,设定为8类
3、对数据进行拟合,训练模型 ,每个ID对应一个类别(0-7)
4、如何将分类好的数字标签,和RFM 模型中的客户类别匹配起来?
查看每个类别的中心点,用其构造Dataframe来代表整个数据集
查看每个类别的中心点:clf.cluster_centers_
"""分别计算每个属性值的中位数,代表整个属性的中位水平"""
rmd = r['R'].median()
fmd = r['F'].median()
mmd = r['M'].median()
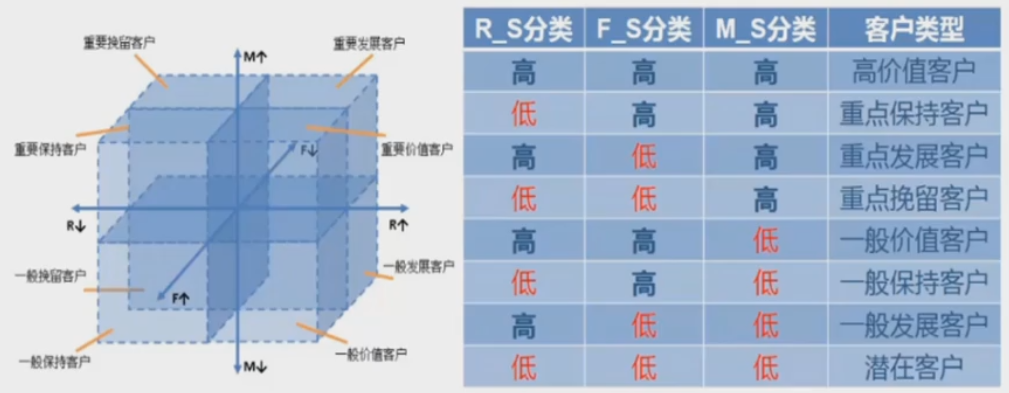
然后对8行3列数据进行判断,对8类数据进行客户类别标签
5、对整个数据集贴上标签
标签0-7和客户类型一一对应 数据集:

导入数据集到mysql数据库中
总共有940个独立消费数据
无监督算法:
K-Means 算法
K-Means 算法是一个聚类算法。你可以这么理解,最终我想把物体划分成 K 类。假设每
个类别里面,都有个“中心点”,即意见领袖,它是这个类别的核心。现在我有一个新点
要归类,这时候就只要计算这个新点与 K 个中心点的距离,距离哪个中心点近,就变成了
哪个类别。
引入模块
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
import pymysql
连接数据库:
conn = pymysql.connect(host='localhost',user='root',password='',db='db2',port=3306)
rfm = pd.read_sql('select * from consumption_data',con=conn)
conn.close()
查看详情:
rfm.info()
rfm.head()
"""选取RFM 三列"""
new_rfm = rfm.loc[:,['R','F','M']]
"""调用KMeans算法 进行聚类 ,设定为8类"""
clf = KMeans(n_clusters=8,random_state=0)
"""对数据进行拟合,训练模型"""
clf.fit(new_rfm)
"""查看一下分类的结果,返回的数组中每个数字对应了rfm中每一行"""
print(len(clf.labels_))
se = pd.Series(clf.labels_)
se.value_counts()

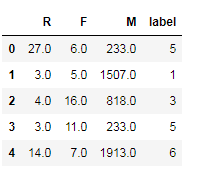
new_rfm['label']=clf.labels_
new_rfm.head()
"""如何将分类好的数字标签,和RFM 模型中的客户类别匹配起来?"""
