BugPhobia回顾篇章:团队Alpha阶段工作分析
0x00:序言
1 universe, 9 planets,
204 countries,809 islands, 7 seas,
and i had the privilege to meet you.
To the searching tags, you may well fall in love with http:// 10.2.26.67
0x01 :敏捷开发原则评估
0x0100:敏捷开发的基本原则
|
(1)尽早并持续地交付有价值的软件以满足顾客需求。 (2)敏捷流程欢迎需求的变化, 并利用这种变化来提高用户的竞争优势。 (3)经常发布可用的软件,发布间隔可以从几周到几个月,能短则短。 (4)业务人员和开发人员在项目开发过程中应该每天共同工作。 (5)无论团队内外,面对面的交流始终是最有效的沟通方式 (6)以有进取心的人为项目核心,充分支持信任他们 (7)可用的软件是衡量项目进展的主要指标 (8)敏捷流程应能保持可持续的发展。 领导, 团队和用户应该能按照目前步调持续合作下去。 )只有不断关注技术和设计才能越来越敏捷. (10)保持简明 - 尽可能简化工作量的技艺 - 极为重要。 )只有能自我管理的团队才能创造优秀的架构, 需求和设计. (12)时时总结如何提高团队效率, 并付诸行动。 |
0x0104:敏捷开发的团队评估
从基本的论述方案中,BugPhobia团队经过严谨论述,分析认为对于以下三方面的原则,团队在敏捷开发阶段感受最为深刻:
|
(5)无论团队内外,面对面的交流始终是最有效的沟通方式 )只有不断关注技术和设计才能越来越敏捷. (12)时时总结如何提高团队效率, 并付诸行动。 |
实际在学霸在线系统Alaph阶段的开发工作中,不妨首先去借用《构建之法》中总结的敏捷原则,去印证团队在软件开发过程中对效率和讨论的专注调研。
在团队敏捷开发的实践过程中,团队本身时刻总结有利于提高我们团队效率的方法,并且切实实践,我们在提升效率的过程中密切关注技术和设计,以使得我们的开发流程整体敏捷效率较高,并呈现稳步上升的趋势。所谓“磨刀不误砍柴工”,基于集市方案的配置,团队架构师致力于尝试新的技术和工具,并且在面对面的交流之中将其推广给团队的所有的开发人员,虽然前期的学习成本不容忽视,甚至由于团队管理疏忽而没有正视高昂的学习成本,使得在软件开发的前期阶段一度陷入“力不能及”的消极工作状态,但尽管万事开头难,一段实践与磨合后开发人员与架构技术得到了很好地融合,从而可以将工具的性能极大地发挥出来。正如《构建之法》中强调的观点,“创造和使用工具是人类和普通动物的最大差别”。我们因为关注技术和设计,敢于尝试新的符合我们需求的技术和工具,我们的团队在开发的过程中越来越能感受得到强大的技术架构带给开发人员的生产力的大解放,而在遭遇Scrum Meeting事件危机后,团队本身迅速机动处理,采用了组内结对编程的方式,进一步提升了效率。

图 1 BugPhobia团队在Alaph阶段结束的过渡期间的“反思与展望“聚餐(捂脸)
在整体的开发流程中,正如“无论团队内外,面对面的交流始终是最有效的沟通方式“所言,通过真正例会的反思和总结,团队本身能够从架构、设计、开发、测试的方向依次评估,从不同角度把握进度本身的影响,尽可能保证此前设计的”流水线“工作方案能够稳定而高效的执行(关于流水线方案的执行效果,详情分析请参阅0x04:设计与实现工作评价),而不同方面的评估,才能依据各流水线的执行状况,不仅可以解决当下的问题,而且也能让组员了解下一步要完成的任务对项目本身的意义所在。这在很大的程度上提升了我们的效率。
暂且抛开书上总结的敏捷原则,Martin Fowler总结的敏捷方法的两个特征在我们组上都有明显的体现:
首先是适应性优于预测性。众所周知,我们的团队的产品是“爬虫—数据处理—在线系统“这条开发流的最末端,按照预测,我们应该是顺着这条“天衣无缝”的流程华丽地完成我们的既定任务的,但是很遗憾由于组间协调的部分问题,团队本身并没有及时获得相应的数据,但是我们可以迅速应变紧急制定出一套自主提供数据的框架方案,在既定路线未正常执行的情况下,能够迅速变更需求,紧急完成Solr和Nutch框架的整体部署和开发,完成独立的数据提供模块,虽未完美,却也问心无愧。
其次是以人为本。提及以人为本,这里按照大众的思路应该都是将“人“设定为”用户“,然而在敏捷开发的阶段,这里Martin Fowler所总结的人,更主要关注的是”开发者“。在整体的开发模式中,团队始终采用集市式的方式进行团队项目的基本管理和开发,因为首先我们的项目是有一个基础原型的(虽然遗留的代码框架被推翻重构,但基本的创意和功能定位仍能体现于具体的代码中),其次我们一直采用集市式的方式进行我们的团队项目,大多数任务几乎都是自己主动要来的。团队内部的大部分人都很积极,任务也大多数都有明确的人真正去负责,每个人选择其自己感兴趣的任务去进行。我们顺利地采用集市式的模式完成了几份高质量的作品。一个人初稿、一个人复审迭代更新、一个人再度审核排版等等,每个人都出于个人的责任、荣誉以及兴趣等复杂情感,深入地参与到了整个过程中。虽然没有非常明确的安排,但是大家都主动承担了某一部分的任务。我们用集市搭建起了一座教堂,团队开发人员的热情非常高,团队的关系非常融洽,大家一起工作斗志十足,效率很高,每一个成员都能在这个团队的协作过程中获得充分的价值体现和归属感。

