深度学习之神经网络核心原理与算法-caffe&keras框架图片分类
之前我们在使用cnn做图片分类的时候使用了CIFAR-10数据集
其他框架对于CIFAR-10的图片分类是怎么做的
来与TensorFlow做对比。
Caffe Keras
安装
官方安装文档:
https://github.com/IraAI/caffe-gpu-installation
https://github.com/BVLC/caffe/tree/windows
windows下安装gpu加速版的caffe

mark
使用的数据集依然是CIFAR-10,使用的也依然是卷积神经网络。查看有什么不同点和相同点。
十种分类。
准备数据
把图片转成leveldb格式,对图片做均值。

mark
里面是一个官方给出来的例子,如何使用caffe 对cifar10做分类。
caffe-master/examples/cifar10/create_cifar10.sh
是一个bash脚本: 作用是转换cifar数据到 into leveldb format.
定义了两个目录变量和数据类型
EXAMPLE=examples/cifar10
DATA=data/cifar10
DBTYPE=lmdb
删除指定目录下的文件
echo "Creating $DBTYPE..."rm -rf $EXAMPLE/cifar10_train_$DBTYPE $EXAMPLE/cifar10_test_$DBTYPE
调用了convert_cifar_data.bin 二进制文件。 指定参数,就可以下载,解压,格式化。
计算图片的均值。compute_image_mean 输入参数 backend: 数据类型。
计算均值,保存到mean.binaryproto文件中
将数据转换为lmdb格式,保存到磁盘中。
计算image文件的均值。保存。
这里用到的两个命令是c++编写的,也可以阅读源代码变成python脚本。
网上也有这个数据脚本的python实现代码
http://research.beenfrog.com/code/2015/05/04/write-leveldb-lmdb-using-python.html
就是根据c++代码改写的。这两个数据格式都是键值对的格式。
训练模型
caffe-master/examples/cifar10/train_quick.sh
#!/usr/bin/env shset -e TOOLS=./build/tools
定义一个存放的目录
调用tools目录下的caffe 主程序。
$TOOLS/caffe train \
--solver=examples/cifar10/cifar10_quick_solver.prototxt $@
第一个参数指定训练,第二个参数指定模型
cifar10_quick_solver.prototxt
超参数和模型的结构定义与描述。
# The train/test net protocol buffer definitionnet: "examples/cifar10/cifar10_quick_train_test.prototxt"
网络结构:
caffe-master/examples/cifar10/cifar10_quick_train_test.prototxt
我们在使用TensorFlow时是使用python脚本定义的网络结构。有多少层什么的。
caffe使用一个描述文件来描述。
第二次的时候从第一次的模型快照处继续运行。
# reduce learning rate by factor of 10 after 8 epochs$TOOLS/caffe train \
--solver=examples/cifar10/cifar10_quick_solver_lr1.prototxt \
--snapshot=examples/cifar10/cifar10_quick_iter_4000.solverstate $@
两次的变化只是学习率不同。
模型的描述文件

mark
训练参数,初始化参数: 网络描述
caffe中有方法可以将模型的描述文件打印成图表
caffe-master/examples/cifar10/cifar10_quick_train_test.prototxt
http://ethereon.github.io/netscope/#/editor
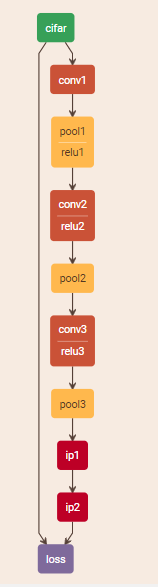
mark
第一层是数据层。卷积层 池层 卷积层 池层 全连接 激励函数。 softmax
本地版本:
https://graphviz.gitlab.io/_pages/Download/Download_windows.html# 下载Graphvizpip install pydot
