mysql索引提高查询速度
使用索引提高查询速度
1.前言
在web开发中,业务模版,业务逻辑(包括缓存、连接池)和数据库这三个部分,数据库在其中负责执行SQL查询并返回查询结果,是影响网站速度最重要的性能瓶颈。本文主要针对Mysql数据库,在淘宝的去IOE(I 代表IBM的缩写,即去IBM的存储设备和小型机;O是代表Oracle的缩写,去Oracle数据库,采用Mysql和Hadoop代替;E是代表EMC2,去EMC2的设备性,用PC server代替EMC2),大量使用Mysql集群!而优化数据的重要一步就是索引的建立,对于Mysql出现的慢查询,可以用索引提升查询速度。索引用于快速找出在某个列中有一特定值的行,不使用索引,Mysql将全表扫描,从第一条记录开始,然后读完整个表直到找出相关的行。
2.Mysql索引类型及创建
索引相关知识:
PRI主键约束; UNI唯一约束; MUL可以重复。
1).主键索引
它是一种特殊的唯一索引,不允许为空。一般建表时同时创建主键索引:
CREATE TABLE user(
id int unsigned not null auto_increment,
name varchar(50) not null,
email varchar(40) not null,
primary key (id)
);
2).普通索引
这是最基本的索引,没有任何限制:
create index idx_email on user(
email(20)
);
create index idx_name on user(
name(20)
);
mysql 支持索引前缀,一般姓名不超过20字符,所以建立索引限定20长度,节省索引文件大小
3).唯一索引
它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,列值的组合必须唯一。
CREATE UNIQUE INDEX idx_email ON user(
);
4).组合索引
create table sb_man(
id int PRIMARY key auto_increment,
new_name char(30) not null,
old_name char(30) not null,
index name(new_name,old_name)
);
# name索引是一个对new_name和old_name的索引。 查询方法:
select * from sb_man where new_name='yu';
select * from sb_man where new_name='yu' and old_name='yu1';
提示:>>>>>> 组合索引是最左前缀创建, 所以不能用如下sql
select * from sb_man where old_name='yu1'; <<<< 错误

3.什么时候用索引
1.索引引用
在索引列上,除了上面提到的有序查找之外,数据库利用各种各样的快速定位技术,能够大大提高查询效率。特别是当数据量非常大,查询涉及多个表时,使用索引往往能使查询速度加快成千上万倍。
例如,有2个未索引的表t1、t2、分别只包含列c1、c2 每个表分别含有1000行数据组成,值为111的数值,然后设置三张表,不同的几个值,
(这里我是用pymysql 执行 while 创建的数据)
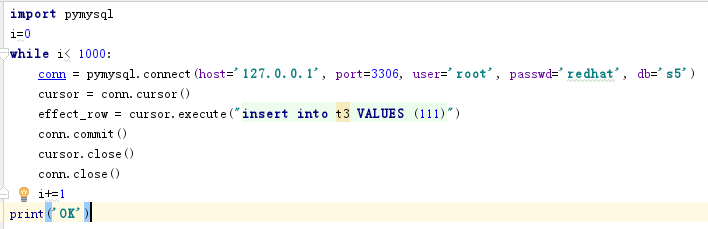
查找对应值相等行的查询如下所示。
在无索引的情况下处理此查询,必须寻找3个表所有的组合,以便得出与WHERE子句相配的那些行。
select c1,c2 from t1,t2 where c1!=c2
结果 查询过程>>
查询过程>>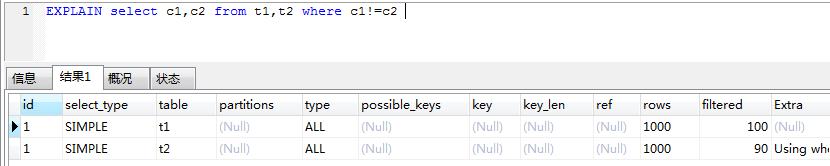
2.创建索引
在执行CREATE TABLE语句时可以创建索引,也可以单独用CREATE INDEX或ALTER TABLE来为表增加索引。
1.ALTER TABLE
ALTER TABLE用来创建普通索引、UNIQUE索引或PRIMARY KEY索引
删除索引: alter table tab_name drop {index|key} index_name;
alter table t1 drop index idx_c1;
添加索引: alter table t1 add index idx_c1(c1);
alter table t2 add index idx_c2(c2);
查询结果 虽然感觉没什么卵用。。。但是索引查询就是如此了。。。
虽然感觉没什么卵用。。。但是索引查询就是如此了。。。

mysql索引提高查询速度的更多相关文章
- 利用SQL索引提高查询速度
1.合理使用索引 索引是数据库中重要的数据结构,它的根本目的就是为了提高查询效率.现在大多数的数据库产品都采用IBM最先提出的ISAM索引结构. 索引的使用要恰到好处,其使用原则如下: 在经常进行连接 ...
