NLP(九) 文本相似度问题
原文链接:http://www.one2know.cn/nlp9/
- 多个维度判别文本之间相似度
- 情感维度 Sentiment/Emotion
- 感官维度 Sense
- 特定词的出现
- 词频 TF
逆文本频率 IDF
构建N个M维向量,N是文档总数,M是所有文档的去重词汇量 - 余弦相似度:
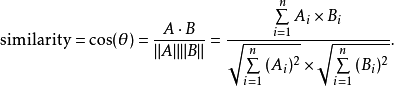
A,B分别是两个词的向量
import nltk
import math
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
class TextSimilarityExample:
def __init__(self):
self.statements = [ # 例句
'ruled india',
'Chalukyas ruled Badami',
'So many kingdoms ruled India',
'Lalbagh is a botanical garden in India',
]
def TF(self,sentence):
words = nltk.word_tokenize(sentence.lower()) # 分词,都化成小写
freq = nltk.FreqDist(words) # 计算词频分布,词和词频组成的字典
dictionary = {}
for key in freq.keys():
norm = freq[key] / float(len(words)) # 把词频正则化
dictionary[key] = norm
return dictionary # 返回 词:词频
def IDF(self):
def idf(TotalNumberOfDocuments,NumberOfDocumentsWithThisWord):
return 1.0 + math.log(TotalNumberOfDocuments/NumberOfDocumentsWithThisWord)
# idf = 1 + log(总文件数/含该词的文件数)
numDocuments = len(self.statements) # 总文档数
uniqueWords = {} # 不重复的 字典
idfValues = {} # 词:IDF 字典
for sentence in self.statements: # 得到每个句子的 词:含该词文章数量 字典
for word in nltk.word_tokenize(sentence.lower()):
if word not in uniqueWords:
uniqueWords[word] = 1
else:
uniqueWords[word] += 1
for word in uniqueWords: # 词:含该词文章数量 字典 => 词:IDF 字典
idfValues[word] = idf(numDocuments,uniqueWords[word])
return idfValues
def TF_IDF(self,query): # 返回每句话的向量
words = nltk.word_tokenize(query.lower())
idf = self.IDF() # IDF 由所有文档求出
vectors = {}
for sentence in self.statements: # 遍历所有句子
tf = self.TF(sentence) # TF 由单个句子得出
for word in words:
tfv = tf[word] if word in tf else 0.0
idfv = idf[word] if word in idf else 0.0
mul = tfv * idfv
if word not in vectors:
vectors[word] = []
vectors[word].append(mul) # 字典里添加元素7
return vectors
def displayVectors(self,vectors): # 显示向量内容
print(self.statements)
for word in vectors:
print("{} -> {}".format(word,vectors[word]))
def cosineSimilarity(self):
vec = TfidfVectorizer() # 创建新的向量对象
matrix = vec.fit_transform(self.statements) # 计算所有文本的TF-IDF值矩阵
for j in range(1,5):
i = j - 1
print("\tsimilarity of document {} with others".format(j))
similarity = cosine_similarity(matrix[i:j],matrix) # scikit库的余弦相似度函数
print(similarity)
def demo(self):
inputQuery = self.statements[0] # 第一个句子作为输入查询
vectors = self.TF_IDF(inputQuery) # 建立第一句的向量
self.displayVectors(vectors) # 屏幕上显示所有句子的TF×IDF向量
self.cosineSimilarity() # 计算输入句子与所有句子的余弦相似度
if __name__ == "__main__":
similarity = TextSimilarityExample()
similarity.demo()
输出:
['ruled india', 'Chalukyas ruled Badami', 'So many kingdoms ruled India', 'Lalbagh is a botanical garden in India']
ruled -> [0.6438410362258904, 0.42922735748392693, 0.2575364144903562, 0.0]
india -> [0.6438410362258904, 0.0, 0.2575364144903562, 0.18395458177882582]
similarity of document 1 with others
[[1. 0.29088811 0.46216171 0.19409143]]
similarity of document 2 with others
[[0.29088811 1. 0.13443735 0. ]]
similarity of document 3 with others
[[0.46216171 0.13443735 1. 0.08970163]]
similarity of document 4 with others
[[0.19409143 0. 0.08970163 1. ]]
NLP(九) 文本相似度问题的更多相关文章
- NLP点滴——文本相似度
[TOC] 前言 在自然语言处理过程中,经常会涉及到如何度量两个文本之间的相似性,我们都知道文本是一种高维的语义空间,如何对其进行抽象分解,从而能够站在数学角度去量化其相似性.而有了文本之间相似性的度 ...
