Netty源码分析第7章(编码器和写数据)---->第3节: 写buffer队列
Netty源码分析七章: 编码器和写数据
第三节: 写buffer队列
之前的小节我们介绍过, writeAndFlush方法其实最终会调用write和flush方法
write方法最终会传递到head节点, 调用HeadContext的write方法:
- public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
- unsafe.write(msg, promise);
- }
这里通过unsafe对象的write方法, 将消息写入到缓存中, 具体的执行逻辑, 我们在这个小节进行剖析
我们跟到AbstractUnsafe的write方法中:
- public final void write(Object msg, ChannelPromise promise) {
- assertEventLoop();
- //负责缓冲写进来的byteBuf
- ChannelOutboundBuffer outboundBuffer = this.outboundBuffer;
- if (outboundBuffer == null) {
- safeSetFailure(promise, WRITE_CLOSED_CHANNEL_EXCEPTION);
- ReferenceCountUtil.release(msg);
- return;
- }
- int size;
- try {
- //非堆外内存转化为堆外内存
- msg = filterOutboundMessage(msg);
- size = pipeline.estimatorHandle().size(msg);
- if (size < 0) {
- size = 0;
- }
- } catch (Throwable t) {
- safeSetFailure(promise, t);
- ReferenceCountUtil.release(msg);
- return;
- }
- //插入写队列
- outboundBuffer.addMessage(msg, size, promise);
- }
首先看 ChannelOutboundBuffer outboundBuffer = this.outboundBuffer
ChannelOutboundBuffer的功能就是缓存写入的ByteBuf
我们继续看try块中的 msg = filterOutboundMessage(msg)
这步的意义就是将非对外内存转化为堆外内存
filterOutboundMessage方法方法最终会调用AbstractNioByteChannel中的filterOutboundMessage方法:
- protected final Object filterOutboundMessage(Object msg) {
- if (msg instanceof ByteBuf) {
- ByteBuf buf = (ByteBuf) msg;
- //是堆外内存, 直接返回
- if (buf.isDirect()) {
- return msg;
- }
- return newDirectBuffer(buf);
- }
- if (msg instanceof FileRegion) {
- return msg;
- }
- throw new UnsupportedOperationException(
- "unsupported message type: " + StringUtil.simpleClassName(msg) + EXPECTED_TYPES);
- }
首先判断msg是否byteBuf对象, 如果是, 判断是否堆外内存, 如果是堆外内存, 则直接返回, 否则, 通过newDirectBuffer(buf)这种方式转化为堆外内存
回到write方法中:
outboundBuffer.addMessage(msg, size, promise)将已经转化为堆外内存的msg插入到写队列
我们跟到addMessage方法当中, 这是ChannelOutboundBuffer中的方法:
- public void addMessage(Object msg, int size, ChannelPromise promise) {
- Entry entry = Entry.newInstance(msg, size, total(msg), promise);
- if (tailEntry == null) {
- flushedEntry = null;
- tailEntry = entry;
- } else {
- Entry tail = tailEntry;
- tail.next = entry;
- tailEntry = entry;
- }
- if (unflushedEntry == null) {
- unflushedEntry = entry;
- }
- incrementPendingOutboundBytes(size, false);
- }
首先通过 Entry.newInstance(msg, size, total(msg), promise) 的方式将msg封装成entry
然后通过调整tailEntry, flushedEntry, unflushedEntry三个指针, 完成entry的添加
这三个指针均是ChannelOutboundBuffer的成员变量
flushedEntry指向第一个被flush的entry
unflushedEntry指向第一个未被flush的entry
也就是说, 从flushedEntry到unflushedEntry之间的entry, 都是被已经被flush的entry