图 2 BugPhobia团队在Alaph阶段的集市式开发剪影
对于集市式的开发,更为具体的反思与思考同时也可以关注团队内部成员博客反思的展示:
GNU_Linuxer:http://www.cnblogs.com/fzyz999/p/4963681.html
Fihezro:http://www.cnblogs.com/Fengzr/p/4963514.html
PocketPanacea:http://www.cnblogs.com/panacea/p/4966144.html
Whenever:http://www.cnblogs.com/whenever/p/4963109.html
-OwO-:http://www.cnblogs.com/-OwO-/p/4961662.html
Someonefighting:http://www.cnblogs.com/someonefighting/p/4963118.html
SummerMTY:http://www.cnblogs.com/summerMTY/p/4965973.html
0x02 :设想与目标概述
|
ü 我们的软件要解决什么问题?是否定义得很清楚?是否对典型用户和典型场景有清晰的描述? ü 是否有充足的时间来做计划? ü 团队在计划阶段是如何解决同事们对于计划的不同意见的? ü 用户量, 用户对重要功能的接受程度和我们事先的预想一致么? 我们离目标更近了么? |
0x0200:团队需求与实现评价
在此阶段,BugPhobia团队本身再次引用此前的团队需求和分析表格:
|
网站基本定位 |
面向CS/EE领域的垂直搜索引擎 |
|
网站创新形式 |
首先,按照《构建之法》中创新类型的划分,在创新的类型上,我们的产品是改良型的创新,而非颠覆性的创新 |
|
用户基本定位 |
计算机及相关专业学生,其中以大学生群体为最主要的用户群 |
|
用户的知识层次 |
用户具备基本的编程基础,并具备使用通用搜索引擎(百度、谷歌等)的能力 |
|
网站的基本功能 |
网站能够采集专业化社区中的问答数据、高质量课程资源、专业技术文档中的内容,为使用者提供一体化的、精准的、高质量的搜索内容 同时,用户能够通过网站直接参与到上游社区的讨论中 |
从网站的基础功能上,参照此前学长搭建的网站功能(http://www.cnblogs.com/ourteam/p/4225596.html),简单概述而言,完善的用户个性化管理、完备的问答资源爬取、完善的搜索引擎架构已经基本搭建完成,而与此前搭建网站的Beta版本相比,基本功能的实现已经达到50%左右,而目前主要的需求和实现集中于:“学霸后端数据组的数据规范化”(25%的工作量,但在沟通成本上会非常严重,所以这里采取前端两组联谊共同开发后端的方式,然后订制统一的数据接口,以降低此前其他组所提及的工作量),“课程、问答的具体展示页面优化”(25%的工作量,此部分工作比较“泛化”,主要是将此前的模块重新布局,保证符合用户体验),而在此基础上,团队还额外完成了外部搜索引擎的搭建工作、Phobia助手的交互工作、流媒体的播放预览功能等方面。
因此,综合评价整体的需求和实现方向的映射关系:
ü 用户模块部分的设计:用户模块缺乏概念模型的基本构建,但对于已经提及的基本属性已经覆盖;Beta阶段将依据沟通文档(详情请翻阅0x07:沟通工作的进度评价),对这一部分的数据进行json的结构化处理,从而展示与前端的单页应用中
ü 问答模块的设计:基础功能基本搭建完成,从后续的沟通文档中回顾,此部分的设计模型基本符合预期,目前只需要完成Semantic UI向ReactJS的代码迁移工作即可,此部分截至笔者撰写此文时,迁移工作已完成30%左右
ü 课程模块的设计:基本的展示功能搭建完成,但对于具体的数据类型尚无良好的数据结构,因此,此部分需要根据沟通文档对前端方面进行一定程度布局的修改,而非“新功能模块”的开发
ü Phobia助手的设计:基本功能迁移完成,基础的知识库考虑搭建;若沟通进度进展紧张,此部分内容将维持现状
0x0204:时间计划安排和执行情况
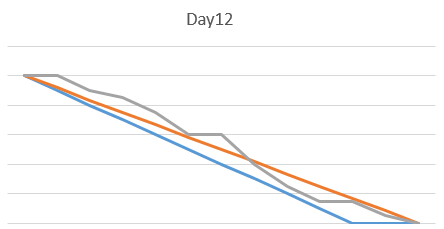
|
燃尽图具体数据说明 |
系列1:预定目标(蓝色直线),是指代预期目标 系列2:实际日均(橙色直线),按照团队本身的实际开发天数,每天应该做到的量 系列3:实际完成(灰色直线),实际完成的工作量 |
从燃尽图的安排中,团队本身对此次的整体任务分配情况进行了一定程度的阐释:
 高昂学习成本的低估
高昂学习成本的低估
