XGBoost算法原理小结
在两年半之前作过梯度提升树(GBDT)原理小结,但是对GBDT的算法库XGBoost没有单独拿出来分析。虽然XGBoost是GBDT的一种高效实现,但是里面也加入了很多独有的思路和方法,值得单独讲一讲。因此讨论的时候,我会重点分析和GBDT不同的地方。
1. 从GBDT到XGBoost
作为GBDT的高效实现,XGBoost是一个上限特别高的算法,因此在算法竞赛中比较受欢迎。简单来说,对比原算法GBDT,XGBoost主要从下面三个方面做了优化:
一是算法本身的优化:在算法的弱学习器模型选择上,对比GBDT只支持决策树,还可以直接很多其他的弱学习器。在算法的损失函数上,除了本身的损失,还加上了正则化部分。在算法的优化方式上,GBDT的损失函数只对误差部分做负梯度(一阶泰勒)展开,而XGBoost损失函数对误差部分做二阶泰勒展开,更加准确。算法本身的优化是我们后面讨论的重点。
二是算法运行效率的优化:对每个弱学习器,比如决策树建立的过程做并行选择,找到合适的子树分裂特征和特征值。在并行选择之前,先对所有的特征的值进行排序分组,方便前面说的并行选择。对分组的特征,选择合适的分组大小,使用CPU缓存进行读取加速。将各个分组保存到多个硬盘以提高IO速度。
三是算法健壮性的优化:对于缺失值的特征,通过枚举所有缺失值在当前节点是进入左子树还是右子树来决定缺失值的处理方式。算法本身加入了L1和L2正则化项,可以防止过拟合,泛化能力更强。
在上面三方面的优化中,第一部分算法本身的优化是重点也是难点。现在我们就来看看算法本身的优化内容。
2. XGBoost损失函数
在看XGBoost本身的优化内容前,我们先回顾下GBDT的回归算法迭代的流程,详细算法流程见梯度提升树(GBDT)原理小结第三节,对于GBDT的第t颗决策树,主要是走下面4步:
1)对样本i=1,2,...m,计算负梯度$$r_{ti} = -\bigg[\frac{\partial L(y_i, f(x_i)))}{\partial f(x_i)}\bigg]_{f(x) = f_{t-1}\;\; (x)}$$
2)利用$(x_i,r_{ti})\;\; (i=1,2,..m)$, 拟合一颗CART回归树,得到第t颗回归树,其对应的叶子节点区域为$R_{tj}, j =1,2,..., J$。其中J为回归树t的叶子节点的个数。
3) 对叶子区域j =1,2,..J,计算最佳拟合值$$c_{tj} = \underbrace{arg\; min}_{c}\sum\limits_{x_i \in R_{tj}} L(y_i,f_{t-1}(x_i) +c)$$
4) 更新强学习器$$f_{t}(x) = f_{t-1}(x) + \sum\limits_{j=1}^{J}c_{tj}I(x \in R_{tj}) $$
上面第一步是得到负梯度,或者是泰勒展开式的一阶导数。第二步是第一个优化求解,即基于残差拟合一颗CART回归树,得到J个叶子节点区域。第三步是第二个优化求解,在第二步优化求解的结果上,对每个节点区域再做一次线性搜索,得到每个叶子节点区域的最优取值。最终得到当前轮的强学习器。
从上面可以看出,我们要求解这个问题,需要求解当前决策树最优的所有J个叶子节点区域和每个叶子节点区域的最优解$c_{tj}$。GBDT采样的方法是分两步走,先求出最优的所有J个叶子节点区域,再求出每个叶子节点区域的最优解。
对于XGBoost,它期望把第2步和第3步合并在一起做,即一次求解出决策树最优的所有J个叶子节点区域和每个叶子节点区域的最优解$c_{tj}$。在讨论如何求解前,我们先看看XGBoost的损失函数的形式。
在GBDT损失函数$L(y, f_{t-1}(x)+ h_t(x))$的基础上,我们加入正则化项如下:$$\Omega(h_t) = \gamma J + \frac{\lambda}{2}\sum\limits_{j=1}^Jw_{tj}^2$$
这里的$J$是叶子节点的个数,而$w_{tj}$是第j个叶子节点的最优值。这里的$w_{tj}$和我们GBDT里使用的$c_{tj}$是一个意思,只是XGBoost的论文里用的是$w$表示叶子区域的值,因此这里和论文保持一致。
最终XGBoost的损失函数可以表达为:$$L_t=\sum\limits_{i=1}^mL(y_i, f_{t-1}(x_i)+ h_t(x_i)) + \gamma J + \frac{\lambda}{2}\sum\limits_{j=1}^Jw_{tj}^2 $$
