10-scrapy框架介绍
Scrapy 入门教程
Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。
Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
Scrapy架构图(绿线是数据流向)
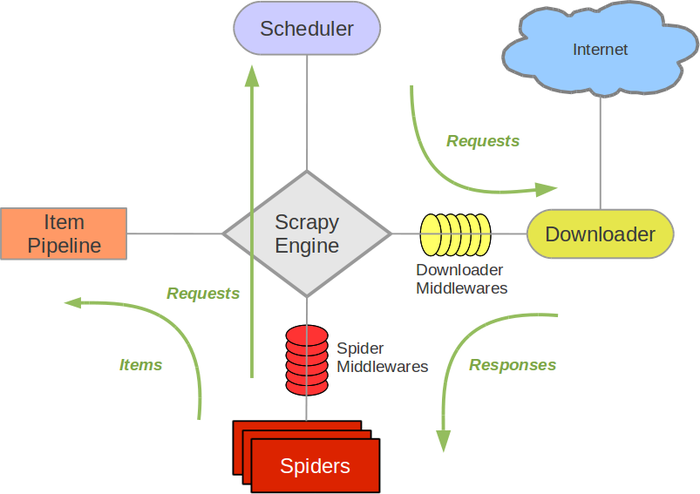
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器).
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
Scrapy的运作流程
代码写好,程序开始运行...
- 1 引擎:Hi!Spider, 你要处理哪一个网站?
- 2 Spider:老大要我处理xxxx.com。
- 3 引擎:你把第一个需要处理的URL给我吧。
- 4 Spider:给你,第一个URL是xxxxxxx.com。
- 5 引擎:Hi!调度器,我这有request请求你帮我排序入队一下。
- 6 调度器:好的,正在处理你等一下。
- 7 引擎:Hi!调度器,把你处理好的request请求给我。
- 8 调度器:给你,这是我处理好的request
- 9 引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求
- 10 下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)
- 11 引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)
- 12 Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
- 13 引擎:Hi !管道 我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
- 14 管道调度器:好的,现在就做!
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy也会重新下载。)
安装
Windows 安装方式
安装 Scrapy 框架步骤流程:
1、
- pip3 install wheel
2、
- 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/
- 进入下载目录,执行 pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl
- 备注(一定要下载对应的python版本号以及电脑的系统对应下载,否则安装不成功)
3、
- pip3 install pywin32
4、
- pip3 install scrapy
制作 Scrapy 爬虫 一共需要4步:
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
学习目标
- 创建一个Scrapy项目
- 定义提取的结构化数据(Item)
- 编写爬取网站的 Spider 并提取出结构化数据(Item)
- 编写 Item Pipelines 来存储提取到的Item(即结构化数据)
一. 新建项目(scrapy startproject)
在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令:
- scrapy startproject mySpider
其中, mySpider 为项目名称,可以看到将会创建一个 mySpider 文件夹,目录结构大致如下:
下面来简单介绍一下各个主要文件的作用:
- mySpider/
- scrapy.cfg
- mySpider/
- __init__.py
- items.py
- pipelines.py
- settings.py
- spiders/
- __init__.py
- ...
