linux内存查看方法
cat /proc/meminfo
查看RAM使用情况,最简单的方法是通过/proc/meminfo。这个动态更新的虚拟文件实际上是许多其他内存相关工具(如:free / ps / top)等的组合显示。/proc/meminfo列出了所有你想了解的内存的使用情况。进程的内存使用信息也可以通过/proc/<pid>/statm 和 /proc/<pid>/status 来查看。
可以在/proc/<pid>/里查看进程的各种信息
1、free -h/-g/-m
2、htop
3、ps aux --sort -rss
4、ps -aux | sort -k4nr | head -K 如果是10个进程,K=10
swap空间属于磁盘空间的一部分,独立于主分区(C盘)和扩展分区(再分为逻辑分区DEFG),是在内存不足的情况下,临时作为长久未使用程序的内存被释放后暂时存放的地方,当这些长久未被使用的程序再次被激活后,便从swap中读取保存的内容到内存中。说白了,内存不足,释放未激活进程的内存数据到swap中,未激活进程再次激活,从swap再读取数据到内存中
关键字解释:
1、众所周知,现代操作系统都实现了“虚拟内存”这一技术,不但在功能上突破了物理内存的限制,使程序可以操纵大于实际物理内存的空间,更重要的是,“虚拟内存”是隔离每个进程的安全保护网,使每个进程都不受其它程序的干扰。
===============================================================================================================================================================
解释一下Linux上free命令的输出。
下面是free的运行结果,一共有4行。为了方便说明,我加上了列号。这样可以把free的输出看成一个二维数组FO(Free Output)。例如:
- FO[2][1] = 24677460
- FO[3][2] = 10321516
1 2 3 4 5 6
1 total used free shared buffers cached
2 Mem: 7.7G 4.4G 3.3G 452K 30M 548M
3 -/+ buffers/cache: 3.9G 3.8G
4 Swap: 0B 0B 0B
free的输出一共有四行,第四行为交换区的信息,分别是交换的总量(total),使用量(used)和有多少空闲的交换区(free)
free输出的第二行和第三行都是说明内存使用情况的。第一列是总量(total),第二列是使用量(used),第三列是可用量(free)。
第二行的输出是从操作系统(OS)的角度来看的。也就是说,从OS的角度来看,计算机上一共有:
- 24677460KB(缺省时free的单位为KB)物理内存,即FO[2][1];
- 在这些物理内存中有23276064KB(即FO[2][2])被使用了;
- 还用1401396KB(即FO[2][3])是可用的,并不代表应用程序就剩这么内存可用了;
这里得到第一个等式:
- FO[2][1] = FO[2][2] + FO[2][3]
FO[2][4]表示被几个进程共享的内存的,现在已经deprecated,其值总是0(当然在一些系统上也可能不是0,主要取决于free命令是怎么实现的)。
FO[2][5]表示被OS buffer住的内存。FO[2][6]表示被OS cache的内存。在有些时候buffer和cache这两个词经常混用。不过在一些比较低层的软件里是要区分这两个词的,看老外的洋文:
- A buffer is something that has yet to be "written" to disk.
- A cache is something that has been "read" from the disk and stored for later use.
