Hadoop基础-HDFS的API实现增删改查
Hadoop基础-HDFS的API实现增删改查
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
本篇博客开发IDE使用的是Idea,如果没有安装Idea软件的可以去下载安装,如何安装IDE可以参考我的笔记:https://www.cnblogs.com/yinzhengjie/p/9080387.html。当然如果有小伙伴已经有自己使用习惯的IDE就不用更换了,只是配置好相应的Maven即可,我这里配置Maven是针对idea界面进行说明的。
一.将模块添加maven框架支持
1>.点击"Add Frameworks Support"
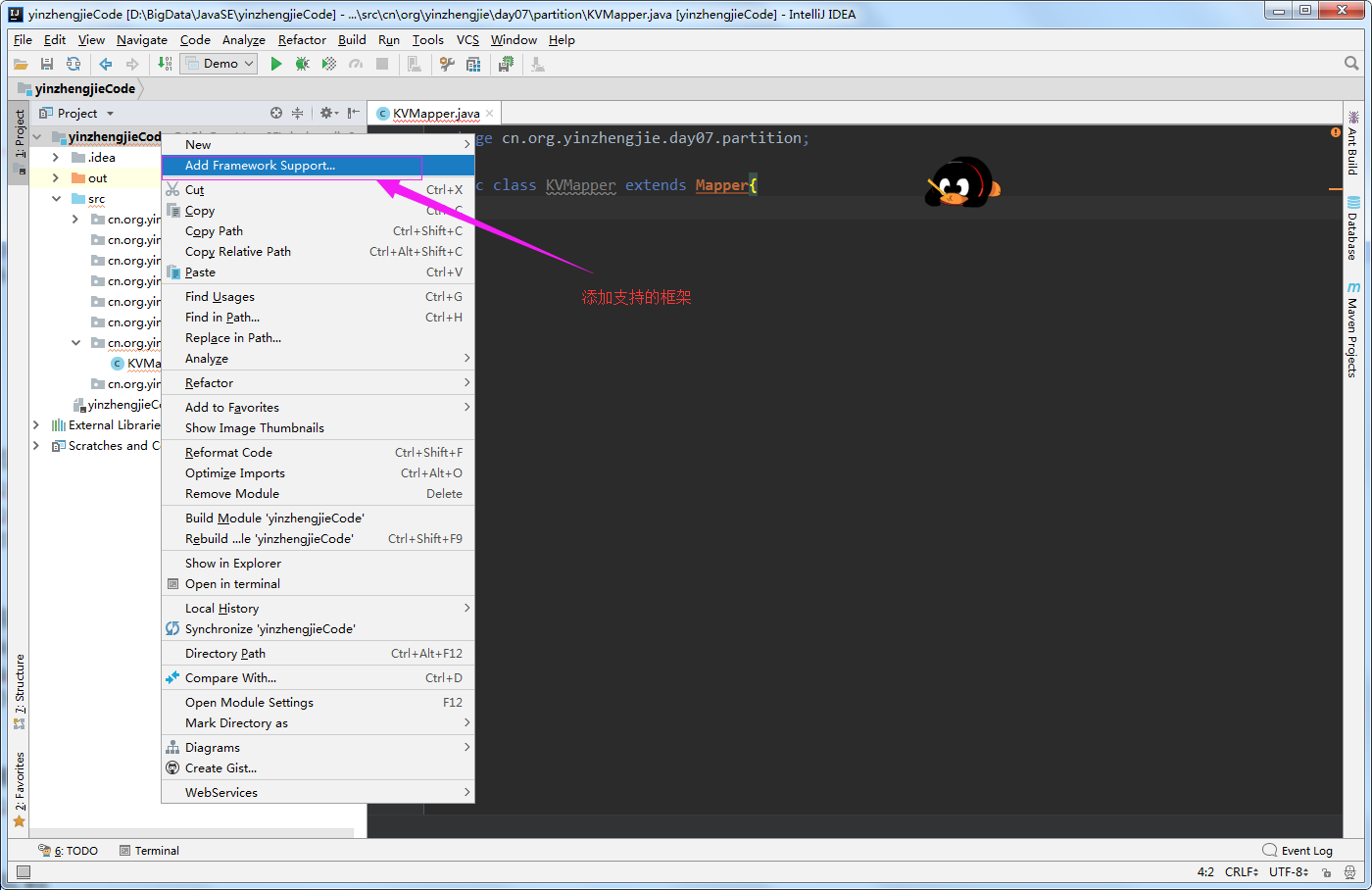
2>.添加Maven框架的支持
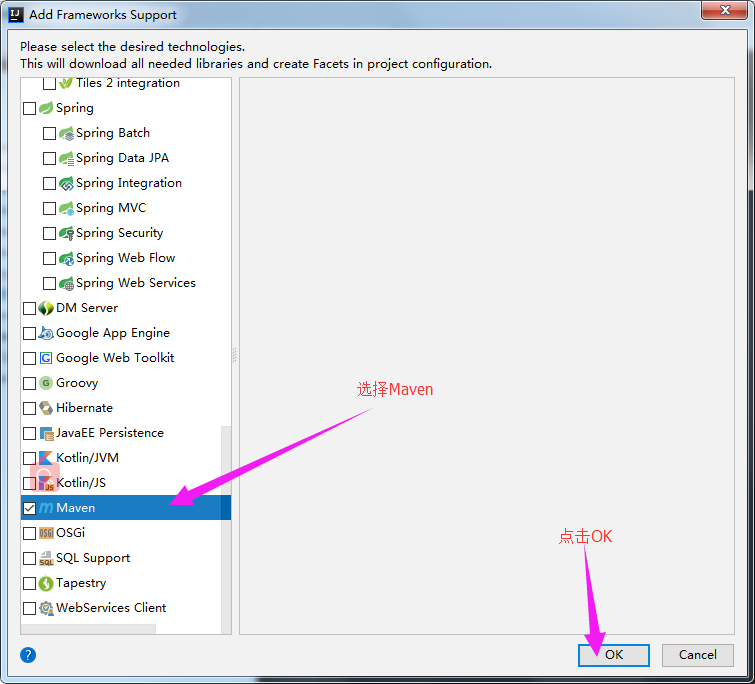
3>.在pom.xml中添加以下依赖关系
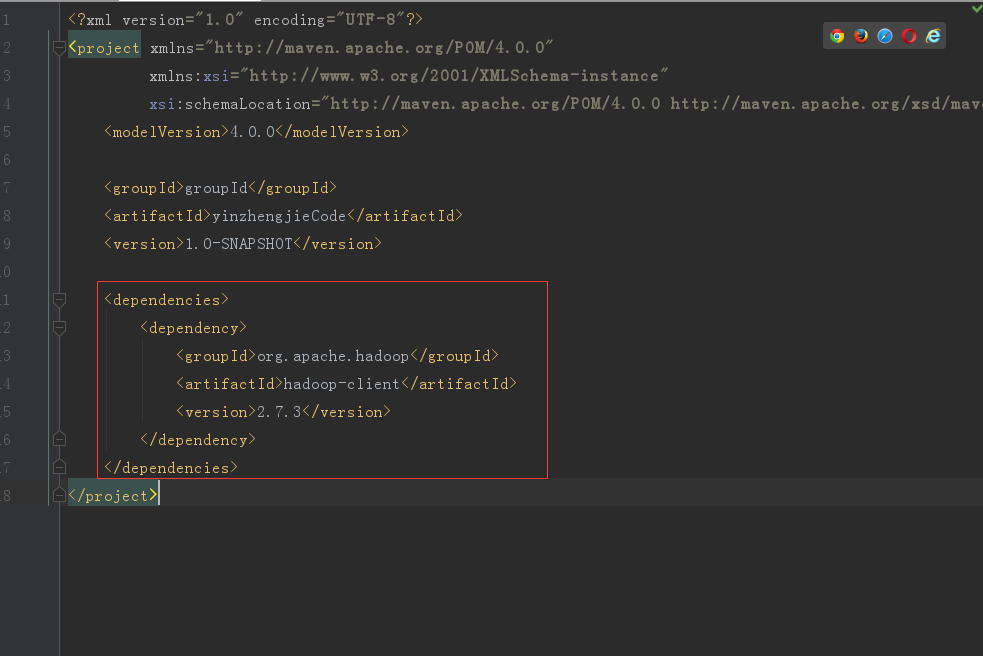
4>.启用自动导入

5>.等待下载完成
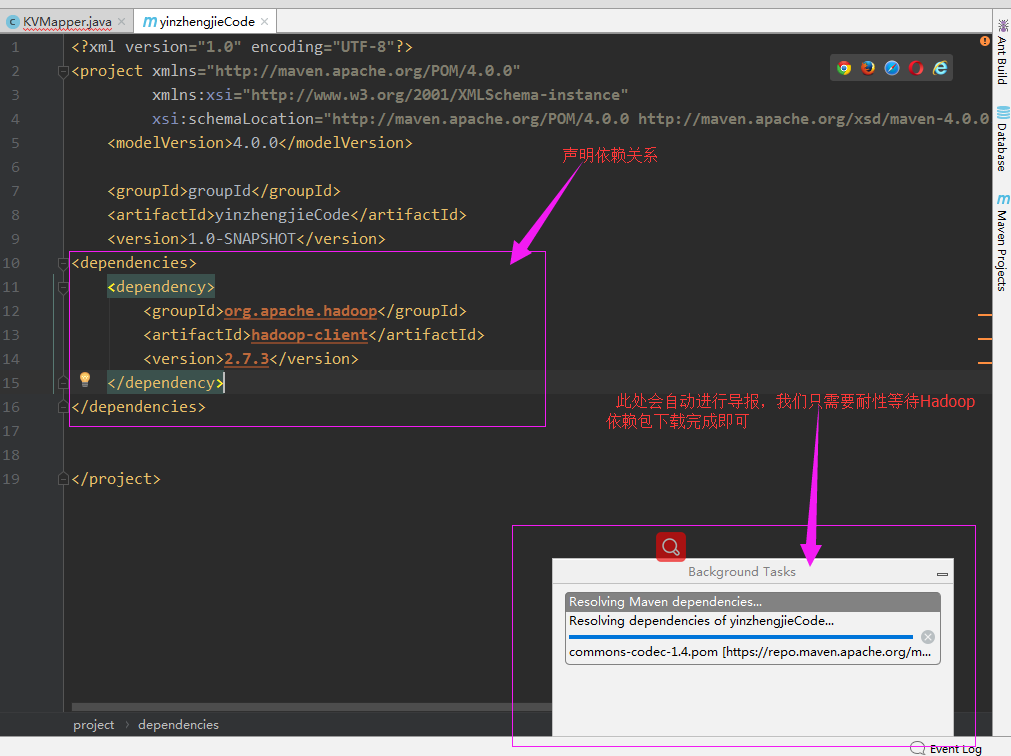
6>.手动刷新Maven项目