在项目开展初期,项目本身并未忽视高昂学习成本,但却严重低估了各框架本身的学习成本,Solr、Nutch、Django、Semantic UI框架本身的配置和学习占用了大量的开发时间;而对应到开发阶段,没有很好地把握学习成本和进展之间的平衡,导致开发前期出现了“前后端脱节”“代码复审质量降低”等问题;因此,在Beta阶段,已经开始将学习任务落实到团队的各个成员的工作上,如ReactJS、Semantic UI等框架的学习工作(分别给出3~5天的学习成本用以中和后期的开发工作)。
 任务分工粒度庞大
任务分工粒度庞大
在此次的燃尽图中,任务按照开发的模块进行划分,例如此前提及的“主页面 —— 用户页面 —— 搜索页面”等方式的模块。但从分工的角度,此阶段的分工粒度较大,导致前期由于数据的匮乏,整体的项目进展缓慢,甚至导致环境配置全部完成后,任务粒度划分较大。因此,在Beta阶段,此次任务分工采用协商的方式,由开发人员完成学习任务的Demo后,给出一定的时间参考,而全部任务排列后,再和具体的负责人协商时间的延长或缩短;进度耽搁后,将严格按照绩效管理进行处理,同时将部分工作量进行转移,保证团队整体进度能够基本按照预期进行燃尽。
 学霸整体系统的流水线需求沟通缺失
学霸整体系统的流水线需求沟通缺失
从此次的学霸整体组别展示效果,由于缺乏一定的协商和沟通,或者说在和另外两组几番讨论后仍未确定数据的基本结构,团队整体的开发陷入了尴尬的停滞阶段(具体细节可以参阅0x0404:流水线开发的冒险与暂停),而此阶段中,团队出于展示效果和严峻的开发周期,最终额外而独立完成了展示数据的结构化爬取和设计。同时,此问题也出现于开发“学霸APP”的Dream组中,根据数据组的基本抱怨,“由于缺乏沟通,我们和APP组的数据定义相差太多”,而导致数据组“心有余而力不足”。因此,在Beta阶段,团队本身将严重重视沟通这一问题,在Alpha阶段向Beta的过渡期(2015/11/17~2015/11/24),团队本身和Dream团队也已经进行了大幅度的沟通工作,从而保证前端组之间能够定义完成的数据接口,并共同同一套后端,以此来充分整合前端两组的工作量,从而保证数据组和爬虫组在数据的格式化和爬取上,降低压力,从而实现团队双赢。
而对于爬虫组、数据组,由于在展示和沟通时,存在“团队本身不提供需求”的误解,此次团队将在近期内发布统一的前后端数据接口,并将需求真正定位到数据层次,再做进一步的讨论。带接口调研完成后,预计于2015/12/1日后开展数据组的沟通工作,此部分沟通工作中,项目经理将全程进行文档备案,并充分保证沟通的高效执行。
 团队成员的责任明确化
团队成员的责任明确化
在此次的团队分工工作中,由于团队整体处理基础的磨合期,导致团队成员对于责任的制度不清晰,在某些事件上(例如经典的BugPhobia’s Scrum Meetings事件),团队成员的对于责任制不存在清晰的定位,导致大量已经完成的Scrum Meeting文档草稿没有按时发布。因此,考虑到集市式本身的弊端,在Beta阶段,项目经理将特别明确任务的警戒时间和基本负责人,一旦这一段时间内的工作进度并无起色,将额外选定有足够能力、且适合完成这一任务的人,进行责任的明确化,从而避免集市式模式失效后直接的崩盘。
0x03 :团队协作与计划核定
|
ü 你原计划的工作是否最后都做完了? 如果有没做完的,为什么? ü 有没有发现你做了一些事后看来没必要或没多大价值的事? ü 是否每一项任务都有清楚定义和衡量的交付件? ü 是否项目的整个过程都按照计划进行,有什么风险是当时没有估计到的,为什么没有估计到? ü 在计划中有没有留下缓冲区,缓冲区有作用么? ü 将来的计划会做什么修改?(例如:缓冲区的定义,加班) |
0x0300:团队集市式管理评价
|
集市式管理方式积极端 |
|
ü 初期根据高昂的学习成本,制定了架构师和团队其他成员的结对编程方案,同时立会时特别依据各人的疑问和困惑进行解答,保证了团队在重构轮子的初期不会因为高昂的学习成本而严重拖延进度; ü 中期根据他组的协商结果,制定了依据“一定原则”的尽可能独立效率编程,虽说在最终的耦合结果并不理想,但此次尝试也基本确立了团队各成员的基本开发方向,开发沟通渠道的思路; ü 后期,根据敏捷开发的剩余需求,采用前后端对接方式的结对编程,极其高效地完成了各部分的收尾工作。
ü 自主申请任务,确保思路灵活,开发高度积极 ü 各任务均存在必要负责人 |
 高效且积极的开发效率
高效且积极的开发效率 管理方式灵活高效
管理方式灵活高效|
集市式管理方式弊端 |
|
ü 每日立会、每日例会、每宿舍例会均是正常进行,无论是初期的结对编程“培训”或是中后期的数据对接上,此方面的立会均能有效保证前后端的高效对接,在一定程度上弥补了中期任务分配失衡的错误;但最核心的问题,就是负责人的指定,也就是责任的单一化!因此,手中积累了大量的松散记录和项目草图,却一直未能有效整合;同时,负责维护的少年也对内容审核过于严苛,导致文档发布拖延造成了严重的后果。现在回顾,若当初能够将责任高度单一化,并确保能力足够,可能进展会更为顺利