最终我们要极小化上面这个损失函数,得到第t个决策树最优的所有J个叶子节点区域和每个叶子节点区域的最优解$w_{tj}$。XGBoost没有和GBDT一样去拟合泰勒展开式的一阶导数,而是期望直接基于损失函数的二阶泰勒展开式来求解。现在我们来看看这个损失函数的二阶泰勒展开式:
$$\begin{align} L_t & = \sum\limits_{i=1}^mL(y_i, f_{t-1}(x_i)+ h_t(x_i)) + \gamma J + \frac{\lambda}{2}\sum\limits_{j=1}^Jw_{tj}^2 \\ & \approx \sum\limits_{i=1}^m( L(y_i, f_{t-1}(x_i)) + \frac{\partial L(y_i, f_{t-1}(x_i) }{\partial f_{t-1}(x_i)}h_t(x_i) + \frac{1}{2}\frac{\partial^2 L(y_i, f_{t-1}(x_i) }{\partial f_{t-1}^2(x_i)} h_t^2(x_i)) + \gamma J + \frac{\lambda}{2}\sum\limits_{j=1}^Jw_{tj}^2 \end{align}$$
为了方便,我们把第i个样本在第t个弱学习器的一阶和二阶导数分别记为$$g_{ti} = \frac{\partial L(y_i, f_{t-1}(x_i) }{\partial f_{t-1}(x_i)}, \; h_{ti} = \frac{\partial^2 L(y_i, f_{t-1}(x_i) }{\partial f_{t-1}^2(x_i)}$$
则我们的损失函数现在可以表达为:$$L_t \approx \sum\limits_{i=1}^m( L(y_i, f_{t-1}(x_i)) + g_{ti}h_t(x_i) + \frac{1}{2} h_{ti} h_t^2(x_i)) + \gamma J + \frac{\lambda}{2}\sum\limits_{j=1}^Jw_{tj}^2$$
损失函数里面$L(y_i, f_{t-1}(x_i))$是常数,对最小化无影响,可以去掉,同时由于每个决策树的第j个叶子节点的取值最终会是同一个值$w_{tj}$,因此我们的损失函数可以继续化简。
$$\begin{align} L_t & \approx \sum\limits_{i=1}^m g_{ti}h_t(x_i) + \frac{1}{2} h_{ti} h_t^2(x_i)) + \gamma J + \frac{\lambda}{2}\sum\limits_{j=1}^Jw_{tj}^2 \\ & = \sum\limits_{j=1}^J (\sum\limits_{x_i \in R_{tj}}g_{ti}w_{tj} + \frac{1}{2} \sum\limits_{x_i \in R_{tj}}h_{ti} w_{tj}^2) + \gamma J + \frac{\lambda}{2}\sum\limits_{j=1}^Jw_{tj}^2 \\ & = \sum\limits_{j=1}^J [(\sum\limits_{x_i \in R_{tj}}g_{ti})w_{tj} + \frac{1}{2}( \sum\limits_{x_i \in R_{tj}}h_{ti}+ \lambda) w_{tj}^2] + \gamma J \end{align}$$
我们把每个叶子节点区域样本的一阶和二阶导数的和单独表示如下:$$G_{tj} = \sum\limits_{x_i \in R_{tj}}g_{ti},\; H_{tj} = \sum\limits_{x_i \in R_{tj}}h_{ti}$$
最终损失函数的形式可以表示为:$$L_t = \sum\limits_{j=1}^J [G_{tj}w_{tj} + \frac{1}{2}(H_{tj}+\lambda)w_{tj}^2] + \gamma J $$
现在我们得到了最终的损失函数,那么回到前面讲到的问题,我们如何一次求解出决策树最优的所有J个叶子节点区域和每个叶子节点区域的最优解$w_{tj}$呢?
3. XGBoost损失函数的优化求解
关于如何一次求解出决策树最优的所有J个叶子节点区域和每个叶子节点区域的最优解$w_{tj}$,我们可以把它拆分成2个问题:
1) 如果我们已经求出了第t个决策树的J个最优的叶子节点区域,如何求出每个叶子节点区域的最优解$w_{tj}$?
2) 对当前决策树做子树分裂决策时,应该如何选择哪个特征和特征值进行分裂,使最终我们的损失函数$L_t$最小?