二.将Linux服务器端的HDFS文件到项目中的resources目录
1>.查看服务端配置文件
[yinzhengjie@s101 ~]$ more /soft/hadoop/etc/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://s101:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/yinzhengjie/hadoop</value>
</property>
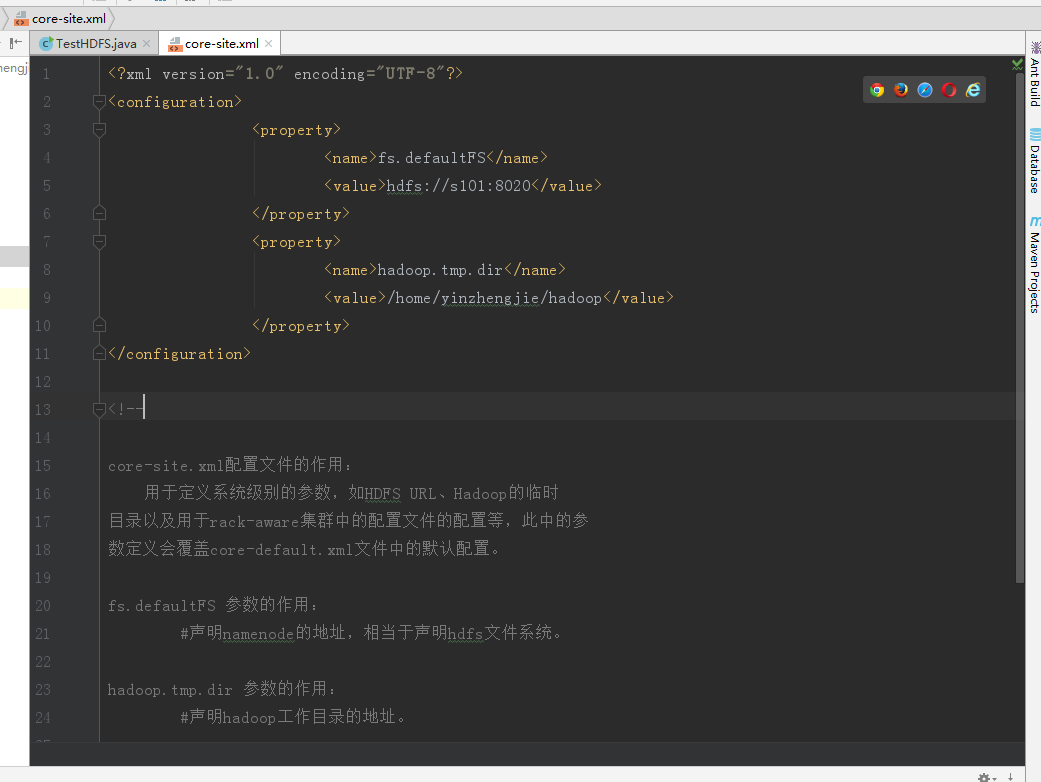
</configuration> <!-- core-site.xml配置文件的作用:
用于定义系统级别的参数,如HDFS URL、Hadoop的临时
目录以及用于rack-aware集群中的配置文件的配置等,此中的参
数定义会覆盖core-default.xml文件中的默认配置。 fs.defaultFS 参数的作用:
#声明namenode的地址,相当于声明hdfs文件系统。 hadoop.tmp.dir 参数的作用:
#声明hadoop工作目录的地址。 -->
[yinzhengjie@s101 ~]$ sz /soft/hadoop/etc/hadoop/core-site.xml
rz
zmodem trl+C ȡ % bytes bytes/s :: Errors [yinzhengjie@s101 ~]$
2>.将下载的文件拷贝到项目中resources目录下
3>.查看下载的core-site.xml 文件内容
三.HDFS的API实现增删改查
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.day01.note1; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException; public class HdfsDemo {
public static void main(String[] args) throws IOException {
insert();
update();
read();
delete();
} //删除文件
private static void delete() throws IOException {
//由于我的Hadoop完全分布式根目录对yinzhengjie以外的用户(尽管是root用户也没有写入权限哟!因为是hdfs系统,并非Linux系统!)没有写入
// 权限,所以需要手动指定当前用户权限。使用“HADOOP_USER_NAME”属性就可以轻松搞定!