ü 我们顺利地采用集市式的模式完成了几份高质量的作品。一个人初稿、一个人复审迭代更新、一个人再度审核排版等等,每个人都出于个人的责任、荣誉以及兴趣等复杂情感,深入地参与到了整个过程中。虽然没有非常明确的安排,但是大家都主动承担了某一部分的任务。我们用集市搭建起了一座教堂。 ü 之前的成功使得我们没能认清楚上面所叙述的一些本质性的东西,从而导致了后面的问题。我认为其中最主要的是第一条:项目必须首先是你感兴趣的,最终对其他人有用的。之前构筑的一系列文档,源自团队中对于文字有执着追求的青年的努力,也源自团队自身开发设计的需求,因此,大家参与得较为深入。特别是一些每个成员都能够用到的文档,比如设计文档、需求分析等等。然而,我们没有认识到'每日立会'的会议记录的作用,因而也没有人对其感兴趣。大家都觉得,这个东西似乎没那么重要,没有给予太多的重视。现在回想起来,我觉得这确实是违背了上面的第一条条件:项目必须首先是自己感兴趣的。没有人愿意关注的东西,自然难以采用集市式的方式进行。于是,在这一次,集市没有起到任何作用,我们一直所倚靠的集市式成了低质量的罪魁祸首。 |
 缺乏高度的责任制管理
缺乏高度的责任制管理 用集市搭建了教堂,却忽视了“兴趣”和“责任”的非等价关系
用集市搭建了教堂,却忽视了“兴趣”和“责任”的非等价关系在经历了这样许多之后,我认为,我们依旧需要坚持我们所一直依赖的集市式模式,它是我们成功的基石。但在此之上,我们必须另想办法解决那些不适用于它的情景。在我看来,一个适合我们团队情况的开发模式是这样的:对于每一个任务或者需求,首先应当尽量采用集市式的思路去完成它。但同时,我们应当设置一个警戒时间。如果超过这个时间依旧没有任何起色,那么就说明集市模式已经不再适用于这个任务或需求了。我们应当综合各方面意见,选定一个特定的,有足够能力的且适合完成这个任务的人。让他为此事负责,这样才能产生足够的质量。从而避免集市式模式失效后直接崩盘的惨痛结果。
0x0304:前端AND 后端
|
前端—后端对接 |
|
ü 从项目本身的架构出发,Seamantic UI的前端框架和Django框架相比,学习成本相对较低,因此不可避免遇到设计—前端的组合进度提前于后端进度;因此,在通过一定的协商规则,让设计—前端组合优先整理需求,并反馈给后端调研可行性,但也导致后期,前后端对接过程两方均做出了一定的修改,同时对接也更加依赖“全栈工程师”协调; |
 “半独立开发”造成冗杂交流
“半独立开发”造成冗杂交流因此,在第二轮迭代的过程中,团队将优先保证设计层次的对接。扩展来讲,前后端将优先以类似“E-R图”的方式进行逻辑层次的设计,同时,尽可能采取阶段性的结对编程,实时完成需求变更的编码实现,具体
0x0308:NOT 任务责任集中/他组协商工作
|
NOT 任务责任集中 |
|
详情可翻阅0x0300:教堂OR集市模式 |
|
NOT 他组协商工作 |
|
|
 考虑中间层的搭建工作(鉴于第一轮迭代的Nutch插件开发思路未被采纳)
考虑中间层的搭建工作(鉴于第一轮迭代的Nutch插件开发思路未被采纳) 优先整合另外两组原有的接口
优先整合另外两组原有的接口 协商额外需求的特性
协商额外需求的特性 及早进行接口、功能方面的沟通和整合
及早进行接口、功能方面的沟通和整合 通过交换人员来建立更有效的沟通渠道
通过交换人员来建立更有效的沟通渠道0x04 :设计与实现工作评价
|
ü 设计工作在什么时候,由谁来完成的?是合适的时间,合适的人么? ü 设计工作有没有碰到模棱两可的情况,团队是如何解决的? ü 团队是否运用单元测试(unit test),测试驱动的开发(TDD)、UML, 或者其他工具来帮助设计和实现?这些工具有效么? ü 什么功能产生的Bug最多,为什么?在发布之后发现了什么重要的bug? 为什么我们在设计/开发的时候没有想到这些情况? ü 代码复审(Code Review)是如何进行的,是否严格执行了代码规范? |
0x0400:团队原定的开发流程
在Alpha阶段的团队开发流程中,团队本身为了减少沟通交流成本,制定了一个流水线式的开发流程:
|
设计:由团队中的原型设计人员梳理需求逻辑,利用Pencil原型工具制作出简易的原型。这个原型图主要展现出页面布局,各个控件、内容的布局,以及整体的页面逻辑。 |
|
前端:原型设计图完成后,交付前端人员实现。前端人员把原型图制成静态页面。用Semantic UI框架来实现原型图中的各处设计。 |
|
后端:页面完成后交付后端人员。后端人员实现后端的功能,然后将静态页面整理成Django模版,并最终让页面“动起来”。 |
|
测试:“动起来”后的页面交由测试人员负责测试(蕴含的单元测试自然由开发人员首先覆盖完成) |
这样的一套开发流程最主要的意图有两个:减少沟通次数,降低学习成本。
在这种流水线式的开发流程中,前端人员可以完全不用接触动态网页部分的知识,只需真正实现清楚的静态页面;而后端人员只需要看着前端人员的页面,将所有的部分整理为Django模版,并在后端实现对应功能即可,无需再和前端人员做太多沟通。同时,利用流水线式的开发让大家的工作尽量可以并行地进行,提供人力资源的利用率。
0x0404:流水线开发的冒险与暂停
|