"""查看每个类别的中心点,用其构造Dataframe来代表整个数据集"""
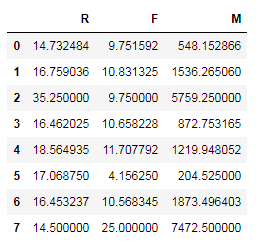
查看每个类别的中心点:clf.cluster_centers_ 8行3列

r = pd.DataFrame(clf.cluster_centers_,columns=['R','F','M'])
print(r) 每个类别的中心点0-7共8类
"""分别计算每个属性值的中位数,代表整个属性的中位水平"""
rmd = r['R'].median()
fmd = r['F'].median()
mmd = r['M'].median()
cluster=[]
for i in range(len(r)):
if r.iloc[i,0] > rmd and r.iloc[i,1] >fmd and r.iloc[i,2] >mmd:
cluster.append('高价值客户')
elif r.iloc[i,0] < rmd and r.iloc[i,1] > fmd and r.iloc[i,2] >mmd:
cluster.append('重点保持客户')
elif r.iloc[i,0] > rmd and r.iloc[i,1] < fmd and r.iloc[i,2] >mmd:
cluster.append('重点发展客户')
elif r.iloc[i,0] < rmd and r.iloc[i,1] < fmd and r.iloc[i,2] > mmd:
cluster.append('重点挽留客户')
elif r.iloc[i,0] > rmd and r.iloc[i,1] > fmd and r.iloc[i,2] < mmd:
cluster.append('一般价值客户')
elif r.iloc[i,0] < rmd and r.iloc[i,1] > fmd and r.iloc[i,2] < mmd:
cluster.append('一般保持客户')
elif r.iloc[i,0] > rmd and r.iloc[i,1] < fmd and r.iloc[i,2] < mmd:
cluster.append('一般发展客户')
else:
cluster.append('潜在客户')
cluster

"""将贴好的标签,匹配到每一行数据"""
r['客户分类']=cluster
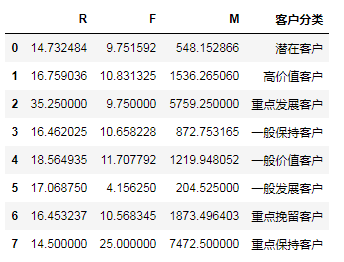
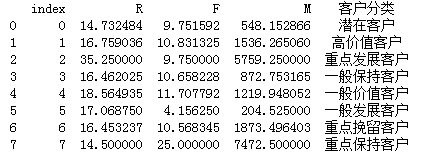
s = r.reset_index()
print(s)
new_rfm.head()
标签0-7和客户类型一一对应 对整个数据集贴上标签 # result = pd.merge(new_rfm,r['客户分类'],how='inner',left_on='label',right_index=True)# 用右表的索引做连接键
result = pd.merge(new_rfm,s[['index','客户分类']],how='inner',left_on='label',right_on='index') result.sort_index()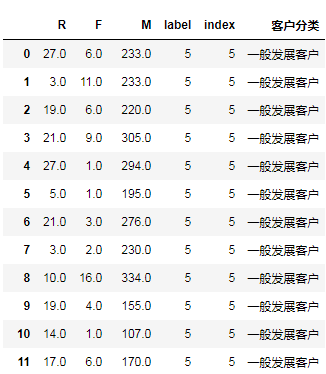
k-means实战-RFM客户价值分群的更多相关文章
- RFM客户价值分类
# 自定义好的包,亲测可用 原数据和代码思想来自以下网址 # https://github.com/joaolcorreia/RFM-analysis import datetime as dt im ...
- 客户主题分析(tableau)—客户分群
主要分析方面:客户合理分群 客户分群实现:使用聚类构建指标,需理解聚类的分析逻辑,需使用软件:tableau 聚类方法:选择3指标分别为购买总金额,客户购买次数.类平均购买价格(四类的平均购买价格,四 ...
- 数据分析之客户价值模型(RFM)技术总结
作者 | leo 管理学中有一个重要概念那就是客户关系管理(CRM),它核心目的就是为了提高企业的核心竞争力,通过提高企业与客户间的交互,优化客户管理方式,从而实现吸引新客户.保留老客户以及将已有客户 ...
- Python使用RMF聚类分析客户价值
投资机构或电商企业等积累的客户交易数据繁杂.需要根据用户的以往消费记录分析出不同用户群体的特征与价值,再针对不同群体提供不同的营销策略. 用户分析指标 根据美国数据库营销研究所Arthur Hughe ...