python draw_net.py C:\Users\mtian\PycharmProjects\NeuralNetworksGetStarted\caffe-master\examples\cifar10\cifar10_quick_train_test.prototxt ./cifar.png
运行的画图py文件,位于caffe python下。
三个参数: 1. 网络模型的ProtoTXT文件 2. 保存的图片路径 3. 从左到右。
–rankdir=x , x 有四种选项,分别是LR, RL, TB, BT 。
画图报错:
Traceback (most recent call last):
File "draw_net.py", line 9, in <module> import caffe.draw
File "C:\software\caffe\python\caffe\draw.py", line 31, in <module>
pydot_find_graphviz = pydot.graphviz.find_graphviz
AttributeError: module 'pydot_ng' has no attribute 'graphviz'
查看这个文件可以看到里面写着解决方案
pip install pydot-plustry: # Try to load pydotplus
import pydotplus as pydot
给这个描述文件起一个名字
name: "CIFAR10_quick"
定义每一层,名字,类型,top有两个一个是data 一个是label。数据层的top有两个
layer {
name: "cifar"
type: "Data"
top: "data"
top: "label"
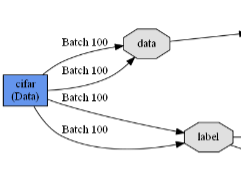
mark
训练阶段调用这一层
include { phase: TRAIN
}
图片的均值文件所放的路径。
transform_param { mean_file: "examples/cifar10/mean.binaryproto"
}
图片的训练数据路径,batchsize的大小。训练数据存储的方式
data_param { source: "examples/cifar10/cifar10_train_lmdb"
batch_size: 100
backend: LMDB
}
接下来又定义了一层
layer {
name: "cifar"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mean_file: "examples/cifar10/mean.binaryproto"
}
data_param {
source: "examples/cifar10/cifar10_test_lmdb"
batch_size: 100
backend: LMDB
}
}
跟上一层一模一样,只不过指定了阶段是TEST
测试集入口和训练集入口
卷积层
layer { name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
} param { lr_mult: 2
} convolution_param { num_output: 32
pad: 2
kernel_size: 5
stride: 1
weight_filler {
type: "gaussian"
std: 0.0001
} bias_filler { type: "constant"
}
}
}
起个名字,类型卷积层。bottom是data也就是上一层的名字。上一层的top对应下一层的bottom
top是conv1
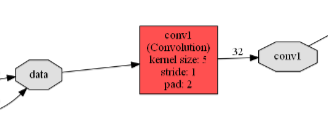
mark
指定了一下w和b的学习率。以及卷积层的相关参数
总共有多少个output的feature map
padding 过滤器大小 步长
w的初始化方式: 高斯 方差
b的初始化方式: 类型
池层
layer { name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
类型池层。 bottom是conv1 top是pool1
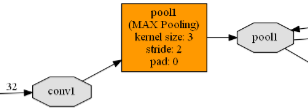
mark
池层的参数: 取最大值的pool(或均值)
池层出来的结果过relu 激励函数。它的bottom和top是一个
mark
把数据过完relu之后又返回pool1.