对于第一个问题,其实是比较简单的,我们直接基于损失函数对$w_{tj}$求导并令导数为0即可。这样我们得到叶子节点区域的最优解$w_{tj}$表达式为:$$w_{tj} = - \frac{G_{tj}}{H_{tj} + \lambda}$$
这个叶子节点的表达式不是XGBoost首创,实际上在GBDT的分类算法里,已经在使用了。大家在梯度提升树(GBDT)原理小结第4.1节中叶子节点区域值的近似解表达式为:$$c_{tj} = \sum\limits_{x_i \in R_{tj}}r_{ti}\bigg / \sum\limits_{x_i \in R_{tj}}|r_{ti}|(1-|r_{ti}|)$$
它其实就是使用了上式来计算最终的$c_{tj}$。注意到二元分类的损失函数是:$$L(y, f(x)) = log(1+ exp(-yf(x)))$$
其每个样本的一阶导数为:$$g_i=-r_i= -y_i/(1+exp(y_if(x_i)))$$
其每个样本的二阶导数为:$$h_i =\frac{exp(y_if(x_i)}{(1+exp(y_if(x_i))^2} = |g_i|(1-|g_i|) $$
由于没有正则化项,则$c_{tj} = -\frac{g_i}{h_i} $,即可得到GBDT二分类叶子节点区域的近似值。
现在我们回到XGBoost,我们已经解决了第一个问题。现在来看XGBoost优化拆分出的第二个问题:如何选择哪个特征和特征值进行分裂,使最终我们的损失函数$L_t$最小?
在GBDT里面,我们是直接拟合的CART回归树,所以树节点分裂使用的是均方误差。XGBoost这里不使用均方误差,而是使用贪心法,即每次分裂都期望最小化我们的损失函数的误差。
注意到在我们$w_{tj}$取最优解的时候,原损失函数对应的表达式为:$$L_t = -\frac{1}{2}\sum\limits_{j=1}^J\frac{G_{tj}^2}{H_{tj} + \lambda} +\gamma J$$
如果我们每次做左右子树分裂时,可以最大程度的减少损失函数的损失就最好了。也就是说,假设当前节点左右子树的一阶二阶导数和为$G_L,H_L,G_R,H_L$, 则我们期望最大化下式:$$-\frac{1}{2}\frac{(G_L+G_R)^2}{H_L+H_R+ \lambda} +\gamma J -( -\frac{1}{2}\frac{G_L^2}{H_L + \lambda} -\frac{1}{2}\frac{G_{tj}^2}{H_{tj+\lambda} + \lambda}+ \gamma (J+1) ) $$
整理下上式后,我们期望最大化的是:$$\max \frac{1}{2}\frac{G_L^2}{H_L + \lambda} + \frac{1}{2}\frac{G_R^2}{H_R+\lambda} - \frac{1}{2}\frac{(G_L+G_R)^2}{H_L+H_R+ \lambda} - \gamma$$
也就是说,我们的决策树分裂标准不再使用CART回归树的均方误差,而是上式了。
具体如何分裂呢?举个简单的年龄特征的例子如下,假设我们选择年龄这个 特征的值a作为决策树的分裂标准,则可以得到左子树2个人,右子树三个人,这样可以分别计算出左右子树的一阶和二阶导数和,进而求出最终的上式的值。

然后我们使用其他的不是值a的划分标准,可以得到其他组合的一阶和二阶导数和,进而求出上式的值。最终我们找出可以使上式最大的组合,以它对应的特征值来分裂子树。
至此,我们解决了XGBoost的2个优化子问题的求解方法。
4. XGBoost算法主流程
这里我们总结下XGBoost的算法主流程,基于决策树弱分类器。不涉及运行效率的优化和健壮性优化的内容。
输入是训练集样本$I=\{(x_,y_1),(x_2,y_2), ...(x_m,y_m)\}$, 最大迭代次数T, 损失函数L, 正则化系数$\lambda,\gamma$。
输出是强学习器f(x)
对迭代轮数t=1,2,...T有:
1) 计算第i个样本(i-1,2,..m)在当前轮损失函数L基于$f_{t-1}(x_i)$的一阶导数$g_{ti}$,二阶导数$h_{ti}$,计算所有样本的一阶导数和$G_t = \sum\limits_{i=1}^mg_{ti}$,二阶导数和$H_t = \sum\limits_{i=1}^mh_{ti}$
