K-D TREE算法原理及实现
博客转载自:https://leileiluoluo.com/posts/kdtree-algorithm-and-implementation.html
k-d tree即k-dimensional tree,常用来作空间划分及近邻搜索,是二叉空间划分树的一个特例。通常,对于维度为k,数据点数为N的数据集,k-d tree适用于N≫2k的情形。
1)k-d tree算法原理
k-d tree是每个节点均为k维数值点的二叉树,其上的每个节点代表一个超平面,该超平面垂直于当前划分维度的坐标轴,并在该维度上将空间划分为两部分,一部分在其左子树,另一部分在其右子树。即若当前节点的划分维度为d,其左子树上所有点在d维的坐标值均小于当前值,右子树上所有点在d维的坐标值均大于等于当前值,本定义对其任意子节点均成立。
1.1)树的构建
一个平衡的k-d tree,其所有叶子节点到根节点的距离近似相等。但一个平衡的k-d tree对最近邻搜索、空间搜索等应用场景并非是最优的。常规的k-d tree的构建过程为:循环依序取数据点的各维度来作为切分维度,取数据点在该维度的中值作为切分超平面,将中值左侧的数据点挂在其左子树,将中值右侧的数据点挂在其右子树。递归处理其子树,直至所有数据点挂载完毕。
a)切分维度选择优化
构建开始前,对比数据点在各维度的分布情况,数据点在某一维度坐标值的方差越大分布越分散,方差越小分布越集中。从方差大的维度开始切分可以取得很好的切分效果及平衡性。
b)中值选择优化
第一种,算法开始前,对原始数据点在所有维度进行一次排序,存储下来,然后在后续的中值选择中,无须每次都对其子集进行排序,提升了性能。
第二种,从原始数据点中随机选择固定数目的点,然后对其进行排序,每次从这些样本点中取中值,来作为分割超平面。该方式在实践中被证明可以取得很好性能及很好的平衡性。本文采用常规的构建方式,以二维平面点(x,y)的集合(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)为例结合下图来说明k-d tree的构建过程。
a)构建根节点时,此时的切分维度为x,如上点集合在x维从小到大排序为(2,3),(4,7),(5,4),(7,2),(8,1),(9,6);其中值为(7,2)。(注:2,4,5,7,8,9在数学中的中值为(5 + 7)/2=6,
但因该算法的中值需在点集合之内,所以本文中值计算用的是len(points)//2=3, points[3]=(7,2))
b)(2,3),(4,7),(5,4)挂在(7,2)节点的左子树,(8,1),(9,6)挂在(7,2)节点的右子树。
c)构建(7,2)节点的左子树时,点集合(2,3),(4,7),(5,4)此时的切分维度为y,中值为(5,4)作为分割平面,(2,3)挂在其左子树,(4,7)挂在其右子树。
d)构建(7,2)节点的右子树时,点集合(8,1),(9,6)此时的切分维度也为y,中值为(9,6)作为分割平面,(8,1)挂在其左子树。至此k-d tree构建完成。
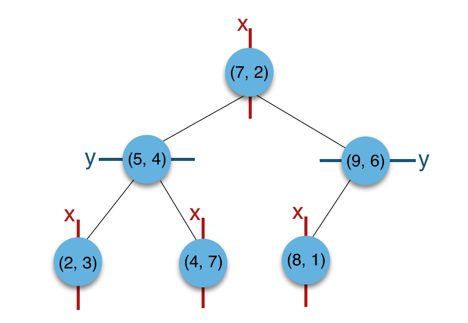
上述的构建过程结合下图可以看出,构建一个k-d tree即是将一个二维平面逐步划分的过程。

我们还可以结合下图(该图引自维基百科),从三维空间来看一下k-d tree的构建及空间划分过程。首先,边框为红色的竖直平面将整个空间划分为两部分,此两部分又分别被边框为绿色的水平平面划分为上下两部分。最后此4个子空间又分别被边框为蓝色的竖直平面分割为两部分,变为8个子空间,此8个子空间即为叶子节点。

如下为k-d tree的构建代码:
def kd_tree(points, depth):
if 0 == len(points):
return None
cutting_dim = depth % len(points[0])
medium_index = len(points) // 2
points.sort(key=itemgetter(cutting_dim))
node = Node(points[medium_index])
node.left = kd_tree(points[:medium_index], depth + 1)
node.right = kd_tree(points[medium_index + 1:], depth + 1)
return node
1.2)寻找d维最小坐标值点
a)若当前节点的切分维度是d
因其右子树节点均大于等于当前节点在d维的坐标值,所以可以忽略其右子树,仅在其左子树进行搜索。若无左子树,当前节点即是最小坐标值节点。
b)若当前节点的切分维度不是d
需在其左子树与右子树分别进行递归搜索。如下为寻找d维最小坐标值点代码:
def findmin(n, depth, cutting_dim, min):
if min is None:
min = n.location
if n is None:
return min
current_cutting_dim = depth % len(min)
if n.location[cutting_dim] < min[cutting_dim]:
min = n.location
if cutting_dim == current_cutting_dim:
return findmin(n.left, depth + 1, cutting_dim, min)
else:
leftmin = findmin(n.left, depth + 1, cutting_dim, min)
rightmin = findmin(n.right, depth + 1, cutting_dim, min)
if leftmin[cutting_dim] > rightmin[cutting_dim]:
return rightmin
else:
return leftmin
1.3)新增节点
从根节点出发,若待插入节点在当前节点切分维度的坐标值小于当前节点在该维度的坐标值时,在其左子树插入;若大于等于当前节点在该维度的坐标值时,在其右子树插入。递归遍历,直至叶子节点。
如下为新增节点代码:
def insert(n, point, depth):
if n is None:
return Node(point)
cutting_dim = depth % len(point)
if point[cutting_dim] < n.location[cutting_dim]:
if n.left is None:
n.left = Node(point)
else:
insert(n.left, point, depth + 1)
else:
if n.right is None:
n.right = Node(point)
else:
insert(n.right, point, depth + 1)
多次新增节点可能引起树的不平衡。不平衡性超过某一阈值时,需进行再平衡。
1.4)删除节点
最简单的方法是将待删节点的所有子节点组成一个新的集合,然后对其进行重新构建。将构建好的子树挂载到被删节点即可。此方法性能不佳,下面考虑优化后的算法。
假设待删节点T的切分维度为x,下面根据待删节点的几类不同情形进行考虑。
a)无子树
本身为叶子节点,直接删除。
b)有右子树
在T.right寻找x切分维度最小的节点p,然后替换被删节点T;递归处理删除节点p。
c)无右子树有左子树
在T.left寻找x切分维度最小的节点p,即p=findmin(T.left, cutting-dim=x),然后用节点p替换被删节点T;将原T.left作为p.right;递归处理删除节点p。(之所以未采用findmax(T.left, cutting-dim=x)节点来替换被删节点,是由于原被删节点的左子树节点存在x维度最大值相等的情形,这样就破坏了左子树在x分割维度的坐标需小于其根节点的定义),如下为删除节点代码
def delete(n, point, depth):
cutting_dim = depth % len(point)
if n.location == point:
if n.right is not None:
n.location = findmin(n.right, depth + 1, cutting_dim, None)
delete(n.right, n.location, depth + 1)
elif n.left is not None:
n.location = findmin(n.left, depth + 1)
delete(n.left, n.location, depth + 1)
n.right = n.left
n.left = None
else:
n = None
else:
if point[cutting_dim] < n.location[cutting_dim]:
delete(n.left, point, depth + 1)
else:
delete(n.right, point, depth + 1)
2)最近邻搜索
给定点p,查询数据集中与其距离最近点的过程即为最近邻搜索。
如在上文构建好的k-d tree上搜索(3,5)的最近邻时,本文结合如下左右两图对二维空间的最近邻搜索过程作分析。
a)首先从根节点(7,2)出发,将当前最近邻设为(7,2),对该k-d tree作深度优先遍历。以(3,5)为圆心,其到(7,2)的距离为半径画圆(多维空间为超球面),可以看出(8,1)右侧的区域与该圆不相交,所以(8,1)的右子树全部忽略。