定义第二个卷积层。relu层。池层。 卷积层。 全连接层
计算test上的准确率,计算loss值。使用的类型softmax

mark
caffe的官方网站上就介绍了这些data loss
数据layers 卷积层。可以看到input output
http://caffe.berkeleyvision.org/tutorial/
给你一个sample如何定义一个卷积。每个参数的意思。
Solver 定义你所使用的优化方式。
Loss 定义损失。
keras是怎样做的
keras比theano 或者TensorFlow写代码简洁很多。
中文文档:
https://keras-cn.readthedocs.io/en/latest/
上手keras。源代码工程中。
7-3 keras-master/examples/cifar10_cnn.py
引入一些我们工程需要的包
from __future__ import print_functionimport kerasfrom keras.datasets import cifar10from keras.preprocessing.image import ImageDataGeneratorfrom keras.models import Sequentialfrom keras.layers import Dense, Dropout, Activation, Flattenfrom keras.layers import Conv2D, MaxPooling2Dimport os
batch_size = 32num_classes = 10epochs = 100data_augmentation = Truenum_predictions = 20save_dir = os.path.join(os.getcwd(), 'saved_models')
model_name = 'keras_cifar10_trained_model.h5'
定义网络训练所需要的超参数
# The data, split between train and test sets:(x_train, y_train), (x_test, y_test) = cifar10.load_data()
读取数据分为训练数据,测试数据。
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25)) model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25)) model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
我们要把网络结构层加入到sequential中
官方文档中有激励函数的说明。Flatten展开成1维的。
过最后一个全连接层的时候,总共有10类。
keras是一个高层次的封装。简单的网络结构。
# initiate RMSprop optimizeropt = keras.optimizers.rmsprop(lr=0.0001, decay=1e-6)
告诉我们的模型使用的是什么损失函数
# Let's train the model using RMSpropmodel.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
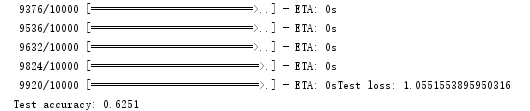
模型训练fit,以前我们是训练多少轮,每轮里面有多少个batch
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_test, y_test),
shuffle=True)
注明验证数据集是什么。是否需要打乱。
keras是基于theano和TensorFlow之上的。
更改后端。厦门叉车价格是多少
keras代码简洁。caffe使用文件配置模型描述。
mark
课程总结
神经元 激励函数 神经网络 神经网络中的梯度下降 前向传播 反向更新
随机梯度下降 简单版本神经网络
提高神经网络的学习效率: 并行计算 梯度消失问题 归一化
参数初始化 正则化 学习率 Dropout 交叉熵
简单版本的前馈神经网络 增加代码提高学习效率
卷积神经网络 全连接神经网络对比 卷积核 卷积层(参数)
池化层(池化层参数) 典型的卷积神经网络 如何使用卷积神经网络做图片识别
softmax层 theano实现卷积神经网络
TensorFlow框架 线性回归 TensorBoard
手写数字识别 图片分类(cnn) 单gpu 多gpu
其他两个框架与TensorFlow对比。caffe keras
神经网络的算法和原理有初步的了解。
rnn神经网络原理 与 应用 游戏ai
卷积神经网络做图像风格变化。 人脸识别。
深度学习之神经网络核心原理与算法-caffe&keras框架图片分类的更多相关文章
- Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.1
3.Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.1 http://blog.csdn.net/sunbow0 ...
- Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.2
3.Spark MLlib Deep Learning Convolution Neural Network(深度学习-卷积神经网络)3.2 http://blog.csdn.net/sunbow0 ...
- 针对深度学习(神经网络)的AI框架调研
针对深度学习(神经网络)的AI框架调研 在我们的AI安全引擎中未来会使用深度学习(神经网络),后续将引入AI芯片,因此重点看了下业界AI芯片厂商和对应芯片的AI框架,包括Intel(MKL CPU). ...
- Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.3
3.Spark MLlib Deep Learning Convolution Neural Network(深度学习-卷积神经网络)3.3 http://blog.csdn.net/sunbow0 ...
- 基于深度学习的人脸识别系统系列(Caffe+OpenCV+Dlib)——【四】使用CUBLAS加速计算人脸向量的余弦距离
前言 基于深度学习的人脸识别系统,一共用到了5个开源库:OpenCV(计算机视觉库).Caffe(深度学习库).Dlib(机器学习库).libfacedetection(人脸检测库).cudnn(gp ...
- 机器学习&深度学习基础(机器学习基础的算法概述及代码)
参考:机器学习&深度学习算法及代码实现 Python3机器学习 传统机器学习算法 决策树.K邻近算法.支持向量机.朴素贝叶斯.神经网络.Logistic回归算法,聚类等. 一.机器学习算法及代 ...
