HBase概念及表格设计
HBase概念及表格设计
1. 概述(扯淡~)
HBase是一帮家伙看了Google发布的一片名为“BigTable”的论文以后,犹如醍醐灌顶,进而“山寨”出来的一套系统。
由此可见:
1. 几乎所有的HBase中的理念,都可以从BigTable论文中得到解释。原文是英语的,而且还有不少数学概念,看了有点儿懵,建议网上找找学习笔记看看,差不多也就可以入门了。
2. Google确实牛X。
3. 老外也爱山寨~
第一次看HBase, 可能看到以下描述会懵:“基于列存储”,“稀疏MAP”,“RowKey”,“ColumnFamily”。
其实没那么高深,我们需要分两步来理解HBase, 就能够理解为什么HBase能够“快速地”“分布式地”处理“大量数据”了。
1.内存结构
2.文件存储结构
2. 名词概念以及内存结构
假设我们有一张表(其中只有一条数据):
|
RowKey |
ColumnFamily : CF1 |
ColumnFamily : CF2 |
TimeStamp |
||
|
Column: C11 |
Column: C12 |
Column: C21 |
Column: C22 |
||
|
“com.google” |
“C11 good” |
“C12 good” |
“C12 bad” |
“C12 bad” |
T1 |
1) RowKey: 行键,可理解成MySQL中的主键列。
2) Column: 列,可理解成MySQL列。
3) ColumnFamily: 列族, HBase引入的概念:
- 将多个列聚合成一个列族。
- 可以理解成MySQL的垂直分区(将一张宽表,切分成几张不那么宽的表)。
- 此机制引入的原因,是因为HBase相信,查询可能并不需要将一整行的所有列数据全部返回。(就像我们往往在写SQL时不太会写select all一样)
- 对应到文件存储结构(不同的ColumnFamily会写入不同的文件)。
4) TimeStamp:在每次跟新数据时,用以标识一行数据的不同版本(事实上,TimeStamp是与列绑定的。)
那我们为何会得到HBase的读写高性能呢?其实所有数据库操作如何得到高性能,答案几乎都是一致的,就是做索引。
HBase的设计抛弃了传统RDBMS的行式数据模型,把索引和数据模型原生的集成在了一起。
以上图的表为例,表数据在HBase内部用Map实现,我们把它写成JSon的Object表述,即:

{
"com.google": {
CF1: {
C11:{
T1: good
}
C12:{
T1: good
}
CF2: {
C21:{
T1: bad
}
C22:{
T1: bad
}
}
}
}
由于Map本身可以通过B+树来实现,所以随机访问的速度大大加快(我们需要想象一下,表中有很多行的情况)。
现在我们在原来的表上修改一下(将Column: C22改为”good”):
|
RowKey |
ColumnFamily : CF1 |
ColumnFamily : CF2 |
TimeStamp |
||
|
Column: C11 |
Column: C12 |
Column: C21 |
Column: C22 |
||
|
“com.google” |
“C11 good” |
“C12 good” |
“C12 bad” |
“C12 bad” |
T1 |
|
“com.google” |
“C11 good” |
“C12 good” |
“C12 bad” |
“C12 good” |
T2 |
于是MAP变为了:
{
"com.google": {
CF1: {
C11:{
T1: good
}
C12:{
T1: good
}
CF2: {
C21:{
T1: bad
}
C22:{
T1: bad
T2:good
}
}
}
}
事实上,我们只需要在C22的object再加一个属性即可。如果我们把这个MAP翻译成表形状,也可以表示为:
|
RowKey |
ColumnFamily : CF1 |
ColumnFamily : CF2 |
TimeStamp |
||
|
Column: C11 |
Column: C12 |
Column: C21 |
Column: C22 |
||
|
“com.google” |
“C11 good” |
“C12 good” |
“C12 bad” |
“C12 bad” |
T1 |
|
“C12 good” |
T2 |
||||
我们发现,这个表里很多列是没有value的。想象一下,如果再加入一行RowKey不同的数据,其中Column:C11内容为空,就可以在Json中省略该属性了。
好了,扯了这么多,就是为了说明HBase是“稀疏的高阶MAP”。
为了查询效率,HBase内部对RowKey做了排序,以保证类似的或者相同的RowKey都集中在一起,于是HBase就变成了一张“稀疏的,有序的,高阶的MAP”。有没有觉得这样的表述很高冷? :)
3. 文件存储结构与进程模型
如上所述,HBase是一张“稀疏的,有序的,高阶的MAP”。
通常来说,MAP可以用B+树来实现。B+树对查询性能而言表现良好,但是对插入数据有些力不从心,尤其对于插入的数据需要持久化到磁盘的情况而言。
我们对RowKey做了排序,为了保证查询效率,我们希望将连续RowKey的数值保存在连续的磁道上,以避免大量的磁盘随机寻道。所以在插入数据时,对于B+树而言,就面临着大量的文件搬移工作。
HBase使用了LSM树实现了MAP,简单说来,就是将插入/修改操作缓存在内存中,当内存中积累足够的数据后,再以块的形式刷入到磁盘上。
HBase的进程模型:
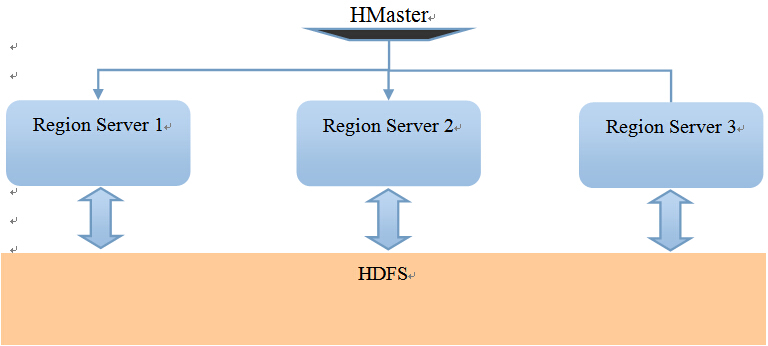
Region: 基于RowKey的分区,可理解成MySQL的水平切分。
每个Region Server就是Hadoop集群中一台机器上的一个进程。
比如我们的有1-300号的RowKey, 那么1-100号RowKey的行被分配到Region Server 1上,同样,101-200号分配到Region Server 2上, 201-300号分配到Region Server 3上。
在内存模型中,我们说RowKey保证了相邻RowKey的记录被连续地写入了磁盘。在这里,我们发现,RowKey决定了行操作(增,删,改,查)会被交与哪台Region Server操作。
让我们假设一下,如果我们的RowKey以记录的TimeStamp起始,从内存模型上说,这很合理,因为我们可能面临大量的用户流水记录查询,查询的条件会设置一个时间片段,我们希望一次性从磁盘中读取这些流水记录,从而避免频繁的磁盘寻道操作。
但是再另一方面,用户的流水记录查询会很频繁的出现“截至到至今”的查询条件,依照我们上面的进程模型,Region Server 3一定会被分配到(因为最近的记录排在最后),这样就可能造成Region Server 3的“过热”,而Region Server 1“过冷”的情况。
文件存储模型:
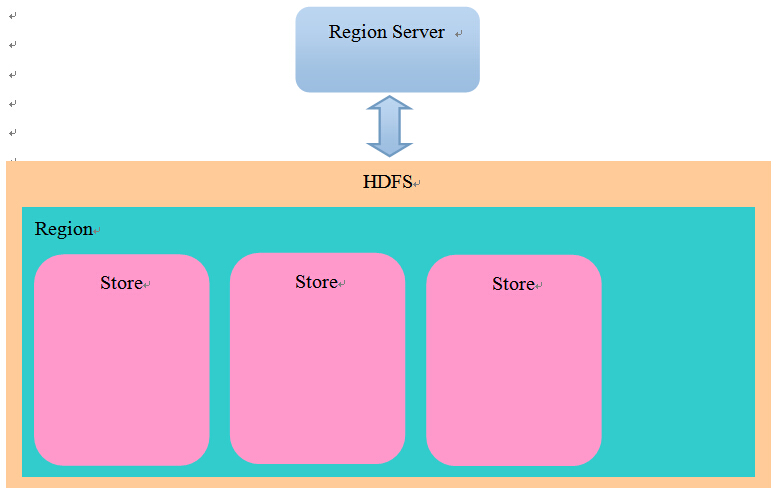