tailEntry指向最后一个entry, 也就是从unflushedEntry到tailEntry之间的entry都是没flush的entry
我们回到代码中:
创建了entry之后首先判断尾指针是否为空, 在第一次添加的时候, 均是空, 所以会将flushedEntry设置为null, 并且将尾指针设置为当前创建的entry
最后判断unflushedEntry是否为空, 如果第一次添加这里也是空, 所以这里将unflushedEntry设置为新创建的entry
第一次添加如下图所示
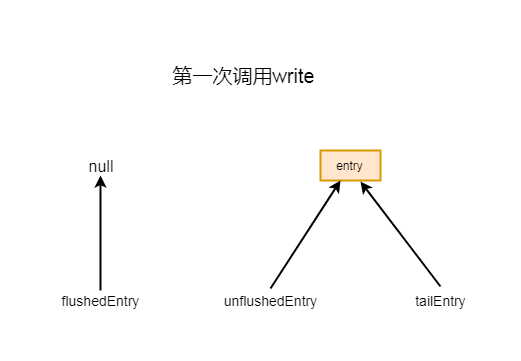
7-3-1
如果不是第一次调用write方法, 则会进入 if (tailEntry == null) 中else块:
Entry tail = tailEntry 这里tail就是当前尾节点
tail.next = entry 代表尾节点的下一个节点指向新创建的entry
tailEntry = entry 将尾节点也指向entry
这样就完成了添加操作, 其实就是将新创建的节点追加到原来尾节点之后
第二次添加 if (unflushedEntry == null) 会返回false, 所以不会进入if块
第二次添加之后指针的指向情况如下图所示:
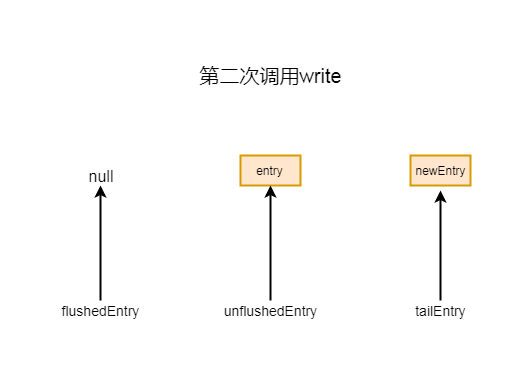
7-3-4
以后每次调用write, 如果没有调用flush的话都会在尾节点之后进行追加
回到代码中, 看这一步incrementPendingOutboundBytes(size, false)
这步时统计当前有多少字节需要被写出, 我们跟到这个方法中:
- private void incrementPendingOutboundBytes(long size, boolean invokeLater) {
- if (size == 0) {
- return;
- }
- //TOTAL_PENDING_SIZE_UPDATER当前缓冲区里面有多少待写的字节
- long newWriteBufferSize = TOTAL_PENDING_SIZE_UPDATER.addAndGet(this, size);
- //getWriteBufferHighWaterMark() 最高不能超过64k
- if (newWriteBufferSize > channel.config().getWriteBufferHighWaterMark()) {
- setUnwritable(invokeLater);
- }
- }
看这一步:
- long newWriteBufferSize = TOTAL_PENDING_SIZE_UPDATER.addAndGet(this, size)
TOTAL_PENDING_SIZE_UPDATER表示当前缓冲区还有多少待写的字节, addAndGet就是将当前的ByteBuf的长度进行累加, 累加到newWriteBufferSize中
在继续看判断 if (newWriteBufferSize > channel.config().getWriteBufferHighWaterMark())
channel.config().getWriteBufferHighWaterMark() 表示写buffer的高水位值, 默认是64k, 也就是说写buffer的最大长度不能超过64k
如果超过了64k, 则会调用setUnwritable(invokeLater)方法设置写状态
我们跟到setUnwritable(invokeLater)方法中:
- private void setUnwritable(boolean invokeLater) {
- for (;;) {
- final int oldValue = unwritable;
- final int newValue = oldValue | 1;
- if (UNWRITABLE_UPDATER.compareAndSet(this, oldValue, newValue)) {
- if (oldValue == 0 && newValue != 0) {
- fireChannelWritabilityChanged(invokeLater);
- }
- break;
- }
- }
- }
这里通过自旋和cas操作, 传播一个ChannelWritabilityChanged事件, 最终会调用handler的channelWritabilityChanged方法进行处理
以上就是写buffer的相关逻辑
Netty源码分析第7章(编码器和写数据)---->第3节: 写buffer队列的更多相关文章
- Netty源码分析第7章(编码器和写数据)---->第1节: writeAndFlush的事件传播
Netty源码分析第七章: 编码器和写数据 概述: 上一小章我们介绍了解码器, 这一章我们介绍编码器 其实编码器和解码器比较类似, 编码器也是一个handler, 并且属于outbounfHandle ...
- Netty源码分析第7章(编码器和写数据)---->第4节: 刷新buffer队列
Netty源码分析第七章: 编码器和写数据 第四节: 刷新buffer队列 上一小节学习了writeAndFlush的write方法, 这一小节我们剖析flush方法 通过前面的学习我们知道, flu ...
- Netty源码分析第7章(编码器和写数据)---->第5节: Future和Promies
Netty源码分析第七章: 编码器和写数据 第五节: Future和Promise Netty中的Future, 其实类似于jdk的Future, 用于异步获取执行结果 Promise则相当于一个被观 ...
