spark thriftserver
spark可以作为一个分布式的查询引擎,用户通过JDBC的形式无需写任何代码,写写sql就可以实现查询啦,spark thriftserver的实现也是相当于hiveserver2的方式,并且在测试时候,即可以通过hive的beeline测试也可以通过spark bin/下的beeline,不管通过哪个beeline链接,都要指定spark thriftserver的主机和端口(默认是10000),比如
beeline> !connect jdbc:hive2://host_ip:port
spark thriftserver启动之后实质上就是一个Spark的应用程序,并且也可以通过4040端口来查看web ui界面,但是这个应用程序它支持JDBC/ODBC的连接,如下:
配置
接上文编译spark支持thriftserver编译完成的spark包,在sbin目录下可以看到有start-thriftserver.sh和stop-thriftserver.sh脚本

默认情况下,可以这样启动thriftserver
./sbin/start-thriftserver.sh
另外可以像使用spark-submit一样输入一些相关的参数,比如--master <master-uri>之类的,此外还可以通过--hiveconf 选项来指定hive的相关属性,比如:
./sbin/start-thriftserver.sh \ --hiveconf hive.server2.thrift.port=<listening-port> \ --hiveconf hive.server2.thrift.bind.host=<listening-host> \ --master <master-uri> ...
如果集群资源管理为yarn的话,--master设置为yarn,需要配置spark-env.sh脚本,增加hadoop的配置目录等,比如:
# Options read in YARN client/cluster mode
# - SPARK_CONF_DIR, Alternate conf dir. (Default: ${SPARK_HOME}/conf)
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
# - YARN_CONF_DIR, to point Spark towards YARN configuration files when you use YARN
# - SPARK_EXECUTOR_CORES, Number of cores ).
# - SPARK_EXECUTOR_MEMORY, Memory per Executor (e.g. 1000M, 2G) (Default: 1G)
# - SPARK_DRIVER_MEMORY, Memory for Driver (e.g. 1000M, 2G) (Default: 1G)
HADOOP_CONF_DIR=/home/etluser/kong/spark/spark--bin/spark--bin-hadoop2./conf
SPARK_CONF_DIR=/home/etluser/kong/spark/spark--bin/spark--bin-hadoop2./conf
YARN_CONF_DIR=/home/etluser/kong/spark/spark--bin/spark--bin-hadoop2./conf
启动thriftserver
[etluser@master01 spark--bin-hadoop2.]$ /home/etluser/kong/spark/spark--bin/spark--bin-hadoop2./sbin/start-thriftserver.sh \ > --master yarn \ > --driver-memory 2G \ > --executor-memory 2G \ > --num-executors \ > --executor-cores starting org.apache.spark.sql.hive.thriftserver.HiveThriftServer2, logging to /home/etluser/kong/spark/spark--bin/spark--bin-hadoop2./logs/spark-etluser-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2--master01.hadoop.dtmobile.cn.out
启动之后查看日志,看是否有报错。日志如下:
// :: INFO Client: Uploading resource file:/tmp/spark-0b2c2488-9bb3-44d5-bb1d-2d8f815dfc5f/__spark_libs__2287999641897109745.zip -> hdfs://master01.hadoop.dtmobile.cn:8020/user/etluser/.sparkStaging/application_1570496850779_0362/__spark_libs__2287999641897109745.zip
// :: INFO Client: Uploading resource file:/tmp/spark-0b2c2488-9bb3-44d5-bb1d-2d8f815dfc5f/__spark_conf__8007288391370765190.zip -> hdfs://master01.hadoop.dtmobile.cn:8020/user/etluser/.sparkStaging/application_1570496850779_0362/__spark_conf__.zip
// :: INFO SecurityManager: Changing view acls to: etluser
// :: INFO SecurityManager: Changing modify acls to: etluser
// :: INFO SecurityManager: Changing view acls groups to:
// :: INFO SecurityManager: Changing modify acls groups to:
// :: INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(etluser); groups with view permissions: Set(); users with modify permissions: Set(etluser); groups with modify permissions: Set()
// :: INFO Client: Submitting application application_1570496850779_0362 to ResourceManager
// :: INFO YarnClientImpl: Submitted application application_1570496850779_0362
// :: INFO SchedulerExtensionServices: Starting Yarn extension services with app application_1570496850779_0362 and attemptId None
// :: INFO Client: Application report for application_1570496850779_0362 (state: ACCEPTED)
// :: INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: N/A
ApplicationMaster RPC port: -
queue: root.users.etluser
start
final status: UNDEFINED
tracking URL: http://master01.hadoop.dtmobile.cn:8088/proxy/application_1570496850779_0362/
user: etluser
