我的ORM框架
任何系统的基础,都可以算是各种数据的增删改查(CRUD)。最早操作数据是直接在代码里写SQL语句,后来出现了各种ORM框架。C#下的ORM框架有很多,如微软自己的Entity Framework、第三方的NHibernate。这些ORM框架甚至可以直接隐去具体SQL语句,让开发人员直接面向持久化后的对象。
虽然这种ORM框架大大简化了开发流程,但也带来了一个很大的问题。开发人员不了解SQL,而有时候这些ORM框架自己生成的SQL语句效率极低。
想象一个场景:
某天DBA说:”那谁谁谁,这个数据操作性能太低,得优化一下。”
开发人员:“这是NHibernate自动生成的,关我屁事”
DBA:“这个查询跨表太多,容易造成死锁,需要修改一下”
开发人员:“这是NHibernate自动生成的SQL,我不会修改啊”
DBA:“%¥…*&(*“
所以在大型项目里,ORM封装的太好,反而有时候会带来问题。说句题外话,微软太照顾开发人员了,各种封装,虽然用起来舒服,开发效率快,但是对于一些特殊场景性能就跟不上。有一次一个团队成员用ASP.net的Treeview控件做树形菜单,生成的Html源代码足足有20M。
我自己用的ORM框架是多层+代码生成器。多层提供数据持久化,代码生成器生成基本的CRUD操作,如果有更复杂的业务,可以扩充。这样既可以封装重复的底层操作,让开发人员集中精力到业务上,也可以提供足够的灵活性。
代码生成器是基于动软代码生成器(http://www.maticsoft.com/codematic.aspx)2.41版本的源码做的二次开发:
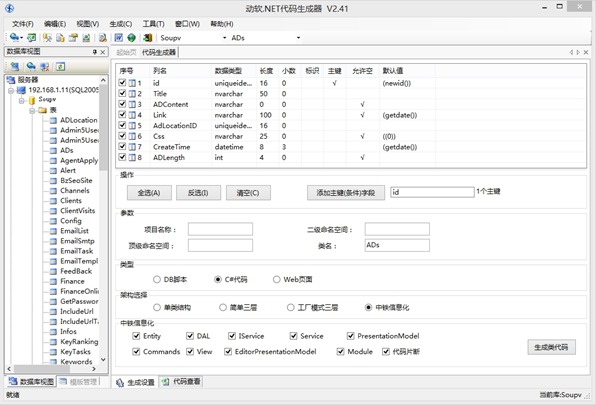
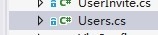
在开发过程中,数据表发生变化,很常见。这样每次都要重新生成三层代码。为了防止新生成的代码覆盖我扩充的方法,可以将使用分部类将扩充方法放到单独一个文件中。举例来说:这有个用户类Users.cs,里面放了有关用户的CRUD:
我有个扩充方法Login,就可以新建一个Users的分部类,名字命名为Users.designer.cs 。VS会自动将这个文件折叠到User.cs的里面:
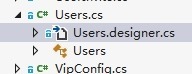
这样我以后即使重新生成代码,也不会覆盖掉扩充方法。
不过我觉得仍然过于繁琐。开发阶段表字段变来变去,每次都要重新覆盖3个文件,老陷入这种重复性的工作,真是有损程序员的清名。仔细考虑下,数据表字段和Model属性是一致的,而CRUD基本上都是对Model的操作。这样依靠反射和泛型两尊大神,可以将SQLHelper做进一步的简化:
- 新增和修改
Dataset构造一个DataRow,把Model中和表字段对应属性的值复制过来,然后提交到数据库。代码如下(同时支持新增和修改。如果数据库存在该记录,为修改,不存在为新增):
public static bool ModelToDatabase(object model, string tabname)
{
Type ObjType = model.GetType();
PropertyInfo[] ObjProInfos = ObjType.GetProperties();
string sql = "";
DataSet ds = null;
DataTable dt = null;
DataRow dr = null;
//检测是新增记录还是修改记录
SqlConnection conn = Conn();
try
{
SqlDataAdapter oda = null;
bool IsEditFlag = false;
//--------------------------
foreach (PropertyInfo ObjProInfo in ObjProInfos)
{
if (ObjProInfo.Name.ToLower() == "id")
{
object IdObject = ObjProInfo.GetValue(model, null);
if (IdObject != null)
{
sql = "select top 1 * from " + tabname + " where id=" + StringPlus.SafeStrN(IdObject.ToString());
oda = new SqlDataAdapter(sql, conn);
ds = new DataSet();
oda.Fill(ds, tabname);
conn.Close();
dt = ds.Tables[0];
if (dt.Rows.Count == 0)
{
dr = dt.NewRow();
IsEditFlag = false;
}
else
{
dr = dt.Rows[0];
IsEditFlag = true;
}
break;
}
else
{
sql = "select top 1 * from " + tabname;
oda = new SqlDataAdapter(sql, conn);
ds = new DataSet();
oda.Fill(ds, tabname);