也就是说buffer是用于存放要输出到disk(块设备)的数据的,而cache是存放从disk上读出的数据。这二者是为了提高IO性能的,并由OS管理。
Linux和其他成熟的操作系统(例如windows),为了提高IO read的性能,总是要多cache一些数据,这也就是为什么FO[2][6](cached memory)比较大,而FO[2][3]比较小的原因。我们可以做一个简单的测试:
- 释放掉被系统cache占用的数据;
echo 3>/proc/sys/vm/drop_caches
- 读一个大文件,并记录时间;
- 关闭该文件;
- 重读(从缓存Cache中读)这个大文件,并记录时间;
第二次读应该比第一次快很多。原来我做过一个BerkeleyDB的读操作,大概要读5G的文件,几千万条记录。在我的环境上,第二次读比第一次大概可以快9倍左右。
free输出的第三行是从一个应用程序的角度看系统内存的使用情况。
- 对于FO[3][2],即-buffers/cache,表示一个应用程序认为系统被用掉多少内存;
- 对于FO[3][3],即+buffers/cache,表示一个应用程序认为系统还有多少内存;
因为被系统cache和buffer占用的内存可以被快速回收,所以通常FO[3][3]比FO[2][3]会大很多。
这里还用两个等式:
- FO[3][2] = FO[2][2] - FO[2][5] - FO[2][6]
- FO[3][3] = FO[2][3] + FO[2][5] + FO[2][6]
这二者都不难理解。
free命令由procps.*.rpm提供(在Redhat系列的OS上)。free命令的所有输出值都是从/proc/meminfo中读出的。在系统上可能有meminfo(2)这个函数,它就是为了解析/proc/meminfo的。
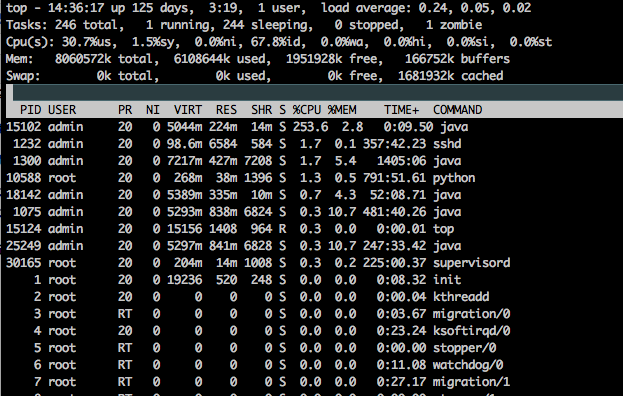
TOP个字段的含义:
- 第一行:14:36:17--系统当前时间;125 days, 3:19--系统启动了多久;1 user--当前登录到系统的用户,更确切的说是登录到用户的终端数,同一个用户同一时间对系统多个终端的连接将被视为多个用户连接到系统,这里的用户数也将表现为终端的数目;load average--为当前系统负载的平均值,后面的三个值分别为1分钟前、5分钟前、15分钟前进程的平均数,一般的可以认为这个数值超过 CPU 数目时,CPU 将比较吃力的负载当前系统所包含的进程;
- 第二行(Tasks):“246 total”为当前系统进程总数;“1 running”为当前运行中的进程数;“244 sleeping”为当前处于等待状态中的进程数;“0 stoped”为被停止的系统进程数;“1 zombie”为被复原的进程数;
- 第三行(Cpus) :分别表示了 CPU 当前的使用率;30.7%us 用户空间占用CPU百分比;1.5%sy 内核空间占用CPU百分比;0.0%ni 用户进程空间内改变过优先级的进程占用CPU百分比;67.8% id 空闲CPU百分比;0.0% wa 等待输入输出的CPU时间百分比;0.0% hi;0.0% si;0.0%st
- 第四行(Mem) :分别表示了内存总量、当前使用量、空闲内存量、以及缓冲使用中的内存量;
- 第五行(Swap) :表示类别同第四行(Mem),但此处反映着交换分区(Swap)的使用情况。通常,交换分区(Swap)被频繁使用的情况,将被视作物理内存不足而造成的。
- 第六行 空行,输入h可以查看帮助信息
- 第七行序号:PID 进程id;PPID 父进程id;RUSER Real user name;UID 进程所有者的用户id;USER 进程所有者的用户名;GROUP 进程所有者的组名;TTY 启动进程的终端名。不是从终端启动的进程则显示为 ? ;PR 优先级;NI nice值。负值表示高优先级,正值表示低优先级;P 最后使用的CPU,仅在多CPU环境 下有意义;%CPU 上次更新到现在的CPU时间占用百分比;TIME 进程使用的CPU时间总计,单位秒 ;TIME+ 进程使用的CPU时间总计,单位1/100秒 ;%MEM 进程使用的物理内存 百分比 ; VIRT 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES ; SWAP 进程使用的虚拟内存中,被换出的大小,单位kb。 RES 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA r CODE 可执行代码占用的物理 内存大小,单位kb ; DATA 可执行代码以外的部分(数据 段+栈)占用的物理 内存大小,单位kb ; SHR 共享内存大小,单位kb ; nFLT 页面错误次数 ; nDRT 最后一次写入到现在,被修改过的页面数。 S 进程状态。D =不可中断的睡眠状态;R =运行; S =睡眠 T =跟踪/停止 Z =僵尸进程 COMMAND 命令名/命令行WCHAN 若该进程在睡眠,则显示睡眠中的系统函数名;Flags 任务标志,参考 sched.h
linux内存查看方法的更多相关文章
- linux 内存查看方法:meminfo\maps\smaps\status 文件解析
linux 下面查看内存有多种渠道,比如通过命令 ps ,top,free 等,比如通过/proc系统,一般需要比较详细和精确地知道整机内存/某个进程内存的使用情况,最好通过/proc 系统,下面介绍 ...
