Flask源码剖析详解
1. 前言
本文将基于flask 0.1版本(git checkout 8605cc3)来分析flask的实现,试图理清flask中的一些概念,加深读者对flask的理解,提高对flask的认识。从而,在使用flask过程中,能够减少困惑,胸有成竹,遇bug而不惊。
在试图理解flask的设计之前,你知道应该知道以下几个概念:
- flask(web框架)是什么
- WSGI是什么
- jinja2是什么
- Werkzeug是什么
本文将首先回答这些问题,然后再分析flask源码。
2. 知识准备
2.1 WSGI
下面这张图来自这里,通过这张图,读者对web框架所处的位置和WSGI协议能够有一个感性的认识。
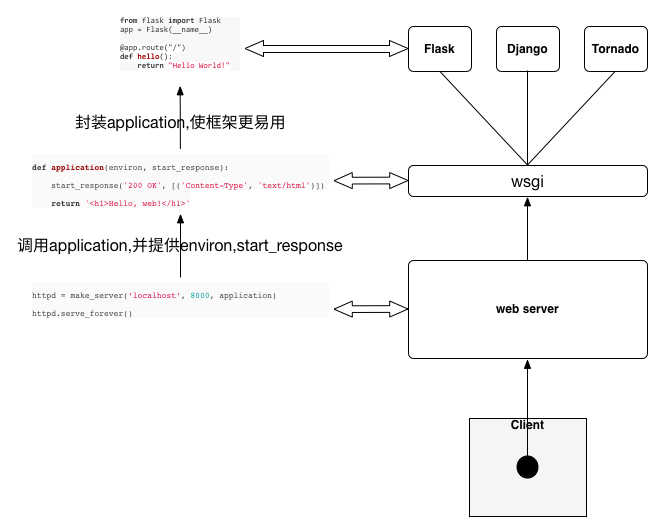
WSGI
wikipedia上对WSGI的解释就比较通俗易懂。为了更好的理解WSGI,我们来看一个例子:
from eventlet import wsgi
import eventlet
def hello_world(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/plain')])
return ['Hello, World!\r\n']
wsgi.server(eventlet.listen(('', 8090)), hello_world)
我们定义了一个hello_world函数,这个函数接受两个参数。分别是environ和start_response,我们将这个hello_world传递给eventlet.wsgi.server以后, eventlet.wsgi.server在调用hello_world时,会自动传入environ和start_response这两个参数,并接受hello_world的返回值。而这,就是WSGI的作用。
也就是说,在python的世界里,通过WSGI约定了web服务器怎么调用web应用程序的代码,web应用程序需要符合什么样的规范,只要web应用程序和web服务器都遵守WSGI 协议,那么,web应用程序和web服务器就可以随意的组合。这也就是WSGI存在的原因。
WSGI是一种协议,这里,需要注意两个相近的概念:
- uwsgi同WSGI一样是一种协议
- 而uWSGI是实现了uwsgi和WSGI两种协议的web服务器
2.2 jinja2与Werkzeug
flask依赖jinja2和Werkzeug,为了完全理解flask,我们还需要简单介绍一下这两个依赖。
jinja2
Jinja2是一个功能齐全的模板引擎。它有完整的unicode支持,一个可选 的集成沙箱执行环境,被广泛使用。
jinja2的一个简单示例如下:
>>> from jinja2 import Template
>>> template = Template('Hello !')
>>> template.render(name='John Doe')
u'Hello John Doe!'
Werkzeug
Werkzeug是一个WSGI工具包,它可以作为web框架的底层库。
我发现Werkzeug的官方文档介绍特别好,下面这一段摘录自这里。
Werkzeug是一个WSGI工具包。WSGI是一个web应用和服务器通信的协议,web应用可以通过WSGI一起工作。一个基本的”Hello World”WSGI应用看起来是这样的:
def application(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/plain')])
return ['Hello World!']
