深入理解JAVA I/O系列五:对象序列化
序列化
对象序列化的目标是将对象保存到磁盘中,或者允许在网络中直接传输对象。对象序列化机制允许把内存中的JAVA对象转换成跟平台无关的二进制流,从而允许将这种二进制流持久地保存在磁盘上,通过网络将这种二进制流传输到另一个网络节点,其他程序一旦获得了这种二进制流,都可以讲二进制流恢复成原来的JAVA对象。
序列化为何存在
我们知道当虚拟机停止运行之后,内存中的对象就会消失;另外一种情况就是JAVA对象要在网络中传输,如RMI过程中的参数和返回值。这两种情况都必须要将对象转换成字节流,而从用于保存到磁盘空间中或者能在网络中传输。
由于RMI是JAVA EE技术的基础---所有分布式应用都需要跨平台、跨网络。因此序列化是JAVA EE的基础,通常建议,程序创建的每个JavaBean类都可以序列化。
如何序列化
如果要让每个对象支持序列化机制,必须让它的类是可序列化的,则该类必须实现如下两个接口之一:
1、Serializable
2、Extmalizable
这里有几个原则,我们一起来看下:
1、Serializable是一个标示性接口,接口中没有定义任何的方法或字段,仅用于标示可序列化的语义。
2、静态变量和成员方法不可序列化。
3、一个类要能被序列化,该类中的所有引用对象也必须是可以被序列化的。否则整个序列化操作将会失败,并且会抛出一个NotSerializableException,除非我们将不可序列化的引用标记为transient。
4、声明成transient的变量不被序列化工具存储,同样,static变量也不被存储。
一、先来看下将一个对象序列化之后存储到文件中:
public class Person implements Serializable
{
int age;
String address;
double height;
public Person(int age, String address, double height)
{
this.age = age;
this.address = address;
this.height = height;
}
}
public class SerializableTest
{
public static void main(String[] args) throws IOException, IOException
{
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(
"d:/data.txt"));
Person p = new Person(25,"China",180);
oos.writeObject(p);
oos.close();
}
}
执行结果:

1、对象序列化之后,写入的是一个二进制文件,所有打开乱码是正常现象,不过透过乱码我们还是可以看到文件中存储的就是我们创建的那个对象那个。
2、Person对象实现了Serializable接口,这个接口没有任何方法需要被实现,只是一个标记接口,表示这个类的对象可以被序列化。

3、在该程序中,我们是调用ObjectOutputStream对象的writeObject()方法输出可序列化对象的。该对象还提供了输出基本类型的方法。
writeFloat(float val)
二、接下来我们来看下从文件中反序列化对象的过程:
public class SerializableTest
{
public static void main(String[] args) throws IOException, IOException,
ClassNotFoundException
{
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(
"d:/data.txt"));
Person p = new Person(25, "China", 180);
oos.writeObject(p);
oos.close(); ObjectInputStream ois = new ObjectInputStream(new FileInputStream(
"d:/data.txt"));
Person p1 = (Person) ois.readObject();
System.out.println("age=" + p1.age + ";address=" + p1.address
+ ";height=" + p1.height);
ois.close();
}
}
执行结果:
age=25;address=China;height=180.0
1、从第12行开始就是反序列化的过程。其中输入流用到的是ObjectInputStream,与前面的ObjectOutputStream相对应。
2、在调用readObject()方法的时候,有一个强转的动作。所以在反序列化时,要提供java对象所属类的class文件。
3、如果使用序列化机制向文件中写入了多个对象,在反序列化时,需要按实际写入的顺序读取。
对象引用的序列化
1、上面介绍对象的成员变量都是基本数据类型,如果对象的成员变量是引用类型,会有什么不同吗?