这些文件分别是:
- scrapy.cfg: 项目的配置文件。(爬虫相关的配置信息在settings.py文件中)
- mySpider/: 项目的Python模块,将会从这里引用代码。
- mySpider/items.py: 项目的目标文件。(设置数据储存模板,用于结构化数据)(相当于Django的Model)
- mySpider/pipelines.py: 项目的管道文件。(数据持久化处理)
- mySpider/settings.py: 项目的设置文件。(递归的层数,并发数。延迟下载等等)
- mySpider/spiders/: 存储爬虫代码目录。(编写爬虫解析规则)
二、明确目标(mySpider/items.py)
我们打算抓取 https://www.thepaper.cn/channel_25951网站里的标题和内容
打开 mySpider 目录下的 items.py。
Item 定义结构化数据字段,用来保存爬取到的数据,有点像 Python 中的 dict,但是提供了一些额外的保护减少错误。
可以通过创建一个 scrapy.Item 类, 并且定义类型为 scrapy.Field 的类属性来定义一个 Item(可以理解成类似于 ORM 的映射关系)。
接下来,创建一个 ItcastItem 类,和构建 item 模型(model)。
三、制作爬虫 (spiders/pengpai.py)
1
- cd project_name(进入项目目录)
2
- scrapy genspider 应用名称 爬取网页的起始url(scrapy gensipider app名 要爬取的域名) 例如:scrapy genspider pengpai www.thepaper.cn/channel_25951
3
编写爬虫文件:在步骤2执行完毕后,会在项目的spiders中生成一个应用名的py爬虫文件,文件源码如下:
- # -*- coding: utf-8 -*-
- import scrapy
- class PengpaiSpider(scrapy.Spider):
- name = 'pengpai'
- allowed_domains = ['www.thepaper.cn/channel_25951']
- start_urls = ['http://www.thepaper.cn/channel_25951/']
- def parse(self, response):
- pass
4、
在settings.py中配置user-agent

在爬取数据时,可以选择是否往.../robots.txt/发送验证,是否允许爬取,一般设置为False

使用scrapy解析文本内容时,可以使用每个应用中的response.xpath(xxx) 进行数据的解析。
5、
- 执行爬虫程序:scrapy crawl 应用名称
四、将澎湃首页中财经的内容和标题进行爬取
- # -*- coding: utf-8 -*-
- import scrapy
- class PengpaiSpider(scrapy.Spider):
- name = 'pengpai'#应用的名称
- #允许爬取的域名(如果遇到非该域名的url则怕取不到数据)
- allowed_domains = ['www.thepaper.cn/channel_25951']
- #起始爬取的url
- start_urls = ['http://www.thepaper.cn/channel_25951/']
- #访问起始url并获取结果后的回调函数,response就是请求后响应对象
- #该函数返回值必须是可迭代对象或者NULL
- def parse(self, response):
- #xpath是response的方法,直接调用xpath,
- page_list = response.xpath('//*[@class="news_li"]')
- text_list = []
- for page in page_list:
- #返回的是一个selector标签列表,需要的数据在data中,因此取值需要用extract()
- title = page.xpath('./h2/a/text()')[0].extract()
- content = page.xpath('./p/text()')[0].extract()
- print(title,content)
- dic = {
- "title":title,
- "content":content,
- }
- text_list.append(dic)
- print(text_list)
- return text_list
执行爬虫程序:
scrapy crawl 爬虫名称 :显示执行的日志信息 scrapy crawl 爬虫名称 --nolog:不会显示执行的日志信息
备注:xpath使用方法:
1.//+标签 表示从全局的子子孙孙中查找标签
scrapy持久化储存
持久化流程:
1.爬虫文件爬取到数据后,需要将数据封装到items对象中。
2.使用yield关键字将items对象提交给pipelines管道进行持久化操作。
3.在管道文件中的process_item方法中接收爬虫文件提交过来的item对象,然后编写持久化存储的代码将item对象中存储的数据进行持久化存储
4.settings.py配置文件中开启管道
基于终端指令的持久化存储
将爬取到的数据写入不同格式的文件中进行存储scrapy crawl 爬虫名称 -o xxx.jsonscrapy crawl 爬虫名称 -o xxx.xmlscrapy crawl 爬虫名称 -o xxx.csv
spiders/pengpai.py
- # -*- coding: utf-8 -*-
- import scrapy
- from mySpider.items import MyspiderItem
- class PengpaiSpider(scrapy.Spider):
- name = 'pengpai'#应用的名称
- #允许爬取的域名(如果遇到非该域名的url则怕取不到数据)
- allowed_domains = ['www.thepaper.cn/channel_25951']
- #起始爬取的url
- start_urls = ['http://www.thepaper.cn/channel_25951/']
- #访问起始url并获取结果后的回调函数,response就是请求后响应对象
- #该函数返回值必须是可迭代对象或者NULL
- def parse(self, response):
- #xpath是response的方法,直接调用xpath,
- page_list = response.xpath('//*[@class="news_li"]')
- text_list = []
- for page in page_list:
- #返回的是一个selector标签列表,需要的数据在data中,因此取值需要用extract()
- title = page.xpath('./h2/a/text()')[0].extract()
- content = page.xpath('./p/text()')[0].extract()
- #将解析到的数据封装到items对象中
- item = MyspiderItem()
- item['title'] = title
- item['content'] = content
- #将数据提交到管道文件(pipelines.py)
- yield item
基于mysql的管道存储
在爬虫程序中,将数据解析出来,然后封装到items.py的items类中。最后用yield提交item到管道(pipelines.py)中
items.py
- import scrapy
- class MyspiderItem(scrapy.Item):
- # define the fields for your item here like:
- # name = scrapy.Field()
- #储存的内容有多少,就实例化多少个field属性
- title = scrapy.Field()#储存标题
- content = scrapy.Field()#储存内容
pipelines.py数据item提交到管道:
进行数据储存:
- #1、基于终端储存数据
- class MyspiderPipeline(object):
- def __init__(self):
- self.fp = None#定义文件描述属性
- #重写父类方法,开始爬虫先执行
- def open_spider(self,spider):
- print("爬虫开始了。。。。")
- self.fp = open('./data.txt',"w",encoding="utf8")
- def process_item(self, item, spider):
- """
- 因为数据yield的item数据会提交多次,然而文件打开关闭操作执行一次
- 因此,将文件的打开关闭操作拿出去。
- 将爬虫程序提交eitem进行持久化存储
- :param item: 爬虫程序提交的数据
- :param spider:
- :return:
- """
- self.fp.write(item["title"]+":"+item["content"]+"\n")
- return item#返回数据,下面可能进行多次其他储存方式操作
- # 重写父类方法,爬虫结束,执行
- def close_spider(self,spider):
- self.fp.close()
- print("爬虫结束!!!")