- Linux 内存使用方法详细解析
我是一名程序员,那么我在这里以一个程序员的角度来讲解Linux内存的使用. 一提到内存管理,我们头脑中闪出的两个概念,就是虚拟内存,与物理内存.这两个概念主要来自于linux内核的支持. Linux在 ...
- Linux内存使用方法详细解析
我是一名程序员,那么我在这里以一个程序员的角度来讲解Linux内存的使用. 一提到内存管理,我们头脑中闪出的两个概念,就是虚拟内存,与物理内存.这两个概念主要来自于linux内核的支持. Linux在 ...
- linux内存查看工具
这里帮你总结了一下Linux下查看内存使用情况的多种方法~ 在做 Linux 系统优化的时候,物理内存是其中最重要的一方面.自然的,Linux 也提供了非常多的方法来监控宝贵的内存资源的使用情况.下面 ...
- jvm内存查看方法----个人参考版
查看设置JVM内存信息 1 Runtime.getRuntime().maxMemory(); //最大可用内存,对应-Xmx 2 3 Runtime.getRuntime().freeMemory( ...
- linux内存查看及释放
查看内存 常用的查看内存工具有:top,ps,free,/proc/meminfo,/proc/$PID/status等,一般都指定了虚拟内存占用情况,但ps或/proc/$PID/status中RS ...
- linux内存查看
一般用free命令,显示整体内存使用状况: 第二行从OS角度,used包括内核+应用+buffers+cached使用的内存,buffers/cached是磁盘缓存的大小 第三行从应用角度,可用内存= ...
- linux内存查看、清理、释放命令
echo 1 > /proc/sys/vm/drop_caches 清理前 # free -h total used free shared buffers cached Mem: 19G 19 ...
- (jvm调优)一、linux内存查看命令
转载自https://blog.csdn.net/dongzhongyan/article/details/80067796 开始学习服务器性能查看以及调优 1.整体情况查看(任务管理器):top 第 ...
随机推荐
- CocoaPods 安装与使用
1.如果之前已经安装过的 gem list --local | grep cocoapods 会看到如下输出: cocoapods (1.1.1)cocoapods-deintegrate (1.0. ...
- 【bzoj4719】[Noip2016]天天爱跑步 权值线段树合并
题目描述 给出一棵n个点的树,以及m次操作,每次操作从起点向终点以每秒一条边的速度移动(初始时刻为0),最后对于每个点询问有多少次操作在经过该点的时刻为某值. 输入 第一行有两个整数N和M .其中N代 ...
- LeetCode -- Implement Stacks using Queue
Question: Implement the following operations of a queue using stacks. push(x) -- Push element x to t ...
- Linux临时增加swap空间
linux临时增加swap空间:step 1: #dd if=/dev/zero of=/home/swap bs=1024 count=500000 注释:of=/home/swap,放置swap的 ...
- AGC007 - C Pushing Ball
Description 题目链接 懒得写详细题意了, 放个链接 \(n\le 2*10^5\) 个球, \(n+1\) 个坑, 排成数轴, 球坑交替. 相邻球-坑距离为等差数列 \(d\). 给定首项 ...
- win7 iis 7.0 碰到 503错误,找到的解决方案
Service Unavailable HTTP Error 503. The service is unavailable. 今天要布署一个网站,在自己的电脑上,结果碰到服务器503错误,找应用程序 ...
- http://stormzhang.com/opensource/2016/06/26/android-open-source-project-recommend1/
转载自:http://stormzhang.com/opensource/2016/06/26/android-open-source-project-recommend1/ 推荐他的所有博文~ 图片 ...
- 【IDEA】IDEA断点调试与清除断点
有时候我们必须启动debug模式来进行调试,在IDEA中断点调试与Eclipse大致相同: 1.以debug模式启动服务器: 2.在需要打断点的那一行前面点击一下标记上红点则是有断点,再次点击可以清除 ...
- linux内核情景分析之exit与Wait
//第一层系统调用 asmlinkage long sys_exit(int error_code) { do_exit((error_code&0xff)<<8); } 其主体是 ...
- 给notepad++加nppFtp插件连接ubuntu编写文本
打开notepad++的菜单栏中的插件,如果没有“插件管理”,去https://github.com/ashkulz/NppFTP/releases/tag/v0.27.2,下载对应的版本,将其解压后 ...