// :: INFO Client: Application report for application_1570496850779_0362 (state: ACCEPTED)
// :: INFO Client: Application report for application_1570496850779_0362 (state: ACCEPTED)
// :: INFO Client: Application report for application_1570496850779_0362 (state: ACCEPTED)
// :: INFO YarnClientSchedulerBackend: Add WebUI Filter. org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter, Map(PROXY_HOSTS -> master01.hadoop.dtmobile.cn, PROXY_URI_BASES -> http://master01.hadoop.dtmobile.cn:8088/proxy/application_1570496850779_0362), /proxy/application_1570496850779_0362
// :: INFO JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /jobs, /jobs/json, /jobs/job, /jobs/job/json, /stages, /stages/json, /stages/stage, /stages/stage/json, /stages/pool, /stages/pool/json, /storage, /storage/json, /storage/rdd, /storage/rdd/json, /environment, /environment/json, /executors, /executors/json, /executors/threadDump, /executors/threadDump/json, /static, /, /api, /jobs/job/kill, /stages/stage/kill.
// :: INFO Client: Application report for application_1570496850779_0362 (state: RUNNING)
// :: INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 172.30.5.213
ApplicationMaster RPC port:
queue: root.users.etluser
start
final status: UNDEFINED
tracking URL: http://master01.hadoop.dtmobile.cn:8088/proxy/application_1570496850779_0362/
user: etluser
// :: INFO YarnClientSchedulerBackend: Application application_1570496850779_0362 has started running.
// :: INFO Utils: Successfully started service .
// :: INFO NettyBlockTransferService: Server created on worker01.hadoop.dtmobile.cn:
// :: INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
// :: INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, worker01.hadoop.dtmobile.cn, , None)
// :: INFO BlockManagerMasterEndpoint: Registering block manager worker01.hadoop.dtmobile.cn: with , None)
// :: INFO YarnSchedulerBackend$YarnSchedulerEndpoint: ApplicationMaster registered as NettyRpcEndpointRef(spark-client://YarnAM)
// :: INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, worker01.hadoop.dtmobile.cn, , None)
// :: INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, worker01.hadoop.dtmobile.cn, , None)
// :: INFO JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /metrics/json.
// :: INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.30.5.212:36832) with ID 1
// :: INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.30.5.212:36834) with ID 2
// :: INFO YarnClientSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.8
// :: INFO BlockManagerMasterEndpoint: Registering block manager worker03.hadoop.dtmobile.cn: with , worker03.hadoop.dtmobile.cn, , None)
// :: INFO SharedState: loading hive config -bin/spark--bin-hadoop2./conf/hive-site.xml
// :: INFO BlockManagerMasterEndpoint: Registering block manager worker03.hadoop.dtmobile.cn: with , worker03.hadoop.dtmobile.cn, , None)
// :: INFO SharedState: spark.sql.warehouse.dir is not set, but hive.metastore.warehouse.dir is set. Setting spark.sql.warehouse.dir to the value of hive.metastore.warehouse.dir ('/user/hive/warehouse').
// :: INFO SharedState: Warehouse path is '/user/hive/warehouse'.
// :: INFO JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /SQL.
// :: INFO JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /SQL/json.
// :: INFO JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /SQL/execution.
// :: INFO JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /SQL/execution/json.
// :: INFO JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /static/sql.
// :: INFO HiveUtils: Initializing HiveMetastoreConnection version using Spark classes.