这个引用类型的成员变量必须也是可序列化的,否则拥有该类型成员变量的类的对象不可序列化。
2、在引用对象这个地方,会出现一种特殊的情况。例如,有两个Teacher对象,它们的Student实例变量都引用了同一个Person对象,而且该Person对象还有一个引用变量引用它。如下图所示:
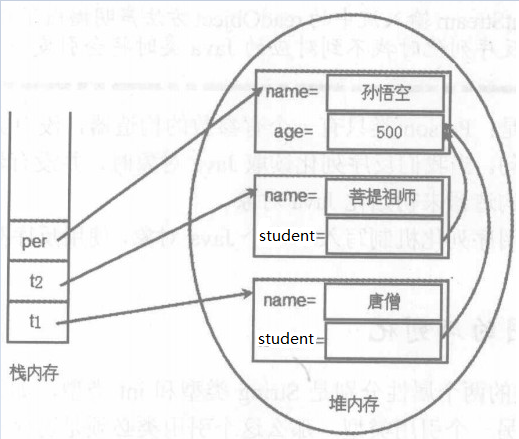
这里有三个对象per、t1、t2,如果都被序列化,会存在这样一个问题,在序列化t1的时候,会隐式的序列化person对象。在序列化t2的时候,也会隐式的序列化person对象。在序列化per的时候,会显式的序列化person对象。所以在反序列化的时候,会得到三个person对象,这样就会造成t1、t2所引用的person对象不是同一个。显然,这并不符合图中所展示的关系,也违背了java序列化的初衷。
为了避免这种情况,JAVA的序列化机制采用了一种特殊的算法:
1、所有保存到磁盘中的对象都有一个序列化编号。
2、当程序试图序列化一个对象时,会先检查该对象是否已经被序列化过,只有该对象从未(在本次虚拟机中)被序列化,系统才会将该对象转换成字节序列并输出。
3、如果对象已经被序列化,程序将直接输出一个序列化编号,而不是重新序列化。
自定义序列化
1、前面介绍可以用transient关键字来修饰实例变量,该变量就会被完全隔离在序列化机制之外。还是用前面相同的程序,只是将address变量用transient来修饰:
public class Person implements Serializable
{
int age;
transient String address;
double height;
public Person(int age, String address, double height)
{
this.age = age;
this.address = address;
this.height = height;
}
}
public class SerializableTest
{
public static void main(String[] args) throws IOException, IOException,
ClassNotFoundException
{
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(
"d:/data.txt"));
Person p = new Person(25, "China", 180);
oos.writeObject(p);
oos.close(); ObjectInputStream ois = new ObjectInputStream(new FileInputStream(
"d:/data.txt"));
Person p1 = (Person) ois.readObject();
System.out.println("age=" + p1.age + ";address=" + p1.address
+ ";height=" + p1.height);
ois.close();
}
}
序列化的结果:
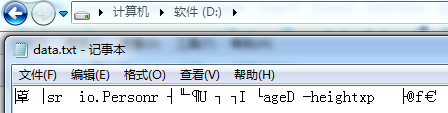
反序列化结果:
age=25;address=null;height=180.0
2、在二进制文件中,没有看到"China"的字样,反序列化之后address的value值为null。
3、这说明使用tranisent修饰的变量,在经过序列化和反序列化之后,JAVA对象会丢失该实例变量值。
鉴于上述的这种情况,JAVA提供了一种自定义序列化机制。这样程序就可以自己来控制如何序列化各实例变量,甚至不序列化实例变量。
在序列化和反序列化过程中需要特殊处理的类应该提供如下的方法,这些方法用于实现自定义的序列化。
writeObject()
readObject()
这两个方法并不属于任何的类和接口,只要在要序列化的类中提供这两个方法,就会在序列化机制中自动被调用。
其中writeObject方法用于写入特定类的实例状态,以便相应的readObject方法可以恢复它。通过重写该方法,程序员可以获取对序列化的控制,可以自主决定可以哪些实例变量需要序列化,怎样序列化。该方法调用out.defaultWriteObject来保存JAVA对象的实例变量,从而可以实现序列化java对象状态的目的。
public class Person implements Serializable
{
/**
*
*/
private static final long serialVersionUID = 1L;
int age;
String address;
double height;
public Person(int age, String address, double height)
{
this.age = age;
this.address = address;