System.setProperty("HADOOP_USER_NAME","yinzhengjie");
//实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。)
Configuration conf = new Configuration();
//代码的入口点,初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。
FileSystem fs = FileSystem.get(conf);
//这个path是指是需要在文件系统中写入的数据,里面的字符串可以写出“hdfs://s101:8020/yinzhengjie.sql”,但由于core-site.xml配置
// 文件中已经有“hdfs://s101:8020”字样的前缀,因此我们这里可以直接写文件名称
Path path = new Path("/yinzhengjie.sql");
//通过fs的delete方法可以删除文件,第一个参数指的是删除文件对象,第二参数是指递归删除,一般用作删除目录
boolean res = fs.delete(path, true);
if (res == true){
System.out.println("====================");
System.out.println(path + "文件删除成功!");
System.out.println("====================");
}
//释放资源
fs.close();
} //将数据追加到文件内容中
private static void update() throws IOException {
//由于我的Hadoop完全分布式根目录对yinzhengjie以外的用户(尽管是root用户也没有写入权限哟!因为是hdfs系统,并非Linux系统!)没有写入
// 权限,所以需要手动指定当前用户权限。使用“HADOOP_USER_NAME”属性就可以轻松搞定!
System.setProperty("HADOOP_USER_NAME","yinzhengjie"); //实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。)
Configuration conf = new Configuration();
//代码的入口点,初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。
FileSystem fs = FileSystem.get(conf);
//这个path是指是需要在文件系统中写入的数据,里面的字符串可以写出“hdfs://s101:8020/yinzhengjie.sql”,但由于core-site.xml配置
// 文件中已经有“hdfs://s101:8020”字样的前缀,因此我们这里可以直接写文件名称
Path path = new Path("/yinzhengjie.sql");
//通过fs的append方法实现对文件的追加操作
FSDataOutputStream fos = fs.append(path);
//通过fos写入数据
fos.write("\nyinzhengjie".getBytes());
//释放资源
fos.close();
fs.close(); } //将数据写入HDFS文件系统
private static void insert() throws IOException {
//由于我的Hadoop完全分布式根目录对yinzhengjie以外的用户(尽管是root用户也没有写入权限哟!因为是hdfs系统,并非Linux系统!)没有写入
// 权限,所以需要手动指定当前用户权限。使用“HADOOP_USER_NAME”属性就可以轻松搞定!
System.setProperty("HADOOP_USER_NAME","yinzhengjie"); //实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。)
Configuration conf = new Configuration();
//代码的入口点,初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。
FileSystem fs = FileSystem.get(conf);
//这个path是指是需要在文件系统中写入的数据,里面的字符串可以写出“hdfs://s101:8020/yinzhengjie.sql”,但由于core-site.xml配置
// 文件中已经有“hdfs://s101:8020”字样的前缀,因此我们这里可以直接写文件名称
Path path = new Path("/yinzhengjie.sql");
//通过fs的create方法创建一个文件输出对象,第一个参数是hdfs的系统路径,第二个参数是判断第一个参数(也就是文件系统的路径)是否存在,如果存在就覆盖!
FSDataOutputStream fos = fs.create(path,true);
//通过fos写入数据
fos.writeUTF("尹正杰");
//释放资源
fos.close();
fs.close();
} //在HDFS文件系统中读取数据
private static void read() throws IOException {
//实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。)
Configuration conf = new Configuration();
//代码的入口点,初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。
FileSystem fs = FileSystem.get(conf);
//这个path是指NameNode中的HDFS分布式系统中的路径映射(注意,我这里写的是主机名,你可以写IP,如果是测试环境的话需要在hosts文件中添加主机名映射哟!)