// :: INFO metastore: Trying to connect to metastore with URI thrift://worker03.hadoop.dtmobile.cn:9083
// :: INFO metastore: Connected to metastore.
// :: INFO SessionState: Created local directory: /tmp/a8f6b1e4-5ada-4c34-aba6-80d7c6d6f021_resources
// :: INFO SessionState: Created HDFS directory: /tmp/hive/etluser/a8f6b1e4-5ada-4c34-aba6-80d7c6d6f021
// :: INFO SessionState: Created local directory: /tmp/etluser/a8f6b1e4-5ada-4c34-aba6-80d7c6d6f021
// :: INFO SessionState: Created HDFS directory: /tmp/hive/etluser/a8f6b1e4-5ada-4c34-aba6-80d7c6d6f021/_tmp_space.db
// :: INFO HiveClientImpl: Warehouse location ) is /user/hive/warehouse
// :: INFO StateStoreCoordinatorRef: Registered StateStoreCoordinator endpoint
// :: INFO HiveUtils: Initializing execution hive, version
// :: INFO HiveMetaStore: : Opening raw store with implemenation class:org.apache.hadoop.hive.metastore.ObjectStore
// :: INFO ObjectStore: ObjectStore, initialize called
// :: INFO Persistence: Property hive.metastore.integral.jdo.pushdown unknown - will be ignored
// :: INFO Persistence: Property datanucleus.cache.level2 unknown - will be ignored
// :: INFO ObjectStore: Setting MetaStore object pin classes with hive.metastore.cache.pinobjtypes="Table,StorageDescriptor,SerDeInfo,Partition,Database,Type,FieldSchema,Order"
// :: INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MFieldSchema" is tagged as "embedded-only" so does not have its own datastore table.
// :: INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MOrder" is tagged as "embedded-only" so does not have its own datastore table.
// :: INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MFieldSchema" is tagged as "embedded-only" so does not have its own datastore table.
// :: INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MOrder" is tagged as "embedded-only" so does not have its own datastore table.
// :: INFO MetaStoreDirectSql: Using direct SQL, underlying DB is DERBY
// :: INFO ObjectStore: Initialized ObjectStore
// :: WARN ObjectStore: Version information not found
// :: WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
// :: INFO HiveMetaStore: Added admin role in metastore
// :: INFO HiveMetaStore: Added public role in metastore
// :: INFO HiveMetaStore: No user is added in admin role, since config is empty
// :: INFO HiveMetaStore: : get_all_databases
// :: INFO audit: ugi=etluser ip=unknown-ip-addr cmd=get_all_databases
// :: INFO HiveMetaStore: : get_functions: db=default pat=*
// :: INFO audit: ugi=etluser ip=unknown-ip-addr cmd=get_functions: db=default pat=*
// :: INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MResourceUri" is tagged as "embedded-only" so does not have its own datastore table.
// :: INFO SessionState: Created local directory: /tmp/6b9ea521-f369-45c7--4fdc6134ad51_resources
// :: INFO SessionState: Created HDFS directory: /tmp/hive/etluser/6b9ea521-f369-45c7--4fdc6134ad51
// :: INFO SessionState: Created local directory: /tmp/etluser/6b9ea521-f369-45c7--4fdc6134ad51
// :: INFO SessionState: Created HDFS directory: /tmp/hive/etluser/6b9ea521-f369-45c7--4fdc6134ad51/_tmp_space.db
// :: INFO HiveClientImpl: Warehouse location ) is /user/hive/warehouse
// :: WARN SessionManager: Unable to create operation log root directory: /var/log/hive/operation_logs
// :: INFO SessionManager: HiveServer2: Background operation thread pool size:
// :: INFO SessionManager: HiveServer2: Background operation thread
// :: INFO SessionManager: HiveServer2: Background operation thread keepalive seconds
// :: INFO AbstractService: Service:OperationManager is inited.
// :: INFO AbstractService: Service:SessionManager is inited.
// :: INFO AbstractService: Service: CLIService is inited.