this.height = height;
} //JAVA BEAN自定义的writeObject方法
private void writeObject(ObjectOutputStream out) throws IOException
{
System.out.println("writeObejct ------");
out.writeInt(age);
out.writeObject(new StringBuffer(address).reverse());
out.writeDouble(height);
} private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException
{
System.out.println("readObject ------");
this.age = in.readInt();
this.address = ((StringBuffer)in.readObject()).reverse().toString();
this.height = in.readDouble();
}
}
public class SerializableTest
{
public static void main(String[] args) throws IOException, IOException,
ClassNotFoundException
{
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(
"d:/data.txt"));
Person p = new Person(25, "China", 180);
oos.writeObject(p);
oos.close(); ObjectInputStream ois = new ObjectInputStream(new FileInputStream(
"d:/data.txt"));
Person p1 = (Person) ois.readObject();
System.out.println("age=" + p1.age + ";address=" + p1.address
+ ";height=" + p1.height);
ois.close();
}
}
序列化结果:

反序列化结果:
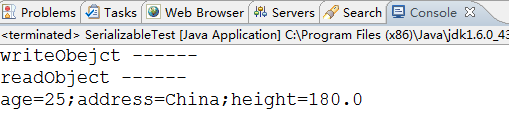
1、这个地方跟前面的区别就是在Person类中提供了writeObject方法和readObject方法,并且提供了具体的实现。
2、在ObjectOutputStream调用writeObject方法执行过程,肯定调用了Person类的writeObject方法,因为在控制台上将代码中第20行的日志输出了。
3、自定义实现的好处是:程序员可以更加精细或者说可以去定制自己想要实现的序列化,如例子中将address变量值反转。利用这种特点,我们可以在序列化过程中对一些敏感信 息做特殊的处理。
4、在这里因为我们在要序列化的类中提供了这两个方法,所以被调用了,如果不提供,我认为会默认调用ObjectOutputStream/ObjectInputStream提供的这两个方法。
序列化问题
1、静态变量不会被序列化。
2、子类序列化时:
如果父类没有实现Serializable接口,没有提供默认构造函数,那么子类的序列化会出错;
如果父类没有实现Serializable接口,提供了默认的构造函数,那么子类可以序列化,父类的成员变量不会被序列化。
如果父类实现了Serializable接口,则父类和子类都可以序列化。
深入理解JAVA I/O系列五:对象序列化的更多相关文章
- 深入理解java内存模型系列文章
转载关于java内存模型的系列文章,写的非常好. 深入理解java内存模型(一)--基础 深入理解java内存模型(二)--重排序 深入理解java内存模型(三)--顺序一致性 深入理解java内存模 ...
- java基础解析系列(五)---HashMap并发下的问题以及HashTable和CurrentHashMap的区别
java基础解析系列(五)---HashMap并发下的问题以及HashTable和CurrentHashMap的区别 目录 java基础解析系列(一)---String.StringBuffer.St ...
- 深入理解Java中的不可变对象
深入理解Java中的不可变对象 不可变对象想必大部分朋友都不陌生,大家在平时写代码的过程中100%会使用到不可变对象,比如最常见的String对象.包装器对象等,那么到底为何Java语言要这么设计,真 ...
- JAVA基础知识之IO——对象序列化
对象序列化 Java对象序列化(Serialize)是指将Java对象写入IO流,反序列化(Deserilize)则是从IO流中恢复该Java对象. 对象序列化将程序运行时内存中的对象以字节码的方式保 ...
