Classification of text documents: using a MLComp dataset
注:原文代码链接http://scikit-learn.org/stable/auto_examples/text/mlcomp_sparse_document_classification.html
运行结果为:
Loading 20 newsgroups training set...
20 newsgroups dataset for document classification (http://people.csail.mit.edu/jrennie/20Newsgroups)
13180 documents
20 categories
Extracting features from the dataset using a sparse vectorizer
done in 139.231000s
n_samples: 13180, n_features: 130274
Loading 20 newsgroups test set...
done in 0.000000s
Predicting the labels of the test set...
5648 documents
20 categories
Extracting features from the dataset using the same vectorizer
done in 7.082000s
n_samples: 5648, n_features: 130274
Testbenching a linear classifier...
parameters: {'penalty': 'l2', 'loss': 'hinge', 'alpha': 1e-05, 'fit_intercept': True, 'n_iter': 50}
done in 22.012000s
Percentage of non zeros coef: 30.074190
Predicting the outcomes of the testing set
done in 0.172000s
Classification report on test set for classifier:
SGDClassifier(alpha=1e-05, average=False, class_weight=None, epsilon=0.1,
eta0=0.0, fit_intercept=True, l1_ratio=0.15,
learning_rate='optimal', loss='hinge', n_iter=50, n_jobs=1,
penalty='l2', power_t=0.5, random_state=None, shuffle=True,
verbose=0, warm_start=False) precision recall f1-score support alt.atheism 0.95 0.93 0.94 245
comp.graphics 0.85 0.91 0.88 298
comp.os.ms-windows.misc 0.88 0.88 0.88 292
comp.sys.ibm.pc.hardware 0.82 0.80 0.81 301
comp.sys.mac.hardware 0.90 0.92 0.91 256
comp.windows.x 0.92 0.88 0.90 297
misc.forsale 0.87 0.89 0.88 290
rec.autos 0.93 0.94 0.94 324
rec.motorcycles 0.97 0.97 0.97 294
rec.sport.baseball 0.97 0.97 0.97 315
rec.sport.hockey 0.98 0.99 0.99 302
sci.crypt 0.97 0.96 0.96 297
sci.electronics 0.87 0.89 0.88 313
sci.med 0.97 0.97 0.97 277
sci.space 0.97 0.97 0.97 305
soc.religion.christian 0.95 0.96 0.95 293
talk.politics.guns 0.94 0.94 0.94 246
talk.politics.mideast 0.97 0.99 0.98 296
talk.politics.misc 0.96 0.92 0.94 236
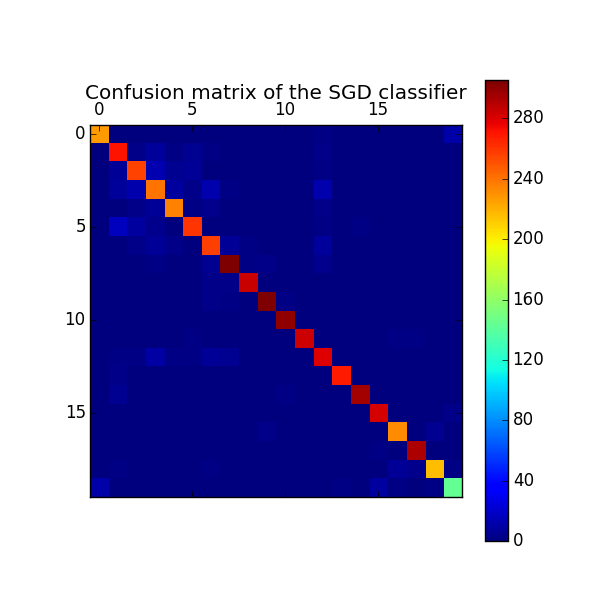
talk.religion.misc 0.89 0.84 0.86 171 avg / total 0.93 0.93 0.93 5648 Confusion matrix:
[[227 0 0 0 0 0 0 0 0 0 0 1 2 1 1 1 0 1
0 11]
[ 0 271 3 8 2 5 2 0 0 1 0 0 3 1 1 0 0 1
0 0]
[ 0 7 256 14 5 6 1 0 0 0 0 0 2 0 1 0 0 0
0 0]
[ 1 8 12 240 9 3 12 2 0 0 0 1 12 0 0 1 0 0
0 0]
[ 0 1 3 6 235 2 4 0 0 0 0 1 3 0 1 0 0 0
0 0]
[ 0 17 9 4 0 260 0 0 1 1 0 0 2 0 2 0 1 0
0 0]
[ 0 1 3 7 3 0 257 7 2 0 0 1 8 0 1 0 0 0
0 0]
[ 0 0 0 2 1 0 5 305 2 3 0 0 4 1 0 0 1 0
0 0]
[ 0 0 0 0 1 0 3 3 285 0 0 0 1 0 0 1 0 0
0 0]
[ 0 0 0 0 0 0 3 2 0 305 2 1 1 0 0 0 0 0
1 0]
[ 0 0 0 0 0 0 1 0 1 0 300 0 0 0 0 0 0 0
0 0]
[ 0 0 1 1 0 2 0 1 0 0 0 284 0 1 1 0 2 2
1 1]
[ 0 2 2 10 2 2 6 5 1 0 1 1 279 1 1 0 0 0
0 0]
[ 0 3 0 0 1 1 1 0 0 0 0 0 0 269 0 1 1 0
0 0]
[ 0 5 0 0 1 0 0 0 0 0 2 0 1 0 295 0 0 0
1 0]
[ 1 1 1 0 0 1 0 1 0 0 0 0 0 1 1 282 1 0
0 3]
[ 0 0 1 0 0 0 0 0 1 3 0 0 1 0 0 1 232 1
5 1]
[ 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 2 0 293
0 0]
[ 0 2 0 0 0 0 2 0 0 1 0 1 0 1 0 0 7 4
216 2]
[ 11 0 0 0 0 0 0 0 0 0 0 1 0 2 0 9 2 1
2 143]]
Testbenching a MultinomialNB classifier...