- 项目实战:负载均衡集群企业级应用实战—LVS详解
目录 一.负载均衡集群介绍 二.lvs 的介绍 三.LVS负载均衡四种工作模式 1.NAT工作模式 2.DR工作模式 3.TUN工作模式 4.full-nat 工作模式 5.四者的区别 四.LVS i ...
- Admixture的监督分群(Supervised analysis)
目录 说明 实战 说明 Admixture通过EM算法一般用于指定亚群分类:或者在不知材料群体结构背景下,通过迭代交叉验证获得error值,取最小error对应的K值为推荐亚群数目.如果我们预先已知群 ...
- python实现六大分群质量评估指标(兰德系数、互信息、轮廓系数)
python实现六大分群质量评估指标(兰德系数.互信息.轮廓系数) 1 R语言中的分群质量--轮廓系数 因为先前惯用R语言,那么来看看R语言中的分群质量评估,节选自笔记︱多种常见聚类模型以及分群质量评 ...
- 如何通过CRM评估客户价值和提高客户忠诚度?
随着市场经济的日益繁荣,同行业之间企业的竞争越来越激烈,企业纷纷各出奇招吸引和挖掘客户,力求让自己的品牌成为更多客户的第一选择.那么,我们可以用什么方法来评估客户价值,提高客户忠诚度呢? 在互联网时代 ...
- Tableau 分群
对数据的特征进行分析,分群. 数据选用的是Iris data 下载地址:http://archive.ics.uci.edu/ml/machine-learning-databases/iris/ 1 ...
随机推荐
- c语言文件
完整代码块展示: #include <stdio.h> #include <stdlib.h> #include <string.h> struct student ...
- shell通配符, 变量, shell作用域
1. 指定格式输出当前时间: echo `date +%Y%m%d` # 注意使用反引号, +号后面不要有空格 反引号中的东西会被当做命令来执行, 并输出执行的结果 2. $uid用于判断当前是否是 ...
- ClickHouse
ClickHouse 是俄罗斯的Yandex于2016年开源的列式存储数据库(DBMS),主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告 1 安装前的准备1.1 Cent ...
- PUT和POST区别
POST是用来提交数据的.提交的数据放在HTTP请求的正文里,目的在于提交数据并用于服务器端的存储,而不允许用户过多的更改相应数据(主要是相对于在url 修改要麻烦很多).PUT操作是幂等的.所谓幂等 ...
- 基于mysqld_multi实现MySQL 5.7.24多实例多进程配置
学习环境: 操作系统 IP地址 主机名 软件包 备注 CentOS7.5 192.168.200.111 localhost 实验初始配置:所有主机关闭防火墙与selinux [root@ ...
- 报错:Something is already running on port 8000.
在用react框架的时候,用cnpm run dev命令执行项目时,有时会出现这种错误, 这是因为你之前执行过该命令,但是没关闭,解决办法是打开任务管理器, 在进程中找到node.exe,右键关闭这个 ...
- event.stopPropagation()和event.preventDefault()
1.event.stopPropagation()方法 这是阻止事件的冒泡方法,不让事件向documen上蔓延,但是默认事件任然会执行,当你掉用这个方法的时候,如果点击一个连接,这个连接仍然会被打开, ...
- Update 19.11 for Azure Sphere
今天,微软发布了面向Azure Sphere的19.11更新,其主要亮点就是加入了对开发工具Visual Studio Code和Linux开发环境的支持.具体来讲,本次更新包含3个部分: 1. Az ...
- golang数据结构之双链表
目录结构: doubleLink.go package link import ( "fmt" ) //HerosNode 链表节点 type HerosNode struct { ...
- DirectShow 获取音视频输入设备列表
开发环境:Win10 + VS2015 本文介绍一个 "获取音频视频输入设备列表" 的示例代码. 效果图 代码下载 代码下载(VC2015):Github - DShow_simp ...