用python解析word文件(二):table
(二)表格篇(table)(本篇)
选你所需即可。下面开始正文。
docx.tables
cell.text

for t in docx.tables:
# todo
_table_list = []
for i, row in enumerate(table.rows): # 读每行
row_content = []
for cell in row.cells: # 读一行中的所有单元格
c = cell.text
if c not in row_content:
row_content.append(c)
# print(row_content)
_table_list.append(row_content)
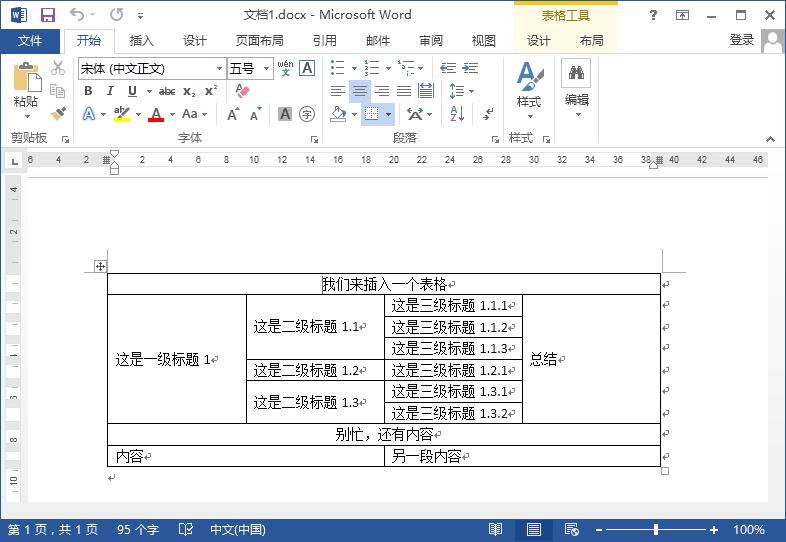
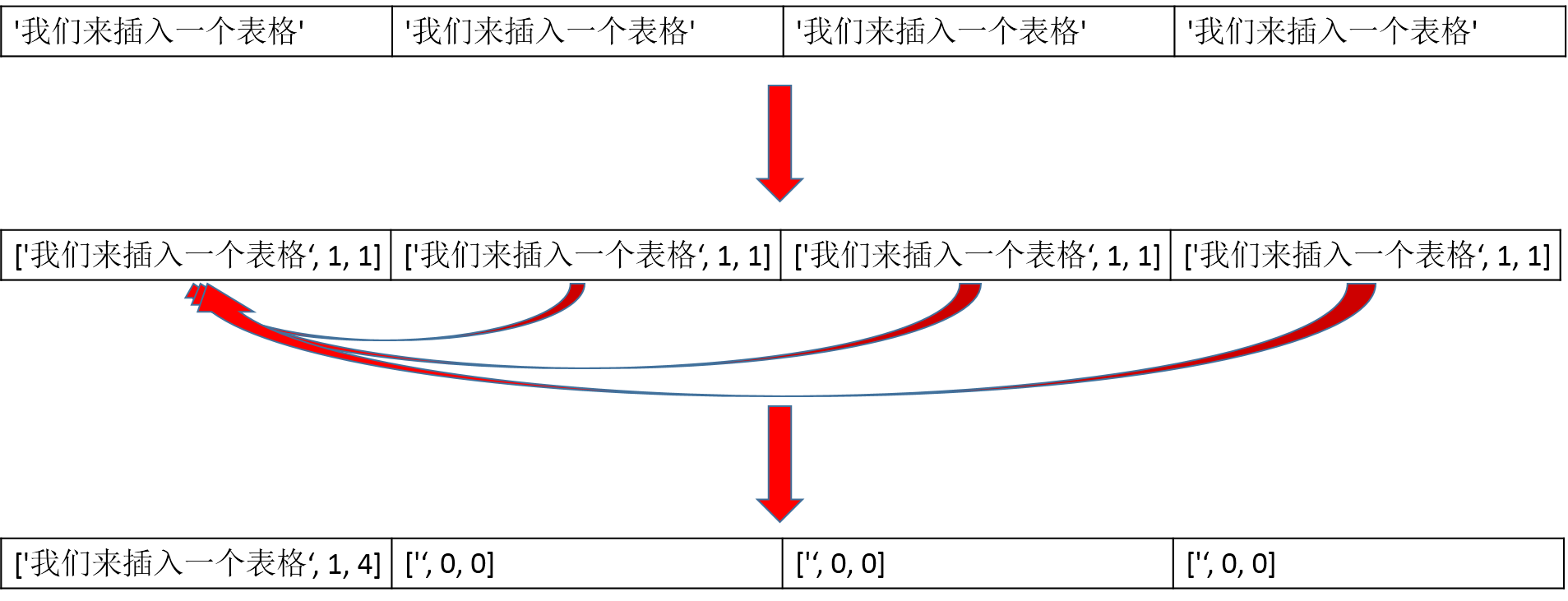
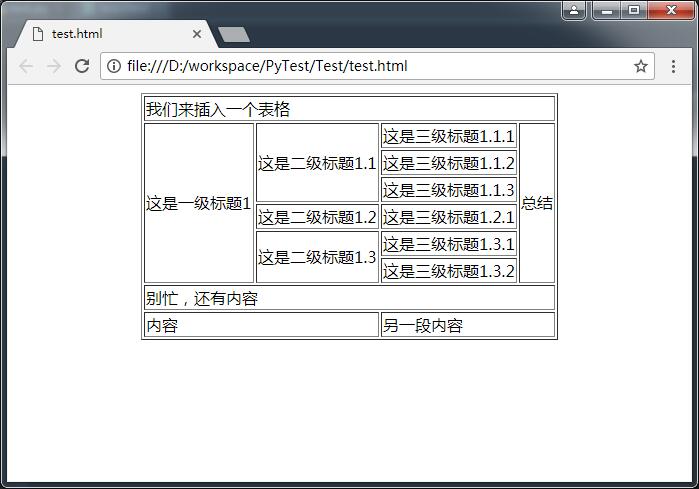
['我们来插入一个表格']
['这是一级标题1', '这是二级标题1.1', '这是三级标题1.1.1', '总结']
['这是一级标题1', '这是二级标题1.1', '这是三级标题1.1.2', '总结']
['这是一级标题1', '这是二级标题1.1', '这是三级标题1.1.3', '总结']
['这是一级标题1', '这是二级标题1.2', '这是三级标题1.2.1', '总结']
['这是一级标题1', '这是二级标题1.3', '这是三级标题1.3.1', '总结']
['这是一级标题1', '这是二级标题1.3', '这是三级标题1.3.2', '总结']
['别忙,还有内容']
['内容', '另一段内容']
def _fill_blank(table):
cols = max([len(i) for i in table]) new_table = []