什么是流水线的冒险和暂停:在计算机组成中,流水线CPU设计式,前后两条指令如果都使用了某个寄存器,则可能导致数据冒险。遇到这种情况,CPU就不得不暂停,即在流水线中插入空指令以规避冒险。 |
团队本身设计的流水线式开发流程也遇到了如同定义所描述的类似问题,然而,在团队开发的初期,由于缺少一定的处理,导致了此流程的流水线被迫陷入流水线的暂停工作。
首先将团队问题映射到“页面设计“阶段,在最初的开发阶段中,由于流水线式开发的核心理念没有传达得太明确,设计人员试图做出一份相当完整的界面设计,甚至将配色和模块精确到像素级别。然而,我们约定使用的Pencil原型绘制软件是绝对做不出类似效果的,而且也并不需要做出那样。由于这样一个传达上的失误,导致了大约半天的拖延。而在此后的设计阶段,团队本身的流水线缺乏了一定的交互,导致设计图本身出的也较慢,这里最重要的交互在于”前端技术实现“和”设计理想实现“的差异,设计人员本身不了解Semantic UI具体的特性和效果,导致前端人员和设计这里很难接洽。因此,在最初的开发阶段,前端人员连同设计的工作一同承担,是流程本身的第一处问题。
然而,团队流程进一步的问题集中到“数据来源“的问题,团队本身并不了解其他两组如何将数据反馈给我们。而经过和另外两组几番讨论,这件事仍旧未能确定下来。导致了整个后端处于完全的停滞状态。我们的流水线开发流程暂停了大量的时间(数天),最后才决心采用自己的数据和框架结构来推动开发稳定实现。而团队本身设计数据和规范数据部分的内容,团队开发才继续执行,而此时距离开发的结束期限已然不多。
总览而言,用最通俗的话语去解释,Alpha阶段开发初期最大的问题就在于数据供给这一部分的停滞。由于和其他组沟通带来的问题,团队的开发节奏略微自乱阵脚。部分同学不知道该去做什么,部分同学想做些事情又无可奈何。
0x0408:结对编程:流水线开发的转机
当开发时间急剧缩短时,流水线开发本身的模式已经难以适应具体的开发工作,因此,考虑到问题本身在于前后端的交流和数据依赖相对缺失,因此,开发流程整体趋向于“结对编程“的方式进行调整。在此阶段,由于团队本身的的Solr和StackExchange本身爬取的数据已经基本到位,并且能够满足开发和展示的部分需求,此时,阻碍后端进展的最大问题已经被妥善解决,进一步所需的工作,就是以最快的速度解决完所有的问题。
此时,我们采用了结对编程这种方案。而在功能的定位和划分上也尽可能通过面对面的交流和文档传递的方式进行解决,同时对于新功能,也采取团队Scrum Meeting协商开发时间和需求定位进行平衡,因此,在敏捷开发阶段,学霸在线系统的基本功能稳步开发和上传,同时,新功能的提议和开发也稳步部署于服务器端和系统端。在此阶段,敏捷开发的效能真正的体现出来了,积蓄已久的“开发势能”,恰到好处地迸发出来。此前,整体的前端页面已经完全准备就绪,而仅仅缺少后端对页面的“动态化“处理,而结对编程很有效地发挥了我们积蓄已久的积极性。
经过了长达几周的磨合,团队成员间相互也非常熟悉了。同时,对于需求的理解也基本达成一致。因此,现实的压力又迫使我们高效地完成余下的任务。结对编程正好有了用武之地。其结对编程效率呈现高度的高效性真正地体现出来,以至于测试人员在这一阶段感慨“敏捷到测试都无法完全执行“
0x040c:Alpha阶段的总结概述
事后总结起来,Alpha阶段最主要的问题还在于前后端耦合度太高,前后端人员没法单独进行开发。我们试图让后端人员接收前端中和后端相关的部分。结果后端开发工作的问题显得十分明显。后端进行不下去的时候,前端只能写写静态页面,而没法帮忙制作Django模版。前后端的分离不好。况且Alpha阶段的最后,团队迫于项目压力,进行了一轮“大跃进”式的开发。结对编程高效是高效,但代码质量着实一般。这轮开发达成的成果是显著的,但与此同时,粗放式的开发也为Beta阶段遗留了一定的问题
0x0410:Beta阶段的过渡与重生
在Alpha阶段,团队对敏捷开发过程的主要问题进行了基本的梳理工作:
|
ü VIEWS代码存在重复,很多函数用于渲染模版的字典是相似的 ü DJHTML的代码有大量重复,主要是很多模版都非常相似 ü JS代码混乱,CSS和JS缺乏有效整理 ü 前后端开发都没有留下相对有效的接口文档 ü 需要其他组统一接口,数据以及APP组都需要能够接到一起 ü 部分UI效果需要重写 |
因此,在基于以上的代码“历史问题“,团队权衡后也给出了一定的解决之道:
首先回顾数据组的基本抱怨:“由于缺乏沟通,我们和APP组的数据定义相差太多“,因此数据组认为目前想支持都非常困难。而学霸APP组本身也在困扰数据的类型和结构等问题。因此,在Beta阶段,如何有效衔接成为了摆在我们这四个组面前的最大问题。因此,基于数据沟通的问题,在过渡阶段,团队本身首先选择了和APP组进行沟通,力图统一我们两组的接口。而统一必然要带来一定的重构。 如何降低重构成本,以及如何沟通,都成为了摆在我们面前的大问题。最终,我们提出了一个相对合理的方案,并且得到了APP组的认可。 双方正在就具体细节进行进一步的沟通。Beta阶段我们的设计方案是这样的,我们可以将整个项目理解为这样:APP和网页全部是学霸项目的一种前端,也就是说,我们可以做一个统一的后端,然后,前端只负责展现以及处理必要的用户逻辑。这样,APP和WEB页面都通过URL调用统一的后端,我们不但接口能够统一 ,而且还能够实现完美的互操作 。那么前后端之间如何沟通呢?回忆起老师当初提及的XML,我们联想到了现在很多网站都在使用的JSON。 前端应用和后端之间采用JSON进行交互,前端的所有功能均通过调用后端API来实现。同时,这里特别回顾社团平台的“WoWoTou“团队,他们采取了前后端分离的设计方案,从最终展示效果观望,这样的开发整体效果很理想,团队的组织很有序。前后端的开发工作就可以实现解耦。同时,由于我们团队本身和Dream组共同开发后端,双方共享了一部分开发力量,所以后端整体的开发成本会降低很多, 可以实现双赢。
因此,基于以上基本情况的铺垫,目前整体的开发流程能够接近于Flux的开发思路。
首先回顾之前的方案,若仍然沿用现有的结构,将前端理解为通过AJAX向后端请求数据的单页应用,很有可能导致项目崩溃,而页面也堆叠为由各种JS和CSS混杂的大泥球。
因此,我们将前端进一步工程化、专业化。引入更现代的前端开发技术:Webpack和ReactJS,而将页面设计为Flux架构的单页应用。
Webpack用于处理各个模块间的依赖关系,处理ReactJS、ES6等,并最终将其编译为可以使用的静态资源;ReactJS是目前我们所能找到的最强力的用于构建数据变化频繁的应用的框架,上手容易,设计简洁;在前端工程化并转换为单页应用后,我们可以获得额外的一些好处:
ü 前后端开发耦合性降低,相互间更为独立
ü 混乱的JS代码可以被整合起来了
ü 后端的代码重复可以得到一定程度的解决(因为后端的重复主要是为了渲染模版。现在前端主动从后端获得数据了,相应问题得到解决)
ü 开发效率提高
Flux架构的思路较为清晰,可以很简单地理清现有前端代码混乱的思路。由官方网站可以看到,Flux架构是对MVC模式的一种创造性的改进。Action由全局唯一的Dispatcher分发到各个Store。 Store负责处理业务逻辑,并更新其所维护的数据。数据的改变最终流向View。View获取到用户输入后触发Action。整个数据流沿着单一的方向流动,程序逻辑十分简洁清晰。
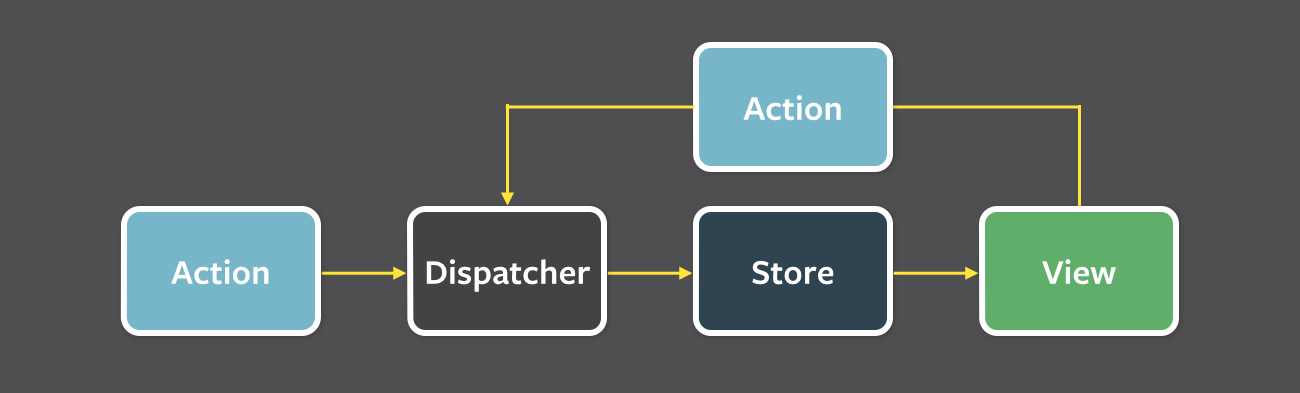
图 3 Flux框架的基本思路和流程图
(特别鸣谢来源:http://facebook.github.io/flux/img/flux-simple-f8-diagram-with-client-action-1300w.png)
0x05 :测试工作计划评价
|
ü 团队是否有一个测试计划?为什么没有? ü 是否进行了正式的验收测试? ü 团队是否有测试工具来帮助测试? ü 团队是如何测量并跟踪软件的效能的?从软件实际运行的结果来看,这些测试工作有用么?应该有哪些改进? ü 在发布的过程中发现了哪些意外问题? |
0x0500:基本测试计划
|
功能测试 |
模拟用户的使用方式进行的测试,属于黑盒测试。在这一阶段的测试中,不通过阅读代码的方式反复尝试所有用户可能的使用方式,探索可能出现的问题。在M1阶段,全员参与到了这一阶段的测试中。测试的项目包括但不限于:所有输入框的输入、页面之间的跳转关系是否正常、资料修改的结果能否保存、Tag云能否进行有效点击、对于一般错误请求能否给出响应等。除此之外,我们还使用修改过的爬虫对网站进行整站链接的访问,确保每一个链接都指向了有效的地址。 测试中出现了一些Bug,其中影响主要功能的均已修复完成,但依然有少量非功能性bug尚待修复。 |
|
安全性测试 |
安全性测试主要进行的是注入测试和csrf攻击测试。在M1阶段,网站存在的主要注入点是输入框(登录注册框和用户资料框)和页面跳转链接。注入测试主要使用了功能全面的Sqlmap和BSQL Hacker,在手工注入阶段使用Burp进行抓包并修改。首先尝试对数据库进行盲注入,探测数据库类型及存在的表,均得不到结果。随后,尝试使用部分信息注入的方式,发现存在有效注入点,反馈给后端人员进行修改。对于csrf攻击,由于django的框架自身存在反攻击措施,均未成功。 |
|
白盒测试 |
在进行完功能测试和安全性测试后,我开始了白盒测试。前段实现采用了Sementic-UI的响应式布局,测试时着重测试了响应式布局的实现是否正确。通过阅读代码不难发现,实现的方式确实满足响应式的方式,但是一些细节的控制还欠缺问题,如Text的宽度可能超过一个grid,导致在响应式生效时可能超出区域,显示出现问题。后端实现使用django框架,功能实现基本正确,但是缺少一些基本的安全防护措施,如对于用户输入的限制只在前段进行,后端不做检查。多数问题在后期反馈后已修复。 |
|
服务器压力测试 |
使用Pylot进行服务器的压力测试。pylot可以指定连接到服务器的客户端数量以及持续的运行时间,可以得到在一段时间内的请求数以及服务器的平均相应时间、各比例的相应时间和无响应数。使用LoadRunner模拟用户的请求,进行连续访问,得到测试结果图。 在全部服务迁移至新的服务器之前,我们使用的阿里云的性能过低,不足以支撑我们需要的功能,因此缺失率极高(保持在50%左右)。在切换至新的服务器后,可以确保满足200用户的并发访问,基本不会出现拒绝服务的情况。 |