Path path = new Path("hdfs://s101:8020/yinzhengjie.sql");
//通过fs读取数据
FSDataInputStream fis = fs.open(path);
int len = 0;
byte[] buf = new byte[4096];
while ((len = fis.read(buf)) != -1){
System.out.println(new String(buf, 0, len));
}
}
} /*
以上代码执行结果如下:
尹正杰
yinzhengjie
====================
/yinzhengjie.sql文件删除成功!
====================
*/
四.HDFS的API实现文件拷贝(不需要我们自己实现数据流的拷贝,而是使用Hadoop自带的IOUtils类实现)
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.day01.note1; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils; import java.io.FileOutputStream;
import java.io.IOException; public class HdfsDemo1 {
public static void main(String[] args) throws IOException {
get();
} //定义方法下载文件到本地
private static void get() throws IOException {
//由于我的Hadoop完全分布式根目录对yinzhengjie以外的用户(尽管是root用户也没有写入权限哟!因为是hdfs系统,并非Linux系统!)没有写入
// 权限,所以需要手动指定当前用户权限。使用“HADOOP_USER_NAME”属性就可以轻松搞定!
System.setProperty("HADOOP_USER_NAME","yinzhengjie");
//实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。)
Configuration conf = new Configuration();
//代码的入口点,初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。
FileSystem fs = FileSystem.get(conf);
//这个path是指是需要在文件系统中写入的数据,里面的字符串可以写出“hdfs://s101:8020/xrsync.sh”,但由于core-site.xml配置
// 文件中已经有“hdfs://s101:8020”字样的前缀,因此我们这里可以直接写相对路径
Path path = new Path("/xrsync.sh");
//通过fs的open方法获取一个对象输入流
FSDataInputStream fis = fs.open(path);
//创建一个对象输出流
FileOutputStream fos = new FileOutputStream("yinzhengjie.sql");
//通过Hadoop提供的IOUtiles工具类的copyBytes方法拷贝数据,第一个参数是需要传一个输入流,第二个参数需要传入一个输出流,第三个指定传输数据的缓冲区大小。
IOUtils.copyBytes(fis,fos,4096);
System.out.println("文件拷贝成功!");
//别忘了释放资源哟
fis.close();
fos.close();
fs.close();
}
} /*
以上代码执行结果如下:
文件拷贝成功!
*/
五.自定义块大小写入文件
配置Hadoop的最小blocksize,必须是512的倍数,有可能你会问为什么要设置大小是512的倍数呢?因为hdfs在写入的过程中会进行校验,每512字节进行依次校验,因此需要设置是512的倍数。编辑“hdfs-site.xml”配置文件。
1>.服务器端hdfs的配置文件,修改默认的块大小,默认块大小是1048576字节,我们手动改为1024字节,配合过程如下:(别忘记重启服务,修改配置文件一般都是需要重启服务的哟)
[yinzhengjie@s101 ~]$ more `which xrsync.sh`
#!/bin/bash
#@author :yinzhengjie
#blog:http://www.cnblogs.com/yinzhengjie
#EMAIL:y1053419035@qq.com #判断用户是否传参
if [ $# -lt ];then
echo "请输入参数";
exit
fi #获取文件路径
file=$@ #获取子路径
filename=`basename $file` #获取父路径
dirpath=`dirname $file` #获取完整路径
cd $dirpath
fullpath=`pwd -P` #同步文件到DataNode
for (( i=;i<=;i++ ))
do
#使终端变绿色
tput setaf
echo =========== s$i %file ===========
#使终端变回原来的颜色,即白灰色
tput setaf
#远程执行命令
rsync -lr $filename `whoami`@s$i:$fullpath
#判断命令是否执行成功
if [ $? == ];then
echo "命令执行成功"
fi
done
[yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ more /soft/hadoop/etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.namenode.fs-limits.min-block-size</name>
<value></value>
</property>
</configuration> <!--
hdfs-site.xml 配置文件的作用:
#HDFS的相关设定,如文件副本的个数、块大小及是否使用强制权限
等,此中的参数定义会覆盖hdfs-default.xml文件中的默认配置. dfs.replication 参数的作用:
#为了数据可用性及冗余的目的,HDFS会在多个节点上保存同一个数据
块的多个副本,其默认为3个。而只有一个节点的伪分布式环境中其仅用
保存一个副本即可,这可以通过dfs.replication属性进行定义。它是一个
软件级备份。 dfs.namenode.fs-limits.min-block-size 参数的作用:
#该参数是用指定hdfs最小块存储设置 -->
[yinzhengjie@s101 ~]$ xrsync.sh /soft/hadoop/etc/full/hdfs-site.xml
=========== s102 %file ===========
命令执行成功
=========== s103 %file ===========
命令执行成功
=========== s104 %file ===========
命令执行成功
[yinzhengjie@s101 ~]$
2>.客户端编写API代码如下
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.day01.note1; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IOUtils;
import java.io.FileInputStream;
import java.io.IOException; public class HdfsDemo4 {
public static void main(String[] args) throws IOException {
String path = "F:/yinzhengjie.sql";
customWrite(path);
} //定制化写入副本数和块大小(blocksize)
private static void customWrite(String path) throws IOException {
//由于我的Hadoop完全分布式根目录对yinzhengjie以外的用户(尽管是root用户也没有写入权限哟!因为是hdfs系统,并非Linux系统!)没有写入
// 权限,所以需要手动指定当前用户权限。使用“HADOOP_USER_NAME”属性就可以轻松搞定!