- 【NLP】文本相似度
http://www.ruanyifeng.com/blog/2013/03/cosine_similarity.html
- 从0到1,了解NLP中的文本相似度
本文由云+社区发表 作者:netkiddy 导语 AI在2018年应该是互联网界最火的名词,没有之一.时间来到了9102年,也是项目相关,涉及到了一些AI写作相关的功能,为客户生成一些素材文章.但是, ...
- NLP文本相似度
NLP文本相似度 相似度 相似度度量:计算个体间相似程度 相似度值越小,距离越大,相似度值越大,距离越小 最常用--余弦相似度: 一个向量空间中两个向量夹角的余弦值作为衡量两个个体之间差异的大小 余 ...
- 【NLP】Python实例:基于文本相似度对申报项目进行查重设计
Python实例:申报项目查重系统设计与实现 作者:白宁超 2017年5月18日17:51:37 摘要:关于查重系统很多人并不陌生,无论本科还是硕博毕业都不可避免涉及论文查重问题,这也对学术不正之风起 ...
- NLP文本相似度(TF-IDF)
本篇博文是数据挖掘部分的首篇,思路主要是先聊聊相似度的理论部分,下一篇是代码实战. 我们在比较事物时,往往会用到“不同”,“一样”,“相似”等词语,这些词语背后都涉及到一个动作——双方的比 ...
- Finding Similar Items 文本相似度计算的算法——机器学习、词向量空间cosine、NLTK、diff、Levenshtein距离
http://infolab.stanford.edu/~ullman/mmds/ch3.pdf 汇总于此 还有这本书 http://www-nlp.stanford.edu/IR-book/ 里面有 ...
- TF-IDF 文本相似度分析
前阵子做了一些IT opreation analysis的research,从产线上取了一些J2EE server运行状态的数据(CPU,Menory...),打算通过训练JVM的数据来建立分类模型, ...
- 文本相似度算法——空间向量模型的余弦算法和TF-IDF
1.信息检索中的重要发明TF-IDF TF-IDF是一种统计方法,TF-IDF的主要思想是,如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分 ...
- 【机器学习】使用gensim 的 doc2vec 实现文本相似度检测
环境 Python3, gensim,jieba,numpy ,pandas 原理:文章转成向量,然后在计算两个向量的余弦值. Gensim gensim是一个python的自然语言处理库,能够将文档 ...
随机推荐
- get解决乱码的方式
//自定义的解决乱码方式
- 10w数组去重,排序,找最多出现次数(精华)
package cn.tedu.javaweb.test; import java.util.*; /* * @author XueWeiWei * @date 2019/6/11 8:19 */@S ...
- 脱壳系列_2_IAT加密壳_详细版解法1(含脚本)
1 查看壳程序信息 使用ExeInfoPe 分析: 发现这个壳的类型没有被识别出来,Vc 6.0倒是识别出来了,Vc 6.0的特征是 入口函数先调用GetVersion() 2 用OD找OEP 拖进O ...
- Hive映射HBase表的几种方式
1.Hive内部表,语句如下 CREATE TABLE ods.s01_buyer_calllogs_info_ts( key string comment "hbase rowkey&qu ...
- python协程详解
目录 python协程详解 一.什么是协程 二.了解协程的过程 1.yield工作原理 2.预激协程的装饰器 3.终止协程和异常处理 4.让协程返回值 5.yield from的使用 6.yield ...
- ContentProvider 使用详解
极力推荐文章:欢迎收藏 Android 干货分享 阅读五分钟,每日十点,和您一起终身学习,这里是程序员Android 本篇文章主要介绍 Android 开发中的部分知识点,通过阅读本篇文章,您将收获以 ...
- 使用 Docker 生成 Let’s Encrypt 证书
概念 什么是 Container ? https://www.docker.com/resources/what-container https://www.docker.com/why-docker ...
- hadoop安装解决之道
# 壹.故障现象 ```xml Microsoft Windows [版本 10.0.18362.239] (c) 2019 Microsoft Corporation.保留所有权利. C:\User ...
- 转载 | Sublime text3 实用快捷键整理
实用快捷键 Ctrl+Shift+P:打开命令面板Ctrl+P:搜索项目中的文件Ctrl+G:跳转到第几行Ctrl+W:关闭当前打开文件Ctrl+Shift+W:关闭所有打开文件Ctrl+Shift+ ...
- spring boot 打 war包
spring boot .spring cloud打 war包,并发布到tomcat中运行 1.pom文件修改 <packaging>war</packaging> 2.< ...