- Netty源码分析第7章(编码器和写数据)---->第2节: MessageToByteEncoder
Netty源码分析第七章: Netty源码分析 第二节: MessageToByteEncoder 同解码器一样, 编码器中也有一个抽象类叫MessageToByteEncoder, 其中定义了编码器 ...
- Netty源码分析第6章(解码器)---->第1节: ByteToMessageDecoder
Netty源码分析第六章: 解码器 概述: 在我们上一个章节遗留过一个问题, 就是如果Server在读取客户端的数据的时候, 如果一次读取不完整, 就触发channelRead事件, 那么Netty是 ...
- Netty源码分析第3章(客户端接入流程)---->第1节: 初始化NioSockectChannelConfig
Netty源码分析第三章: 客户端接入流程 概述: 之前的章节学习了server启动以及eventLoop相关的逻辑, eventLoop轮询到客户端接入事件之后是如何处理的?这一章我们循序渐进, 带 ...
- Netty源码分析第3章(客户端接入流程)---->第2节: 处理接入事件之handle的创建
Netty源码分析第三章: 客户端接入流程 第二节: 处理接入事件之handle的创建 上一小节我们剖析完成了与channel绑定的ChannelConfig初始化相关的流程, 这一小节继续剖析客户端 ...
- Netty源码分析第3章(客户端接入流程)---->第3节: NioSocketChannel的创建
Netty源码分析第三章: 客户端接入流程 第三节: NioSocketChannel的创建 回到上一小节的read()方法: public void read() { //必须是NioEventLo ...
- Netty源码分析第3章(客户端接入流程)---->第4节: NioSocketChannel注册到selector
Netty源码分析第三章: 客户端接入流程 第四节: NioSocketChannel注册到selector 我们回到最初的NioMessageUnsafe的read()方法: public void ...
随机推荐
- Hadoop学习之路(五)Hadoop集群搭建模式和各模式问题
分布式集群的通用问题 当前的HDFS和YARN都是一主多从的分布式架构,主从节点---管理者和工作者 问题:如果主节点或是管理者宕机了.会出现什么问题? 群龙无首,整个集群不可用.所以在一主多从的架构 ...
- Day1 Java编程环境和变量
什么是软件? 软件的基本组成部分是完成其功能的程序. 在日程生活中,可以将程序看成对一系列动作的执行过程的描述. 什么是计算机程序? 为了让计算机执行某些操作或解决某个问题二编写的一系列有序指令的集合 ...
- C语言程序设计I—第七周教学
第七周教学总结(14/10-20/10) 教学内容 第二章 用C语言编写程序 2.5 生成乘方表和阶乘表 课前准备 在蓝墨云班课发布资源: PTA:2018秋第七周作业 分享码:FE065DC5D8C ...
- 第12章 GPIO输入-按键检测—零死角玩转STM32-F429系列
第12章 GPIO输入—按键检测 全套200集视频教程和1000页PDF教程请到秉火论坛下载:www.firebbs.cn 野火视频教程优酷观看网址:http://i.youku.com/fi ...
- C#只能lock 引用类型的值 (转载)
Lock: C#只能lock 引用类型的值,如果lock一个int, bool,编译器会报错. 当一个互斥锁已被占用时,在同一线程中执行的代码仍可以获取和释放该锁.但是,在其他线程 ...
- Missing artifact com.sun:tools:jar:1.5.0解决的方法
前一阵子下了最新的JavaEE版本号的eclipse,导入mavenproject之后,pom文件一直报Missing artifact com.sun:tools:jar:1.5.0.非常纳闷,to ...
- SQL AND & OR 运算符
AND 和 OR 运算符用于基于一个以上的条件对记录进行过滤. AND 和 OR 运算符 AND 和 OR 可在 WHERE 子语句中把两个或多个条件结合起来. 假设第一个条件和第二个条件都成立,则 ...
- cocoapods导入三方库头文件找不到问题
问题描述:使用cocoapods时,import 找不到头文件. 问题原因: 1.缓存导致 2.没设置头文件的目录. 1.解决办法: command + k 清理工程 ,找到DerivedData文件 ...
- OC 知识:彻底理解 iOS 内存管理(MRC、ARC)
1. 什么是内存管理 程序在运行的过程中通常通过以下行为,来增加程序的的内存占用 创建一个OC对象 定义一个变量 调用一个函数或者方法 而一个移动设备的内存是有限的,每个软件所能占用的内存也是有限的 ...
- Hadoop(18)-MapReduce框架原理-WritableComparable排序和GroupingComparator分组
1.排序概述 2.排序分类 3.WritableComparable案例 这个文件,是大数据-Hadoop生态(12)-Hadoop序列化和源码追踪的输出文件,可以看到,文件根据key,也就是手机号进 ...