b)接着走到(7,2)左子树根节点(5,4),与原最近邻对比距离后,更新当前最近邻为(5,4)。以(3,5)为圆心,其到(5,4)的距离为半径画圆,发现(7,2)右侧的区域与该圆不相交,忽略该侧所有节点,这样(7,2)的整个右子树被标记为已忽略。
c)遍历完(5,4)的左右叶子节点,发现与当前最优距离相等,不更新最近邻。所以(3,5)的最近邻为(5,4)。

3)复杂度分析
操作 平均复杂度 最坏复杂度
新增节点 O(logn) O(n)
删除节点 O(logn) O(n)
最近邻搜索 O(logn) O(n)
4)scikit-learn使用
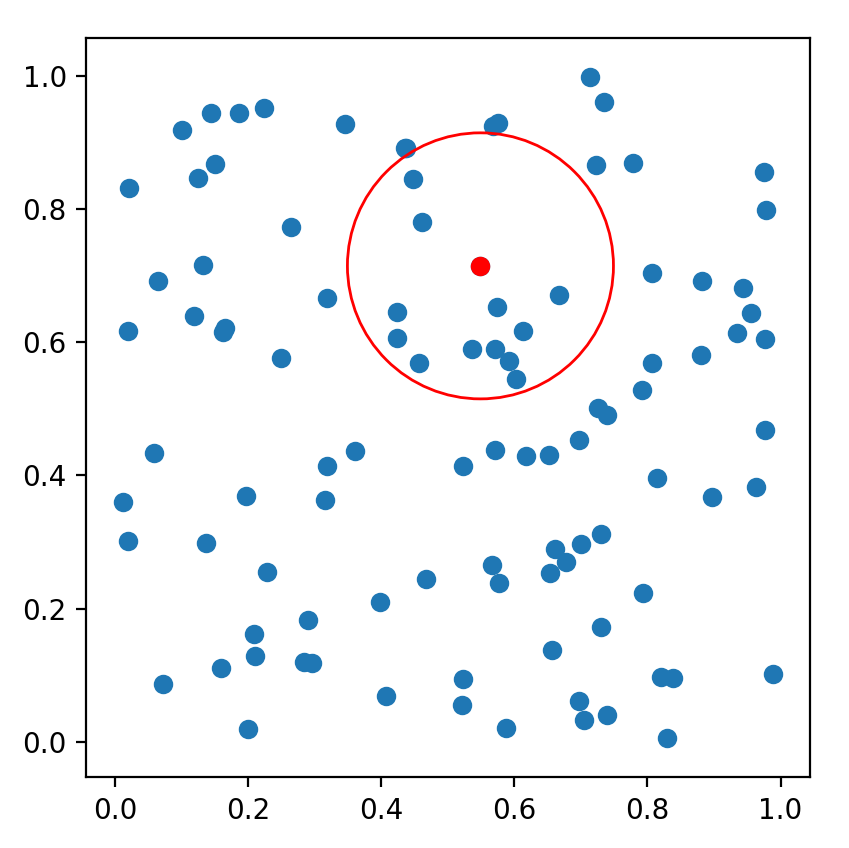
scikit-learn是一个实用的机器学习类库,其有KDTree的实现。如下例子为直观展示,仅构建了一个二维空间的k-d tree,然后对其作k近邻搜索及指定半径的范围搜索。多维空间的检索,调用方式与此例相差无多。如下为最近邻搜索代码:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import numpy as np
from matplotlib import pyplot as plt
from matplotlib.patches import Circle
from sklearn.neighbors import KDTree
np.random.seed(0)
points = np.random.random((100, 2))
tree = KDTree(points)
point = points[0]
# kNN
dists, indices = tree.query([point], k=3)
print(dists, indices)
# query radius
indices = tree.query_radius([point], r=0.2)
print(indices)
fig = plt.figure()
ax = fig.add_subplot(111, aspect='equal')
ax.add_patch(Circle(point, 0.2, color='r', fill=False))
X, Y = [p[0] for p in points], [p[1] for p in points]
plt.scatter(X, Y)
plt.scatter([point[0]], [point[1]], c='r')
plt.show()
参考资料
[1] https://en.wikipedia.org/wiki/K-d_tree
[2] https://www.cs.cmu.edu/~ckingsf/bioinfo-lectures/kdtrees.pdf
[3] https://www.cise.ufl.edu/class/cot5520fa09/CG_RangeKDtrees.pdf
[4] http://www.cs.cornell.edu/courses/cs4780/2017sp/lectures/lecturenote16.html
[5] https://rosettacode.org/wiki/K-d_tree
[6] http://prody.csb.pitt.edu/_modules/prody/kdtree/kdtree.html
[7] http://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KDTree.html
[8] http://www.dcc.fc.up.pt/~pribeiro/aulas/taa1516/rangesearch.pdf
[9] https://courses.cs.washington.edu/courses/cse373/02au/lectures/lecture22l.pdf
[10] http://www.cs.princeton.edu/courses/archive/spr13/cos226/lectures/99GeometricSearch.pdf
[11] http://www.cs.umd.edu/class/spring2002/cmsc420-0401/pbasic.pdf
[12] https://www.ri.cmu.edu/pub_files/pub1/moore_andrew_1991_1/moore_andrew_1991_1.pdf
K-D TREE算法原理及实现的更多相关文章
- FP Tree算法原理总结(转载)
FP Tree算法原理总结 在Apriori算法原理总结中,我们对Apriori算法的原理做了总结.作为一个挖掘频繁项集的算法,Apriori算法需要多次扫描数据,I/O是很大的瓶颈.为了解决这个问题 ...