在HDFS中,每张表对应一个目录,在表目录下,每个Region对应一个目录,在Region目录下,每个Store对应一个目录(一个Store对应一个ColumFamily)。结构如下:
HBase
|
---Table
|
---XXXX(Region的hash)
| |
| ----ColumnFamily
| |
| ---文件
|
---YYYYY(另一个Region的hash)
我们的新发现是,不同的ColumnFamily对应不同的Store, 并且被写入了不同的目录, 这意味着:
1. 通过将一张表分解成了不同的ColumnFamily,HBase可以从磁盘一次读取更少的内容(IO操作往往是计算机系统中最慢的一环)。
2. 我们不应该将需要一次查询出的列,分解在不同的ColumnFamily中,否则以为着HBase不得不读取两个文件来满足查询要求。
另外,一个ColumnFamily中的每一列是连续存储的。即如果一个ColumnFamily中存在C1,C2两列,一段具有100行记录的存储格式是:
C1(1),C2(1),C1(2),C2(2),C1(3),C2(3).............C1(100),C2(100)
与其说HBase是基于列的数据库,更不如说HBase是基于“列族”的数据库。
4 理解:
基于以上的模型,大致的理解是:
1. RowKey决定了行操作任务进入RegionServer的数量,我们应该尽量的让一次操作调用更多的Region Server,已达到分布式的目的。
2. RowKey决定了查询读取连续磁盘块的数量,最理想的情况是一次查询,在每个Region Server上,只读取一个磁盘块。
3. ColumnFamily决定了一次查询需要读取的文件数(不同的文件不仅意味着分散的磁盘块,还意味着多次的文件打开关闭操作)。我们应尽量将希望查询的结果集合并到一个ColumnFamily中。同时尽量去除该ColumnFamily中不需要的列。
4. HBase官方建议尽量的减少ColumnFamily的数量。
再瞎总结一下:
1. RowKey由查询条件决定。
2. ColumnFamily由查询结果决定。
HBase概念及表格设计的更多相关文章
- Hbase:原理和设计
转载自:http://www.sysdb.cn/index.php/2016/01/10/hbase_principle/ ,感谢原作者. 简介 HBase —— Hadoop Database的简称 ...
- HBase,以及GeoMesa设计基于HBase的设计分析,从数据模型到典型查询场景,最后进行RowKey设计
GeoMesa设计基于HBase的设计分析,从数据模型到典型查询场景,最后进行RowKey设计 一.HBase 基本概念 理解KeyValue KeyValue多版本 列定义(1) 列定义(2) Co ...
- (转)HBase 的原理和设计
转自:HBase的原理和设计 HBase架构:
- opencv 手写选择题阅卷 (一)表格设计与识别
(一)答题表格设计与识别 实际设计好的表格如下图 为了图像精确,表格和四角的标记都是由程序生成的,文字和数据是后期排版软件添加上去的. 图中四角的四个黑方块主要用来定位表格,然后就可以切割出每个单元格 ...
- HBase二级索引的设计(案例讲解)
摘要 最近做的一个项目涉及到了多条件的组合查询,数据存储用的是HBase,恰恰HBase对于这种场景的查询特别不给力,一般HBase的查询都是通过RowKey(要把多条件组合查询的字段都拼接在RowK ...