// :: INFO AbstractService: Service:ThriftBinaryCLIService is inited.
// :: INFO AbstractService: Service: HiveServer2 is inited.
// :: INFO AbstractService: Service:OperationManager is started.
// :: INFO AbstractService: Service:SessionManager is started.
// :: INFO AbstractService: Service:CLIService is started.
// :: INFO ObjectStore: ObjectStore, initialize called
// :: INFO Query: Reading in results for query "org.datanucleus.store.rdbms.query.SQLQuery@0" since the connection used is closing
// :: INFO MetaStoreDirectSql: Using direct SQL, underlying DB is DERBY
// :: INFO ObjectStore: Initialized ObjectStore
// :: INFO HiveMetaStore: : get_databases: default
// :: INFO audit: ugi=etluser ip=unknown-ip-addr cmd=get_databases: default
// :: INFO HiveMetaStore: : Shutting down the object store...
// :: INFO audit: ugi=etluser ip=unknown-ip-addr cmd=Shutting down the object store...
// :: INFO HiveMetaStore: : Metastore shutdown complete.
// :: INFO audit: ugi=etluser ip=unknown-ip-addr cmd=Metastore shutdown complete.
// :: INFO AbstractService: Service:ThriftBinaryCLIService is started.
// :: INFO AbstractService: Service:HiveServer2 is started.
// :: INFO HiveThriftServer2: HiveThriftServer2 started
// :: INFO JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /sqlserver.
// :: INFO JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /sqlserver/json.
// :: INFO JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /sqlserver/session.
// :: INFO JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /sqlserver/session/json.
// :: INFO ThriftCLIService: Starting ThriftBinaryCLIService on port with ... worker threads
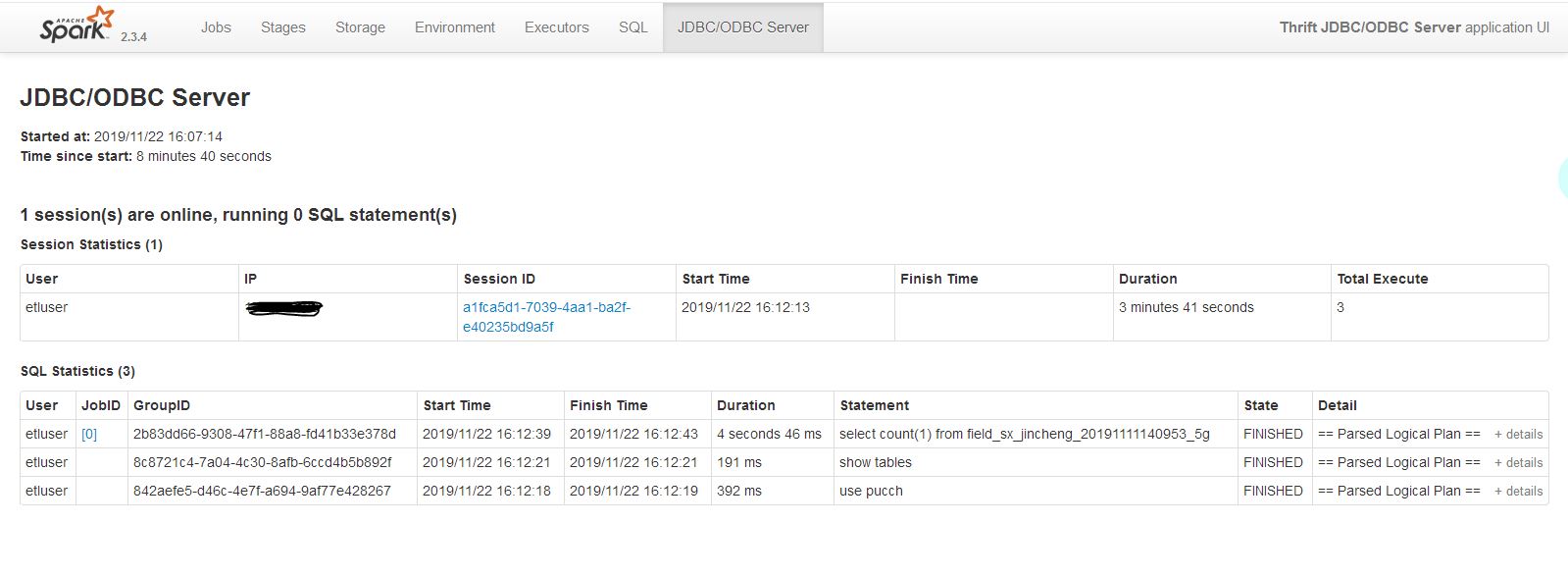
启动成功之后,就可以通过beeline来测试并且到4040界面来查看执行的状态
在使用beeline的时候,会要求输入用户名和密码,如果集群没有做什么安全认证,随意输入账号密码即可;如果设置了安全认证,比如增加了sentry认证,那么就让平台给你分配一个用户吧
简单测试:
[etluser@worker01 spark--bin-hadoop2.]$ bin/beeline Beeline version .spark2 by Apache Hive beeline> !connect jdbc:hive2://worker01.hadoop.dtmobile.cn:10000 Connecting to jdbc:hive2://worker01.hadoop.dtmobile.cn:10000 Enter username for jdbc:hive2://worker01.hadoop.dtmobile.cn:10000: etluser Enter password for jdbc:hive2://worker01.hadoop.dtmobile.cn:10000: ******* log4j:WARN No appenders could be found for logger (org.apache.hive.jdbc.Utils). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. Connected to: Spark SQL (version ) Driver: Hive JDBC (version .spark2) Transaction isolation: TRANSACTION_REPEATABLE_READ : jdbc:hive2://worker01.hadoop.dtmobile.cn:1> use pucch; +---------+--+ | Result | +---------+--+ +---------+--+ No rows selected (0.725 seconds) : jdbc:hive2://worker01.hadoop.dtmobile.cn:1> show tables; +-----------+--------------------------------------------+--------------+--+ | database | tableName | isTemporary | +-----------+--------------------------------------------+--------------+--+ | pucch | cell_lusun_datasx_jincheng20191111140953 | false | | pucch | dw_sinr_rlt_sx_jincheng20191111140953 | false | | pucch | dwsinr_prb_rlt_sx_jincheng20191111140953 | false | | pucch | field_sx_jincheng_20191111140953_5g | false | | pucch | gongcantbl_sx_jincheng20191111140953 | false | | pucch | pucch_rsrp_rlt_sx_jincheng20191111140953 | false | | pucch | pucch_sys_conf_hb_wuhan201907161354 | false | | pucch | pucch_sys_conf_sx_jincheng20191111140953 | false | | pucch | random_grid_sx_jincheng20191111140953 | false | | pucch | random_grid_tmp_sx_jincheng20191111140953 | false | | pucch | test_ultraedit | false | | pucch | test_ultraedit2 | false | | pucch | up_dw_sinr_rlt_sx_jincheng20191111140953 | false | | pucch | up_sinr_rlt_sx_jincheng20191111140953 | false | +-----------+--------------------------------------------+--------------+--+ rows selected (0.224 seconds) : jdbc:hive2://worker01.hadoop.dtmobile.cn:1> select count(1) from field_sx_jincheng_20191111140953_5g; +-----------+--+ | count() | +-----------+--+ | | +-----------+--+
4040界面:
spark thriftserver的更多相关文章
- Spark ThriftServer使用的大坑
当用beeline连接default后,通过use xxx切换到其他数据库,再退出, 再次使用beeline -u jdbc:hive2://hadoop000:10000/default -n sp ...
- 理解Spark SQL(一)—— CLI和ThriftServer
Spark SQL主要提供了两个工具来访问hive中的数据,即CLI和ThriftServer.前提是需要Spark支持Hive,即编译Spark时需要带上hive和hive-thriftserver ...
- Hive On Spark hiveserver2方式使用
启动hiveserver2: hiveserver2 --hiveconf hive.execution.engine=spark spark.master=yarn 使用beeline连接hives ...