- 使用深度学习检测DGA(域名生成算法)——LSTM的输入数据本质上还是词袋模型
from:http://www.freebuf.com/articles/network/139697.html DGA(域名生成算法)是一种利用随机字符来生成C&C域名,从而逃避域名黑名单检 ...
- 深度学习——卷积神经网络 的经典网络(LeNet-5、AlexNet、ZFNet、VGG-16、GoogLeNet、ResNet)
一.CNN卷积神经网络的经典网络综述 下面图片参照博客:http://blog.csdn.net/cyh_24/article/details/51440344 二.LeNet-5网络 输入尺寸:32 ...
- 分享《机器学习实战基于Scikit-Learn和TensorFlow》中英文PDF源代码+《深度学习之TensorFlow入门原理与进阶实战》PDF+源代码
下载:https://pan.baidu.com/s/1qKaDd9PSUUGbBQNB3tkDzw <机器学习实战:基于Scikit-Learn和TensorFlow>高清中文版PDF+ ...
随机推荐
- virtualbox+vagrant学习-4-Vagrantfile-6-SSH Settings
SSH Settings 配置命名空间:config.ssh config.ssh的设置涉及到将如何配置vagrant使其通过ssh访问你的计算机.与大多数vagrant设置一样,默认设置通常都很好, ...
- SSM框架之批量增加示例(同步请求jsp视图解析)
准备环境:SSM框架+JDK8/JDK7+MySQL5.7+MAVEN3以上+Tomcat8/7应用服务器 示例说明: 分发给用户优惠券,通过checkbox选中批量分发,对应也就是批量增加. 对于公 ...
- 404 Note Found 队-Beta2
目录 组员情况 组员1(组长):胡绪佩 组员2:胡青元 组员3:庄卉 组员4:家灿 组员5:凯琳 组员6:翟丹丹 组员7:何家伟 组员8:政演 组员9:黄鸿杰 组员10:刘一好 组员11:何宇恒 展示 ...
- ra寄存器定位core
$ra寄存器中存入的是pc的值(程序运行处的地址),调用函数时,在跳转前,必须保存当前地址(pc的值),以便后来返回.jal $ra 保存后跳转,jr $ra,返回到跳转前,通过$ra保存进入上层栈地 ...
- mysql命令框中向表中插入中文字符,在可视化工具MySQL Workbeach或phpMyAdmin中不显示或显示乱码的问题解决
一.问题导出 在刚刚开始学习MySQL数据库应用与开发这门课程的时候,老师建议我们使用可视化工具MySQL Workbeach进行数据库的相关管理,但是小编在mysql命令框使用insert命令向表 ...
- 部署MongoDB复制集(副本集)
环境 操作系统:Ubuntu 18.04 MongoDB: 4.0.3 服务器 首先部署3台服务器,1台主节点 + 2台从节点 3台服务器的内容ip分别是: 10.140.0.5 (主节点) 10.1 ...
- Qt中的QString和QStringList常用方法
QString //QString定义 QString s1 = "abc"; QString s2("hello"); //字符串连接 QString s = ...
- django中间件-12
目录 自定义中间件 函数定义 类定义 中间件的执行顺序 在django中,中间件其实就是一个类,他是一个可以介入django的 request 和 response 的钩子框架,在请求响应不同的阶段, ...
- 小程序犯错(一):“ReferenceError: 模拟服务器传来的数据 is not defined”
学习数据绑定,在onLoad中模拟服务器传数据时,报错:模拟服务器传来的数据 is not defined 我这里粗心的忘记注释说明了,如下: 把该行无关的错误数据注释或删除即可.这里提醒同学们,出现 ...
- PyQt5 简易计算器
剩下计算函数(self.calculator)未实现,有兴趣的朋友可以实现它 [知识点] 1.利用循环添加按钮部件,及给每个按钮设置信号/槽 2.给按钮设置固定大小:button.setFixedSi ...