parameters: {'alpha': 0.01}
done in 0.608000s
Percentage of non zeros coef: 100.000000
Predicting the outcomes of the testing set
done in 0.203000s
Classification report on test set for classifier:
MultinomialNB(alpha=0.01, class_prior=None, fit_prior=True) precision recall f1-score support alt.atheism 0.90 0.92 0.91 245
comp.graphics 0.81 0.89 0.85 298
comp.os.ms-windows.misc 0.87 0.83 0.85 292
comp.sys.ibm.pc.hardware 0.82 0.83 0.83 301
comp.sys.mac.hardware 0.90 0.92 0.91 256
comp.windows.x 0.90 0.89 0.89 297
misc.forsale 0.90 0.84 0.87 290
rec.autos 0.93 0.94 0.93 324
rec.motorcycles 0.98 0.97 0.97 294
rec.sport.baseball 0.97 0.97 0.97 315
rec.sport.hockey 0.97 0.99 0.98 302
sci.crypt 0.95 0.95 0.95 297
sci.electronics 0.90 0.86 0.88 313
sci.med 0.97 0.96 0.97 277
sci.space 0.95 0.97 0.96 305
soc.religion.christian 0.91 0.97 0.94 293
talk.politics.guns 0.89 0.96 0.93 246
talk.politics.mideast 0.95 0.98 0.97 296
talk.politics.misc 0.93 0.87 0.90 236
talk.religion.misc 0.92 0.74 0.82 171 avg / total 0.92 0.92 0.92 5648 Confusion matrix:
[[226 0 0 0 0 0 0 0 0 1 0 0 0 0 2 7 0 0
0 9]
[ 1 266 7 4 1 6 2 2 0 0 0 3 4 1 1 0 0 0
0 0]
[ 0 11 243 22 4 7 1 0 0 0 0 1 2 0 0 0 0 0
1 0]
[ 0 7 12 250 8 4 9 0 0 1 1 0 9 0 0 0 0 0
0 0]
[ 0 3 3 5 235 2 3 1 0 0 0 2 1 0 1 0 0 0
0 0]
[ 0 19 5 3 2 263 0 0 0 0 0 1 0 1 1 0 2 0
0 0]
[ 0 1 4 9 3 1 243 9 2 3 1 0 8 0 0 0 2 2
2 0]
[ 0 0 0 1 1 0 5 304 1 2 0 0 3 2 3 1 1 0
0 0]
[ 0 0 0 0 0 2 2 3 285 0 0 0 1 0 0 0 0 0
0 1]
[ 0 1 0 0 0 1 1 3 0 304 5 0 0 0 0 0 0 0
0 0]
[ 0 0 0 0 0 0 0 0 1 2 299 0 0 0 0 0 0 0
0 0]
[ 0 2 2 1 0 1 2 0 0 0 0 283 1 0 0 0 2 1
2 0]
[ 0 11 1 9 3 1 3 5 1 0 1 4 270 1 3 0 0 0
0 0]
[ 0 2 0 1 1 1 0 0 0 0 0 1 0 266 2 1 0 0
2 0]
[ 0 2 0 0 1 0 0 0 0 0 0 2 1 1 296 0 1 1
0 0]
[ 3 1 0 0 0 0 0 0 0 0 1 0 0 2 0 283 0 1
2 0]
[ 1 0 1 0 0 0 0 0 1 0 0 1 0 0 0 0 237 1
3 1]
[ 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 3 0 291
0 0]
[ 1 1 0 0 1 1 0 1 0 0 0 0 0 0 1 1 17 6
206 0]
[ 18 1 0 0 0 0 0 0 0 1 0 0 0 0 0 14 4 2
4 127]]
步骤为:
一、preprocessing
1.加载训练集(training set)
2.训练集特征提取,用TfidfVectorizer,得到训练集上的x_train和y_train
3.加载测试集(test set)
4.测试集特征提取,用TfidfVectorizer,得到测试集上的x_train和y_train
二、定义Benchmark classifiers
5.训练,clf = clf_class(**params).fit(X_train, y_train)
6.测试,pred = clf.predict(X_test)
7.测试集上分类报告,print(classification_report(y_test, pred,target_names=news_test.target_names))
8.confusion matrix,cm = confusion_matrix(y_test, pred)
三、训练
9.调用两个分类器,SGDClassifier和MultinomialNB

Classification of text documents: using a MLComp dataset的更多相关文章
- Clustering text documents using k-means
源代码的链接为http://scikit-learn.org/stable/auto_examples/text/document_clustering.html Loading 20 newsgro ...