- ORACLE 查询不走索引的原因分析,解决办法通过强制索引或动态执行SQL语句提高查询速度
(一)索引失效的原因分析: <>或者单独的>,<,(有时会用到,有时不会) 有时间范围查询:oracle 时间条件值范围越大就不走索引 like "%_" ...
- mysql千万级数据量根据索引优化查询速度
(一)索引的作用 索引通俗来讲就相当于书的目录,当我们根据条件查询的时候,没有索引,便需要全表扫描,数据量少还可以,一旦数据量超过百万甚至千万,一条查询sql执行往往需要几十秒甚至更多,5秒以上就已经 ...
- sqlite优化记录:建立索引加快查询速度
凡是数据库中,索引的存在就是为了提高查询速度的,数据库的索引有点类似于书本上面的目录的概念,因为在英文中都是index,事实上也就是目录. 其算法应该叫做“倒排索引”,这个其实也类似于搜索引擎里面的基 ...
- sql处理百万级以上的数据提高查询速度的方法
原文:http://blog.csdn.net/zhengyiluan/article/details/51671599 处理百万级以上的数据提高查询速度的方法: 1.应尽量避免在 where 子句中 ...
- 《转》sql处理百万级以上的数据提高查询速度的方法
处理百万级以上的数据提高查询速度的方法: 1.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描. 2.对查询进行优化,应尽量避免全表扫描,首先应考 ...
- (已实现)相似度到大数据查找之Mysql 文章匹配的一些思路与提高查询速度
需求,最近实现了文章的原创度检测功能,处理思路一是分词之后做搜索引擎匹配飘红,另一方面是量化词组,按文章.段落.句子做数据库查询,功能基本满足实际需求. 接下来,还需要在海量大数据中快速的查找到与一句 ...
- SQL Server 百万级数据提高查询速度的方法
1.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描. 2.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉 ...
- 提高查询速度:SQL Server数据库优化方案
查询速度慢的原因很多,常见如下几种: 1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷) 2.I/O吞吐量小,形成了瓶颈效应. 3.没有创建计算列导致查询不优化. 4.内存不足 ...
随机推荐
- PHP 算术运算符
PHP 算术运算符 运算符 名称 描述 实例 结果 x + y 加 x 和 y 的和 2 + 2 4 x - y 减 x 和 y 的差 5 - 2 3 x * y 乘 x 和 y 的积 5 * 2 1 ...
- python的XML处理模块ElementTree
ElementTree是python的XML处理模块,它提供了一个轻量级的对象模型.它在Python2.5以后成为Python标准库的一部分,但是Python2.4之前需要单独安装.在使用Elemen ...
- 关于QT中“崩溃”问题
经常会遇到一个问题,程序运行崩溃! 1.release.debug直接运行崩溃. 2.程序可以运行但是点击界面崩溃. 3.debug模式崩溃,release正常. 4.软件里面的release和deb ...
- selenium+python自动化87-Chrome浏览器静默模式启动(headless)
前言 selenium+phantomjs可以打开无界面的浏览器,实现静默模式启动浏览器完成自动化测试,这个模式是极好的,不需要占用电脑的屏幕. 但是呢,phantomjs这个坑还是比较多的,并且遇到 ...
- UnicodeEncodeError: 'gbk' codec can't encode character '\xbb' in position
python实现爬虫遇到编码问题: error:UnicodeEncodeError: 'gbk' codec can't encode character '\xXX' in position XX ...
- 3.纯 CSS 创作一个容器厚条纹边框特效
原文地址:3.纯 CSS 创作一个容器厚条纹边框特效 没有啥好点子呀,不爽 HTML代码: <div class="box"> <div class=" ...
- 1. Two Sum + 15. 3 Sum + 16. 3 Sum Closest + 18. 4Sum + 167. Two Sum II - Input array is sorted + 454. 4Sum II + 653. Two Sum IV - Input is a BST
▶ 问题:给定一个数组 nums 及一个目标值 target,求数组中是否存在 n 项的和恰好等于目标值 ▶ 第 1题,n = 2,要求返回解 ● 代码,160 ms,穷举法,时间复杂度 O(n2), ...
- MPI 环境配置,MPICH,VisualStudio
▶ Visual Studio 下配置MPI环境 ● 参考资料:http://blog.csdn.net/z909768094/article/details/50926162 ● 如果使用 MPIC ...
- mysql5.7.13 使用笔记
社区版下载地址:https://dev.mysql.com/downloads/mysql/ 安装:http://www.linuxidc.com/Linux/2016-04/130414.htm ...
- controller检查header
以前都只能拿到request再检查,其实有相应的注解. public Result updateRecentScore(@RequestBody Map map, @RequestHeader(&qu ...