for i, row in enumerate(table):
new_row = []
[new_row.extend([i] * int(cols / len(row))) for i in row]
print(new_row)
new_table.append(new_row) return new_table
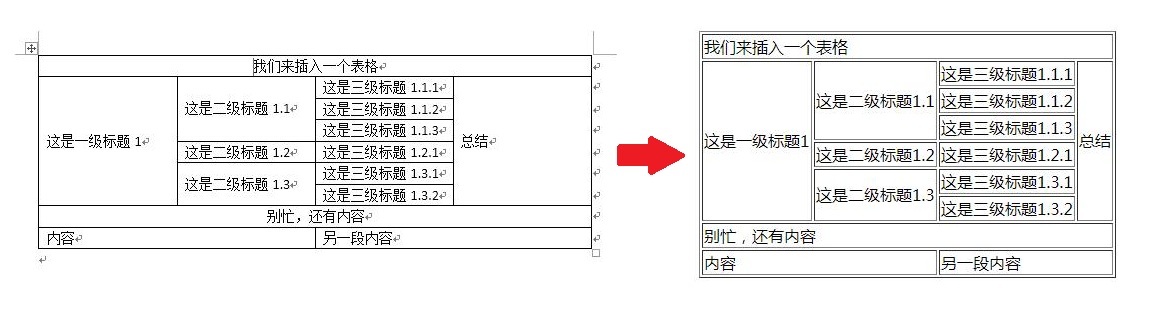
['我们来插入一个表格', '我们来插入一个表格', '我们来插入一个表格', '我们来插入一个表格']
['这是一级标题1', '这是二级标题1.1', '这是三级标题1.1.1', '总结']
['这是一级标题1', '这是二级标题1.1', '这是三级标题1.1.2', '总结']
['这是一级标题1', '这是二级标题1.1', '这是三级标题1.1.3', '总结']
['这是一级标题1', '这是二级标题1.2', '这是三级标题1.2.1', '总结']
['这是一级标题1', '这是二级标题1.3', '这是三级标题1.3.1', '总结']
['这是一级标题1', '这是二级标题1.3', '这是三级标题1.3.2', '总结']
['别忙,还有内容', '别忙,还有内容', '别忙,还有内容', '别忙,还有内容']
['内容', '内容', '另一段内容', '另一段内容']
<table border="1" align="center">
<tr align="center"><td colspan="4">Row One</td></tr>
<tr align="center"><td>Row Two</td><td>Row Two</td><td>Row Two</td><td>Row Two</td></tr>
</table>

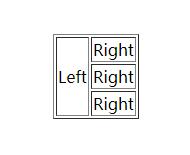
<table border="1" align="center">