上面这小段代码就是WSGI协议的约定,它有一个可调用的start_response 。environ包含了所有进来的信息。 start_response用来表明已经收到一个响应。 通过Werkzeug,我们可以不必直接处理请求或者响应这些底层的东西,它已经为我们封装好了这些。
请求数据需要environ对象,Werkzeug允许我们以一个轻松的方式访问数据。响应对象是一个WSGI应用,提供了更好的方法来创建响应。如下所示:
from werkzeug.wrappers import Response
def application(environ, start_response):
response = Response('Hello World!', mimetype='text/plain')
return response(environ, start_response)
2.3 如何理解wsgi, Werkzeug, flask之间的关系
Flask是一个基于Python开发并且依赖jinja2模板和Werkzeug WSGI服务的一个微型框架,对于Werkzeug,它只是工具包,其用于接收http请求并对请求进行预处理,然后触发Flask框架,开发人员基于Flask框架提供的功能对请求进行相应的处理,并返回给用户,如果要返回给用户复杂的内容时,需要借助jinja2模板来实现对模板的处理。将模板和数据进行渲染,将渲染后的字符串返回给用户浏览器。
2.4 Flask是什么,不是什么
Flask永远不会包含数据库层,也不会有表单库或是这个方面的其它东西。Flask本身只是Werkzeug和Jinja2的之间的桥梁,前者实现一个合适的WSGI应用,后者处理模板。当然,Flask也绑定了一些通用的标准库包,比如logging。除此之外其它所有一切都交给扩展来实现。
为什么呢?因为人们有不同的偏好和需求,Flask不可能把所有的需求都囊括在核心里。大多数web应用会需要一个模板引擎。然而不是每个应用都需要一个SQL数据库的。
Flask 的理念是为所有应用建立一个良好的基础,其余的一切都取决于你自己或者 扩展。
3. Flask源码分析
Flask的使用非常简单,官网的例子如下:
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello():
return "Hello World!"
if __name__ == "__main__":
app.run()
每当我们需要创建一个flask应用时,我们都会创建一个Flask对象:
app = Flask(__name__)
下面看一下Flask对象的__init__方法,如果不考虑jinja2相关,核心成员就下面几个:
class Flask:
def __init__(self, package_name):
self.package_name = package_name
self.root_path = _get_package_path(self.package_name)
self.view_functions = {}
self.error_handlers = {}
self.before_request_funcs = []
self.after_request_funcs = []
self.url_map = Map()
我们把目光聚集到后面几个成员,view_functions中保存了视图函数(处理用户请求的函数,如上面的hello()),error_handlers中保存了错误处理函数,before_request_funcs和after_request_funcs保存了请求的预处理函数和后处理函数。
self.url_map用以保存URI到视图函数的映射,即保存app.route()这个装饰器的信息,如下所示:
def route(...):
def decorator(f):
self.add_url_rule(rule, f.__name__, **options)
self.view_functions[f.__name__] = f
return f
return decorator
上面说到的是初始化部分,下面看一下执行部分,当我们执行app.run()时,调用堆栈如下:
app.run()
run_simple(host, port, self, **options)
__call__(self, environ, start_response)
wsgi_app(self, environ, start_response)
wsgi_app是flask核心:
def wsgi_app(self, environ, start_response):
with self.request_context(environ):
rv = self.preprocess_request()
if rv is None:
rv = self.dispatch_request()
response = self.make_response(rv)
response = self.process_response(response)
return response(environ, start_response)
可以看到,wsgi_app这个函数的作用就是先调用所有的预处理函数,然后分发请求,再调用所有后处理函数,最后返回response。
看一下dispatch_request函数的实现,因为,这里有flask的错误处理逻辑:
def dispatch_request(self):
try:
endpoint, values = self.match_request()
return self.view_functions[endpoint](**values)
except HTTPException, e:
handler = self.error_handlers.get(e.code)
if handler is None:
return e
return handler(e)
except Exception, e:
handler = self.error_handlers.get(500)
if self.debug or handler is None:
raise
return handler(e)
如果出现错误,则根据相应的error code,调用不同的错误处理函数。
上面这段简单的源码分析,就已经将Flask几个核心变量和核心函数串联起来了。其实,我们这里扣出来的几段代码,也就是Flask的核心代码。毕竟,Flask的0.1版本包含大量注释以后,也才六百行代码。
4. flask的魔法
如果读者打开flask.py文件,将看到我前面的源码分析几乎已经覆盖了所有重要的代码。但是,细心的读者会看到,在Flask.py文件的末尾处,有以下几行代码:
# context locals
_request_ctx_stack = LocalStack()
current_app = LocalProxy(lambda: _request_ctx_stack.top.app)
request = LocalProxy(lambda: _request_ctx_stack.top.request)
session = LocalProxy(lambda: _request_ctx_stack.top.session)
g = LocalProxy(lambda: _request_ctx_stack.top.g)
这是我们得以方便的使用flask开发的魔法,也是flask源码中的难点。在分析之前,我们先看一下它们的作用。
在flask的开发过程中,我们可以通过如下方式访问url中的参数:
from flask import request
@app.route('/')
def hello():
name = request.args.get('name', None)
看起来request像是一个全局变量,那么,一个全局变量为什么可以在一个多线程环境中随意使用呢,下面就随我来一探究竟吧!