2) 基于当前节点尝试分裂决策树,默认分数score=0
对特征序号 k=1,2...K:
a) $G_L=0, H_L=0$
b.1) 将样本按特征k从小到大排列,依次取出第i个样本,依次计算当前样本放入左子树后,左右子树一阶和二阶导数和:$$G_L = G_L+ g_{ti}, G_R=G-G_L$$$$H_L = H_L+ h_{ti}, H_R=H-H_L$$
b.2) 尝试更新最大的分数:$$score = max(score, \frac{1}{2}\frac{G_L^2}{H_L + \lambda} + \frac{1}{2}\frac{G_R^2}{H_R+\lambda} - \frac{1}{2}\frac{(G_L+G_R)^2}{H_L+H_R+ \lambda} )$$
3) 基于最大score对应的划分特征和特征值分裂子树。
4) 如果最大score为0,则当前决策树建立完毕,计算所有叶子区域的$w_{tj}$, 得到弱学习器$h_t(x)$,更新强学习器$f_t(x)$,进入下一轮弱学习器迭代.如果最大score不是0,则转到第2)步继续尝试分裂决策树。
5.XGBoost算法运行效率的优化
在第2,3,4节我们重点讨论了XGBoost算法本身的优化,在这里我们再来看看XGBoost算法运行效率的优化。
大家知道,Boosting算法的弱学习器是没法并行迭代的,但是单个弱学习器里面最耗时的是决策树的分裂过程,XGBoost针对这个分裂做了比较大的并行优化。对于不同的特征的特征划分点,XGBoost分别在不同的线程中并行选择分裂的最大增益。
同时,对训练的每个特征排序并且以块的的结构存储在内存中,方便后面迭代重复使用,减少计算量。计算量的减少参见上面第4节的算法流程,首先默认所有的样本都在右子树,然后从小到大迭代,依次放入左子树,并寻找最优的分裂点。这样做可以减少很多不必要的比较。
具体的过程如下图所示:
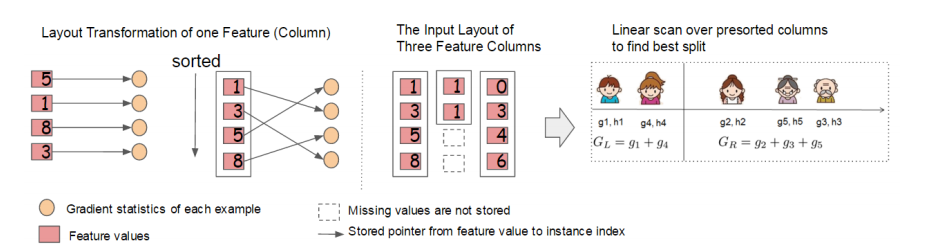
此外,通过设置合理的分块的大小,充分利用了CPU缓存进行读取加速(cache-aware access)。使得数据读取的速度更快。另外,通过将分块进行压缩(block compressoin)并存储到硬盘上,并且通过将分块分区到多个硬盘上实现了更大的IO。
6.XGBoost算法健壮性的优化
最后我们再来看看XGBoost在算法健壮性的优化,除了上面讲到的正则化项提高算法的泛化能力外,XGBoost还对特征的缺失值做了处理。
XGBoost没有假设缺失值一定进入左子树还是右子树,则是尝试通过枚举所有缺失值在当前节点是进入左子树,还是进入右子树更优来决定一个处理缺失值默认的方向,这样处理起来更加的灵活和合理。
也就是说,上面第4节的算法的步骤a),b.1)和b.2)会执行2次,第一次假设特征k所有有缺失值的样本都走左子树,第二次假设特征k所有缺失值的样本都走右子树。然后每次都是针对没有缺失值的特征k的样本走上述流程,而不是所有的的样本。
如果是所有的缺失值走右子树,使用上面第4节的a),b.1)和b.2)即可。如果是所有的样本走左子树,则上面第4节的a)步要变成:$$G_R=0, H_R=0$$
b.1)步要更新为:$$G_R = G_R+g_{ti}, G_L=G-G_R$$$$H_R = H_R+h_{ti}, H_L=H-H_R$$
7. XGBoost小结
不考虑深度学习,则XGBoost是算法竞赛中最热门的算法,它将GBDT的优化走向了一个极致。当然,后续微软又出了LightGBM,在内存占用和运行速度上又做了不少优化,但是从算法本身来说,优化点则并没有XGBoost多。
何时使用XGBoost,何时使用LightGBM呢?个人建议是优先选择XGBoost,毕竟调优经验比较多一些,可以参考的资料也多一些。如果你使用XGBoost遇到的内存占用或者运行速度问题,那么尝试LightGBM是个不错的选择。
(欢迎转载,转载请注明出处。欢迎沟通交流: liujianping-ok@163.com)
XGBoost算法原理小结的更多相关文章
- Bagging与随机森林算法原理小结
在集成学习原理小结中,我们讲到了集成学习有两个流派,一个是boosting派系,它的特点是各个弱学习器之间有依赖关系.另一种是bagging流派,它的特点是各个弱学习器之间没有依赖关系,可以并行拟合. ...