System.setProperty("HADOOP_USER_NAME","yinzhengjie");
//实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。)
Configuration conf = new Configuration();
//代码的入口点,初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。
FileSystem fs = FileSystem.get(conf);
//这个path是指是需要在文件系统中写入的数据,里面的字符串可以写出“hdfs://s101:8020/yinzhengjie.sql”,但由于core-site.xml配置文件中已经有“hdfs://s101:8020”字样的前缀,因此我们这里可以直接写相对路径
Path hdfsPath = new Path("/yinzhengjie.sql");
//通过fs的create方法创建一个文件输出对象,第一个参数是hdfs的系统路径,第二个参数是判断第一个参数(也就是文件系统的路径)是否存在,如果存在就覆盖!第三个参数是指定缓冲区大小,第四个参数是指定存储的副本数(规定数据类型必须为short类型),第五个参数是指定块大小。
FSDataOutputStream fos = fs.create(hdfsPath,true,,(short) ,);
//创建出本地的文件输入流,也就是我们真正想要上传的文件。
FileInputStream fis = new FileInputStream(path);
//拷贝文件
IOUtils.copyBytes(fis,fos,);
//释放资源
fos.close();
fis.close();
}
}
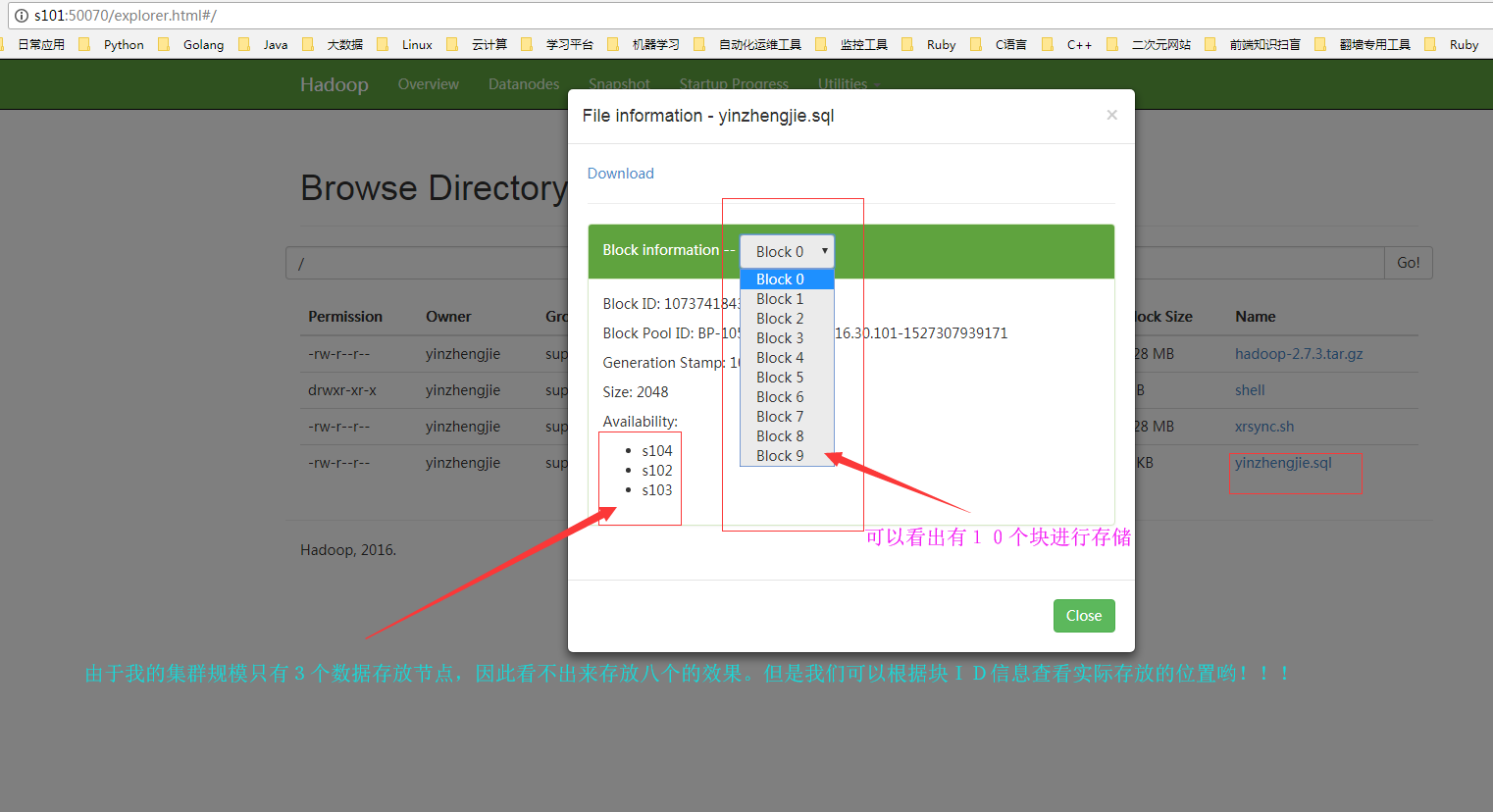
3>.客户端通过浏览器访问NameNode的WEBUI
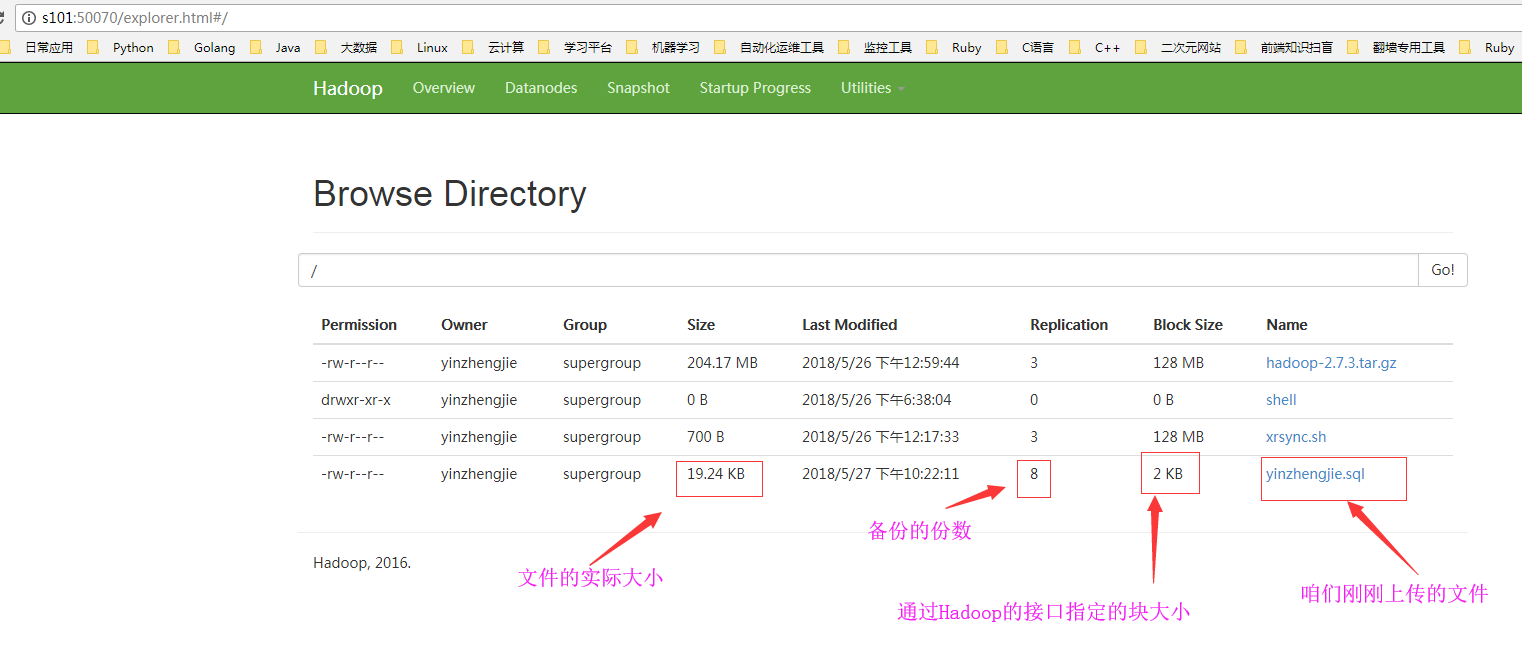
看完上面的信息发现和API设置的几乎一致呢,那必定得一致啊,由于块大小是2KB,而上传的文件是19.25kb,最少得10个块进行存储,我们也可以通过WEBUI来查看。
Hadoop基础-HDFS的API实现增删改查的更多相关文章
- Hadoop基础-HDFS的API常见操作
Hadoop基础-HDFS的API常见操作 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习HDFS时的一些琐碎的学习笔记, 方便自己以后查看.在调用API ...
