机器学习:评价分类结果(F1 Score)
一、基础
- 疑问1:具体使用算法时,怎么通过精准率和召回率判断算法优劣?
- 根据具体使用场景而定:
- 例1:股票预测,未来该股票是升还是降?业务要求更精准的找到能够上升的股票;此情况下,模型精准率越高越优。
- 例2:病人诊断,就诊人员是否患病?业务要求更全面的找出所有患病的病人,而且尽量不漏掉一个患者;甚至说即使将正常人员判断为病人也没关系,只要不将病人判断成健康人员就好。此情况,模型召回率越高越优。
- 疑问2::有些情况下,即需要考虑精准率又需要考虑召回率,二者所占权重一样,怎么中欧那个判断?
- 方法:采用新的评价标准,F1 Score;
二、F1 Score
- F1 Score:兼顾降准了和召回率,当急需要考虑精准率又需要考虑召回率,可查看模型的 F1 Score,根据 F1 Score 的大小判断模型的优劣;
- F1 = 2 * Precision * recall / (precision + recall),是二者的调和平均值;
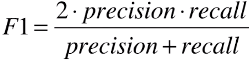
- F1 是 precision 和 recall 的调和平均值;
- 调和平均值:如果 1/a = (1/b + 1/c) / 2,则称 a 是 b 和 c 的调和平均值;
- 调和平均值特点:|b - c| 越大,a 越小;当 b - c = 0 时,a = b = c,a 达到最大值;
- 具体到精准率和召回率,只有当二者大小均衡时,F1 指标才高,
三、F1 Score 的使用
- F1 Score 指标在 scikit-learn 中封装在了 sklearn.metrics 模块下的 f1_score() 方法中
from sklearn.metrics import f1_score f1_score(y_test, y_log_predict)
# 0.8674698795180723 import numpy as np
from sklearn import datasets digits = datasets.load_digits()
X = digits.data
y = digits.target.copy() y[digits.target==9] = 1
y[digits.target!=9] = 0 from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666) from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
y_log_predict = log_reg.predict(X_test) from sklearn.metrics import precision_score
precision_score(y_test, y_log_predict)
# 精准率:0.9473684210526315 from sklearn.metrics import recall_score
recall_score(y_test, y_log_predict)
# 召回率:0.8 from sklearn.metrics import f1_score
f1_score(y_test, y_log_predict)
# F1 Score 指标:0.8674698795180723- 使用scikit-learn 中 sklearn.metrics 模块下的 confusion_matrix()、precision_score()、recall_score()、f1_score() 方法时,所需要的参数都是 y_test、y_predict;
机器学习:评价分类结果(F1 Score)的更多相关文章
- 机器学习中的 precision、recall、accuracy、F1 Score
1. 四个概念定义:TP.FP.TN.FN 先看四个概念定义: - TP,True Positive - FP,False Positive - TN,True Negative - FN,False ...
- 机器学习--如何理解Accuracy, Precision, Recall, F1 score
当我们在谈论一个模型好坏的时候,我们常常会听到准确率(Accuracy)这个词,我们也会听到"如何才能使模型的Accurcy更高".那么是不是准确率最高的模型就一定是最好的模型? 这篇博文会向大家解释 ...
- 机器学习:评价分类结果(Precision - Recall 的平衡、P - R 曲线)
一.Precision - Recall 的平衡 1)基础理论 调整阈值的大小,可以调节精准率和召回率的比重: 阈值:threshold,分类边界值,score > threshold 时分类为 ...
- hihocoder 1522 : F1 Score
题目链接 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 小Hi和他的小伙伴们一起写了很多代码.时间一久有些代码究竟是不是自己写的,小Hi也分辨不出来了. 于是他实现 ...
- 机器学习评价方法 - Recall & Precision
刚开始看这方面论文的时候对于各种评价方法特别困惑,还总是记混,不完全统计下,备忘. 关于召回率和精确率,假设二分类问题,正样本为x,负样本为o: 准确率存在的问题是当正负样本数量不均衡的时候: 精心设 ...
- F1 score,micro F1score,macro F1score 的定义
F1 score,micro F1score,macro F1score 的定义 2018年09月28日 19:30:08 wanglei_1996 阅读数 976 本篇博客可能会继续更新 最近在 ...
- 【笔记】F1 score
F1 score 关于精准率和召回率 精准率和召回率可以很好的评价对于数据极度偏斜的二分类问题的算法,有个问题,毕竟是两个指标,有的时候这两个指标也会产生差异,对于不同的算法,精准率可能高一些,召回率 ...
- 【tf.keras】实现 F1 score、precision、recall 等 metric
tf.keras.metric 里面竟然没有实现 F1 score.recall.precision 等指标,一开始觉得真不可思议.但这是有原因的,这些指标在 batch-wise 上计算都没有意义, ...
- How to compute f1 score for each epoch in Keras
https://medium.com/@thongonary/how-to-compute-f1-score-for-each-epoch-in-keras-a1acd17715a2 https:// ...
随机推荐
- 高通Android display分析【转】
本文转载自:http://blog.csdn.net/zhangchiytu/article/details/6777039 高通7系列硬件架构分析 如上图,高通7系列 Display的硬件部分主要由 ...
- linux上不能显示Jfreechart的图片文件
出现错误: Jan 23, 2015 4:19:21 PM org.apache.catalina.core.StandardWrapperValve invokeSEVERE: Servlet.s ...
- 针对oracle集群的连接配置
Java连接oracle数据库集群的配置:<DB NAME="WFS" DRIVER="oracle.jdbc.driver.OracleDriver" ...
- HBase学习1(hbase基础)
认识NoSQL NoSQL:泛指非关系数据库(Not only SQL) NoSQL两重要特征:使用硬盘和把随机存储器作为存储载体 NoSQL分类(按照存储格式) 1)键值(Key-Value)存储数 ...
- python爬虫-url
特此声明: 以下内容来源于博主:http://blog.csdn.net/pleasecallmewhy http://cuiq ...
- 关于谷歌浏览器(chrome)的一些好用的插件推荐
很多在测试时候都可以使用 第一部分: A:Adblock Plus for Google Chrome™https://chrome.google.com/webstore/detail/cfhdoj ...
- Node.js核心模块_全局变量、util学习
全局对象 javascript的全局对象是window,他及其所有属性都可以在程序的任何地方访问.即全局变量. 而在node中全局对象是global,所有全局变量都是global对象的属性,包括其本身 ...
- 解决:python命令行运行出错 ImportError: No module named ...
一. 发现问题 今天在cmd命令行运行一个py文件,本来在pycharm中运行好好的文件,在命令行却报错了,直接提示我:ImportError: No module named 'homeworks' ...
- HYSBZ - 2038经典莫队算法题
无修改的莫队 emmm莫队的几条性质,必须是离线的,复杂度是n*sqrt(n) 就是通过预处理查询区间,然后从(l,r)转移到(ll,rr),这样的复杂度是曼哈顿距离,即abs(l-ll)+abs(r ...
- The CHECK_POLICY and CHECK_EXPIRATION options cannot be turned OFF when MUST_CHANGE is ON. (Microsoft SQL Server,错误: 15128)
记录下 The CHECK_POLICY and CHECK_EXPIRATION options cannot be turned OFF when MUST_CHANGE is ON. (Micr ...