- 如何用BarTender 2016字处理器完成表格设计
很多时候,需要应客户要求,用BarTender 2016设计带表格的标签.在BarTender 2016中字处理器文本对象可以使用字处理中的诸多格式功能(如项目符号.编号列表.表格.混合字体以及RTF ...
- HBase二级索引的设计
摘要 最近做的一个项目涉及到了多条件的组合查询,数据存储用的是HBase,恰恰HBase对于这种场景的查询特别不给力,一般HBase的查询都是通过RowKey(要把多条件组合查询的字段都拼接在RowK ...
- HBase之八--(1):HBase二级索引的设计(案例讲解)
摘要 最近做的一个项目涉及到了多条件的组合查询,数据存储用的是HBase,恰恰HBase对于这种场景的查询特别不给力,一般HBase的查询都是通过RowKey(要把多条件组合查询的字段都拼接在RowK ...
- SSAS 多维/表格设计模型--事实表与维表的关联
表格设计模型中,同多维设计模型相似, 维表和事实表相互独立,通过关系数据库中的外键来联系,互相关联构成一个统一的架构. DB中外键是需要唯一性约束的,即A表某列建立主键或者唯一键后,B表才可以引用为外 ...
随机推荐
- 在VisualStudio 工具箱中隐藏用户控件
当我们创建一个用户控件后,VisualStudio会自动将其添加到工具箱中,本来这是一个比较贴心的设计.但是,有的时候,我们并不想将用户控件放到工具箱中. 例如:在WPF中,为了避免一个页面的控件过多 ...
- Springboot集成BeanValidation扩展二:加载jar中的资源文件
一.需求 今天在搭建Springboot框架的时候,又遇到一个需求:在多模块系统中,有些模块想自己管理BeanValidation的资源文件(默认是启动项目claspath下的 ValidationM ...
- AFNetworking 2.0 Tutorial
Update 1/18/2014: Fully updated for iOS 7 and AFNetworking 2.0 (original post by Scott Sherwood, upd ...
- Android Rx Android实战
上一次捣蛋 RxAndroid 是今年二月份的事情了,当时 RxAndroid 还处于一个资料甚少交流难的状态,当时还特意建了一个交流群,让搞这个的人可以加进来讨论讨论,毕竟这玩意还是挺有意思的,于是 ...
- GTK+重拾--09 GTK+中的组件(一)
(一):写在前面 在这篇文章中主要介绍了GTK+程序中的各种构件,这是解说构件的第一个部分,另外一部分将在下一个小节中讲到. 构件是建立一个GUI程序的基础.在GTK+的长期发展过程中.一些特定的构件 ...
- 改变PS1变量的颜色
2016.1.11今天学了改变PS1的颜色,怎么增加PS1变量找到文件(.bash_profile),或者bashrc export PS1="\[\e[32;1m\]Test $PWD&g ...
- C#实现在Form上截取消息的两种方法
比较常用的是重载Form的DefWndProc方法,例如截取鼠标按下的消息: protected override void DefWndProc(ref Message m) { if ( m.Ms ...
- 【原创】SpringBoot & SpringCloud 快速入门学习笔记(完整示例)
[原创]SpringBoot & SpringCloud 快速入门学习笔记(完整示例) 1月前在系统的学习SpringBoot和SpringCloud,同时整理了快速入门示例,方便能针对每个知 ...
- [Functional Programming] Read and Transform Values from a State ADT’s State (get)
Many times we need to access and transform state, either in part or in full, to be used when calcula ...
- 使用JMeter录制手机App脚本
Apache JMeter是100%的Java桌面应用程序,用于对软件做压力测试.它最初被设计用于Web应用测试,但后来扩展到其他测试领域.现如今这款软件越来越受到测试人员的青睐,相比于LoadRun ...