最后去设置里将管道打开:
- # Configure item pipelines
- # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
- #******开启管道
- ITEM_PIPELINES = {
- 'mySpider.pipelines.MyspiderPipeline': 300,#300表示优先级,数值越小优先级越大
- }
管道文件里将item对象中的数据值存储到了磁盘中,如果将item数据写入mysql数据库的话,只需要将上述案例中的管道文件修改成如下形式:
- #*****基于数据库mysql储存数据***************
- import pymysql
- class PengpaiPipelinesMysql(object):
- def __init__(self):
- self.conn = None#mysql连接对象声明
- self.cursor = None#mysql游标对象声明
- def open_spider(self,spider):
- """
- 开启数据库连接
- :param spider:
- :return:
- """
- print("开始爬虫!!!")
- #链接数据库
- self.conn = pymysql.Connect(host="127.0.0.1",port=3306,user='root',password='',db='test')
- def process_item(self,item,spider):
- #执行sql语句
- sql = 'insert into pengpai values("%s","%s")'%(item["title"],item["content"])
- self.cursor = self.conn.cursor()
- try:
- self.cursor.execute(sql)
- self.conn.commit()
- except Exception as e:
- print(e)
- #与commit相反,不提交事务
- self.conn.rollback()
- return item
- def close_spider(self,spider):
- """
- 关闭游标和连接
- :param spider:
- :return:
- """
- self.cursor.close()
- self.conn.close()
- print("爬虫mysql结束!@!!")
基于Redis储存:
- import redis
- class pengpaiPipelineRedis(object):
- def __init__(self):
- self.conn = None
- def open_spider(self,spider):
- print('开始爬虫redis')
- #创建链接对象
- self.conn = redis.Redis(host='127.0.0.1',port=6379)
- def process_item(self, item, spider):
- dict = {
- 'title':item['title'],
- 'content':item['content']
- }
- #写入redis中
- self.conn.lpush('data', dict)
- return item
settings.py设置
- # Configure item pipelines
- # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
- #******开启管道
- ITEM_PIPELINES = {
- 'mySpider.pipelines.MyspiderPipeline': 300,#300表示优先级,数值越小优先级越大
- 'mySpider.pipelines.PengpaiPipelinesMysql': 200,#200表示优先级,数值越小优先级越大
- 'mySpider.pipelines.pengpaiPipelineRedis': 100,#100表示优先级,数值越小优先级越大
- }
总结:如果想要实现数据的不同储存方式,先去管道建立新的类,然后类下面都有process_spider(self,item,spider)方法。在每个类下实现储存不一样的程序,即可以实现一次爬取,不同储存方式。
备注解释:第一步先去爬虫程序中建立数据解析,将解析的数据用yield提交给管道(pipelines.py),第二步去items.py中去是实例化解析到的数据的属性(title = scrapy.Field())。第三步步去管道的类(不同类不同储存方式)下面都有process_spider(self,item,spider)方法。在每个类下实现储存不一样的程序,即可以实现一次爬取,不同储存方式。第四步去设置中开启管道,还有robots,user-agent都需要设置好。
备注:settings.py 中设置LOG_LEVEL=“ERROR”只打印错误数据
10-scrapy框架介绍的更多相关文章
- selenium模块使用详解、打码平台使用、xpath使用、使用selenium爬取京东商品信息、scrapy框架介绍与安装
今日内容概要 selenium的使用 打码平台使用 xpath使用 爬取京东商品信息 scrapy 介绍和安装 内容详细 1.selenium模块的使用 # 之前咱们学requests,可以发送htt ...