<tr><td rowspan="3">Left</td><td>Right</td></tr>
<tr><td>Right</td></tr>
<tr><td>Right</td></tr>
</table>
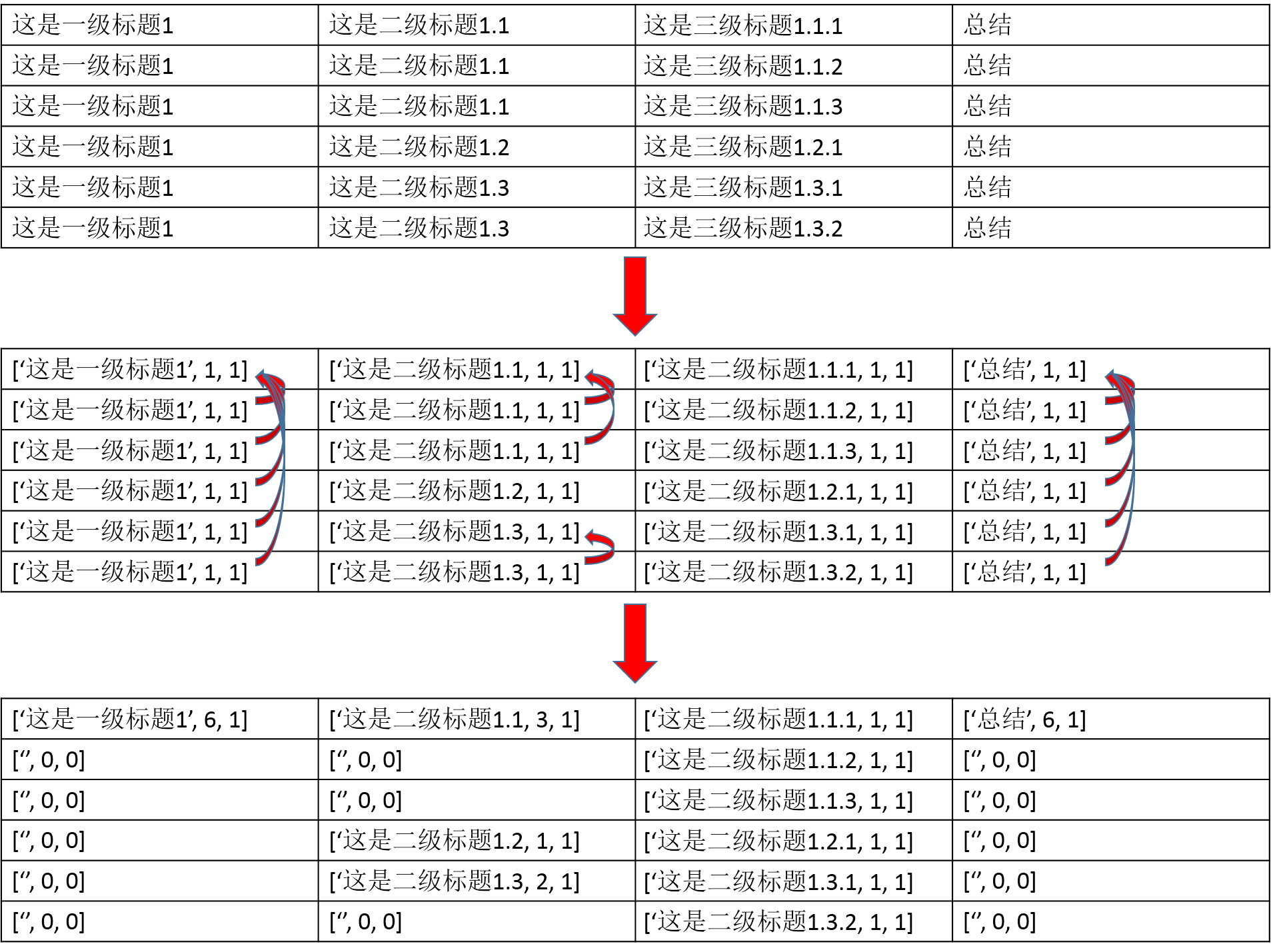
def _table_matrix():
if not table:
return "" # 处理同一行的各列
temp_matrix = []
for row in table:
if not row:
continue col_last = [row[0], 1, 1]
line = [col_last]
for i, j in enumerate(row):
if i == 0:
continue if j == col_last[0]:
col_last[2] += 1
line.append(["", 0, 0])
else:
col_last = [j, 1, 1]
line.append(col_last) temp_matrix.append(line) # 处理不同行
matrix = [temp_matrix[0]]
last_row = []
for i, row in enumerate(temp_matrix):
if i == 0:
last_row.extend(row)
continue new_row = []
for p, r in enumerate(row):
if p >= len(last_row):
break last_pos = last_row[p] if r[0] == last_pos[0] and last_pos[0] != "":
last_row[p][1] += 1
new_row.append(["", 0, 0])
else:
last_row[p] = row[p]
new_row.append(r) matrix.append(new_row) return matrix