先看一下全局变量_request_ctx_stack的定义:
_request_ctx_stack = LocalStack()
正如它LocalStack()的名字所暗示的那样,_request_ctx_stack是一个栈。显然,一个栈肯定会有push 、pop和top函数,如下所示:
class LocalStack(object):
def __init__(self):
self._local = Local()
def push(self, obj):
rv = getattr(self._local, 'stack', None)
if rv is None:
self._local.stack = rv = []
rv.append(obj)
return rv
def pop(self):
stack = getattr(self._local, 'stack', None)
if stack is None:
return None
elif len(stack) == 1:
release_local(self._local)
return stack[-1]
else:
return stack.pop()
按照我们的理解,要实现一个栈,那么LocalStack类应该有一个成员变量,是一个list,然后通过 这个list来保存栈的元素。然而,LocalStack并没有一个类型是list的成员变量, LocalStack仅有一个成员变量self._local = Local()。
顺藤摸瓜,我们来到了Werkzeug的源码中,到达了Local类的定义处:
class Local(object):
def __init__(self):
object.__setattr__(self, '__storage__', {})
object.__setattr__(self, '__ident_func__', get_ident)
def __getattr__(self, name):
try:
return self.__storage__[self.__ident_func__()][name]
except KeyError:
raise AttributeError(name)
def __setattr__(self, name, value):
ident = self.__ident_func__()
storage = self.__storage__
try:
storage[ident][name] = value
except KeyError:
storage[ident] = {name: value}
需要注意的是,Local类有两个成员变量,分别是__storage__和__ident_func__,其中,前者 是一个字典,后者是一个函数。这个函数的含义是,获取当前线程的id(或协程的id)。
此外,我们注意到,Local类自定义了__getattr__和__setattr__这两个方法,也就是说,我们在操作self.local.stack时, 会调用__setattr__和__getattr__方法。
_request_ctx_stack = LocalStack()
_request_ctx_stack.push(item)
# 注意,这里赋值的时候,会调用__setattr__方法
self._local.stack = rv = [] ==> __setattr__(self, name, value)
而__setattr的定义如下:
def __setattr__(self, name, value):
ident = self.__ident_func__()
storage = self.__storage__
try:
storage[ident][name] = value
except KeyError:
storage[ident] = {name: value}
在__setattr__中,通过__ident_func__获取到了一个key,然后进行赋值。自此,我们可以知道, LocalStack是一个全局字典,或者说是一个名字空间。这个名字空间是所有线程共享的。 当我们访问字典中的某个元素的时候,会通过__getattr__进行访问,__getattr__先通过线程id, 找当前这个线程的数据,然后进行访问。
字段的内容如下:
{'thread_id':{'stack':[]}}
{'thread_id1':{'stack':[_RequestContext()]},
'thread_id2':{'stack':[_RequestContext()]}}
最后,我们来看一下其他几个全局变量:
current_app = LocalProxy(lambda: _request_ctx_stack.top.app)
request = LocalProxy(lambda: _request_ctx_stack.top.request)
session = LocalProxy(lambda: _request_ctx_stack.top.session)
g = LocalProxy(lambda: _request_ctx_stack.top.g)
读者可以自行看一下LocalProxy的源码,LocalProxy仅仅是一个代理(可以想象设计模式中的代理模式)。
通过LocalStack和LocalProxy这样的Python魔法,每个线程访问当前请求中的数据(request, session)时, 都好像都在访问一个全局变量,但是,互相之间又互不影响。这就是Flask为我们提供的便利,也是我们 选择Flask的理由!
5. 总结
在这篇文章中,我们简单地介绍了WSGI, jinja2和Werkzeug,详细介绍了Flask在web开发中所处的位置和发挥的作用。最后,深入Flask的源码,了解了Flask的实现。
Flask源码剖析详解的更多相关文章
- NopCommerce源码架构详解--初识高性能的开源商城系统cms
很多人都说通过阅读.学习大神们高质量的代码是提高自己技术能力最快的方式之一.我觉得通过阅读NopCommerce的源码,可以从中学习很多企业系统.软件开发的规范和一些新的技术.技巧,可以快速地提高我们 ...