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- GBDT和XGBOOST算法原理
GBDT 以多分类问题为例介绍GBDT的算法,针对多分类问题,每次迭代都需要生成K个树(K为分类的个数),记为\(F_{mk}(x)\),其中m为迭代次数,k为分类. 针对每个训练样本,使用的损失函数 ...
- xgboost算法原理
XGBoost是2014年3月陈天奇博士提出的,是基于CART树的一种boosting算法,XGBoost使用CART树有两点原因:对于分类问题,CART树的叶子结点对应的值是一个实际的分数,而非一个 ...
- XGBoost类库使用小结
在XGBoost算法原理小结中,我们讨论了XGBoost的算法原理,这一片我们讨论如何使用XGBoost的Python类库,以及一些重要参数的意义和调参思路. 本文主要参考了XGBoost的Pytho ...
- 集成学习值Adaboost算法原理和代码小结(转载)
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类: 第一个是个体学习器之间存在强依赖关系: 另一类是个体学习器之间不存在强依赖关系. 前者的代表算法就是提升(bo ...
- 梯度提升树(GBDT)原理小结
在集成学习之Adaboost算法原理小结中,我们对Boosting家族的Adaboost算法做了总结,本文就对Boosting家族中另一个重要的算法梯度提升树(Gradient Boosting De ...
- 转载:XGBOOST算法梳理
学习内容: CART树 算法原理 损失函数 分裂结点算法 正则化 对缺失值处理 优缺点 应用场景 sklearn参数 转自:https://zhuanlan.zhihu.com/p/58221959 ...
- 机器学习相关知识整理系列之三:Boosting算法原理,GBDT&XGBoost
1. Boosting算法基本思路 提升方法思路:对于一个复杂的问题,将多个专家的判断进行适当的综合所得出的判断,要比任何一个专家单独判断好.每一步产生一个弱预测模型(如决策树),并加权累加到总模型中 ...
随机推荐
- Python中使用Type hinting 和 annotations
Type hints最大的好处就是易于代码维护.当新成员加入,想要贡献代码时,能减少很多时间. 也方便我们在调用汉书时提供了错误的类型传递导致运行时错误的检测. 第一个类型注解示例 我们使用一个简单例 ...
- express-http-proxy 的基础使用
const app = express() app.use(matchPath, proxy(serverAddress, { proxyReqPathResolver: function(req) ...
- 012 Integer to Roman 整数转换成罗马数字
给定一个整数,将其转为罗马数字.输入保证在 1 到 3999 之间. 详见:https://leetcode.com/problems/integer-to-roman/description/ cl ...
- Storm概念学习系列 之Worker工作者进程
不多说,直接上干货! Worker工作者进程 工作者进程(Worker)是一个java进程,执行拓扑的一部分任务.一个Worker进程执行一个Topology的子集,它会启动一个或多个Execut ...
- 初学makefile
makefile 需要用到 常用命令.shell.正则表达式.gcc,比较综合. 今天写了一个做一个记录,以后系统总结一下. 目录结构:russia---------include.src.mian. ...
- mac-profile
Mac 中定义与Linux一样的profile.d 首先Mac是没有profile.d的 在/etc/profile文件中添加 for sh in /etc/profile.d/*sh; do [ - ...
- HDU 5465——Clarke and puzzle——————【树状数组BIT维护前缀和+Nim博弈】
Clarke and puzzle Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others ...
- 每天学一点ubuntu指令
2017-03-06apt-get | dpkg -i | apt-cache | add-apt-repository ppa源 | dpkg -S一.apt 给Ubuntu安装软件的一种命令方式a ...
- Cucumber 步骤中传Data Table作为参数
引用链接:http://cukes.info/step-definitions.html Data Tables Data Tables are handy for specifying a larg ...
- 【Java】深入理解Java中的spi机制
深入理解Java中的spi机制 SPI全名为Service Provider Interface是JDK内置的一种服务提供发现机制,是Java提供的一套用来被第三方实现或者扩展的API,它可以用来启用 ...