conn.Close();
dt = ds.Tables[0];
dr = dt.NewRow();
IsEditFlag = false;
break;
}
}
}
//如果不存在ID这一个项,视为新建
if (!IsEditFlag)
{
sql = "select top 1 * from " + tabname;
oda = new SqlDataAdapter(sql, conn);
ds = new DataSet();
oda.Fill(ds, tabname);
conn.Close();
dt = ds.Tables[0];
dr = dt.NewRow();
}
if (conn.State != ConnectionState.Closed)
conn.Close();
//开始构筑一条datarow
ArrayList col = new ArrayList(dt.Columns.Count);
for (int j = 0; j < dt.Columns.Count; j++)
{
col.Add(dt.Columns[j].ColumnName.ToLower());
}
foreach (PropertyInfo ObjProInfo in ObjProInfos)
{
foreach (string DataColumn in col)
{
object objValue = ObjProInfo.GetValue(model, null);
if (DataColumn.ToLower() == ObjProInfo.Name.ToLower())
{
if (objValue != null)
{
dr[ObjProInfo.Name] = objValue;
}
else
{
dr[ObjProInfo.Name] = DBNull.Value;
}
break;
}
}
}
//将更改或新增的记录更新到数据库
if (!IsEditFlag)
{
dt.Rows.Add(dr);
SqlCommandBuilder ocb = new SqlCommandBuilder(oda);
ocb.ConflictOption = ConflictOption.OverwriteChanges;
ocb.QuotePrefix = "[";
ocb.QuoteSuffix = "]";
SqlCommand odc = ocb.GetInsertCommand();
oda.Update(dt);
}
else
{
SqlCommandBuilder ocb = new SqlCommandBuilder(oda);
ocb.ConflictOption = ConflictOption.OverwriteChanges;
ocb.QuotePrefix = "[";
ocb.QuoteSuffix = "]";
SqlCommand odc = ocb.GetInsertCommand();
oda.Update(dt);
}}
</span><span style="color: #0000ff">catch</span><span style="color: #000000"> (Exception)
{ }
</span><span style="color: #0000ff">finally</span><span style="color: #000000">
{
</span><span style="color: #0000ff">if</span> (conn.State !=<span style="color: #000000"> ConnectionState.Closed)
{
conn.Close();
}
}
</span><span style="color: #0000ff">return</span> <span style="color: #0000ff">true</span><span style="color: #000000">;
}
- 获取一个Model
这个是上一个操作的逆操作。先获取DataRow,然后把泛型实体化,通过反射赋值后返回:
/// <summary>
/// 通过一个Sql查询语句返回一个Model
/// </summary>
/// <typeparam name="T"></typeparam>
/// <param name="sql"></param>
/// <returns></returns>
public static T DatabaseToModel<T>(string sql) where T : new()
{
T model = new T();
PropertyInfo[] MyProInfo = model.GetType().GetProperties();
DataSet MyDS = ReturnDataset(sql);
DataTable MyDT = MyDS.Tables[0];
if (MyDT.Rows.Count > 0)
{
DataRow MyDR = MyDT.Rows[0];
foreach (PropertyInfo MyPro in MyProInfo)
{