- Spark UI界面原理
当Spark程序在运行时,会提供一个Web页面查看Application运行状态信息.是否开启UI界面由参数spark.ui.enabled(默认为true)来确定.下面列出Spark UI一些相关配 ...
- 【自动化】基于Spark streaming的SQL服务实时自动化运维
设计背景 spark thriftserver目前线上有10个实例,以往通过监控端口存活的方式很不准确,当出故障时进程不退出情况很多,而手动去查看日志再重启处理服务这个过程很低效,故设计利用Spark ...
- spark技术总结(1)
1. 请描述spark RDD原理与特征 RDD为Resilient Distributed Datasets缩写,译文弹性分布式数据集. 他是spark系统中的核心数据模型之一,另外一个是DAG模型 ...
- spark sql 的metastore 对接 postgresql
本教程记录 spark 1.3.1 版本的thriftserver 的metastore 对接 postgresql postgresql 的编译,参考:http://www.cnblogs.com/ ...
- 记一次有关spark动态资源分配和消息总线的爬坑经历
问题: 线上的spark thriftserver运行一段时间以后,ui的executor页面上显示大量的active task,但是从job页面看,并没有任务在跑.此外,由于在yarn mode下, ...
- spark动态资源(executor)分配
spark动态资源调整其实也就是说的executor数目支持动态增减,动态增减是根据spark应用的实际负载情况来决定. 开启动态资源调整需要(on yarn情况下) 1.将spark.dynamic ...
随机推荐
- Halcon一日一练:图像采集设备的基本参数
因操作图像处理之前,需要对图像进行采集.采集图像,我们首先要确定的是图像的像素和采集的效率.这些都需要对设备进行配置与操作.现实情况是图像设备有各自不同的采集方式,配置也各不相同.这就需要设备提供商提 ...
- Vuex的简单应用
### 源码地址 https://github.com/moor-mupan/mine-summary/tree/master/前端知识库/Vuex_demo/demo 1. 什么是Vuex? Vue ...
- python soket服务和客户端Demo
#服务端from socket import * s=socket(AF_INET,SOCK_STREAM)#IVP4 寻址 tcp协议 s.bind(('',6666))#补丁端口 s.listen ...
- shell数组(四)
[root@ipha-dev71- exercise_shell]# cat test.sh #!/bin/bash my_array=(a b c d) echo "第一个元素为:${my ...
- if-elif-else分支判断语句(附加continue和break)---举例说明
一.分支循环语句: a=input("请输入一个五位数字") if(len(a)!=5): print("输入的数字不合格"); elif(a[0::]==a[ ...
- ESP8266开发之旅 进阶篇⑤ 代码规范 —— 像写文章一样优美
1.前言 之前,一直在跟大伙分享怎么去玩蓝牙模块,怎么去玩wifi模块,怎么去玩json,然后有很多小伙伴就留言各种问题或者说直接怼他的代码过来让我看,然后我就一脸懵逼(代码中到处各种abcd ...
- 小程序预览pdf文件
有个业务需求,需要在小程序查看客户已开的发票 发票地址: https://www.chinaeinv.com/p.jspa?cxxxxxxxxxxxx 刚开始是想利用webview当作外链进行跳转访问 ...
- Apache Flink 入门示例demo
在本文中,我们将从零开始,教您如何构建第一个Apache Flink (以下简称Flink)应用程序. 开发环境准备 Flink 可以运行在 Linux, Max OS X, 或者是 Windows ...
- Linux常用命令-不定时记录
文件移动命令 命令格式:mv [-fiv] source destination 参数说明:-f:force,强制直接移动而不询问-i:若目标文件(destination)已经存在,就会询问是否覆盖- ...
- 数据结构(三十四)最短路径(Dijkstra、Floyd)
一.最短路径的定义 在网图和非网图中,最短路径的含义是不同的.由于非网图没有边上的权值,所谓的最短路径,其实就是指两顶点之间经过的边数最少的路径:而对于网图来说,最短路径是指两顶点之间经过的边上权值之 ...