- 05_Elasticsearch 单模式下API的增删改查操作
05_Elasticsearch 单模式下API的增删改查操作 安装marvel 插件: zjtest7-redis:/usr/local/elasticsearch-2.3.4# bin/plugi ...
- Elasticsearch 单模式下API的增删改查操作
<pre name="code" class="html">Elasticsearch 单模式下API的增删改查操作 http://192.168. ...
- Vc数据库编程基础MySql数据库的表增删改查数据
Vc数据库编程基础MySql数据库的表增删改查数据 一丶表操作命令 1.查看表中所有数据 select * from 表名 2.为表中所有的字段添加数据 insert into 表名( 字段1,字段2 ...
- Elasticsearch学习系列之单模式下API的增删改查操作
这里我们通过Elasticsearch的marvel插件实现单模式下API的增删改查操作 索引的初始化操作 创建索引之前可以对索引进行初始化操作,比如先指定shard数量以及replicas的数量 代 ...
- Java数据库连接--JDBC基础知识(操作数据库:增删改查)
一.JDBC简介 JDBC是连接java应用程序和数据库之间的桥梁. 什么是JDBC? Java语言访问数据库的一种规范,是一套API. JDBC (Java Database Connectivit ...
- JDBC基础学习(一)—JDBC的增删改查
一.数据的持久化 持久化(persistence): 把数据保存到可掉电式存储设备中以供之后使用.大多数情况下,数据持久化意味着将内存中的数据保存到硬盘上加以固化,而持久化的实现过程大多通过各 ...
- MongoDB(二)-- Java API 实现增删改查
一.下载jar包 http://central.maven.org/maven2/org/mongodb/mongo-java-driver/ 二.代码实现 package com.xbq.mongo ...
- python基础学习之类的属性 增删改查
类中的属性如何在类外部使用代码进行增删改查呢 增加.改变: setattr内置函数以及 __setattr__魔法方法 class A: aaa = '疏楼龙宿' a = A() setattr(a, ...
随机推荐
- TeamWork#3,Week5,Scrum Meeting 11.16
到目前为止各方面工作已经基本完成,爬虫程序也调整完毕,正在等待全部整合. 成员 已完成 待完成 彭林江 完成爬虫结构调整 新爬虫与服务器连接 郝倩 完成爬虫结构调整 新爬虫与服务器连接 高雅智 重定位 ...
- 每日scrum(1)
今天又正式开始了第二个冲刺周期,计划十天,主要需要改进的地方包括UI界面,还有一些细节的把握. 今天出现的主要问题有:在讨论UI界面风格的时候,小组内部意见不统一,对UI界面的创作流程不熟悉,以及难度 ...
- 第二阶段Sprint冲刺会议3
进展:讨论视频录制的具体功能,查看有关资料,开始着手编写有关代码.
- Hibernate笔记④--一级二级缓存、N+1问题、saveorupdate、实例代码
一级缓存及二级缓存 一级缓存也是Session 缓存 一个链接用户的多次查询使用缓存 跨用户 则无缓存 hibernate自带的 get和load都会填充并利用一级缓存 二级缓 ...
- Journal entry of the eleventh chapter to chapter twelfth
第十一章:正如很多人一样,觉得软件工程这个课程好像没什么用,感觉提高不了自己的写代码能力,学的都是理论知识,好像对于我们这种技术类的专业离得有点远,是这样的吗? 第十二章:每样东西都没有完美的,即使我 ...
- 团队作业之四则运算GUI展示
一.项目Coding.net原码仓库地址:https://git.coding.net/caoying/Teamwork.git 队员: 卢琪:2016011986 曹滢:2016012102 二.P ...
- 团队作业2 <嗨,你的快递!>需求分析与原型设计
哦,不,是你的快速(*_*) 第一部分 需求分析 1.1 用户调研 1.1.1调研对象:由于我们的系统是校园快递代取业务,面向的是大学生活,所以本次调研范围都是在校大学生(除了师大学生,也包括了外校的 ...
- Alpha阶段事后诸葛分析
一.设想和目标 1.我们的软件要解决什么问题?是否定义得很清楚?是否对典型用户和典型场景有清晰的描述? 我们的软件主要是解决在宿舍中购买商品的软件,不同于淘宝等软件,本软件主要是用于学生开设的店铺及宿 ...
- js ajax 经典案例
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- [华商韬略] 拉里·埃里森(Larry Elison) 的传奇人生
拉里·埃里森(Larry Elison) 的传奇人生 开战机.玩游艇.盖皇宫,挑战比尔·盖茨,干掉50多家硅谷豪强……全世界比拉里·埃里森更有钱的只有5个,像他这样的硅谷“坏孩子”却是唯一. 19 ...