foreach (DataColumn MyDC in MyDT.Columns)
{
if (MyDC.ColumnName.ToLower() == MyPro.Name.ToLower())
{
if (MyDR[MyDC] != System.DBNull.Value)
{MyPro.SetValue(model, TypeConvertor.ConvertType(MyDR[MyDC], MyPro.PropertyType), </span><span style="color: #0000ff">null</span><span style="color: #000000">);
}
</span><span style="color: #0000ff">else</span><span style="color: #000000">
MyPro.SetValue(model, </span><span style="color: #0000ff">null</span>, <span style="color: #0000ff">null</span><span style="color: #000000">);
}
}
}
</span><span style="color: #0000ff">return</span><span style="color: #000000"> model;
}
</span><span style="color: #0000ff">else</span>
<span style="color: #0000ff">return</span> <span style="color: #0000ff">default</span><span style="color: #000000">(T);
}
- 获取一个List<Model>
用datareader循环读取数据库,然后把每条数据构筑一个Model放到List中返回:
/// <summary>
/// 通过一个SQL检索字符串,返回一个List
/// </summary>
/// <typeparam name="T"></typeparam>
/// <param name="sql"></param>
/// <returns></returns>
public static List<T> DatabaseToModels<T>(string sql) where T : new()
{
List<T> RtnIl = new List<T>();
SqlDataReader sdr = ExecuteReader(sql);
while (sdr.Read())
{
T model = new T();
PropertyInfo[] MyProInfo = model.GetType().GetProperties();
foreach (PropertyInfo MyPro in MyProInfo)
{
for (int i = 0; i < sdr.FieldCount; i++)
{
if (MyPro.Name.ToLower() == sdr.GetName(i).ToLower())
{
if (sdr[i] != System.DBNull.Value)
{
MyPro.SetValue(model, TypeConvertor.ConvertType(sdr[i], MyPro.PropertyType), null);
}
else
{
MyPro.SetValue(model, null, null);
}
break;
}
}
}
RtnIl.Add(model);
}
sdr.Close();
return RtnIl;
}
如此一来,DAL层和BLL层就不会出现和表字段相关的变量。每次修改表后,只需要手动更改Model文件就可以。
如果更进一步偷懒,可以把修改Model写成一个自动化的过程。每次修改表,代码生成器自动去修改Model项目文件下的对应类文件。
当然任何事务都是有局限性的。用反射的问题就是性能会带来一些降低。不过一般系统性能的瓶颈大多数都在数据库和恶劣的业务算法。相比能带来开发效率上的提升,我觉得是非常值得的。
我的ORM框架的更多相关文章
- ASP.NET MVC 使用 Petapoco 微型ORM框架+NpgSql驱动连接 PostgreSQL数据库
前段时间在园子里看到了小蝶惊鸿 发布的有关绿色版的Linux.NET——“Jws.Mono”.由于我对.Net程序跑在Linux上非常感兴趣,自己也看了一些有关mono的资料,但是一直没有时间抽出时间 ...
- 最好的5个Android ORM框架
在开发Android应用时,保存数据有这么几个方式, 一个是本地保存,一个是放在后台(提供API接口),还有一个是放在开放云服务上(如 SyncAdapter 会是一个不错的选择). 对于第一种方式, ...
- [Android]Android端ORM框架——RapidORM(v2.1)
以下内容为原创,欢迎转载,转载请注明 来自天天博客:http://www.cnblogs.com/tiantianbyconan/p/6020412.html [Android]Android端ORM ...