0x0504:测试流程反馈的问题
开发前期整体进度较慢,及因此有充足的时间进行代码复审,代码完成的质量也比较高。而进入后期的最终冲刺阶段后,功能更新速度提升,每天都会有很多新的代码,因此复审的工作便落后于代码编写的进度,这直接导致了一部分代码未经过复审就上线发布。然而问题是,这些直接发布的代码质量普遍偏差,可扩充性不好,不满足后期开发的需求。因此,这一段代码我们将在整理阶段进行删减和部分重构。
同时,在Alpha阶段的开发中,单元模块测试明显不足,大量的测试不足以覆盖模块中的所有代码。后期也存在了一部分没有经过单元模块测试就迁入的代码,这都将对应用的稳定性造成很大影响。
0x06 :Bug反馈机制与TDD模式评价
0x0600:Bug分类设定与处理标准
|
Bug |
基本诠释 |
解决方案 |
|
开发级Bug |
个人开发和对接时遇到的BUG,其特点为阻碍开发的进度。同时此类BUG由于单元测试和架构本身,能够很快的发现,涉及的模块较少 |
由于我们采用的集市化管理结对式开发,所以对于个人开发的过程中遇到的bug就两个开发人员想办法解决就是了;然后在对接过程中遇到的问题,大家都会聚到一起来讨论问题的所在,同时解决问题 |
|
测试级Bug |
在测试人员进行测试时遇到的bug,其特点为隐秘,更多的涉及到安全与性能的问题 |
这类问题,我们通常都是测试人员在每日例会上面说明测试发现的bug,然后当场分析可能是谁的模块出了问题,然后相应的人员去进行修复 |
|
用户级Bug |
在发布后用户反馈的bug,其特点为需要尽快的解决,同时在整个项目中涉及的模块比较多 |
当接到用户的反馈时,我们第一时间让架构师负责,因为我们的架构师也是项目的全栈工程师,所以通过他的分析定位出bug的所在,然后再召集相关人员快速处理 |
0x0604:TDD模式反思与评价
|
BUG缺少一定的记录和备案 |
由于我们的bug解决起来还是比较快速的,所以没有去记录遇到的bug,也不明确什么程度的bug需要记录在案。但是在下一个阶段我们会明确这个方面,增加bug的备案 |
|
BUG的解决上缺少问责制度 |
虽然我们能够将bug较快速的解决,但是这个主要原因还是在于我们的全栈能力比较强。所以目前发现一个问题,由于没有明确BUG的责任人和强制的时间要求,所以不能够让bug在独立解决很流畅 |
这里在评价上,给出一定的BUG解决样例作为反思的基础:
ü 在问答展示模块的开发过程就出现了一个BUG,由于有一些VIEWS函数的URL映射是不同的成员开发的,当时出现了CRSF的异常,这是由于几个静态页面导致的,但是当时由于这方面的沟通没有进行好,导致这样的小问题未在单元测试部分解决,而因此重新查找和确认
ü 在测试环节,测试人员进行安全和性能方面的测试后有发现一些问题,但是由于没有找到明确的负责人,从而导致问题最后拖延了一段时间。原因是某些方面的BUG在分工初期是没有能够很好的分工明确的,所以出现了一些BUG之后,而集市模式下的敏捷开发没有很好地去负责
ü 发布后得到反馈的一些问题,其中有一次得到的反馈是注册登陆过程会存在不确定性的失败现象。那是我们将很多问题归到了服务器性能上面,虽然这是一部分的事实,但是还有很大的原因是我们各个队员的当时在磨合情况上确实还不是很好,所以有些模块上人员不断调动,最后在BUG的处理上造成了一定的不灵活性。还有就是发布前的基础功能测试没能很好做到位。
0x07 :沟通工作的进度评价
在此前的0x01~0x06的工作进度中,都大量提及了沟通缺乏这一严峻问题,因此,特别建立0x07模块来特别强调BugPhobia团队和其他团队的沟通状况,以此在Beta阶段记录项目整体的紧张,近期也会将沟通交流阶段的Scrum Meeting(沟通阶段长周期例会)发布至博客中,作为Beta篇章的启程和重生。
|
时间节点记录 |
沟通摘要 |
讨论成果 |
|
2015/11/17~ 2015/11/24 |
l BugPhobia团队和Dream团队决定共同后端进行开发,Dream团队的赵庶宏和BugPhobia团队的冯志睿、王文基将共同开展后端工作的“结对”编程工作 l 网站和APP整合开发需求,共同协商JSON的数据类型,同时将在概念模型完成后抽象为JSON格式的数据接口,方便前后端的共同开发 |
https://github.com/bugphobia/XuebaOnline/ blob/master/需求分析和定位概念模型.md |
BugPhobia回顾篇章:团队Alpha阶段工作分析的更多相关文章
- BugPhobia回顾篇章:团队Beta 阶段工作分析
0x00:序言 1 universe, 9 planets, 204 countries,809 islands, 7 seas, and i had the privilege to meet yo ...