- 10.scrapy框架简介和基础应用
今日概要 scrapy框架介绍 环境安装 基础使用 今日详情 一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被 ...
- Scrapy框架——介绍、安装、命令行创建,启动、项目目录结构介绍、Spiders文件夹详解(包括去重规则)、Selectors解析页面、Items、pipelines(自定义pipeline)、下载中间件(Downloader Middleware)、爬虫中间件、信号
一 介绍 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速.简单.可扩展的方式从网站中提取所需的数据.但目前Scrapy的用途十分广泛,可 ...
- scrapy框架介绍
一,介绍 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性 ...
- 爬虫之Scrapy框架介绍
Scrapy介绍 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内 ...
- scrapy框架介绍及安装
什么是scrapy框架? scrapy框架的安装 1.windowes下的安装 Python 2 / 3升级pip版本: pip install --upgrade pip 通过pip 安装 Scra ...
- python爬虫之scrapy框架介绍
一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等) ...
- Scrapy框架学习(一)Scrapy框架介绍
Scrapy框架的架构图如上. Scrapy中的数据流由引擎控制,数据流的过程如下: 1.Engine打开一个网站,找到处理该网站的Spider,并向该Spider请求第一个要爬取得URL. 2.En ...
- Scrapy 框架介绍
Scrapy 框架 Scrapy,Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试. ...
- 10 Scrapy框架持久化存储
一.基于终端指令的持久化存储 保证parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的形式写入指定格式的文件中进行持久化操作. 执行输出指定格式进行存储:将爬取到的 ...
随机推荐
- sql server日期转换为dd-mon-yyyy和dd-MMM-yyyy这样的英文月份格式(27-Aug-2019)
脚本: /* 功能:sql server日期转换为dd-mon-yyyy和dd-MMM-yyyy这样的格式 示例:27-Aug-2019 作者:zhang502219048 脚本来源:https:// ...
- 09-Node.js学习笔记-异步编程
同步API,异步API 同步API:只有当前API执行完成后,才能继续执行下一个API console.log('before'); console.log('after'); 异步API:当前API ...
- [洛谷P1122][题解]最大子树和
这是一道还算简单的树型dp. 转移方程:f[i]=max(f[j],0) 其中i为任意非叶节点,j为i的一棵子树,而每棵子树都有选或不选两种选择 具体看代码: #include<bits/std ...
- ResultSet RS_resultxtgg=connDbBean.executeQuery(sqlxtgg);
<%String sqlxtgg="select * from dx where leibie='系统公告'"; ResultSet RS_resultxtgg=connDb ...
- [考试反思]1110csp-s模拟测试108:消遣
是套废题.T1题面错了,T2细节多而暴力>部分分,T3题目错了. T1:打表 题面应该是输出差值期望而不是答案值期望. 看到题目,果断打表. 答案就是所有值差之和除2的k次方. #include ...
- Bit Manipulation-leetcode
Bit Manipulation Find the Difference /* * Given two strings s and t which consist of only lowercase ...
- Go-for循环
一.第一种情况(死循环) package main import "fmt" func main() { for{ fmt.Println("fuck") } ...
- Cesium专栏-空间分析之坡向分析(附源码下载)
Cesium Cesium 是一款面向三维地球和地图的,世界级的JavaScript开源产品.它提供了基于JavaScript语言的开发包,方便用户快速搭建一款零插件的虚拟地球Web应用,并在性能,精 ...
- IDEA org.apache.ibatis.binding.BindingException: Invalid bound statement (not found):
引用地址:https://guozh.net/idea-org-apache-ibatis-binding-bindingexception-invalid-bound-statement-not-f ...
- 使用bean接收ajax表单提交数据包含文件上传
这几天写带图片上传的表单提交,一个配置小程序活动弹出框样式的功能,记录一下一些需要注意的地方 首先是 前端 JSP 文件的表单 <form class="search-wrapper& ...