- FP Tree算法原理总结
在Apriori算法原理总结中,我们对Apriori算法的原理做了总结.作为一个挖掘频繁项集的算法,Apriori算法需要多次扫描数据,I/O是很大的瓶颈.为了解决这个问题,FP Tree算法(也称F ...
- Kd-tree算法原理
参考资料: Kd Tree算法原理 Kd-Tree,即K-dimensional tree,是一棵二叉树,树中存储的是一些K维数据.在一个K维数据集合上构建一棵Kd-Tree代表了对该K维数据集合构成 ...
- K-means算法原理
聚类的基本思想 俗话说"物以类聚,人以群分" 聚类(Clustering)是一种无监督学习(unsupervised learning),简单地说就是把相似的对象归到同一簇中.簇内 ...
- kmeans算法原理以及实践操作(多种k值确定以及如何选取初始点方法)
kmeans一般在数据分析前期使用,选取适当的k,将数据聚类后,然后研究不同聚类下数据的特点. 算法原理: (1) 随机选取k个中心点: (2) 在第j次迭代中,对于每个样本点,选取最近的中心点,归为 ...
- OpenCV学习笔记(27)KAZE 算法原理与源码分析(一)非线性扩散滤波
http://blog.csdn.net/chenyusiyuan/article/details/8710462 OpenCV学习笔记(27)KAZE 算法原理与源码分析(一)非线性扩散滤波 201 ...
- 集成学习值Adaboost算法原理和代码小结(转载)
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类: 第一个是个体学习器之间存在强依赖关系: 另一类是个体学习器之间不存在强依赖关系. 前者的代表算法就是提升(bo ...
- stacking算法原理及代码
stacking算法原理 1:对于Model1,将训练集D分为k份,对于每一份,用剩余数据集训练模型,然后预测出这一份的结果 2:重复上面步骤,直到每一份都预测出来.得到次级模型的训练集 3:得到k份 ...
- 机器学习 KNN算法原理
K近邻(K-nearst neighbors,KNN)是一种基本的机器学习算法,所谓k近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表.比如:判断一个人的人品,只需要观察 ...
随机推荐
- 14 Python 装饰器
装饰器 装饰器其实就是一个以函数作为参数并返回一个替换函数的可执行函数.让我们从简单的开始,直到能写出实用的装饰器. def outer(some_func): def inner(): print ...
- CAP理论、BASE理论
从分布式一致性谈到CAP理论.BASE理论 https://www.cnblogs.com/szlbm/p/5588543.html 问题的提出 在计算机科学领域,分布式一致性是一个相当重要且被广泛探 ...
- bzoj 3771 Triple——FFT
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=3771 把方案作为系数.值作为指数,两项相乘就是系数相乘.指数相加,符合意义. 考虑去重.先自 ...
- Ubuntu 16.04 LTS制作本地源
平时apt-get install安装软件时,下载的deb文件都会存放在/var/cache/apt/archives/下,没有网络时就需要将这些deb制作成本地源.另外,如果在本机架一个简单的网络服 ...
- Azure上采用Powershell从已有的VHD创建VM
刚刚的一篇Blog采用Json Template的方式从已有的VHD创建了一台新的VM.由于Json Template封装的比较好,可以改的内容不多. 下面将介绍通过用Powershell来从已有的V ...
- php system()
学习源头: https://blog.csdn.net/ltx06/article/details/53992905 system(“nohup ./test.py $s &”); 这个不会在 ...
- 如何安装搜索引擎Elasticsearch?
最近工作中要用到搜索引擎,由于目前用的搜索引擎是LeanCloud 提供的 ,不太好用,不支持范围等搜索,而且每天还收费30元,请求次数也有限制.基于这些原因,我们只好在自己的服务器上部署搜索引擎了. ...
- 蓝桥杯 算法训练 ALGO-124 数字三角形
算法训练 数字三角形 时间限制:1.0s 内存限制:256.0MB 问题描述 (图3.1-1)示出了一个数字三角形. 请编一个程序计算从顶至底的某处的一条路 径,使该路径所经过的数字的总和 ...
- ThreadPoolTaskExecutor的配置解释
ThreadPoolTaskExecutor的配置在网上找了很多解释没找到,看了下ThreadPoolExecutor的配置,名字差不多,应该含义也差不多.只不过ThreadPoolTaskExecu ...
- spring--AOP--权限---demo1---bai
AOP权限DEMO1: 实体类: package com.etc.entity; import org.aspectj.lang.annotation.Pointcut; public class U ...