def table2html(t):
table = _fill_blank(t)
matrix = _table_matrix(table) html = ""
for row in matrix:
tr = "<tr>"
for col in row:
if col[1] == 0 and col[2] == 0:
continue td = ["<td"]
if col[1] > 1:
td.append(" rowspan=\"%s\"" % col[1])
if col[2] > 1:
td.append(" colspan=\"%s\"" % col[2])
td.append(">%s</td>" % col[0]) tr += "".join(td)
tr += "</tr>"
html += tr return html
{{ table|safe }}
用python解析word文件(二):table的更多相关文章
- 用python解析word文件(一):paragraph
太长了,我决定还是拆开三篇写. (一)段落篇(paragraph)(本篇) (二)表格篇(table) (三)样式篇(style) 选你所需即可.下面开始正文. 最近公司的项目,需要在页面上显示w ...
- 用python解析word文件(三):style
太长了,我决定还是拆开三篇写. (一)段落篇(paragraph) (二)表格篇(table) (三)样式篇(style)(本篇) 选你所需即可.下面开始正文. 在前两篇中,我们已经解析出了par ...
- 用python解析word文件(段落篇(paragraph) 表格篇(table) 样式篇(style))
首先需要安装相应的支持库: 直接在命令行执行pip install python-docx 示例代码如下: import docxfrom docx import Document #导入库 path ...