- C#(服务器)与Java(客户端)通过Socket传递对象(序列化 json)
下面详细讲解实现的关键步骤: 通信关键: C#和java用Socket通信,发送数据和接收数据可以统一采用UTF-8编码,经过测试,使用UTF-8编码可以成功传递对象. 对于Sock ...
- Java基础(二十九)Java IO(6)对象序列化(Object Serialization)
参考之前整理过的Java序列化与反序列化:https://www.cnblogs.com/BigJunOba/p/9127414.html 使用对象输入输出流可以实现对象序列化与反序列化,可以直接存取 ...
- javaIO流(五)--对象序列化
一.序列化概念 几乎只要是我们的java开发,就一定会存在有序列化的概念,而正是有序列化的概念逐步发展,慢慢也有了更多的系列化的标准.--所谓的对象序列化指的是将内存中保存的对象,以二进制数据流的形式 ...
- js之oop <五>对象序列化(js的JSON操作)
js对象序列化的过程,就是对象转换为JSON的过程.JSON.stringify() 将对象序列化成JSON.(接收对象,输出字符串) var obj = {x:2,y:3}; var str = J ...
- 深入理解JAVA I/O系列一:File
I/O简介 I/O问题可以说是当今web应用中所面临的的主要问题之一,大部分的web应用系统的瓶颈都是I/O瓶颈.这个系列主要介绍JAVA的I/O类库基本架构.磁盘I/O工作机制.网络I/O工作机制以 ...
随机推荐
- 【转】在发布站点前,Web开发者需要关注哪些技术细节
转摘:http://www.csdn.net/article/2014-05-19/2819818-technical-details-programmer 在网站发布前,开发者需要关注有许多的技术细 ...
- 【HNOI2014】道路堵塞
题面 题解 解法一 这个思路要基于以下一个结论: 当你删掉某条边\((x,x+1)\)时,最短路路线为:\(1\to x(\leq u)\to y(>u) \to n\),并且\(x\to y\ ...
- 洛咕 P3645 [APIO2015]雅加达的摩天楼
暴力连边可以每个bi向i+kdi连边权是k的边. 考虑这样的优化: 然后发现显然是不行的,因为可能还没有走到一个dog的建筑物就走了这个dog的边. 然后就有一个很妙的方法--建一个新的图,和原图分开 ...
- 在CentOS上安装Mysql使用yum安装mysql
https://jingyan.baidu.com/article/c74d600079be530f6a595dc3.html
- Open-Drain&Push-Pull
在配置GPIO(General Purpose Input Output)管脚的时候,常会见到两种模式:开漏(open-drain,漏极开路)和推挽(push-pull).对此两种模式,有何区别和联系 ...
- python 利用urllib 获取办公区公网Ip
import json,reimport urllib.requestdef GetLocalIP(): IPInfo = urllib.request.urlopen("http://ip ...
- Kali Linux菜单中各工具功能大全
各工具kali官方简介(竖排):https://tools.kali.org/tools-listing 名称 类型 使用模式 功能 功能评价 dmitry 信息收集 whois查询/子域名收集/ ...
- 16节实用性爆棚的Ps课:零基础秒上手,让你省钱也赚钱
ps视频教程,ps自学视频教程.ps免费视频教程下载,16节实用性爆棚的Ps课教程视频内容较大,分为俩部分: 16节实用性爆棚的Ps课第一部分:百度网盘,https://pan.baidu.com/s ...
- 将exe依赖运行的dll,合并入exe中,整个程序仅存在一个exe文件
方法一: 使用ILMerge合并winform生成的exe和引用的dll文件 参考:https://blog.csdn.net/u010108836/article/details/76782375 ...
- 关于Netty的学习前总结
摘要 前段时间一直在学习netty因为工作忙的原因没有写一个学习的总结,今天抽个空先把总结写了吧.事先声明,本文不会详细的介绍每一个部分不过每个部分都会附上讲解详细的url.本文只是为了解释通Nett ...