- scikit-learn:4.2.3. Text feature extraction
http://scikit-learn.org/stable/modules/feature_extraction.html 4.2节内容太多,因此将文本特征提取单独作为一块. 1.the bag o ...
- Python scikit-learn机器学习工具包学习笔记
feature_selection模块 Univariate feature selection:单变量的特征选择 单变量特征选择的原理是分别单独的计算每个变量的某个统计指标,根据该指标来判断哪些指标 ...
- 特征选择 (feature_selection)
目录 特征选择 (feature_selection) Filter 1. 移除低方差的特征 (Removing features with low variance) 2. 单变量特征选择 (Uni ...
- sklearn—特征工程
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- scikit-learn:3.3. Model evaluation: quantifying the quality of predictions
參考:http://scikit-learn.org/stable/modules/model_evaluation.html#scoring-parameter 三种方法评估模型的预測质量: Est ...
- [Scikit-learn] 1.1 Generalized Linear Models - Comparing various online solvers
数据集分割 一.Online learning for 手写识别 From: Comparing various online solvers An example showing how diffe ...
- [Scikit-learn] Yield miniBatch for online learning.
From: Out-of-core classification of text documents Code: """ ======================= ...
- sklearn中的模型评估-构建评估函数
1.介绍 有三种不同的方法来评估一个模型的预测质量: estimator的score方法:sklearn中的estimator都具有一个score方法,它提供了一个缺省的评估法则来解决问题. Scor ...
随机推荐
- Sea Battle
Sea Battle time limit per test 1 second memory limit per test 256 megabytes input standard input out ...
- php 四种基础算法 ---- 插入排序法
3.插入排序法 插入排序法思路:将要排序的元素插入到已经 假定排序号的数组的指定位置. 代码: function insert_sort($arr) { //区分 哪部分是已经排序好的 / ...
- 根据key存不存在查询json
select * from table where value->'key' != 'null';
- POJ 1845 Sumdiv (整数拆分+等比快速求和)
当我们拆分完数据以后, A^B的所有约数之和为: sum = [1+p1+p1^2+...+p1^(a1*B)] * [1+p2+p2^2+...+p2^(a2*B)] *...*[1+pn+pn^2 ...
- WindowsAPI 之 CreatePipe、CreateProcess
MSDN介绍 CreatePipe A pipe is a section of shared memory that processes use for communication. The pro ...
- hdu_5711_Ingress(TSP+贪心)
题目连接:hdu5711 这题是 HDU 女生赛最后一题,TSP+贪心,确实不好想,看了wkc巨巨的题解,然后再做的 题解传送门:Ingress #include<cstdio> #inc ...
- 【转】使IFRAME在iOS设备上支持滚动
原文链接: Scroll IFRAMEs on iOS原文日期: 2014年07月02日 翻译日期: 2014年07月10日翻译人员: 铁锚 很长时间以来, iOS设备上Safari中超出边界的元素将 ...
- 利用transform制作幻灯片
html代码 <html><head></head><body><div class='hpic'> <ul style=" ...
- php-fpm配置优化
PHP配置文件php-fpm的优化 2013/06/28 php, php-fpm 应用加速与性能调优 评论 6,029 本文所涉及的配置文件名为PHP-fpm.conf,里面比较重要的配置项有如 ...
- android4.0蓝牙使能的详细解析(转)
源:http://www.cnblogs.com/xiaochao1234/p/3818193.html 本文详细分析了android4.0 中蓝牙使能的过程,相比较android2.3,4.0中的蓝 ...