- NopCommerce源码架构详解
NopCommerce源码架构详解--初识高性能的开源商城系统cms 很多人都说通过阅读.学习大神们高质量的代码是提高自己技术能力最快的方式之一.我觉得通过阅读NopCommerce的源码,可以从 ...
- Nop--NopCommerce源码架构详解专题目录
最近在研究外国优秀的ASP.NET mvc电子商务网站系统NopCommerce源码架构.这个系统无论是代码组织结构.思想及分层都值得我们学习.对于没有一定开发经验的人要完全搞懂这个源码还是有一定的难 ...
- Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览
一.设计原理 1.Hadoop架构: 流水线(PipeLine) 2.Hadoop架构: HDFS中数据块的状态及其切换过程,GS与BGS 3.Hadoop架构: 关于Recovery (Lease ...
- Hadoop3.1.1源码Client详解 : 写入准备-RPC调用与流的建立
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 关于RPC(Remote Procedure Call),如果没有概念,可以参考一下RMI(Remot ...
- Hadoop3.1.1源码Client详解 : 入队前数据写入
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 紧接着上一篇: Hadoop3.1.1源码Client详解 : 写入准备-RPC调用与流的建立 先给出 ...
- Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之DataStreamer(Packet发送) : 主干
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 在上一章(Hadoop3.1.1源码Client详解 : 写入准备-RPC调用与流的建立) 我们提到, ...
- Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之ResponseProcessor(ACK接收)
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 紧接着上一篇文章: Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之D ...
- flask源码剖析系列(系列目录)
flask源码剖析系列(系列目录) 01 flask源码剖析之werkzurg 了解wsgi 02 flask源码剖析之flask快速使用 03 flask源码剖析之threading.local和高 ...
随机推荐
- Arrays.binarySearch 数组二分查找
public static void main(String[] args) throws Exception { /** * binarySearch(Object[], Object key) a ...
- opencv查看源代码
这一节是一个插曲,有的人刚开始学opencv就看源代码,有的人直接拿着opencv的API用...... 学了一个多月opencv了,就是没找到源代码,想看的时候都是从网上找的,或者看网上说从哪个文件 ...
- selenium+python自动化91-unittest多线程生成报告(BeautifulReport)
前言 selenium多线程跑用例,这个前面一篇已经解决了,如何生成一个测试报告这个是难点,刚好在github上有个大神分享了BeautifulReport,完美的结合起来,就能生成报告了. 环境必备 ...
- windows2012任务计划不执行
1.Windows Server 2008 计划任务在哪里配置? 2.Windows Server 2008 可以配置每分钟或是每小时执行我的任务吗? 答案是:可以! 首先Windows Server ...
- bootstrap做的导航
顶部导航:nav-tabs 左边导航:nav-list 响应式布局:div嵌套 ~ container.row.ol-lg-X 效果: 源码: <!DOCTYPE html> <ht ...
- VBA 调用DLL动态链接库
在ArcMap中引用动态链接库 我在VB6下编译生成了一个动态链接库文件VBAPrj.dll,其中有一类模块VBACls,此类模块有一个方法Test(Doc As Object). ...
- 机器学习入门-提取文章的主题词 1.jieba.analyse.extract_tags(提取主题词)
1.jieba.analyse.extract_tags(text) text必须是一连串的字符串才可以 第一步:进行语料库的读取 第二步:进行分词操作 第三步:载入停用词,同时对分词后的语料库进行 ...
- as3 文档类判断是否被加载
if (!stage) { trace(("被加载->this.parent:" + this.parent)); }else { trace(("单独打开-> ...
- c++实现一个比较两个string类型的版本号的小demo
在软件实现更新模块的时候,有可能会判断一下服务器上的版本的版本号和本地版本的版本号. 下面有类似这样形式的版本号:string str = "0.0.0.1"; 分析一下可以看出, ...
- salt之grains组件
grains是saltstack最重要的组件之一,作用是收集被控主机的基本信息,这些信息通常都是一些静态类的数据,包括CPU.内核.操作系统.虚拟化等,在服务器端可以根据这些信息进行灵活定制,管理员可 ...