- BugPhobia休息篇章:Beta阶段第IX次Scrum Meeting前奏
特别说明:此次Scrum Meeting不计入正式的Scrum Meeting,因此此次工作仅为第IX次Scrum Meeting的前奏,而笔者也首次采用休息篇章作为子命题 0x01 :Scrum ...
- BugPhobia开发篇章:Beta阶段第II次Scrum Meeting
0x01 :Scrum Meeting基本摘要 Beta阶段第二次Scrum Meeting 敏捷开发起始时间 2015/12/13 00:00 A.M. 敏捷开发终止时间 2015/12/14 22 ...
- BugPhobia开发篇章:Beta阶段第I次Scrum Meeting
0x01 :Scrum Meeting基本摘要 Beta阶段第一次Scrum Meeting 敏捷开发起始时间 2015/12/10 00:00 A.M. 敏捷开发终止时间 2015/12/12 23 ...
- BugPhobia准备篇章:Scrum Meeting工作分析篇
特别说明:此博客不计入正式开发过程的Scrum Meeting篇章,只是工作的基础分析 前端 王鹿鸣.钱林琛撰写初稿 能否前端完成一个页面后就能在本地跑起来进行测试? 能否在前端和后端完成对接后单页面 ...
- 福州大学软件工程1816 | W班 团队Alpha阶段成绩汇总排名(第9、10次作业)
写在前面 汇总成绩排名链接 1.作业链接 第九次作业--项目Alpha冲刺(团队) 第十次作业--事后诸葛亮(团队) 2.评分准则 本次作业包括现场Alpha答辩评分(映射总分为100分)+博客分(总 ...
- [福大2018高级软工教学]团队Alpha阶段成绩汇总
一.作业地址: https://edu.cnblogs.com/campus/fzu/AdvancedSoftwareEngineerning2018/homework/2396 https://ed ...
- 冰多多团队alpha阶段发布说明
标题:冰多多Alpha阶段发布说明 Alpha版本功能介绍 我们项目当前是两个部分,前端编辑器和后端mtermux是分开的,是两个独立的app项目,还没有完美的连起来(我们alpha阶段目标任务是不必 ...
- BugPhobia开发篇章:Beta阶段第VII次Scrum Meeting
0x01 :Scrum Meeting基本摘要 Beta阶段第七次Scrum Meeting 敏捷开发起始时间 2015/12/19 00:00 A.M. 敏捷开发终止时间 2015/12/21 23 ...
随机推荐
- sqoop工具介绍(hdfs与关系型数据库进行数据导入导出)
数据表 第一类:数据库中的数据导入到HDFS上 #数据库驱动jar包用mysql-connector-java--bin,否则有可能报错! ./sqoop import --connect jdbc: ...
- CANopen个人之所见,所想
一直想写一篇关于CANopen的文章,鉴于个人知识能力没有动笔,今天做了一番思想斗争,斗胆发表一下自己对CANOPEN的肤浅认识. 计划从销售人员,技术人员角度都分析一下CANopen的优势,文章可能 ...
- Difference between link and @import
原文don’t use @import Using @import within a stylesheet adds one more roundtrip to the overall downloa ...
- js动态生成水印
原理:通过动态生成canvas然后转为base64格式 代码Demo export const waterMark = (text) =>{ let _wm = document.createE ...
- 与数论的爱恨情仇--01:判断大素数的Miller-Rabin
在我们需要判断一个数是否是素数的时候,最容易想到的就是那个熟悉的O(√n)的算法.那个算法非常的简单易懂,但如果我们仔细想想,当n这个数字很大的时候,这个算法其实是不够用的,时间复杂度会相对比较高. ...
- Linux用户管理及用户信息查询
useradd 创建用户,更改用户信息 1.工作原理流程 使用此命令式,若不加任何参数选项,直接跟用户名,那么系统会首先读取/etc/login.defs(用户定义文件)和/etc/default/u ...
- 关于IRAM和IFLASH启动模式,重映射remap 整理中
工程基于NXP LPC2468 1 为什么试用IRAM MODE 2 设置Program algorithm 编程算法的作用是什么 3 IRAM和FLASH 模式下IROM和IRAM的地址为什么不一样 ...
- 评价指标1--F1值和MSE
1,F1=2*(准确率*召回率)/(准确率+召回率) F1的值是精准率与召回率的调和平均数.F1的取值范围从0到1的数量越大,表明实现越理想. Precision(精准率)=TP/(TP+FP) Re ...
- 洛咕 P2480 [SDOI2010]古代猪文
洛咕 P2480 [SDOI2010]古代猪文 题目是要求\(G^{\sum_{d|n}C^d_n}\). 用费马小定理\(G^{\sum_{d|n}C^d_n\text{mod 999911658} ...
- restful_framework之APIView
一.安装djangorestframework 方式一:pip3 install djangorestframework 方式二:pycharm图形化界面安装 方式三:pycharm命令行下安装(装在 ...