- [Android]Android端ORM框架——RapidORM(v2.0)
以下内容为原创,欢迎转载,转载请注明 来自天天博客:http://www.cnblogs.com/tiantianbyconan/p/5626716.html [Android]Android端ORM ...
- 轻量级ORM框架——第一篇:Dapper快速学习
我们都知道ORM全称叫做Object Relationship Mapper,也就是可以用object来map我们的db,而且市面上的orm框架有很多,其中有一个框架 叫做dapper,而且被称为th ...
- ORM之殇,我们需要什么样的ORM框架?
最近在研究ORM,究竟什么样的框架才是我们想要的 开发框架的意义在于 开发更标准,更统一,不会因为不同人写的代码不一样 开发效率更高,无需重新造轮子,重复无用的代码,同时简化开发流程 运行效率得到控制 ...
- 轻量级ORM框架初探-Dapper与PetaPoco的基本使用
一.EntityFramework EF是传统的ORM框架,也是一个比较重量级的ORM框架.这里仍然使用EF的原因在于为了突出轻量级ORM框架的性能,所谓有对比才有更优的选择. 1.1 准备一张数据库 ...
- ORM框架示例及查询测试,上首页修改版(11种框架)
继上次ORM之殇,我们需要什么样的ORM框架? 整理了11个ORM框架测试示例,通过示例代码和结果,能很容易了解各种框架的特性,优缺点,排名不分先后 EF PDF XCODE CRL NHiberna ...
- [Android]Android端ORM框架——RapidORM(v1.0)
以下内容为原创,欢迎转载,转载请注明 来自天天博客:http://www.cnblogs.com/tiantianbyconan/p/4748077.html Android上主流的ORM框架有很多 ...
- 吉特仓库管理系统-ORM框架的使用
最近在园子里面连续看到几篇关于ORM的文章,其中有两个印象比较深刻<<SqliteSugar>>,另外一篇文章是<<我的开发框架之ORM框架>>, 第一 ...
随机推荐
- gradle 使用本地maven 仓库 和 提交代码到maven
/* * This build file was generated by the Gradle 'init' task. * * This generated file contains a sam ...
- Kibana问题搜集---下载源码,执行npm install 报错
npm ERR! code ELIFECYCLEnpm ERR! errno 1npm ERR! chromedriver@2.34.0 install: `node install.js`npm E ...
- 基于ksoap2-android的soap的封装
实例基于ksoap2-android-assembly-3.3.0-jar-with-dependencies.jar 1:定义回调接口,通过泛型确定返回值类型 package com.ciii.bd ...
- Xshell添加快捷按钮
1.打开xshell,点击[查看],勾[快速命令]: 2.点击xshell右下角[三],选择[添加按钮],在弹出框的“标签栏”和“文本”栏分别输入名称和命令,最后点击[确定]即可.
- python基础之1--Python入门
第1章 Python生态圈 第2章 编程与编程语言 python是一门编程语言,作为学习python的开始,需要事先搞明白:编程的目的是什么?什么是编程语言?什么是编程? 2.1 编程的目的: 计算机 ...
- Maven常见问题总结
Failed to read artifact descriptor for cn.lds.tsp:common:jar 1. 先查看本地repository是否下载成功,如果没有,考虑更改下载rep ...
- linux下重启php服务
有时候修改了一些php配置或者进程满了需要重启php [root@snoopy :: bin]# service php-fpm restart Gracefully shutting down ph ...
- 关于django2.0的外键关系新特性之on_delete!
Django2.0里model外键和一对一的on_delete参数 在django2.0后,定义外键和一对一关系的时候需要加on_delete选项,此参数为了避免两个表里的数据不一致问题,不然会报错: ...
- JQuery 判断滚动条是否到底部
BottomJumpPage: function () { var scrollTop = $(this).scrollTop(); var scrollHeight = $(document).he ...
- JS 获取get请求方式的参数
//获取页面中的参数 name值参数名称(例如:http://localhost:8099/index.aspx?id=10,name则指的是id)function GetQueryString ...