- 用python读取word文件里的表格信息【华为云技术分享】
在企查查查询企业信息的时候,得到了一些word文件,里面有些控股企业的数据放在表格里,需要我们将其提取出来. word文件看起来很复杂,不方便进行结构化.实际上,一个word文档中大概有这么几种类型的 ...
- Python解析excel文件并存入sqlite数据库
最近由于工作上的需求 需要使用Python解析excel文件并存入sqlite 就此做个总结 功能:1.数据库设计 建立数据库2.Python解析excel文件3.Python读取文件名并解析4.将解 ...
- C#仪器数据文件解析-Word文件(doc、docx)
不少仪器数据报告输出为Word格式文件,同Excel文件,Word文件doc和docx的存储格式是不同的,相应的解析Word文件的方式也类似,主要有以下方式: 1.通过MS Word应用程序的DCOM ...
- Python处理word文件
python对word文件进行读写和复制 import win32conimport win32com.clientimport os #读取word文件def readWoldFile(path): ...
- Python解析Wav文件并绘制波形的方法
资源下载 #本文PDF版下载 Python解析Wav文件并绘制波形的方法 #本文代码下载 Wav波形绘图代码 #本文实例音频文件night.wav下载 音频文件下载 (石进-夜的钢琴曲) 前言 在现在 ...
- 用Python将word文件转换成html(转)
用Python将word文件转换成html 序 最近公司一个客户大大购买了一堆医疗健康方面的科普文章,希望能放到我们正在开发的健康档案管理软件上.客户大大说,要智能推送!要掌握节奏!要深度学习!要 ...
随机推荐
- ASP.NET MVC 获得 view 中的HTML并将其中的内容自动转换成繁体中文。
一.思路 1.获得 asp.net mvc 输出的 html 的字符串. 2.将拿到的 html 字符串中的简体中文转换成繁体中文. 3.输出 html. 二.实现 1.扩展 RazorView 视图 ...
- Xshell基础入门
启动 双击快捷方式,启动 新建回话 建立连接 在这里需要填写的是: 1. 连接名称 2. 服务器IP 3. 服务器端口(默认22) 填写完毕后,点击确定,保存配置,回到连接页面,可以看到多了一个测试服 ...
- MVC登陆认证简单设置
首先,弄个基类 /// <summary> /// 所有控制器基类,里面重写了OnActionExecuted方法 /// </summary> public class Ba ...
- [javaSE] 类型转换(1加1等于几)
打印 ‘a’+1,输出98,解释:’a’是char类型占2个8bit,1是int类型占4个,’a’字符会被自动强制转换为int类型对应ascii码表97 打印’1’+1,输出 50,解释:’1’是ch ...
- java类中成员的初始化顺序(一)
类被创建之后的成员的初始化顺序到底是怎么样的? 首先 不考虑继承 package com; public class DemoOne { /** * 关于类的初始化顺序 */ //不考虑继承结构的情况 ...
- zoj 3286 Very Simple Counting---统计[1,N]相同因子个数
Very Simple Counting Time Limit: 1 Second Memory Limit: 32768 KB Let f(n) be the number of fact ...
- SpringBoot配置文件注入值数据校验
package com.hoje.springboot.bean; import org.springframework.beans.factory.annotation.Value; import ...
- Implementation:Dijkstra
#include <iostream> #include <cstdlib> #include <utility> #include <queue> u ...
- Emscripten编译环境搭建--将C和C++编译成JS
Emscripten编译环境搭建--将C和C++编译成JS 需求:linux环境下用js执行c.c++文件,使用emscirpten编译器 目标:搭建好Emscripten环境 环境:Ubuntu16 ...
- cf1000F. One Occurrence(线段树 set)
题意 题目链接 Sol (真后悔没打这场EDU qwq) 首先把询问离线,预处理每个数的\(pre, nxt\),同时线段树维护\(pre\)(下标是\(pre\),值是\(i\)),同时维护一下最大 ...